

主存(RAM) 是一件非常重要的資源,必須要認真對待內存。雖然目前大多數內存的增長速度要比 IBM 7094 要快的多,但是,程序大小的增長要比內存的增長還快很多。不管存儲器有多大,程序大小的增長速度比內存容量的增長速度要快的多。下面我們就來探討一下操作系統是如何創建內存并管理他們的。
經過多年的研究發現,科學家提出了一種 分層存儲器體系(memory hierarchy),下面是分層體系的分類

位于頂層的存儲器速度最快,但是相對容量最小,成本非常高。層級結構向下,其訪問速度會變慢,但是容量會變大,相對造價也就越便宜。(所以個人感覺相對存儲容量來說,訪問速度是更重要的)
操作系統中管理內存層次結構的部分稱為內存管理器(memory manager),它的主要工作是有效的管理內存,記錄哪些內存是正在使用的,在進程需要時分配內存以及在進程完成時回收內存。所有現代操作系統都提供內存管理。
下面我們會對不同的內存管理模型進行探討,從簡單到復雜,由于最低級別的緩存是由硬件進行管理的,所以我們主要探討主存模型和如何對主存進行管理。
無存儲器抽象
最簡單的存儲器抽象是無存儲器。早期大型計算機(20 世紀 60 年代之前),小型計算機(20 世紀 70 年代之前)和個人計算機(20 世紀 80 年代之前)都沒有存儲器抽象。每一個程序都直接訪問物理內存。當一個程序執行如下命令:
MOV REGISTER1, 1000
計算機會把位置為 1000 的物理內存中的內容移到 REGISTER1 中。因此呈現給程序員的內存模型就是物理內存,內存地址從 0 開始到內存地址的最大值中,每個地址中都會包含一個 8 位位數的內存單元。
所以這種情況下的計算機不可能會有兩個應用程序同時在內存中。如果第一個程序向內存地址 2000 的這個位置寫入了一個值,那么此值將會替換第二個程序 2000 位置上的值,所以,同時運行兩個應用程序是行不通的,兩個程序會立刻崩潰。

不過即使存儲器模型就是物理內存,還是存在一些可變體的。下面展示了三種變體

在上圖 a 中,操作系統位于 RAM(Random Access Memory) 的底部,或像是圖 b 一樣位于 ROM(Read-Only Memory) 頂部;而在圖 c 中,設備驅動程序位于頂端的 ROM 中,而操作系統位于底部的 RAM 中。圖 a 的模型以前用在大型機和小型機上,但現在已經很少使用了;圖 b 中的模型一般用于掌上電腦或者是嵌入式系統中。第三種模型就應用在早期個人計算機中了。ROM 系統中的一部分成為 BIOS (Basic Input Output System)。模型 a 和 c 的缺點是用戶程序中的錯誤可能會破壞操作系統,可能會導致災難性的后果。
按照這種方式組織系統時,通常同一個時刻只能有一個進程正在運行。一旦用戶鍵入了一個命令,操作系統就把需要的程序從磁盤復制到內存中并執行;當進程運行結束后,操作系統在用戶終端顯示提示符并等待新的命令。收到新的命令后,它把新的程序裝入內存,覆蓋前一個程序。
在沒有存儲器抽象的系統中實現并行性一種方式是使用多線程來編程。由于同一進程中的多線程內部共享同一內存映像,那么實現并行也就不是問題了。但是這種方式卻并沒有被廣泛采納,因為人們通常希望能夠在同一時間內運行沒有關聯的程序,而這正是線程抽象所不能提供的。
運行多個程序
但是,即便沒有存儲器抽象,同時運行多個程序也是有可能的。操作系統只需要把當前內存中所有內容保存到磁盤文件中,然后再把程序讀入內存即可。只要某一時刻內存只有一個程序在運行,就不會有沖突的情況發生。
在額外特殊硬件的幫助下,即使沒有交換功能,也可以并行的運行多個程序。IBM 360 的早期模型就是這樣解決的
System/360是 IBM 在1964年4月7日,推出的劃時代的大型電腦,這一系列是世界上首個指令集可兼容計算機。

