擊這里在線咨詢客服")
聲明:本文來自于微信公眾號 AIGC開放社區(qū)(ID:AIGCOPEN),作者:AIGC開放社區(qū),授權(quán)轉(zhuǎn)載發(fā)布。
備受關(guān)注的大語言模型,核心是自然語言的理解與文本內(nèi)容的生成,對于此,你是否好奇過它們究竟是如何理解自然語言并生成內(nèi)容的,其工作原理又是什么呢?
要想了解這個,我們就不得不先跳出大語言模型的領(lǐng)域,來到機(jī)器翻譯這里。傳統(tǒng)的機(jī)器翻譯方式,還是采用RNN 循環(huán)神經(jīng)網(wǎng)絡(luò)。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)是一種遞歸神經(jīng)網(wǎng)絡(luò),以序列數(shù)據(jù)為輸入,在序列的演進(jìn)方向進(jìn)行遞歸且所有節(jié)點(diǎn)(循環(huán)單元)按鏈?zhǔn)竭B接。
釋義來源:文心一言
就“我畫一幅畫”這句話而言,它會先將其拆分為“我”、“畫”、“一幅”、“畫”四個詞,然后遞進(jìn)式一個詞一個詞對這句話進(jìn)行理解翻譯,像是:
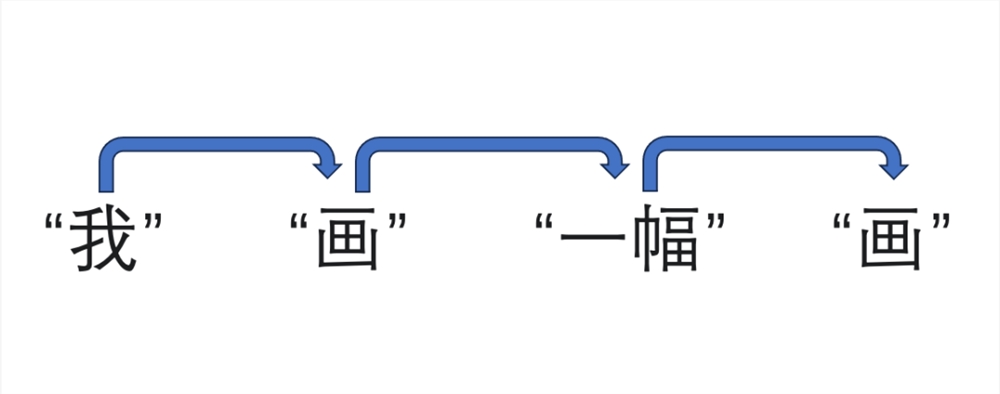
然后輸出:I have drawn a picture.
這種方式簡單直接,但因?yàn)?RNN 自身的線性結(jié)構(gòu)導(dǎo)致其無法對海量文本進(jìn)行并行處理,運(yùn)行緩慢,另外還會有“讀到后面忘了前面”,使 RNN 在處理長序列時會出現(xiàn)梯度消失或爆炸的狀況。
直到2017年,Google Brain 和 Groogle Research 合作發(fā)布了一篇名為《Attention Is All You Need》的論文,該論文為機(jī)器翻譯處理提供了一個嶄新的方式,同時起了一個與《變形金剛》相同的名字——Transformer。
Transformer 是一種神經(jīng)網(wǎng)絡(luò),它通過跟蹤序列數(shù)據(jù)中的關(guān)系來學(xué)習(xí)上下文并因此學(xué)習(xí)含義。該模型在2017年由 Google 提出,是迄今為止發(fā)明的最新和最強(qiáng)大的模型類別之一。
釋義來源:文心一言
