
作者|柯維鴻
編輯|鄧艷琴
在 5 月底舉辦的 QCon 全球軟件開發大會(廣州站)2023 中,網易互娛數據與平臺服務部數據服務組離線業務負責人、網易游戲技術專家柯維鴻分享了題為《?易互娛大數據平臺出海上云架構設計與實踐》,介紹了網易互娛如何通過對存儲、算力、數據分層等優化后的云上大數據平臺,給游戲數據業務出海節省了大量成本,存儲成本為優化前的 50%,算力總成本為優化前的 40%,冷數據成本為優化后線上存儲成本 33%。本文由 JuiceFS 社區(公眾號 ID:Juicedata)根據演講整理。
完整 PPT 下載:
https://qcon.infoq.cn/2023/guangzhou/presentation/5269
JuiceFS Github 地址:
https://github.com/juicedata/juicefs
2020 年初,隨著網易互娛的海外業務增長與海外數據合規的需求,我們開始了網易互娛大數據離線計算平臺遷移出海的工作。前期,我們采取了云主機裸機加上高性能 EBS 塊存儲的方案。但是,這個方案存儲費用高昂,成本是國內自建機房的數十倍。于是,我們決定在公有云上構建一個平臺,這個平臺不僅需要更加適應當前業務場景、與歷史業務更為兼容,還要比公有云的 EMR 托管方案更為經濟。我們主要從存儲、計算和數據分層生命周期管理三方面進行了成本優化,具體的優化方案將在下文為大家詳細介紹。
最終,這個項目給下游數據業務和分析部門提供了完整 Hadoop 的兼容性,避免了所有業務邏輯推倒重來;給游戲數據業務出海節省了大量成本,存儲成本為優化前的 50%,算力總成本為優化前的 40%,冷數據成本為優化后線上存儲成本的 33%。未來隨著業務量的增加,成本節約按 10 倍比例節約相應的費用,為出海后的數據化運營等提供有力支持。
01. 大數據平臺海外上云方案設計
在 2020 年,我們開始了一項緊急的出海任務。在國內,我們的業務一直以自建集群的方式進行部署和運行。為了在海外能夠快速上線,我們緊急上線了一個與國內集群完全相同的解決方案,采用了物理節點構建的一套存算一體的系統。我們選用了裸金屬服務器 M5.metal,并使用 EBS gp3 作為存儲。
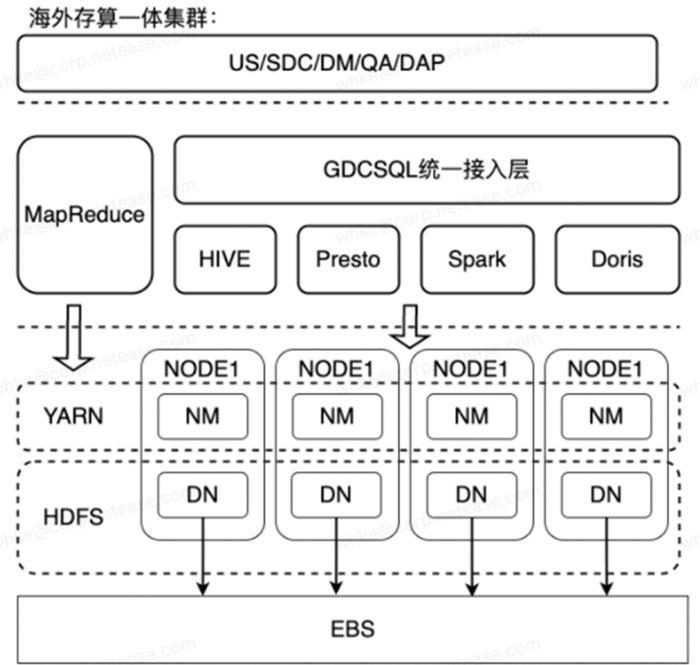 (海外存算一體集群)
(海外存算一體集群)
這套方案的缺點是成本非常高昂,但是它的好處是解決了一個非常痛苦的問題,即我們需要兼容所有歷史業務,確保所有歷史業務能夠快速、立即地在海外運行。我們的上下游業務可以無縫遷移到海外,并支持每天接近 30 萬個作業的調度。
但是,成本一直是一個不能忽視的問題。因此,我們需要重新選擇方案,以獲得性能更優、成本更低的解決方案,并確保兼容性。根據業務需求和大數據場景的特點,我們從以下幾個方向評估如何進行方案選擇:
-
以時間 / 空間換性能;
-
基于業務場景的實現部署優化;
-
加入中間件實現兼容性的整合;
-
充分利用云資源的特性優化成本。
Hadoop 上云
一般 Hadoop 上云有下面兩種方案,EMR+EMRFS、Dataproc+GCS。這兩種方案就是一個正常出海的姿勢。或者使用一些云原生的平臺,例如 BigQuery、Snowflake,Redshift 等做數據查詢方案,但是我們沒有去用這些方案。
為什么沒有使用 EMR
因為我們所有的業務都非常依賴 Hadoop,我們目前使用的 Hadoop 版本是根據業務需求定制的內部版本,并實現了各種新版本功能向下兼容,有很多內部的需求和優化在 EMR 的 Hadoop 版本未能覆蓋。至于云原生的 BigQuery 等方案對業務來說,是一個改動更大更遙遠的方向。
為什么沒有直接使用 S3 存儲
由于對數據業務安全的高需求導致我們有復雜的業務權限設計,遠超亞馬遜 IAM(Identity and Access Management)ROLE 能夠實現的上限。
S3 的性能受限,需要分桶和隨機目錄等優化措施,對業務使用不透明,調整目錄 prefix 去適配 S3 分區或使用更多的桶的方案都需要業務調整已有的使用方法,無法適配我們目前的目錄設計。另外,作為對象存儲實現的文件系統,直接對 S3 的目錄進行 list 和 du 等操作在超大文件數據情況下,基本上是不可用的,但是這又恰好是大數據場景下大量使用的操作。
存儲選型:HDFS vs 對象存儲 vs JuiceFS
我們主要從以下這些維度來評估存儲組件。
業務兼容性:對于我們這種擁有大量存量業務需要出海的情況,兼容性是一個非常關鍵的考慮因素。其次,降本增效不僅僅指降低存儲成本,還包括資源成本和人力成本的考慮。兼容性方面,JuiceFS 社區版兼容 Hadoop 生態,但需要在用戶端部署 JuiceFS Hadoop SDK。
一致性:在當時,我們對 S3 進行了調研,但在 2020 年第一季度之前,并沒有實現強一致性,而目前也并非所有平臺都能做到強一致性。
容量管理:對于我們當前自建的集群,有一個重要的問題是需要預留資源。也就是說,我們不可能使用到 100% 的資源,因此按需使用是一個非常節省成本的方向。
性能:基于 HDFS 可以達到我們國內自建的 HDFS 的性能水平。我們國內提供給業務的 SLA 是在單集群下 4 萬 QPS 的情況下,能夠實現 p90 在 10 毫秒以內的 RPC 性能。但是對于類似 S3 的情況,實現這樣的性能非常困難。
權限認證:在自建集群中,使用 Kerberos 和 Ranger 做認證和權限管理。但 S3 當時并不支持。JuiceFS 社區版本同樣也不支持。