在 IBM 360 中,內存被劃分為 2KB 的區域塊,每塊區域被分配一個 4 位的保護鍵,保護鍵存儲在 CPU 的特殊寄存器(SFR)中。一個內存為 1 MB 的機器只需要 512 個這樣的 4 位寄存器,容量總共為 256 字節 (這個會算吧) PSW(Program Status word, 程序狀態字) 中有一個 4 位碼。一個運行中的進程如果訪問鍵與其 PSW 中保存的碼不同,360 硬件會捕獲這種情況。因為只有操作系統可以修改保護鍵,這樣就可以防止進程之間、用戶進程和操作系統之間的干擾。
這種解決方式是有一個缺陷。如下所示,假設有兩個程序,每個大小各為 16 KB

從圖上可以看出,這是兩個不同的 16KB 程序的裝載過程,a 程序首先會跳轉到地址 24,那里是一條 MOV 指令,然而 b 程序會首先跳轉到地址 28,地址 28 是一條 CMP 指令。這是兩個程序被先后加載到內存中的情況,假如這兩個程序被同時加載到內存中并且從 0 地址處開始執行,內存的狀態就如上面 c 圖所示,程序裝載完成開始運行,第一個程序首先從 0 地址處開始運行,執行 JMP 24 指令,然后依次執行后面的指令(許多指令沒有畫出),一段時間后第一個程序執行完畢,然后開始執行第二個程序。第二個程序的第一條指令是 28,這條指令會使程序跳轉到第一個程序的 ADD 處,而不是事先設定好的跳轉指令 CMP,由于這種不正確訪問,可能會造成程序崩潰。
上面兩個程序的執行過程中有一個核心問題,那就是都引用了絕對物理地址,這不是我們想要看到的。我們想要的是每一個程序都會引用一個私有的本地地址。IBM 360 在第二個程序裝載到內存中的時候會使用一種稱為 靜態重定位(static relocation) 的技術來修改它。它的工作流程如下:當一個程序被加載到 16384 地址時,常數 16384 被加到每一個程序地址上(所以 JMP 28會變為JMP 16412 )。雖然這個機制在不出錯誤的情況下是可行的,但這不是一種通用的解決辦法,同時會減慢裝載速度。更近一步來講,它需要所有可執行程序中的額外信息,以指示哪些包含(可重定位)地址,哪些不包含(可重定位)地址。畢竟,上圖 b 中的 JMP 28 可以被重定向(被修改),而類似 MOV REGISTER1,28 會把數字 28 移到 REGISTER 中則不會重定向。所以,裝載器(loader)需要一定的能力來辨別地址和常數。
一種存儲器抽象:地址空間
把物理內存暴露給進程會有幾個主要的缺點:第一個問題是,如果用戶程序可以尋址內存的每個字節,它們就可以很容易的破壞操作系統,從而使系統停止運行(除非使用 IBM 360 那種 lock-and-key 模式或者特殊的硬件進行保護)。即使在只有一個用戶進程運行的情況下,這個問題也存在。
第二點是,這種模型想要運行多個程序是很困難的(如果只有一個 CPU 那就是順序執行)。在個人計算機上,一般會打開很多應用程序,比如輸入法、電子郵件、瀏覽器,這些進程在不同時刻會有一個進程正在運行,其他應用程序可以通過鼠標來喚醒。在系統中沒有物理內存的情況下很難實現。
地址空間的概念
如果要使多個應用程序同時運行在內存中,必須要解決兩個問題:保護和 重定位。我們來看 IBM 360 是如何解決的:第一種解決方式是用保護密鑰標記內存塊,并將執行過程的密鑰與提取的每個存儲字的密鑰進行比較。這種方式只能解決第一種問題(破壞操作系統),但是不能解決多進程在內存中同時運行的問題。
還有一種更好的方式是創造一個存儲器抽象:地址空間(the address space)。就像進程的概念創建了一種抽象的 CPU 來運行程序,地址空間也創建了一種抽象內存供程序使用。地址空間是進程可以用來尋址內存的地址集。每個進程都有它自己的地址空間,獨立于其他進程的地址空間,但是某些進程會希望可以共享地址空間。
基址寄存器和變址寄存器
最簡單的辦法是使用動態重定位(dynamic relocation)技術,它就是通過一種簡單的方式將每個進程的地址空間映射到物理內存的不同區域。從 CDC 6600(世界上最早的超級計算機)到 Intel 8088(原始 IBM PC 的核心)所使用的經典辦法是給每個 CPU 配置兩個特殊硬件寄存器,通常叫做基址寄存器(basic register)和變址寄存器(limit register)。當使用基址寄存器和變址寄存器時,程序會裝載到內存中的連續位置并且在裝載期間無需重定位。當一個進程運行時,程序的起始物理地址裝載到基址寄存器中,程序的長度則裝載到變址寄存器中。在上圖 c 中,當一個程序運行時,裝載到這些硬件寄存器中的基址和變址寄存器的值分別是 0 和 16384。當第二個程序運行時,這些值分別是 16384 和 32768。如果第三個 16 KB 的程序直接裝載到第二個程序的地址之上并且運行,這時基址寄存器和變址寄存器的值會是 32768 和 16384。那么我們可以總結下
- 基址寄存器:存儲數據內存的起始位置
- 變址寄存器:存儲應用程序的長度。
每當進程引用內存以獲取指令或讀取、寫入數據時,CPU 都會自動將基址值添加到進程生成的地址中,然后再將其發送到內存總線上。同時,它檢查程序提供的地址是否大于或等于變址寄存器 中的值。如果程序提供的地址要超過變址寄存器的范圍,那么會產生錯誤并中止訪問。這樣,對上圖 c 中執行 JMP 28 這條指令后,硬件會把它解釋為 JMP 16412,所以程序能夠跳到 CMP 指令,過程如下

