

新智元報道
編輯: Lumina 桃子
【新智元導讀】清華與微軟合作提出了一種全新「思維骨架」(SoT),大大減少了LLM回答的延遲,并提升了回答的質量。
由于當前先進的LLM采用了順序解碼方式,即一次生成一個詞語或短語。
然而,這種順序解碼可能花費較長生成時間,特別是在處理復雜任務時,會增加系統的延遲。
受人類思考和寫作過程的啟發,來自清華微軟的研究人員提出了「思維骨架」(SoT),以減少大模型的端到端的生成延遲。

論文地址:https://arxiv.org/pdf/2307.15337.pdf
SoT引導LLM,首先生成答案的骨架,然后進行并行API調用或分批解碼,并行完成每個骨架點的內容。
SoT不僅大大提高了速度,在11個不同的LLM中可達2.39倍,而且還可能在多樣性和相關性方面提高多個問題類別的答案質量。
研究人員稱,SoT是以數據為中心優化效率的初步嘗試,揭示了推動LLM更像人類一樣思考答案質量的潛力。
SoT,讓大模型并行解碼
目前,最先進的LLM的推理過程依舊緩慢,交互能力大大減分。
對此,研究人員總結出LLM推理慢的3個主要原因:
- 大模型需要大量內存,內存訪問和計算。
比如,GPT-3的FP16權重需要350 GB內存,這意味著僅推理就需要5×80GB A100 GPU。即使有足夠多的GPU,繁重的內存訪問和計算也會降低推理(以及訓練)的速度。
- 主流Transformer架構中的核心注意力操作受I/O約束,其內存和計算復雜度與序列長度成二次方關系。
- 推理中的順序解碼方法逐個生成token,其中每個token都依賴于先前生成的token。這種方法會帶來很大的推理延遲,因為token的生成無法并行化。
先前的研究中,大多將重點放在大模型規模,以及注意力操作上。
這次,研究團隊展示了,現成LLM并行解碼的可行性,而無需對其模型、系統或硬件進行任何改動。
研究人員可以通過Slack使用Claude模型將延遲時間從22秒,減少到12秒(快了1.83倍),通過A100上的Vicuna-33B V1.3將延遲時間從43秒減少到16秒(快了2.69倍)。
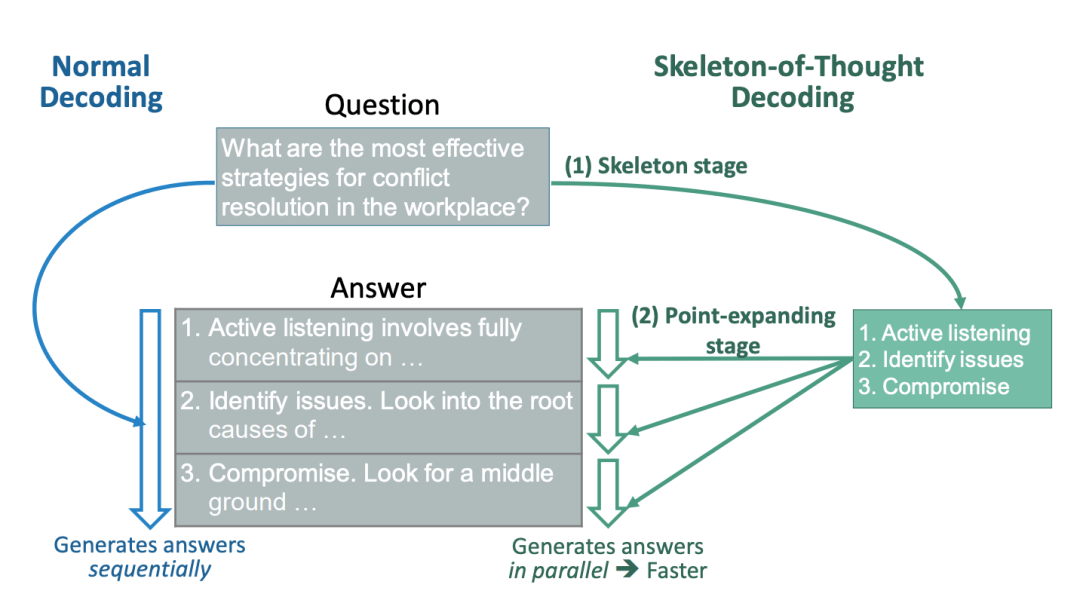
這個想法,來源于對人類自身如何回答問題的思考。
對于我們來講,并不總是按順序思考問題,并寫出答案。相反,對于許多類型的問題,首先根據一些策略推導出骨架,然后添加細節來細化和說明每一點。
那么,這一點在提供咨詢、參加考試、撰寫論文等正式場合中,更是如此。
我們能夠讓LLM以同樣的方式思考嗎?
為此,研究人員提出了「思維骨架」(SoT)。具體來說,引導LLM首先自己推導出一個骨架。