數據可靠性:HDFS 使用三副本來確保數據可靠性。當時我們測試時 JuiceFS 元數據引擎使用的是 redis。我們發現,在高可用模式下,如果發生主節點切換,存儲會出現卡頓,這對我們來說是很難接受的。所以我們采用在每臺機器上獨立部署 Redis 元數據服務的方式,細節將在下文展開。
成本:塊設備這樣的方案成本很高。我們的目標是要使用 S3,如果每個人都只使用 S3,成本當然是最低的。如果使用 JuiceFS,后面的架構會有一定的額外成本,因此我們后面會解釋為什么它的成本不是最低的。
02. Hadoop 海外多云遷移方案
存儲層存算分離 - Hadoop+JuiceFS+S3
JuiceFS 與 Hadoop 的結合可以降低業務的兼容的成本,快速實現已有的業務出海。許多用戶在使用 JuiceFS 方案時,是通過 SDK 加上 Hadoop 開源版本來實現的。但這樣使用會有一個權限認證的問題,JuiceFS 社區版不支持 Ranger 和 Kerberos 的權限認證。因此,我們還是使用了 Hadoop 的整個框架。維護成本看上去很高,但在國內我們有一套自建的組件在維護著,所以對我們來說差不多沒有成本。如下圖所示,我們使用 Fuse 將 JuiceFS 掛載到 Hadoop,再使用 S3 存儲。
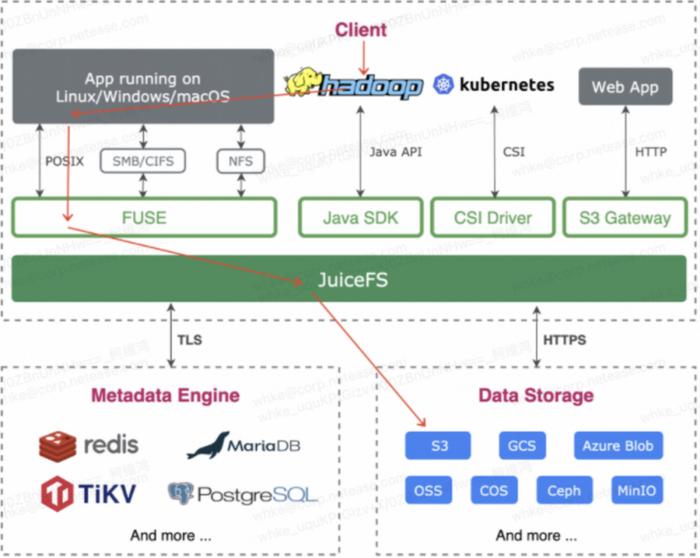
(JuiceFS 使用示意圖)
先簡單對比我們與基于 EBS 自建單集群的性能。
-
在 4 萬 QPS 的情況下可以達到 p90 10ms;
-
單節點能夠承受 30000 IOPS。
一開始我們上云時采用了 HDD 模式,具體來說就是 st1 存儲類型。但很快我們發現,當節點數量較少時,實際的 IOPS 遠遠不能滿足我們的要求。因此,我們決定將所有的 st1 存儲類型全部升級到 gp3。
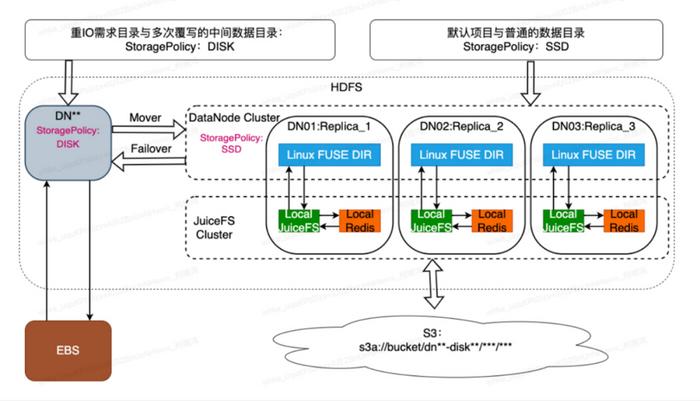 (Hadoop+JuiceFS+S3 部署架構圖)
(Hadoop+JuiceFS+S3 部署架構圖)
每塊 gp3 默認提供大約 3000 個 IOPS。為了提升性能,我們掛載了 10 塊 gp3 存儲卷,總共實現了 30000 IOPS 的性能。這個改進讓我們的系統可以更好地滿足 IOPS 的需求,不再受限于節點數量較少時的性能瓶頸。gp3 的高性能和靈活性使得它成為我們解決 IOPS 問題的理想選擇。
每個節點目前的默認帶寬是 10Gb。但是不同的機型帶寬也有所不同。我們取了一個基準,即 30000 個 IOPS 單節點,帶寬為 10Gb。我們的目標是要能夠整合我們的 S3 存儲,即在高性能的同時也要考慮存儲的成本,數據最終會落在 S3 上面。
