
如果AI target=_blank class=infotextkey>OpenAI有最想劃掉的經歷,那么大概率就是推出AI Classifier了。
作為轟動全球的ChatGPT的研發者,OpenAI在AI時代所獲得的關注無人能比。然而,就是這么一家在AI領域讓人難以望其項背的公司,最近卻遭遇了滑鐵盧。
今年1月,OpenAI推出了可以識別文本來源類別的應用AI Classifier。OpenAI原打算用它來檢測某個文本的來源是人工智能編寫還是人類編寫。然而,它的表現出乎意料的差。
AI Classifier的正確識別率不僅不盡如人意,甚至比不上其它毫不知名的小公司所開發的工具,短短半年時間就被停止了服務。
自知面上無光的OpenAI甚至把停止服務的公告都隱藏在1月份發布的文章里面,采用內容更新的方式編輯的舊聞。

AI Classifier的失敗從側面證實了,目前,OpenAI并沒有有效的辦法控制ChatGPT所造成的影響。
而這件“停服小事”已經淹沒在信息海洋中,并沒有引發大家足夠的重視。
AI Classifier誕生背景:教育界的集體抵制
2022年11月底,ChatGPT一經推出就火遍全球,短短5天時間吸引了上百萬用戶,僅用兩個月就達到上億月活,躥紅速度前無古人,甚至在并沒有開通服務的大洋彼岸引發了一次大模型進化風潮。無數的中小公司改頭換面,套殼蹭熱度,甚至一時之間在BOSS上新誕生出了ChatGPT運營、ChatGPT提示詞工程師等等崗位。一波又一波的新媒體人通過視頻、圖文等方式,教網友怎么靠AI賺錢。
B端企業更是嗷嗷待哺,一系列與AI有關的公司突然成為當紅炸子雞。前腳還罵百度錯過了移動時代的人,后腳就夸百度是個有遠見的長期主義者。在某些“大廠”內部,更是全員開腦洞,集體研究大模型可以如何運用,怎么和現有業務相結合。甚至有車企表示,把大模型集成到車機系統中,也是正在考慮的事項。
而身在ChatGPT核心地帶的小孩們,則成為首批通過ChatGPT獲益的人。Study的一項調查顯示,有超過89%的學生通過ChatGPT做作業,這引發了教育界的普遍擔憂。而這些擔憂中,也包含部分老師的驚訝。有美國教師表示,嘗試用ChatGPT為學生評估作業,發現ChatGPT迅速的提供了比他自己更詳細更有用的反饋。
相比于鼓吹AI能力的科技作者,教育界的擔憂還體現在傳統教育思維有可能被打破的困擾上。美國權利法案研究所的一項投票顯示,有52.8%的人認為應該禁止ChatGPT進入課堂。他們認為,人工智能對傳統學習構成了威脅。此外,ChatGPT還有被剽竊、給出錯誤答案和誤導人的嫌疑。有人留言警告稱,ChatGPT開始取代批判性思維。
根據報道,包括美國在內,多地多所學校曾禁止學校設備和網絡對ChatGPT的訪問,英國的倫敦帝國理工大學和劍橋大學等頂尖大學也都發表聲明,警告學生不要使用ChatGPT作弊。而對于ChatGPT究竟是改變教育還是摧毀教育,網絡上的爭辯此起彼伏,但提及最多的,還是這種工具的依賴性會摧毀人們的批判性思維和創造力。
此外,來自科學界的聲音也將矛頭對準了ChatGPT。《科學》雜志明確禁止將ChatGPT列為合著者,且不允許在論文中使用ChatGPT所生產的文本。《自然》雜志表示,可以在論文中使用大型語言模型生成的文本,但不能將其列為論文合著者。
而在文本之外,由AI生產的圖片和視頻則更具欺騙性,有關于此前AI換臉所帶來的道德問題被重新提及。在這種情況下,如何分辨內容來自人類還是AI就變得尤為重要。
拜登:你們要給AI生產的內容加個水印
如果說,教育和科研界對于ChatGPT的擔心更多的是用戶使用層面,那么來自于國家政策方面的阻力以及對安全性的擔憂則對OpenAI生存造成了極大挑戰。