在骨架的基礎上,LLM可以并行地完成每個點,從而提高速度。SoT既可用于加速分批解碼的開源模型,也可用于加速并行API調用的閉源模型。
最后,研究人員在最近發布的11個LLM上測試SoT。
結果顯示,SoT不僅提供了相當大的加速度(最高可達2.39倍) ,而且它還可以在多樣性和相關性方面提高幾個問題類別的答案質量。
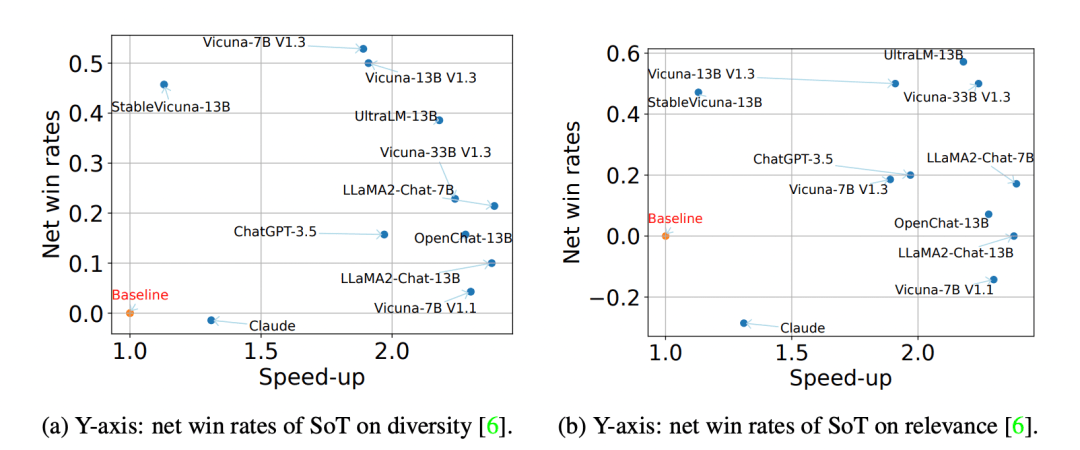
在vicuna-80的所有問題中,SoT的凈勝率和與正常一代相比的速度
SoT框架
- 骨架階段。
SoT首先使用骨架提示模版
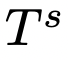
,以問題q為參數,組裝一個骨架請求。編寫骨架提示模板是為了引導LLM輸出簡潔的答案骨架。然后,研究人員從LLM的骨架答案
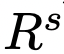
中提取B點。
- 點擴展階段
基于骨架,讓LLM在每個點上平行展開。
具體地說,對于帶有索引b和骨架
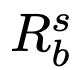
的點,SoT使用作為LLM的點擴展請求,其中
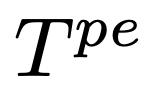
是點擴展提示模板。最后,在完成所有的點之后,研究人員連接點擴展響應來得到最終的答案。
如下,Prompt 1和 Prompt 2顯示了,研究人員當前實現使用的骨架提示模板
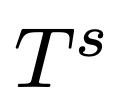
和點擴展提示模板
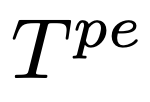
。