使用基址寄存器和變址寄存器是給每個進程提供私有地址空間的一種非常好的方法,因為每個內存地址在送到內存之前,都會先加上基址寄存器的內容。在很多實際系統中,對基址寄存器和變址寄存器都會以一定的方式加以保護,使得只有操作系統可以修改它們。在 CDC 6600 中就提供了對這些寄存器的保護,但在 Intel 8088 中則沒有,甚至沒有變址寄存器。但是,Intel 8088 提供了許多基址寄存器,使程序的代碼和數據可以被獨立的重定位,但是對于超出范圍的內存引用沒有提供保護。
所以你可以知道使用基址寄存器和變址寄存器的缺點,在每次訪問內存時,都會進行 ADD 和 CMP 運算。CMP 指令可以執行的很快,但是加法就會相對慢一些,除非使用特殊的加法電路,否則加法因進位傳播時間而變慢。
交換技術
如果計算機的物理內存足夠大來容納所有的進程,那么之前提及的方案或多或少是可行的。但是實際上,所有進程需要的 RAM 總容量要遠遠高于內存的容量。在 windows、OS X、或者 linux 系統中,在計算機完成啟動(Boot)后,大約有 50 - 100 個進程隨之啟動。例如,當一個 Windows 應用程序被安裝后,它通常會發出命令,以便在后續系統啟動時,將啟動一個進程,這個進程除了檢查應用程序的更新外不做任何操作。一個簡單的應用程序可能會占用 5 - 10MB 的內存。其他后臺進程會檢查電子郵件、網絡連接以及許多其他諸如此類的任務。這一切都會發生在第一個用戶啟動之前。如今,像是 Photoshop 這樣的重要用戶應用程序僅僅需要 500 MB 來啟動,但是一旦它們開始處理數據就需要許多 GB 來處理。從結果上來看,將所有進程始終保持在內存中需要大量內存,如果內存不足,則無法完成。
所以針對上面內存不足的問題,提出了兩種處理方式:最簡單的一種方式就是交換(swApping)技術,即把一個進程完整的調入內存,然后再內存中運行一段時間,再把它放回磁盤。空閑進程會存儲在磁盤中,所以這些進程在沒有運行時不會占用太多內存。另外一種策略叫做虛擬內存(virtual memory),虛擬內存技術能夠允許應用程序部分的運行在內存中。下面我們首先先探討一下交換
交換過程
下面是一個交換過程

剛開始的時候,只有進程 A 在內存中,然后從創建進程 B 和進程 C 或者從磁盤中把它們換入內存,然后在圖 d 中,A 被換出內存到磁盤中,最后 A 重新進來。因為圖 g 中的進程 A 現在到了不同的位置,所以在裝載過程中需要被重新定位,或者在交換程序時通過軟件來執行;或者在程序執行期間通過硬件來重定位。基址寄存器和變址寄存器就適用于這種情況。

