
多模態大模型最全綜述來了!
由微軟7位華人研究員撰寫,足足119頁——

它從目前已經完善的和還處于最前沿的兩類多模態大模型研究方向出發,全面總結了五個具體研究主題:
- 視覺理解
- 視覺生成
- 統一視覺模型
- LLM加持的多模態大模型
- 多模態agent
并重點關注到一個現象:
多模態基礎模型已經從專用走向通用。
Ps. 這也是為什么論文開頭作者就直接畫了一個哆啦A夢的形象。
誰適合閱讀這份綜述(報告)?
用微軟的原話來說:
只要你想學習多模態基礎模型的基礎知識和最新進展,不管你是專業研究員,還是在校學生,它都是你的“菜”。
一起來看看~
一文摸清多模態大模型現狀
這五個具體主題中的前2個為目前已經成熟的領域,后3個則還屬于前沿領域。
1、視覺理解
這部分的核心問題是如何預訓練一個強大的圖像理解backbone。
如下圖所示,根據用于訓練模型的監督信號的不同,我們可以將方法分為三類:
標簽監督、語言監督(以CLIP為代表)和只有圖像的自監督。
其中最后一個表示監督信號是從圖像本身中挖掘出來的,流行的方法包括對比學習、非對比學習和masked image建模。
在這些方法之外,文章也進一步討論了多模態融合、區域級和像素級圖像理解等類別的預訓練方法。
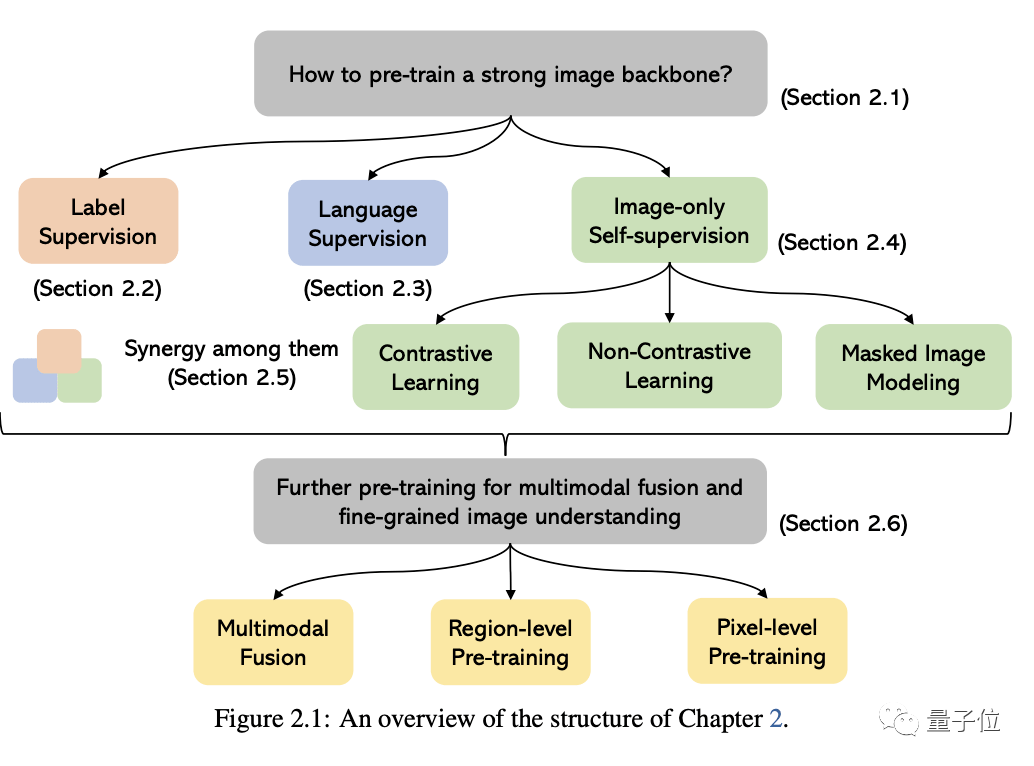