- 骨架提示模板。為了使輸出的骨架簡短且格式一致,以提高效率和便于提取要點,骨架提示模板(1)精確描述了任務,(2)使用了兩個簡單的示范,(3)提供了部分答案「1」為LLM繼續寫作。
- 點擴展提示模板。點擴展提示模板描述點擴展任務,并提供部分答案。研究人員還提供了指示「在1ー2個句子中非常簡短地寫出」的說明,以便LLM使答案保持簡潔。
- 并行點擴展。對于只能訪問API的專有模型可以發出多個并行的API調用。對于開源模型,讓模型將點擴展請求作為批處理。
為什么SoT降低了解碼延遲?
首先要對SoT為什么能夠帶來顯著的端到端加速有一個高層次的理解。為了簡單起見,在這里集中討論點擴展階段。
具有并行API調用的模型。普通方法向服務器發送一個API請求,而 SoT 并行發送多個 API 請求以獲得答案的不同部分。
根據經驗,研究人員觀察到,在論文中使用的API的延遲與響應中的token數呈正相關。如果請求數量沒有達到速率限制,SoT顯然會帶來加速。
采用批量解碼的開源模型。普通的方法只處理一個問題,并按順序解碼答案,而SoT處理多個點擴展請求和一批答案。
實驗結論
實驗數據集:使用Vicuna-80數據集,它由跨越9個類別的80個問題組成,如編碼、數學、寫作、角色扮演等。
模型:對11個最近發布的模型進行SoT測試,其中包括9個開源模型和2個基于API的模型)。
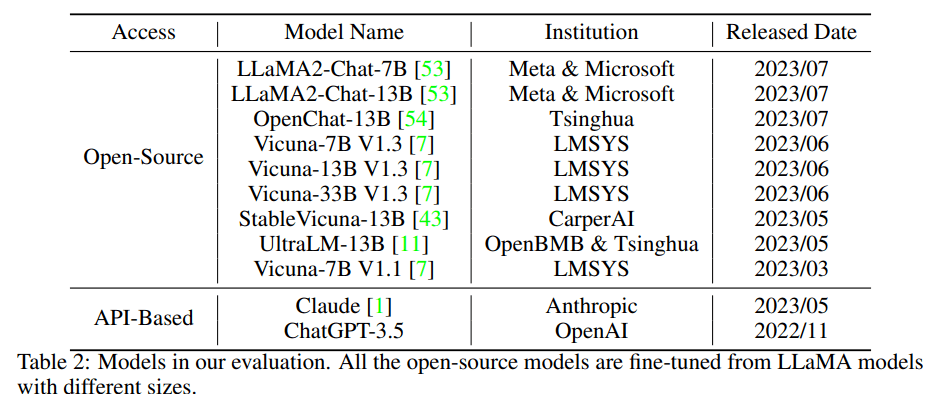
評估的模型,所有的開源模型都是根據不同大小的LLaMA模型進行微調的
效率評估:
1. SoT減少不同模型上的端到端延遲
圖4a顯示了應用SOYT后,每個模型在所有問題類別中的平均加速。
應用SoT后,11個模型中,有6個模型速度有2倍以上的提升(即LLaMA2-Chat-7B,LLaMA2-Chat-13B,Vicuna-7B V1.1,OpenChat-13B,Vicuna-33B V1.3,UltraLM-13B)。
在ChatGPT-3.5,Vicuna-13B V1.3和Vicuna-7B V1.3上則有1.8倍以上的速度提升。
但在StableVicuna-13B和Claude中,速度幾乎沒有提升。
如果排除數學和代碼的問題類別,速度提升會較排除前略高,如圖4b所示。
2. SoT減少不同類別問題的端到端延遲
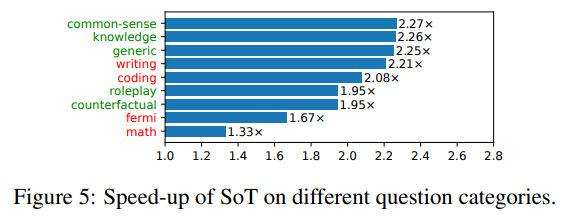
圖5顯示了每個問題類別在所有模型中的平均速度提升。
那些SoT能夠提供高質量答案的問題類別標記為綠色,不能的其他問題類別標記為紅色。
當前的SoT已經可以提升所有類別問題的速度。
但對于那些SoT可以提供高質量答案的5個問題類別(即知識、常識、通用、角色扮演、虛擬情景),SoT可以將整體答案生成過程加速1.95倍-2.27倍。