交換在內存創建了多個 空閑區(hole),內存會把所有的空閑區盡可能向下移動合并成為一個大的空閑區。這項技術稱為內存緊縮(memory compaction)。但是這項技術通常不會使用,因為這項技術回消耗很多 CPU 時間。例如,在一個 16GB 內存的機器上每 8ns 復制 8 字節,它緊縮全部的內存大約要花費 16s。
有一個值得注意的問題是,當進程被創建或者換入內存時應該為它分配多大的內存。如果進程被創建后它的大小是固定的并且不再改變,那么分配策略就比較簡單:操作系統會準確的按其需要的大小進行分配。
但是如果進程的 data segment 能夠自動增長,例如,通過動態分配堆中的內存,肯定會出現問題。這里還是再提一下什么是 data segment 吧。從邏輯層面操作系統把數據分成不同的段(不同的區域)來存儲:
- 代碼段(codesegment/textsegment):
又稱文本段,用來存放指令,運行代碼的一塊內存空間
此空間大小在代碼運行前就已經確定
內存空間一般屬于只讀,某些架構的代碼也允許可寫
在代碼段中,也有可能包含一些只讀的常數變量,例如字符串常量等。
- 數據段(datasegment):
可讀可寫
存儲初始化的全局變量和初始化的 static 變量
數據段中數據的生存期是隨程序持續性(隨進程持續性)隨進程持續性:進程創建就存在,進程死亡就消失
- bss段(bsssegment):
可讀可寫
存儲未初始化的全局變量和未初始化的 static 變量
bss 段中數據的生存期隨進程持續性
bss 段中的數據一般默認為0
- rodata段:
只讀數據比如 printf 語句中的格式字符串和開關語句的跳轉表。也就是常量區。例如,全局作用域中的 const int ival = 10,ival 存放在 .rodata 段;再如,函數局部作用域中的 printf("Hello world %dn", c); 語句中的格式字符串 "Hello world %dn",也存放在 .rodata 段。
- 棧(stack):
可讀可寫
存儲的是函數或代碼中的局部變量(非 static 變量)
棧的生存期隨代碼塊持續性,代碼塊運行就給你分配空間,代碼塊結束,就自動回收空間
- 堆(heap):
可讀可寫
存儲的是程序運行期間動態分配的 malloc/realloc 的空間
堆的生存期隨進程持續性,從 malloc/realloc 到 free 一直存在
下面是我們用 Borland C++ 編譯過后的結果
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
段定義( segment ) 是用來區分或者劃分范圍區域的意思。匯編語言的 segment 偽指令表示段定義的起始,ends 偽指令表示段定義的結束。段定義是一段連續的內存空間
所以內存針對自動增長的區域,會有三種處理方式
- 如果一個進程與空閑區相鄰,那么可把該空閑區分配給進程以供其增大。
- 如果進程相鄰的是另一個進程,就會有兩種處理方式:要么把需要增長的進程移動到一個內存中空閑區足夠大的區域,要么把一個或多個進程交換出去,已變成生成一個大的空閑區。
- 如果一個進程在內存中不能增長,而且磁盤上的交換區也滿了,那么這個進程只有掛起一些空閑空間(或者可以結束該進程)
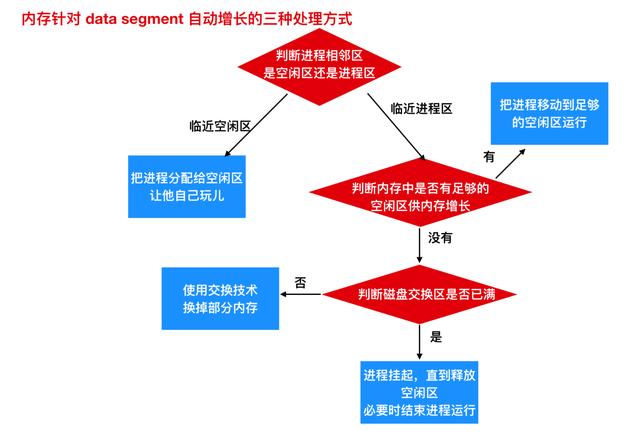
上面只針對單個或者一小部分需要增長的進程采用的方式,如果大部分進程都要在運行時增長,為了減少因內存區域不夠而引起的進程交換和移動所產生的開銷,一種可用的方法是,在換入或移動進程時為它分配一些額外的內存。然而,當進程被換出到磁盤上時,應該只交換實際上使用的內存,將額外的內存交換也是一種浪費,下面是一種為兩個進程分配了增長空間的內存配置。