而最重要的是要兼容 Hadoop 訪問,也就是所有的業務其實都不需要做任何修改,可以直接上云解決兼容性問題。對于一些歷史業務來說,它可能有一定的業務價值,但是我們要評估業務的改造成本和平臺兼容的成本,在我們場景業務中重構所有歷史業務的人力成本當前是大于平臺兼容成本,而且不可能短時間完成。
我們對 JuiceFS 的掛載方式與官網可能有所不同。我們在每臺機器上都部署了本地的 JuiceFS 和 Redis(如下圖所示)。這樣做是為了最大化 JuiceFS 的性能,并將本地元數據的損耗降到最低。我們曾嘗試過使用 Redis 集群和 TiDB 集群,但發現元數據性能差了好幾個數量級。因此,我們一開始就決定采用本地的部署方式。
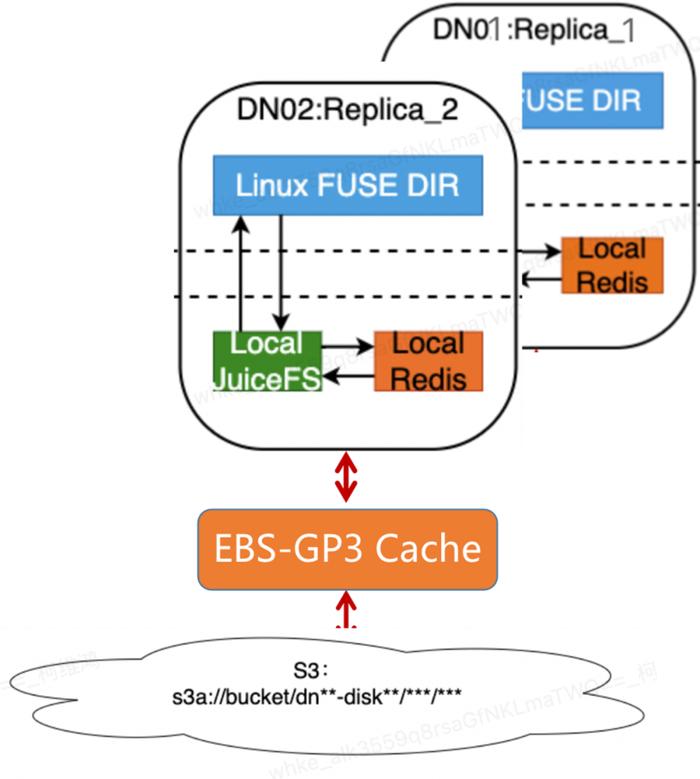 (JuiceFS 部署方式)
(JuiceFS 部署方式)
另一個好處是我們的系統與 DNO(Data Node Object)綁定。我們可以控制每個 DNO 的文件數量,即單個節點的文件數量,使其穩定在一個合理的水平范圍內。例如,我們一個 DNO 大約有 3 百萬到 8 百萬個元數據文件的上限,所以元數據單節點大約為 20GB。這樣,我們不需要過于關注其膨脹情況,將一個大規模的分布式 Redis 需求轉化為單節點元數據可控的 Redis 需求。但穩定性也是一個問題,如果單節點出現穩定性問題,我們就會面臨丟失的風險。
為了解決單節點的宕機問題,我們與 DNO 進行了綁定,并利用了 HDFS 多副本機制,在我們集群有兩種副本模式,一種是三副本,一種是 EC(Erasure Coding)副本。不同模式下,都通過副本的機制實現數據的高可靠性:在多副本的部署方案下,即使某個節點完全掛掉,我們也可以直接剔除它,而不影響整體運行和數據的可靠性。
在實踐中,將單節點部署在本地,同時使用 JuiceFS 和單節點 Redis,是能夠獲得最佳性能的方式。因為我們需要與 HDFS 和 EBS 方案的性能進行對標。
我們通過基于 HDFS 的分布式水平擴展和 JuiceFS 的緩存與讀寫策略優化,實現了高性能的 HDFS。優化部分如下:
使用 JuiceFS 替換 gp3 的目錄,以一塊小的 gp3 存儲作為 JuiceFS 的緩存目錄,實現了 IOPS 對齊 gp3 的水平;
通過優化 JuiceFS 緩存機制,定制的異步刪除,異步合并上傳,S3 目錄 TPS 預置等優化減少落到 S3 的情況,低成本存儲的 S3 替換 gp3;
基于 HDFS 集群的分布式實現節點水平擴展;
利用 Hadoop 異構存儲的特性,根據業務特性拆解 IO,以優化性能和成本。