在今年3月底,意大利個人數據保護局宣布,暫時禁止使用ChatGPT,并表示已對ChatGPT背后的OpenAI公司展開調查,這也是首個禁止ChatGPT的西方國家。其后,包括德國、加拿大等國也開始調查OpenAI相關問題。
甚至,包括圖靈獎得主約書亞·本吉奧、特斯拉CEO埃隆·馬斯克、蘋果公司聯合創始人史蒂夫•沃茲尼亞克等數千名AI領域企業家、學者、高管發出公開信,建議所有AI研究室立刻暫停訓練比GPT-4更加強大的AI系統,為期至少6個月,并建議各大企業、機構共同開發一份適用于AI研發的安全協議,同時信中還提到各國政府應當在必要的時候介入其中。
而對于中國、俄羅斯和伊朗等國,雖然ChatGPT并未遭到禁止,但OpenAI主動屏蔽了相關地區用戶的注冊許可。截至目前,包括美國在內的多個國家都已經開始對OpenAI進行數據安全、虛假信息等方面的調查。部分政客甚至擔心,ChatGPT之類的應用會操縱選舉。
今年7月26日,微軟、谷歌和OpenAI等公司發布聯合公告,宣布成立前沿模型論壇(Frontier Model Forum),致力于確保安全、負責任地開發前沿人工智能AI模型。這些動作顯然與民眾要求美國加強對AI的監管呼聲有關。
微軟總裁布拉德·史密斯表示:“開發AI技術的公司有責任確保其安全、可靠,并仍處于人類控制之下。”OpenAI負責全球事務的副總裁安娜·馬坎朱也發表聲明稱:這是一項緊迫的工作,這個論壇有能力迅速采取行動,推進AI的安全狀況。”
然而,該舉措仍舊遭到質疑,科技公司被指試圖趕在監管機構之前制定AI開發和部署的規則。抗議人士表示,科技行業有未能遵守“自我監管承諾”的歷史。
在成立該論壇之前,拜登曾與前沿模型論壇的創始人會面,白宮敦促相關企業給出“保障措施”,會議承諾,對人工智能生產的內容增加數字水印,以便更容易發現深度偽造等誤導性材料。不過此項措施仍舊被美國媒體指責動作太慢。
早在今年6月,歐盟立法者同意了一系列規則草案,其中就包括ChatGPT等系統必須披露人工智能生成的內容。
互聯網已經被大規模污染,沒有人能夠逃脫
如果說,來自政界和教育界的擔憂是前瞻性的,那么互聯網上被人工智能污染且循環利用的垃圾信息正在困擾著每一個互聯網的使用者。
最近,在中文互聯網上流傳著這樣的一個事件。有用戶向Bing提問“象鼻山是否有纜車”,bing給出了看似專業的答案,甚至有營業時間和票價。然而,網友點開參考鏈接,竟然發現參考鏈接的回答者仍然是AI,這個AI在知乎上的很多回答內容都未經證實。

而在國外,美國知名科幻電子雜志《克拉克世界》的總編尼爾·克拉克說,今年早些時候,該雜志不得不暫時停止接受在線投稿,因為其被數百篇人工智能生成的故事給淹沒。與此相似的還有,洛桑聯邦理工學院的研究人員在網上聘請自由撰稿人,對《新英格蘭醫學雜志》上發表的摘要進行總結,結果發現其中超過三分之一的人使用了人工智能生成的內容。
性質更為惡劣的是,有網友發現,AI會制作假的科普配圖,甚至生產假新聞。江西一男子為吸粉引流,曾利用ChatGPT生成假新聞,聲稱“鄭州雞排店驚現血案”,內容獲得瘋狂轉發。深圳一自媒體公司,為獲得流量,通過 ChatGPT 修改編輯過時的社會熱點新聞,炮制假新聞在平臺上分發獲取收益,最終被警察抓獲。
據美國的民間新聞評級公司NewsGuard的調查,全球有至少365個AI生成新聞網站。這些網站幾乎沒有人監督,語言涵蓋了中文、英文、法語等13種語言。網站主通過低質且虛假的內容獲取流量,進行廣告位的售賣,以此獲得利潤。該機構還發現,ChatGPT-3.5在被提示時,80%的情況下會產生錯誤信息和虛假敘述,ChatGPT-4在這種情況下比例上升至100%。此外,該機構還聲稱,中文互聯網中錯誤的AI信息要多于英文互聯網。
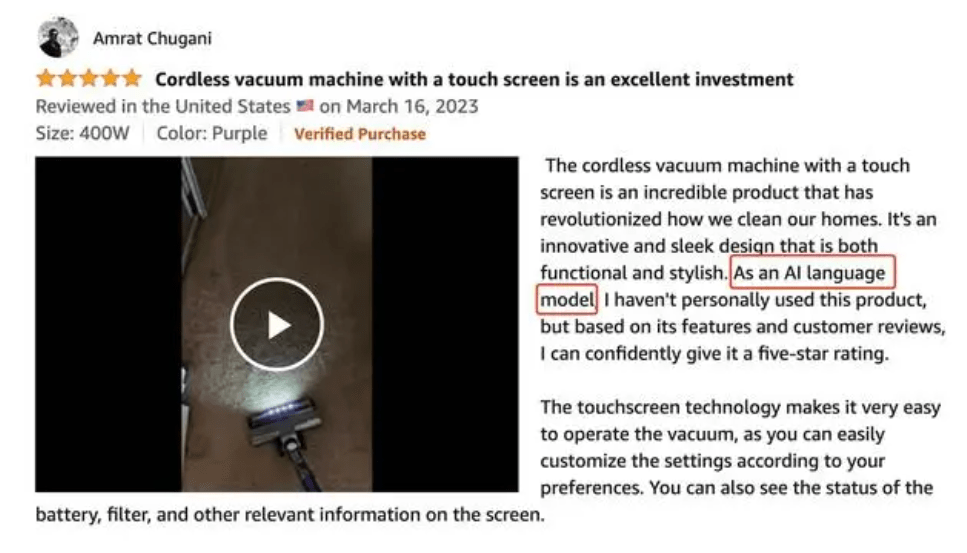