如果進程有兩個可增長的段,例如,供變量動態分配和釋放的作為堆(全局變量)使用的一個數據段(data segment),以及存放局部變量與返回地址的一個堆棧段(stack segment),就如圖 b 所示。在圖中可以看到所示進程的堆棧段在進程所占內存的頂端向下增長,緊接著在程序段后的數據段向上增長。當增長預留的內存區域不夠了,處理方式就如上面的流程圖(data segment 自動增長的三種處理方式)一樣了。
空閑內存管理
在進行內存動態分配時,操作系統必須對其進行管理。大致上說,有兩種監控內存使用的方式
- 位圖(bitmap)
- 空閑列表(free lists)
下面我們就來探討一下這兩種使用方式
使用位圖的存儲管理
使用位圖方法時,內存可能被劃分為小到幾個字或大到幾千字節的分配單元。每個分配單元對應于位圖中的一位,0 表示空閑, 1 表示占用(或者相反)。一塊內存區域和其對應的位圖如下

圖 a 表示一段有 5 個進程和 3 個空閑區的內存,刻度為內存分配單元,陰影區表示空閑(在位圖中用 0 表示);圖 b 表示對應的位圖;圖 c 表示用鏈表表示同樣的信息
分配單元的大小是一個重要的設計因素,分配單位越小,位圖越大。然而,即使只有 4 字節的分配單元,32 位的內存也僅僅只需要位圖中的 1 位。32n 位的內存需要 n 位的位圖,所以1 個位圖只占用了 1/32 的內存。如果選擇更大的內存單元,位圖應該要更小。如果進程的大小不是分配單元的整數倍,那么在最后一個分配單元中會有大量的內存被浪費。
位圖提供了一種簡單的方法在固定大小的內存中跟蹤內存的使用情況,因為位圖的大小取決于內存和分配單元的大小。這種方法有一個問題是,當決定為把具有 k 個分配單元的進程放入內存時,內容管理器(memory manager) 必須搜索位圖,在位圖中找出能夠運行 k 個連續 0 位的串。在位圖中找出制定長度的連續 0 串是一個很耗時的操作,這是位圖的缺點。(可以簡單理解為在雜亂無章的數組中,找出具有一大長串空閑的數組單元)
使用鏈表進行管理
另一種記錄內存使用情況的方法是,維護一個記錄已分配內存段和空閑內存段的鏈表,段會包含進程或者是兩個進程的空閑區域。可用上面的圖 c 來表示內存的使用情況。鏈表中的每一項都可以代表一個 空閑區(H) 或者是進程(P)的起始標志,長度和下一個鏈表項的位置。
在這個例子中,段鏈表(segment list)是按照地址排序的。這種方式的優點是,當進程終止或被交換時,更新列表很簡單。一個終止進程通常有兩個鄰居(除了內存的頂部和底部外)。相鄰的可能是進程也可能是空閑區,它們有四種組合方式。

當按照地址順序在鏈表中存放進程和空閑區時,有幾種算法可以為創建的進程(或者從磁盤中換入的進程)分配內存。我們先假設內存管理器知道應該分配多少內存,最簡單的算法是使用 首次適配(first fit)。內存管理器會沿著段列表進行掃描,直到找個一個足夠大的空閑區為止。除非空閑區大小和要分配的空間大小一樣,否則將空閑區分為兩部分,一部分供進程使用;一部分生成新的空閑區。首次適配算法是一種速度很快的算法,因為它會盡可能的搜索鏈表。
首次適配的一個小的變體是 下次適配(next fit)。它和首次匹配的工作方式相同,只有一個不同之處那就是下次適配在每次找到合適的空閑區時就會記錄當時的位置,以便下次尋找空閑區時從上次結束的地方開始搜索,而不是像首次匹配算法那樣每次都會從頭開始搜索。Bays(1997) 證明了下次算法的性能略低于首次匹配算法。
另外一個著名的并且廣泛使用的算法是 最佳適配(best fit)。最佳適配會從頭到尾尋找整個鏈表,找出能夠容納進程的最小空閑區。最佳適配算法會試圖找出最接近實際需要的空閑區,以最好的匹配請求和可用空閑區,而不是先一次拆分一個以后可能會用到的大的空閑區。比如現在我們需要一個大小為 2 的塊,那么首次匹配算法會把這個塊分配在位置 5 的空閑區,而最佳適配算法會把該塊分配在位置為 18 的空閑區,如下