Transformer 能對海量文本進(jìn)行并行處理,因?yàn)樗褂玫氖且环N特殊的機(jī)制,稱為自注意力(self-attention)機(jī)制。就像我們在進(jìn)行長閱讀時,大腦會依靠注意力選擇重點(diǎn)詞進(jìn)行關(guān)聯(lián),從而“略讀”后對文章更好的理解,該機(jī)制的作用就是賦予AI這項(xiàng)能力。
self-attention 是一種注意力機(jī)制,它通過對輸入序列進(jìn)行線性變換,得到一個注意力權(quán)重分布,然后根據(jù)這個分布加權(quán)輸入序列中的每個元素,得到最終的輸出。
釋義來源:文心一言
同樣還是“請注意垃圾分類”這句話,同樣是被分成“我”、“畫”、“一幅”、“畫”四個詞,在 Transformer 中它們會經(jīng)歷輸入、編碼器(encoder)、解碼器(decoder)、輸出四個階段。
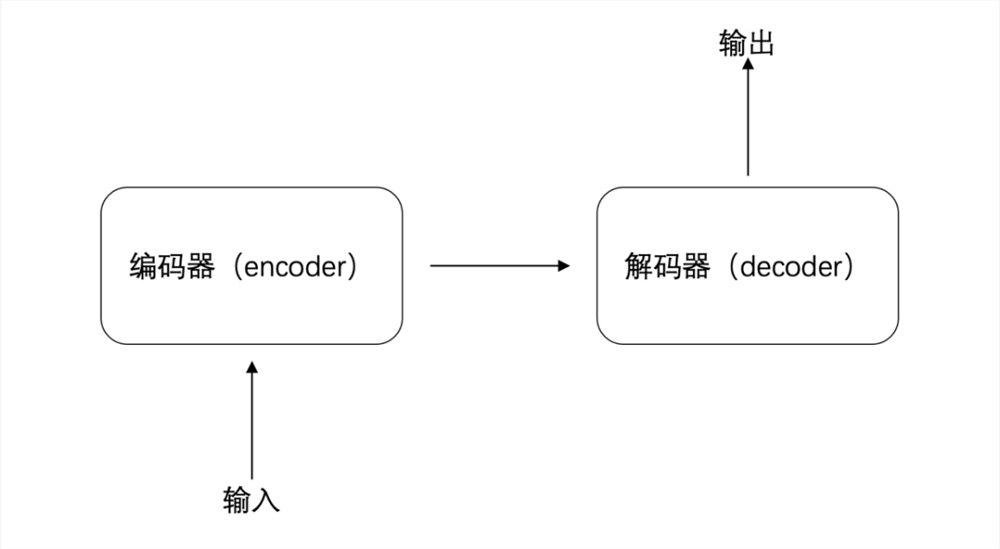
具體來看,當(dāng)句子拆解后輸入到編碼器(encoder)中,編碼器會先對每個詞的生成一個初始表征,可簡單理解為對每個詞的初始判斷,比如“畫”是名詞,也可以是動詞。
然后,利用自注意力(self-attention)機(jī)制計(jì)算詞與詞之間的關(guān)聯(lián)程度,可以理解為進(jìn)行打分,比方第一個“畫”與“我”的關(guān)聯(lián)程度高就給打6分,第二個“畫”與“一幅”的關(guān)聯(lián)也高打8分,“我”與“一幅”沒什么關(guān)聯(lián)就打-2分。
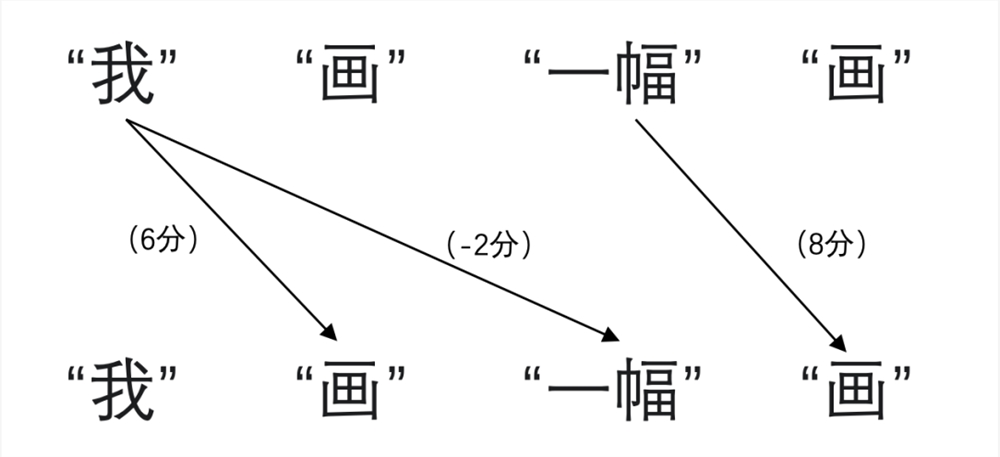
接著,根據(jù)打分對先前生成的初始表征進(jìn)行加工,第一個“畫”與“我”的關(guān)聯(lián)程度高,那就可以降低表征中對名詞詞性的判斷,提升動詞詞性的判斷;第二個“畫”與“一幅”的關(guān)聯(lián)程度高,那就可以降低表征中對動詞詞性的判斷,提升名詞詞性的判斷。
最后,將加工過的表征輸入到解碼器(decoder),解碼器(decoder)再根據(jù)對每個詞的了解結(jié)合上下文,再輸出翻譯。在這期間,每個詞與詞之間都可以同時進(jìn)行,大大提高了處理速率。
可這樣的 Transformer 和大語言模型有什么關(guān)系呢?