我們將 HDFS 存儲拆分為兩個部分,"DISK" 和 "SSD"。"SSD" 存儲類型對應的是使用 JuiceFS 的 EBS 緩存與 S3 整合的混合存儲。"DISK" 存儲類型被配置為寫入 DN 的 EBS 存儲的目錄。在那些會頻繁覆寫的目錄,例如 Stage 目錄,我們會將這些目錄設置成使用 DISK 進行存儲。EBS 存儲更適合頻繁擦寫,對比 S3 的少了額外 OP 費用,而且這些目錄對存儲的總量要求是可控的,因此這個場景我們保留了一小部分 EBS 存儲。
計算層:Spot 節點與按需節點混合部署方案
首先,當我們將國內自建的 YARN 集群遷移到云上時,它無法適應云上的資源特性以實現成本優化。因此,我們基于 YARN 的智能動態伸縮方案與標簽調度相結合,同時采用 Spot 節點與按需節點混合部署方案,來優化計算資源的使用。
調整調度器策略為容量調度 (CapacityScheduler);
劃分按需節點分區和 Spot 節點分區;
調整有狀態的節點到按需節點的分區 ,讓不同狀態的任務跑在不同的區域;
使用按需節點兜底;
回收通知與 GracefulStop,當搶占節點在回收之前會提前收到回收的通知,調用與 GracefulStop 停止業務,避免與用戶作業直接失敗;
Spark+RSS,減少當節點回收的時候,數據本來在動態節點上面從而去導致要重算作業的概率。
基于我們的業務需求去做了一些動態智能伸縮的方案。和原生方案對比,我們更關注的方向是:基于業務的狀態去做動態伸縮,因為云廠商不可能知道業務的熱點時間。
基于內部運維工具 Smarttool 的周期性預測,實現智能伸縮。我們取前三周的一個歷史數據,去做一次簡單的擬合,然后通過 Smarttool 預置的算法得到擬合殘差序列 resid,以及預測值 ymean。通過這個工具預測某一天某個時間點它的資源使用應該是什么樣子,然后去實現動態伸縮容。
基于時間規則的定時伸縮,例如針對特定時間做預伸縮:每月 1 號的月報表生成時間、大促等特定的時間做提前的容量預置。
基于使用率的動態伸縮,使用容量在一定時間內大于閾值上限,或小于閾值的下限,會觸發自動擴容和縮容,實現非預期的用量需求兜底。盡量保障我們的業務在云上面是能夠得到一個穩定的,但是成本相對比較低的,計算資源的方案。
生命周期管理:數據分層,實現存儲成本優化
我們實際上是基于副本機制將 JuiceFS 和 S3 整合的數據可靠性。不論是三副本還是 1.5 副本的 EC,都會有額外的存儲支出成本,但是我們考慮到一些數據熱度的情況,一旦數據過了一定的生命周期,其對 IO 的需求可能不再那么高。因此,我們引入了一層 Alluxio+S3 的單副本層,來處理這些數據。但是需要注意,如果不改變目錄架構,這一層的性能其實比使用 JuiceFS 要差很多。盡管如此,在冷數據的場景下我們仍然可以接受這樣的性能。