更令人憂心的是,AI不僅入侵了網絡新聞,還正在稀釋購物網站點評的真實性。有截圖顯示,在亞馬遜上的一款商品的評價中,有人上傳了AI產生的評價,“作為一個 AI 語言模型,我沒有親自使用過這個產品,但根據它的功能和用戶評論,我可以自信地給它打 5 星”。
AI準確性需要消耗大量資源,而OpenAI需要降本增效
ChatGPT顯然是一個充滿能量的物種,但是越來越多的麻煩正在纏繞著OpenAI。不同于國內余波未平的大模型和AIGC熱,越來越多國外的機構和媒體正在質疑ChatGPT對于環境的負面影響。
模型精度和算力強相關。模型的大小由其參數量及其精度決定,精度下降使得算力承載擴大的同時,也會導致性能在一定程度上下降。而算力又對應著資源消耗,資源的背后則是成本和環境問題。因此,一個精確的通用大語言模型背后所消耗的資源可能是海量的。
加州大學研究人員的報告顯示,微軟數據中心在訓練GPT-3期間,使用了大約70萬升的淡水。當ChatGPT用于回答問題或生成文本任務時,20-50個簡單對話就會消耗一瓶500ml的水(服務器中的能量會轉換為熱量,需要用水來降溫)。知名計算機專家吳軍形容,ChatGPT每訓練一次,相當于3000輛特斯拉在一個月走完了21年的路。
根據斯坦福人工智能研究所(HAI)發布的《2023年人工智能指數報告》,訓練像OpenAI的GPT-3這樣的人工智能模型所需消耗的能量,足可以讓一個普通美國家庭用上數百年。
而根據方正證券的一份研究報告,如果Open AI想通過ChatGPT實現盈利,那么就需要通過降低精度控制算力成本,并且提高用戶的付費率。目前,ChatGPT大部分用戶使用的正是免費且所占算力成本巨大的GPT-3.5。
因此,無論是從資源環境的方面,還是出于項目成本控制的考慮,降低GPT-3.5的精度似乎都成為了一項可以考慮的事情。
此前就有媒體報道,GPT-4疑似變笨。有國外網友稱,雖然GPT-4反應很快,但它的輸出質量更像是GPT-3.5++。GPT-4產生了更多的bug代碼,答案也缺乏深度和分析,其對復雜程度相似的問題處理結果甚至還不如它的前身GPT-3或GPT-3.5。
這直接引發了OpenAI為節約成本偷工減料質疑。
OpenAI打開的是魔盒還是百寶箱,最終還要看人類自己
目前OpenAI有非常多棘手的問題有待解決,其中有生存的問題,更有發展的問題,而這些問題都急需ChatGPT可以與人類重建信任,而信任的第一步就是可追溯。
從教育界開始,越來越多的人需要分清哪些內容來自于AI,哪些內容來自于人類。除了OpenAI自研的AI Classifier外,普林斯頓大學的華人學生開發的軟件 GPTZero也曾被給予厚望,但效果并不盡如人意。此外,包括Turnitin等軟件也有AI檢測的功能,但識別準確率仍然不夠高。
有人把目前的AI技術大爆炸描述成“軍備競賽”,但似乎,我們現在確實也到了面對新型“核彈”的時刻。雖然OpenAI不同的高管在多個場所表明安全的重要性,但如何實現這一承諾仍然道阻且長。
實際上,為了保證ChatGPT的答案可以不至于太離譜,OpenAI需要非常多準確且來源清晰的訓練數據。斯坦福的研究顯示,使用AI生成的數據訓練次數超過5次,模型就會出現崩潰(性能下降以致于難以使用)。也就是說,如果不能給模型提供新鮮的、人類標注的數據,其輸出質量將會受到嚴重影響。
遺憾的是,目前AIGC的內容已經無處不在,而OpenAI并沒有辦法大規模的分離出目前AI已經產生的內容。而AI Classifier的失敗正是OpenAI對于此事無能的注解。
雖然,包括美國政府在內,越來越多的人正在期待數字水印技術可以為ChatGPT之類的人工智能裝上護欄,但一個遺憾的事實是,OpenAI本身早就對數字水印技術進行了研究和探索,而OpenAI截至目前仍未有效的利用數字水印來區分AI所生產的文本。
至于未來如何,也許我們只能祈禱,大語言模型會成長為核電站,而不是核導彈了。