3. SoT和正常生成的延遲對比
圖6顯示了模型正常生成和SoT生成的絕對延遲的比較。與正常生成相比,應用SoT的模型生成的速度提升是顯而易見的。
而解碼階段是內容生成端到端延遲的主要原因。
因此,盡管SoT在骨架階段比正常生成具有較高的預填充延遲,但這對總體延遲和總體速度提升幾乎沒有影響。
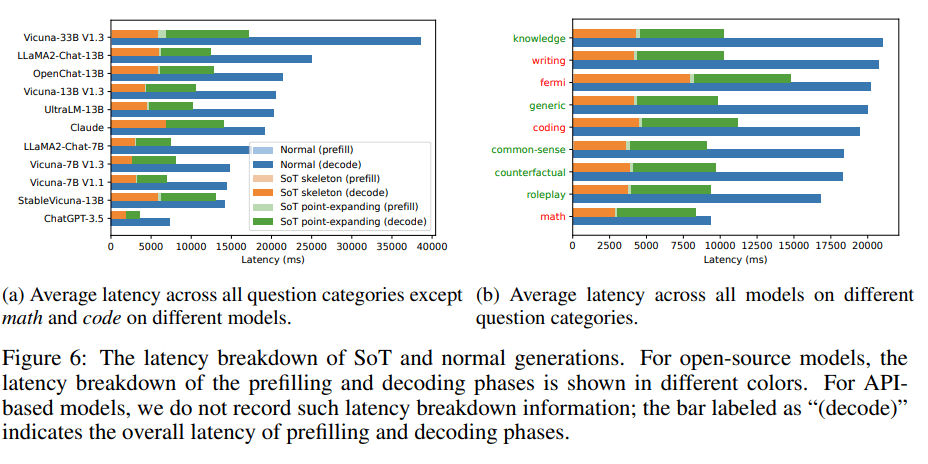
SoT和正常生成的延遲對比。對于開源模型,預填充和解碼階段的延遲分解以不同的顏色顯示。對于基于API的模型,研究不記錄此類延遲分解信息:標記為「decode」的柱狀圖表示預填充和解碼階段的整體延遲。
質量評估:
為了比較正常的順序生成(以下簡稱為正常)和SoT生成的答案質量,研究采用了兩個基于LLM的評估框架: FastCha和LLMZoo。
評估過程是向LLM評判器(本研究中為ChatGPT-3.5)展示一個問題和一對答案(由正常和SoT生成),并詢問其偏好。
回答可能是SoT的答案勝出、與正常答案并列、輸給正常答案。
1. 整體質量:
圖7顯示了使用FastChat和LLMZoo兩個指標下使用SOT的模型在所有問題下的贏/平/輸率。
在SoT嚴格優于基線時,兩個指標之間存在差異(49.0% vs.10.4%)。
但這兩個指標都認為,在超過76%的情況下,SoT并不比基線(正常生成)差。
對于FastChat指標,研究人員還展示了排除數學和編碼問題(SoT不適用于這些問題,請參見3.2.2節)的比率:
在超過90%的情況下,SoT與基準相當。這表明SoT的答案保持著良好的質量。
使用FastChat和LLMZoo的「基準」,SoT相較于正常生成,在大約80%的情況下表現更好或者相當。
2. SOT在不同類別問題上的表現
圖8計算了所有問題類別的凈勝率(勝率-敗率)。
與圖7類似,LLMZoo指標下SoT的質量比FastChat的更好。
但不論在哪個框架指標下,SoT在泛型、常識、知識、角色扮演和反事實方面的表現都相對較好,而在寫作、費米問題、數學和編碼方面表現相對較差。
研究人員調查了如下一些問題的答案,并總結了下面的發現。
凈勝率低的類別
數學
數學問題需要循序漸進的思考。如果不知道前面的步驟,很難推導出下面的步驟。SoT強調擴展順序思考步驟,以成功解決這些問題的重要性。
相比之下,SoT要求模型首先提出解決方案的框架,不參考以前的結果獨立地推斷每個單獨的步驟。
這兩個都是具有挑戰性的任務。
強模型能夠得到(a)正確,但在(b)失敗。
在下面的例子中,ChatGPT-35得到了正確的框架步驟。然而,在不知道第一步的結果的情況下,模型開始在第二步犯錯誤。

