
9月7日,在2023騰訊全球數字生態大會上,騰訊首次公開了完全自主研發的通用大語言模型——騰訊混元大模型。得益于全鏈路自研技術,騰訊混元大模型能夠理解上下文的含義,并且有長文記憶能力,可以流暢地進行專業領域的多輪對話。
騰訊從2021年開始,曾先后推出了千億、萬億級參數模型。經過多年時間的持續研發投入和積累,以及在實際應用中不斷地自主研發創新,騰訊目前已經完全掌握了從模型算法到機器學習框架,再到AI基礎設施的全鏈路自研技術。騰訊混元大模型的誕生,也是騰訊在大模型領域多年的積累和探索的成果。
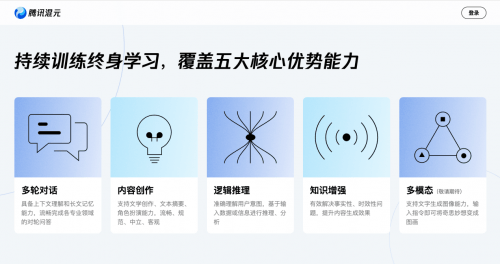
據了解,混元大模型是從第一個token開始從零訓練的。通過采用預訓練“探真”技術、動態鋸齒狀注意力機制、位置編碼優化、原創思維鏈策略等創新的大模型算法,使得大模型事實幻覺率相比主流開源大模型減少30%—50%,并讓大模型能夠真正像人一樣識別問題陷阱,并結合實際的應用場景進行推理和決策。
此外,混元大模型還使用了自研的機器學習框架Angel,使得訓練速度相比業界主流框架提升1倍,推理速度比業界主流框架提升1.3倍。

得益于在算法、學習框架等各個層面進行的一系列自研創新,混元大模型已經具備良好的可靠性和成熟度,其上下文理解、長文記憶能力和邏輯推理能力表現優秀。
在中國信通院《大規模預訓練模型技術和應用的評估方法》的標準符合性測試中,混元大模型共測評66個能力項,在“模型開發”和“模型能力”兩個重要領域的綜合評價均獲得了當前的最高分。在主流的評測集MMLU、CEval和AGI-eval上,混元大模型均有優異的表現,特別是在中文的理科、高考題和數學等子項上表現突出。
騰訊混元大模型是一個從實踐中來,到實踐中去的實用級大模型。它不僅展示了騰訊在大模型領域的技術實力和創新能力,更體現了騰訊在將人工智能技術應用到實際場景中的探索和實踐。通過與產業數據和場景相結合,混元大模型為解決產業痛點帶來了全新的思路和方案。