因此,我們自主開發了一個數據治理和組織分層的服務,通過對數據進行異步處理,實現了對不同生命周期數據的管理和成本優化。我們稱這個服務為數據生命周期管理工具 BTS。
 (生命周期管理工具 BTS 架構)
(生命周期管理工具 BTS 架構)
BTS 的設計基于我們的文件數據庫、元數據以及審計日志數據,通過對表格及其熱度的管理,來實現數據生命周期管理。用戶可以使用上層的 DAYU Rulemanager 自定義規則以及使用數據的熱度來生成規則。這些規則指定哪些數據被視為冷數據,哪些數據被視為熱數據。
根據這些規則,我們會對數據執行壓縮、合并、轉換、歸檔、或刪除等不同的生命周期管理操作,并將它們分發到調度器去執行。數據生命周期管理工具 BTS 提供了以下能力:
-
數據重組織,將小文件合并為大文件,優化 EC 存儲的效率和 namenode 壓力;
-
表存儲和壓縮方式的轉換:異步將表從 Text 存儲格式轉換為 ORC 或 Parquet 存儲格式,并將壓縮方式從 None 或 SnAppy 轉換為 ZSTD,可以提高存儲和性能效率。BTS 支持按分區進行異步表轉換;
-
異構數據遷移,將數據異步在不同架構的存儲之間遷移,為數據分層提供組織能力。
存儲分層架構我們簡單地分為三層:
性能最好的是 HDFS on JuiceFS(熱),3 副本;
其次是 HDFS on JuiceFS EC 的模式(溫熱)1.5 副本;
再次是 Alluxio on S3(低頻冷數據)1 副本;
在所有數據消亡之前,它們都會被歸檔到 Alluxio on S3 并變為單副本。
 (存儲分層架構)
(存儲分層架構)
目前,數據生命周期治理效果如下:
-
60% 冷, 30% 溫熱, 10% 熱;
-
平均的副本數 (70% * 1 + 20% * 1.5 + 10% * 3) = 1.3 在歸檔這樣對性能要求不高的場景,我們能夠實現約 70% 的數據。使用 EC 副本時,大約 20% 的數據,而使用三副本時約為 10% 的。我們整體上控制了副本的數量,平均副本數維持在約 1.3 個。
03. 出海新架構的上線效果
在測試中,JuiceFS 在大文件的讀寫方面能夠達到相當高的帶寬。特別是在多線程模型下,大文件讀取的帶寬接近客戶端的網卡帶寬上限。
在小文件場景下,隨機寫入的 IOPS 性能較好(得益于 gp3 磁盤作為緩存),而隨機讀的 IOPS 性能相比之下較低,大約差了 5 倍。
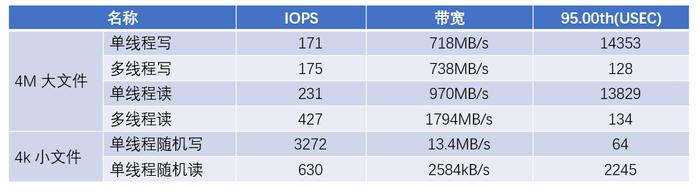 (JuiceFS 社區版讀寫性能測試結果)