對于較弱的模型,步驟(a)甚至都很難達到正確的標準。例如,如下圖所示,在 Vicuna-13B V1.3的 SoT 解決方案中,第三步「應用箔片」是突然出現的。
這使 SoT 的解決方案并不正確(盡管普通代的解決方案也不正確)。

編碼
在大多數情況下,模型能夠在框架階段將編碼問題分解為較小的任務,但是在論點擴展階段的生成質量很差。
這可能是由于研究人員沒有仔細地為編碼設計一個特殊的點擴展提示符。
在某些情況下,模型只生成一個描述,說明如何在不給出代碼的情況下完成實現。


寫作
寫作問題通常是寫一封電子郵件,一篇博客文章,或者一篇給定場景下的評論。
在FastChat和LLMZoo的詳細評估結果中,最主要也是最常見的抱怨是SoT的回答不夠詳細。但這一點可以通過要求更多細節的點擴展提示得到改善。

凈勝率高的類別
反事實,知識,常識,通用
所有這四個類別都有相同的特征:理想的答案應該包括幾個相對獨立的點。
在擴展細節之前,讓LLM生成一個框架可以對這個問題進行更全面的討論。
此外,將答案組織成一個點的列表使得答案更容易閱讀,而普通生成的答案有時結構化程度較低,可讀性較差。




角色扮演

總結以上內容,可以得出:
如果提問問題可以從多個論點出發,并且這些論點的細節可以獨立擴展,SoT的表現十分良好。
但如果是需要逐步思考的問題,比如數學問題,SoT就很難發揮作用。
為了能在更廣泛的問題中通用SoT,一個可行的途徑是使SoT根據問題自適應地退回到1階段的順序生成,而不觸發點擴展。
研究中的一些結果表明,某些LLMs已經能夠偶爾在沒有特殊提示或調整的情況下實現這一點。
質量分解: 模型
接下來,團隊還研究了SoT在不同模型上的性能,計算了圖9中所有模型的凈贏率。
同樣,團隊看到FastChat和LLMZoo的兩個通用指標具有不同的絕對值,但排名相似。
特別是,這兩個指標都認為OpenChat-13B、Vicuna-7B V1.1、Claude、chatgpt-3.5的凈勝率較低,而Vicuna-13B V1.3、 StableVicuna-13B 和 UltraLM-13B的凈勝率較高。
凈勝率低的模型
OpenChat-13B和Vicuna-7B V1.1。
對于較弱的模型,如OpenChat-13B和Vicuna-7B V1.1,他們不能精確地跟隨SoT提示。OpenChat-13B中框架有時包含著不想要的內容。