大語言模型本就是指使用大量文本數(shù)據(jù)訓(xùn)練的深度學(xué)習(xí)模型,而 Transformer 正好能為大量文本數(shù)據(jù)訓(xùn)練提供足夠的動力。另外,在加工過的表征輸入到解碼器(decoder)后,能依靠這些表征推斷下一個詞出現(xiàn)的概率,然后從左到右逐字生成內(nèi)容,在這個過程中還會不斷結(jié)合先前已生成的這個詞共同推斷。
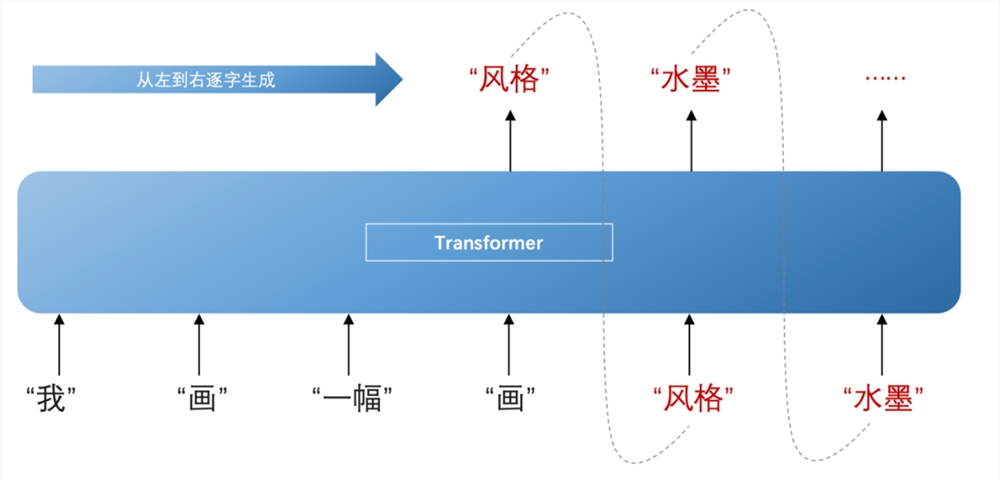
比如根據(jù)“一幅”、“畫”這兩個詞推斷出下一個詞是“風(fēng)格”的概率最大,再兼顧“一幅”、“畫”與“風(fēng)格”推斷下下個詞是“水墨”,以此類推再下下下個詞,下下下下個詞,這才有了我們看到的大語言模型的內(nèi)容生成。
這也是為什么大家普遍認(rèn)為,大語言模型的誕生起點(diǎn),就是 Transformer。
那么,Transformer 中最關(guān)鍵的自注意力(self-attention)機(jī)制是如何知道“打多少分”的呢?
這是一套比較復(fù)雜的計(jì)算公式:
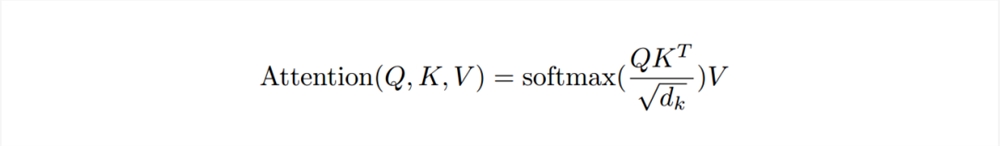
作簡單理解的話,可以想想數(shù)學(xué)課本上關(guān)于向量的知識,當(dāng)兩個向量 a 和 b 同向,a.b=lallb|;當(dāng) a 和 b 垂直,a.b=0;當(dāng) a 和 b 反向,a.b=-lallbl。
如果把這里的 a、b 兩個向量,看作是“我”、“畫”、“一幅”、“畫”四個詞當(dāng)中的兩個在空間中的投射,那 a 乘 b 的數(shù)值就是打分。
這個數(shù)值越大,兩個向量的方向越趨于一致,就代表著兩個詞的關(guān)聯(lián)程度大;
數(shù)值是0,那就是兩個向量垂直,同理詞之間就沒有關(guān)聯(lián);
數(shù)值是負(fù)數(shù),那兩個向量就是相反,兩個詞不但沒關(guān)聯(lián),還差距過大。
只是這是簡單理解,在現(xiàn)實(shí)中還需要一套紛繁復(fù)雜的計(jì)算過程,并且還需要多次的重復(fù),才能獲取到更加準(zhǔn)確的信息,確定每個詞符合上下文語境的含義。
以上就是大語言模型的工作原理了,強(qiáng)大 Transformer 的實(shí)用性還不止于在自然語言處理領(lǐng)域,包括圖像分類、物體檢測和語音識別等計(jì)算機(jī)視覺和語音處理任務(wù)也都有它的身影,可以說 Transformer 就是是今年大模型井噴式爆發(fā)的關(guān)鍵。
當(dāng)然,Transformer 再強(qiáng)也只是對輸入的處理過程,要想生成式 AI 生成的內(nèi)容更符合我們的需求,一個好的輸入是重要前提,所以下一期我們就來聊聊什么是好的輸入,Prompt 又是什么?