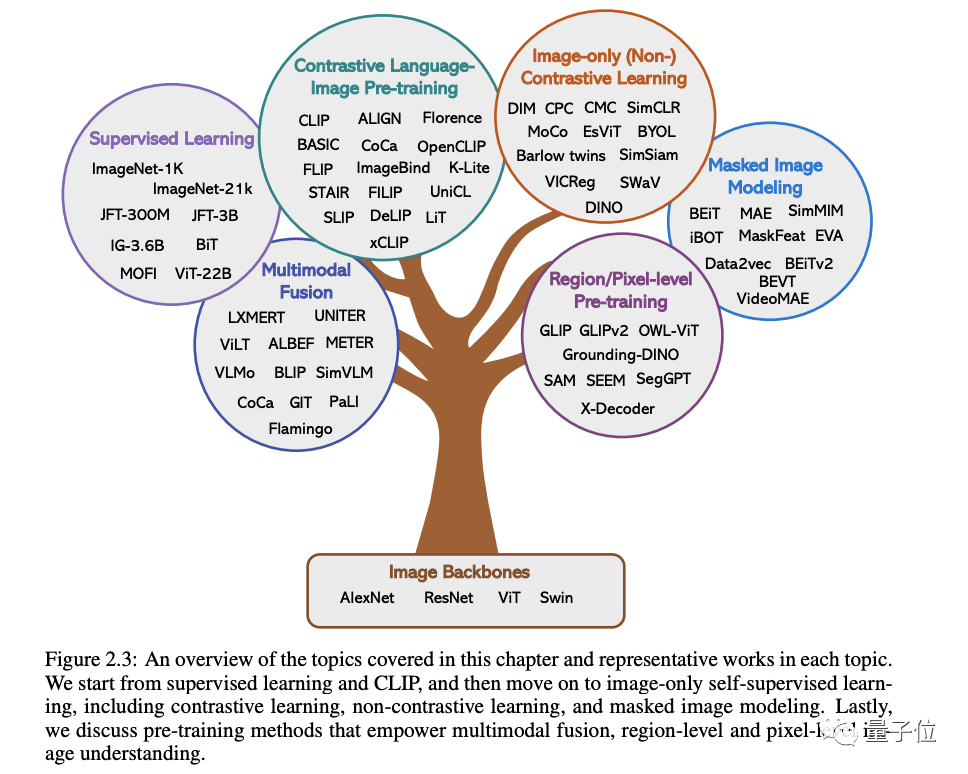
還列出了以上這些方法各自的代表作品。
2、視覺生成
這個主題是AIGC的核心,不限于圖像生成,還包括視頻、3D點云圖等等。
并且它的用處不止于藝術、設計等領域——還非常有助于合成訓練數據,直接幫助我們實現多模態內容理解和生成的閉環。
在這部分,作者重點討論了生成與人類意圖嚴格一致的效果的重要性和方法(重點是圖像生成)。
具體則從空間可控生成、基于文本再編輯、更好地遵循文本提示和生成概念定制(concept customization)四個方面展開。
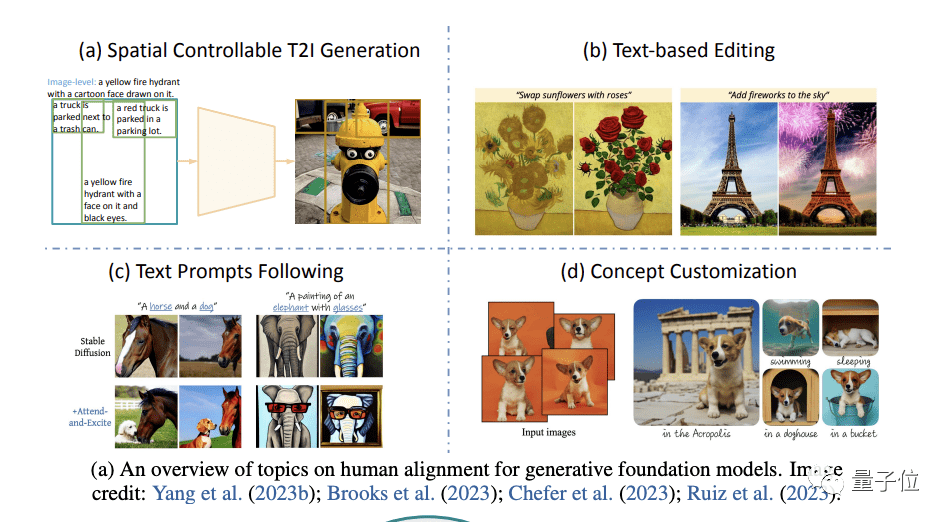
在本節最后,作者還分享了他們對當前研究趨勢和短期未來研究方向的看法。
即,開發一個通用的文生圖模型,它可以更好地遵循人類的意圖,并使上述四個方向都能應用得更加靈活并可替代。
同樣列出了四個方向的各自代表作:

3、統一視覺模型
這部分討論了構建統一視覺模型的挑戰:
一是輸入類型不同;
二是不同的任務需要不同的粒度,輸出也要求不同的格式;
三是在建模之外,數據也有挑戰。
比如不同類型的標簽注釋成本差異很大,收集成本比文本數據高得多,這導致視覺數據的規模通常比文本語料庫小得多。
不過,盡管挑戰多多,作者指出:
CV領域對于開發通用、統一的視覺系統的興趣是越來越高漲,還衍生出來三類趨勢:
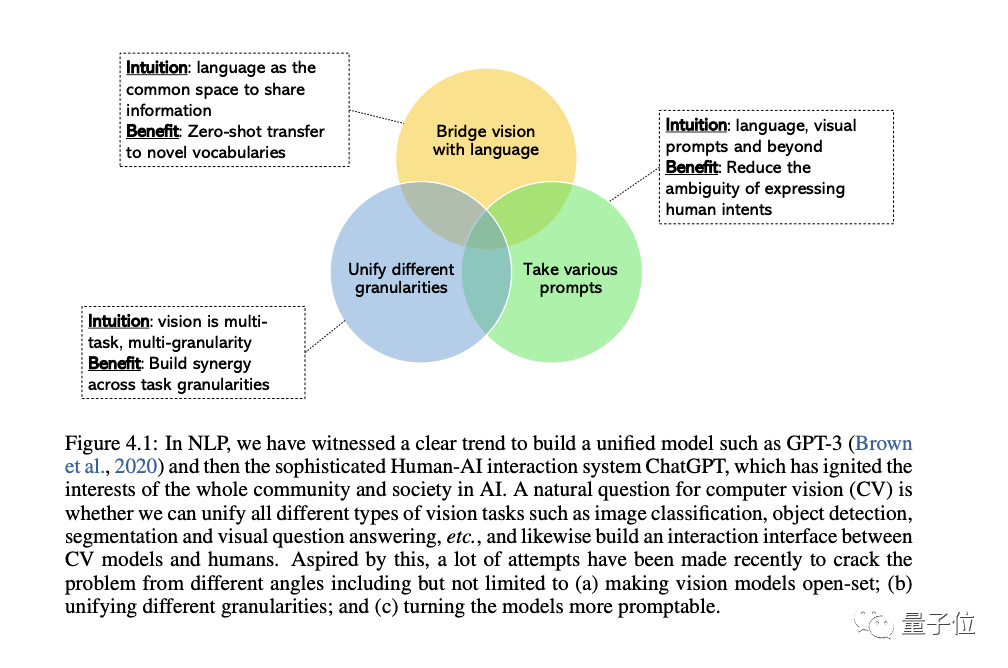
一是從閉集(closed-set)到開集(open-set),它可以更好地將文本和視覺匹配起來。
二是從特定任務到通用能力,這個轉變最重要的原因還是因為為每一項新任務都開發一個新模型的成本實在太高了;
三是從靜態模型到可提示模型,LLM可以采用不同的語言和上下文提示作為輸入,并在不進行微調的情況下產生用戶想要的輸出。我們要打造的通用視覺模型應該具有相同的上下文學習能力。
4、LLM加持的多模態大模型
本節全面探討多模態大模型。
先是深入研究背景和代表實例,并討論OpenAI的多模態研究進展,確定該領域現有的研究空白。
接下來作者詳細考察了大語言模型中指令微調的重要性。
再接著,作者探討了多模態大模型中的指令微調工作,包括原理、意義和應用。
最后,涉及多模態模型領域中的一些高階主題,方便我們進行更深入的了解,包括:
更多超越視覺和語言的模態、多模態的上下文學習、參數高效訓練以及Benchmark等內容。
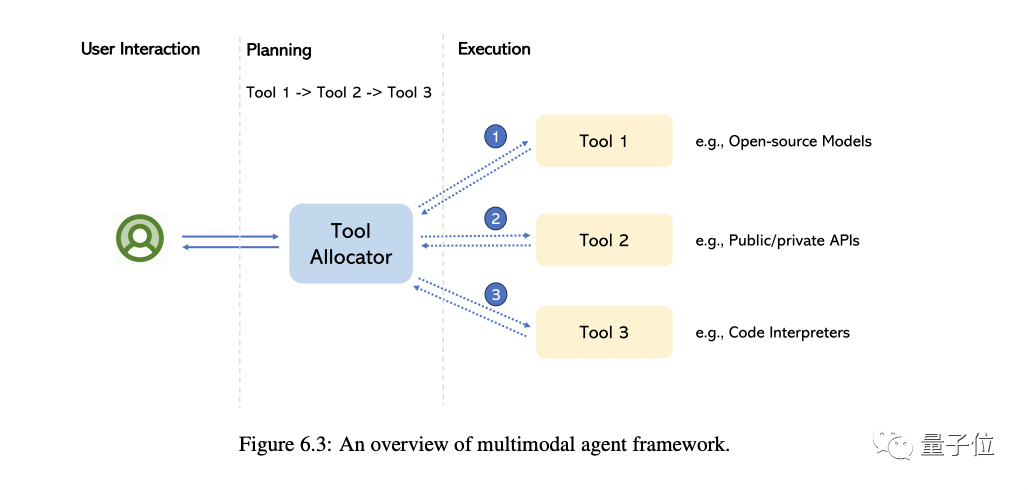
5、多模態agent
所謂多模態agent,就是一種將不同的多模態專家與LLM聯系起來解決復雜多模態理解問題的辦法。
這部分,作者主要先帶大家回顧了這種模式的轉變,總結該方法與傳統方法的根本差異。
然后以MM-REACT為代表帶大家看了這種方法的具體運作方式。