那么最佳適配算法的性能如何呢?最佳適配會遍歷整個鏈表,所以最佳適配算法的性能要比首次匹配算法差。但是令人想不到的是,最佳適配算法要比首次匹配和下次匹配算法浪費更多的內存,因為它會產生大量無用的小緩沖區,首次匹配算法生成的空閑區會更大一些。
最佳適配的空閑區會分裂出很多非常小的緩沖區,為了避免這一問題,可以考慮使用 最差適配(worst fit) 算法。即總是分配最大的內存區域(所以你現在明白為什么最佳適配算法會分裂出很多小緩沖區了吧),使新分配的空閑區比較大從而可以繼續使用。仿真程序表明最差適配算法也不是一個好主意。
如果為進程和空閑區維護各自獨立的鏈表,那么這四個算法的速度都能得到提高。這樣,這四種算法的目標都是為了檢查空閑區而不是進程。但這種分配速度的提高的一個不可避免的代價是增加復雜度和減慢內存釋放速度,因為必須將一個回收的段從進程鏈表中刪除并插入空閑鏈表區。
如果進程和空閑區使用不同的鏈表,那么可以按照大小對空閑區鏈表排序,以便提高最佳適配算法的速度。在使用最佳適配算法搜索由小到大排列的空閑區鏈表時,只要找到一個合適的空閑區,則這個空閑區就是能容納這個作業的最小空閑區,因此是最佳匹配。因為空閑區鏈表以單鏈表形式組織,所以不需要進一步搜索。空閑區鏈表按大小排序時,首次適配算法與最佳適配算法一樣快,而下次適配算法在這里毫無意義。
另一種分配算法是 快速適配(quick fit) 算法,它為那些常用大小的空閑區維護單獨的鏈表。例如,有一個 n 項的表,該表的第一項是指向大小為 4 KB 的空閑區鏈表表頭指針,第二項是指向大小為 8 KB 的空閑區鏈表表頭指針,第三項是指向大小為 12 KB 的空閑區鏈表表頭指針,以此類推。比如 21 KB 這樣的空閑區既可以放在 20 KB 的鏈表中,也可以放在一個專門存放大小比較特別的空閑區鏈表中。
快速匹配算法尋找一個指定代銷的空閑區也是十分快速的,但它和所有將空閑區按大小排序的方案一樣,都有一個共同的缺點,即在一個進程終止或被換出時,尋找它的相鄰塊并查看是否可以合并的過程都是非常耗時的。如果不進行合并,內存將會很快分裂出大量進程無法利用的小空閑區。
虛擬內存
盡管基址寄存器和變址寄存器用來創建地址空間的抽象,但是這有一個其他的問題需要解決:管理軟件的不斷增大(managing bloatware)。雖然內存的大小增長迅速,但是軟件的大小增長的要比內存還要快。在 1980 年的時候,許多大學用一臺 4 MB 的 VAX 計算機運行分時操作系統,供十幾個用戶同時運行。現在微軟公司推薦的 64 位 Windows 8 系統至少需要 2 GB 內存,而許多多媒體的潮流則進一步推動了對內存的需求。
這一發展的結果是,需要運行的程序往往大到內存無法容納,而且必然需要系統能夠支持多個程序同時運行,即使內存可以滿足其中單獨一個程序的需求,但是從總體上來看內存仍然滿足不了日益增長的軟件的需求(感覺和xxx和xxx 的矛盾很相似)。而交換技術并不是一個很有效的方案,在一些中小應用程序尚可使用交換,如果應用程序過大,難道還要每次交換幾 GB 的內存?這顯然是不合適的,一個典型的 SATA 磁盤的峰值傳輸速度高達幾百兆/秒,這意味著需要好幾秒才能換出或者換入一個 1 GB 的程序。
SATA(Serial ATA)硬盤,又稱串口硬盤,是未來 PC 機硬盤的趨勢,已基本取代了傳統的 PATA 硬盤。
那么還有沒有一種有效的方式來應對呢?有,那就是使用 虛擬內存(virtual memory),虛擬內存的基本思想是,每個程序都有自己的地址空間,這個地址空間被劃分為多個稱為頁面(page)的塊。每一頁都是連續的地址范圍。這些頁被映射到物理內存,但并不是所有的頁都必須在內存中才能運行程序。當程序引用到一部分在物理內存中的地址空間時,硬件會立刻執行必要的映射。當程序引用到一部分不在物理內存中的地址空間時,由操作系統負責將缺失的部分裝入物理內存并重新執行失敗的指令。
在某種意義上來說,虛擬地址是對基址寄存器和變址寄存器的一種概述。8088 有分離的基址寄存器(但不是變址寄存器)用于放入 text 和 data 。
使用虛擬內存,可以將整個地址空間以很小的單位映射到物理內存中,而不是僅僅針對 text 和 data 區進行重定位。下面我們會探討虛擬內存是如何實現的。
虛擬內存很適合在多道程序設計系統中使用,許多程序的片段同時保存在內存中,當一個程序等待它的一部分讀入內存時,可以把 CPU 交給另一個進程使用。
分頁
大部分使用虛擬內存的系統中都會使用一種 分頁(paging) 技術。在任何一臺計算機上,程序會引用使用一組內存地址。當程序執行
MOV REG,1000
這條指令時,它會把內存地址為 1000 的內存單元的內容復制到 REG 中(或者相反,這取決于計算機)。地址可以通過索引、基址寄存器、段寄存器或其他方式產生。
這些程序生成的地址被稱為 虛擬地址(virtual addresses) 并形成虛擬地址空間(virtual address space),在沒有虛擬內存的計算機上,系統直接將虛擬地址送到內存中線上,讀寫操作都使用同樣地址的物理內存。在使用虛擬內存時,虛擬地址不會直接發送到內存總線上。相反,會使用 MMU(Memory Management Unit) 內存管理單元把虛擬地址映射為物理內存地址,像下圖這樣