(JuiceFS 社區版讀寫性能測試結果)
EBS 方案與 JuiceFS+S3 方案在業務實測的對比,測試用例為我們生產環境下的業務 SQL,可以看出 JuiceFS+S3 基本與 EBS 差別不大,部分 SQL 甚至更優。所以 JuiceFS+S3 能夠替換掉全量 EBS 。
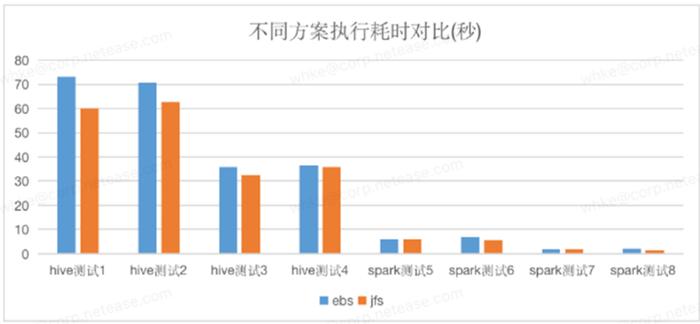 (性能測試:EBS vs JuiceFS+S3)
(性能測試:EBS vs JuiceFS+S3)
使用基于 JuiceFS 的 S3+EBS 混合分層的存算分離方案替換原來的 EBS 方案,通過數據治理和數據分層,從原來的 Hadoop 三副本的機制下降到平均 1.3 個副本,節省 55% 的多副本成本,整體存儲成本下降 72.5%。
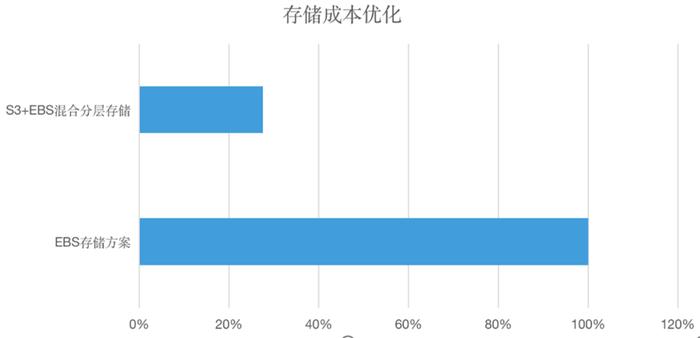 (成本對比:EBS+JuiceFS+S3 vs EBS)
(成本對比:EBS+JuiceFS+S3 vs EBS)
通過智能動態伸縮實現了 85% 集群使用率和使用 95% 的 Spot 實例替換了按需節點,總體計算成本對比優化前優化超過 80%
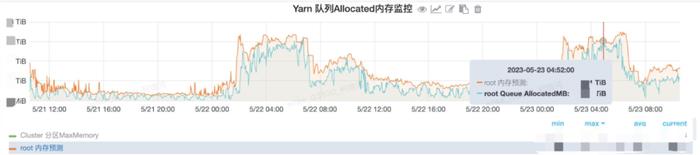 (Yarn 隊列 Allocated 內存監控)
(Yarn 隊列 Allocated 內存監控)
04. 總結與展望:邁向云原生
相比原生的 JuiceFS 方案,Hadoop+JuiceFS 使用額外的副本實現了儲性能優化和實現兼容性與高可用的支持。DN 只寫一個副本的方案, 依賴 JuiceFS 在可靠性上的迭代優化。
雖然已經在不同云上實現一套多云兼容、對比 EMR 更好的方案,但是對于混合多云和云原生的方案還需要更多的迭代。
對于未來大數據云原生場景的展望,目前我們采取的解決方案并非終極版本,而是一個過渡性方案,旨在解決兼容性和成本問題。未來,我們計劃采取以下措施:
推進業務向更云原生的方案遷移,實現 Hadoop 環境的解耦,并將數據湖和云上計算緊密結合在一體。
推動更高層次的混合多云計算和混合存儲方案,實現真正的整合,而不僅僅是現在的兼容性。這將為上層業務部門帶來更多的價值和靈活性。
作者介紹
柯維鴻,網易互娛數據與平臺服務部、數據服務組離線業務負責人。負責離線數據平臺的整體構建和技術演進,提供數據治理、存儲、查詢和上層數據產品構建,支撐網易互娛游戲數據分析業務。QCon 廣州 2023 明星講師。
關于網易互娛:網易 2001 年正式成立在線游戲事業部,經過 20 多年的快速發展,網易已躋身全球七大游戲公司之一。自 2018 年以來,網易游戲全球影響力進一步提升,多次登頂中國發行商出海收入排行榜首。