接著全面總結了如何構建多模態agent,它在多模態理解方面的新興能力,以及如何輕松擴展到包含最新、最強的LLM和潛在的數百萬種工具中。
當然,最后也是一些高階主題討論,包括如何改進/評估多多模態agent,由它建成的各種應用程序等。
作者介紹
本報告一共7位作者。
發起人和整體負責人為Chunyuan Li。
他是微軟雷德蒙德首席研究員,博士畢業于杜克大學,最近研究興趣為CV和NLP中的大規模預訓練。
他負責了開頭介紹和結尾總結以及“利用LLM訓練的多模態大模型”這章的撰寫。

核心作者一共4位:
- Zhe Gan
目前已進入Apple AI/ML工作,負責大規模視覺和多模態基礎模型研究。此前是Microsoft Azure AI的首席研究員,北大本碩畢業,杜克大學博士畢業。
- Zhengyuan Yang
微軟高級研究員,羅切斯特大學博士畢業,獲得了ACM SIGMM杰出博士獎等榮譽,本科就讀于中科大。
- Jianwei Yang
微軟雷德蒙德研究院深度學習小組首席研究員。佐治亞理工學院博士畢業。
- Linjie Li(女)
Microsoft Cloud & AI計算機視覺組研究員,普渡大學碩士畢業。
他們分別負責了剩下四個主題章節的撰寫。
綜述地址:
https://arxiv.org/abs/2309.10020
— 完—