對于OpenChat-13B和Vicuna-7B V1.1,在回答需要細節的時候,它們偶爾不會在點擴展階段寫出任何東西。
凈勝率高的模型。高凈勝率的模型(Vicuna-13B V1.3,StableVicuna-13B 和 UltraLM-13B)介于上述兩個極端之間。
研究得出,對于能夠理解SoT提示的模型,答案的質量可能會得到提高。
研究團隊期望能進一步改進SoT提示或微調模型,使LLM更容易理解框架和論點擴展的提示,最終獲得更好質量的答案。
質量分解:度量
所有以前的評估都使用關于答案總體質量的度量標準。
在圖10中,研究人員顯示了來自LLMZoo的更詳細的指標,以揭示SoT在哪些方面可以改善或損害答案質量。
平均而言,可以看到SoT提高了多樣性和相關性,同時損害了沉浸感和一致性。
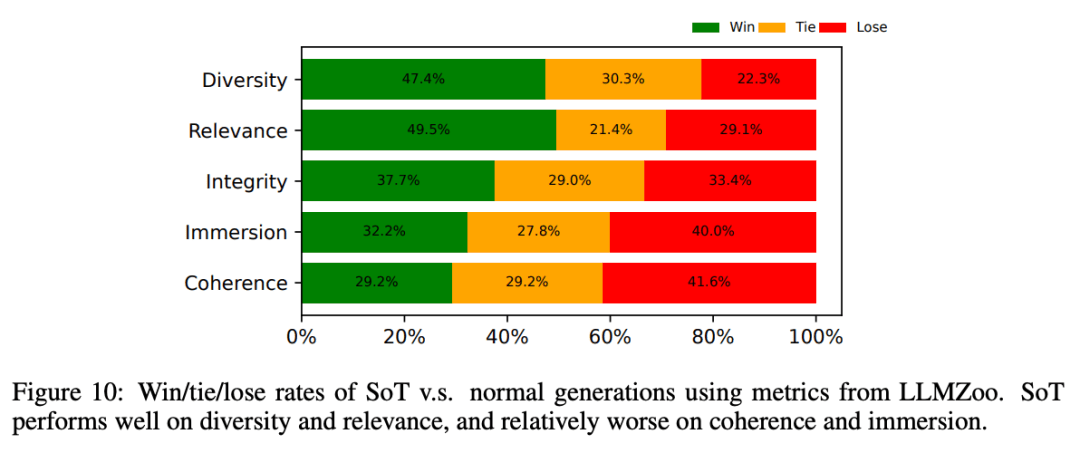
使用LLMZoo的指標,SoT相對于正常生成在多樣性和相關性方面表現良好,而在連貫性和沉浸感方面相對較差。
總的來說,SoT鼓勵LLMs直接從多個方面討論答案,而無需使用填充詞。
盡管回答會有一定程度的連貫性和沉浸感的損失,但SoT大大改善了答案的多樣性和相關性。
然而,在回答的連貫性和沉浸感方面,大約60%的情況下SoT的生成也不比正常生成差。
更多細節參考論文。
局限性
由于提示集的限制、現有LLM判斷的偏差,以及LLM屬性評價的內在困難,研究人員目前對LLM問題的答案質量的評價還遠不全面。
對更可靠的質量評價而言,擴展提示集,以及用人工評價補充基于LLM的評價非常重要。
然而,目前的研究主要集中在揭示潛在的效率效益上,即通過重新思考現有LLM「全序列解碼」的必要性,可以實現相當大的加速。
因此,研究人員在最后將對答案質量的更徹底的評估留給了未來的工作。
參考資料:
https://arxiv.org/pdf/2307.15337.pdf