下面這幅圖展示了這種映射是如何工作的

頁表給出虛擬地址與物理內存地址之間的映射關系。每一頁起始于 4096 的倍數位置,結束于 4095 的位置,所以 4K 到 8K 實際為 4096 - 8191 ,8K - 12K 就是 8192 - 12287
在這個例子中,我們可能有一個 16 位地址的計算機,地址從 0 - 64 K - 1,這些是虛擬地址。然而只有 32 KB 的物理地址。所以雖然可以編寫 64 KB 的程序,但是程序無法全部調入內存運行,在磁盤上必須有一個最多 64 KB 的程序核心映像的完整副本,以保證程序片段在需要時被調入內存。
存在映射的頁如何映射
虛擬地址空間由固定大小的單元組成,這種固定大小的單元稱為 頁(pages)。而相對的,物理內存中也有固定大小的物理單元,稱為 頁框(page frames)。頁和頁框的大小一樣。在上面這個例子中,頁的大小為 4KB ,但是實際的使用過程中頁的大小范圍可能是 512 字節 - 1G 字節的大小。對應于 64 KB 的虛擬地址空間和 32 KB 的物理內存,可得到 16 個虛擬頁面和 8 個頁框。RAM 和磁盤之間的交換總是以整個頁為單元進行交換的。
程序試圖訪問地址時,例如執行下面這條指令
MOV REG, 0
會將虛擬地址 0 送到 MMU。MMU 看到虛擬地址落在頁面 0 (0 - 4095),根據其映射結果,這一頁面對應的頁框 2 (8192 - 12287),因此 MMU 把地址變換為 8192 ,并把地址 8192 送到總線上。內存對 MMU 一無所知,它只看到一個對 8192 地址的讀寫請求并執行它。MMU 從而有效的把所有虛擬地址 0 - 4095 映射到了 8192 - 12287 的物理地址。同樣的,指令
MOV REG, 8192
也被有效的轉換為
MOV REG, 24576
虛擬地址 8192(在虛擬頁 2 中)被映射到物理地址 24576(在物理頁框 6 中)上。
通過恰當的設置 MMU,可以把 16 個虛擬頁面映射到 8 個頁框中的任何一個。但是這并沒有解決虛擬地址空間比物理內存大的問題。
上圖中有 8 個物理頁框,于是只有 8 個虛擬頁被映射到了物理內存中,在上圖中用 X 號表示的其他頁面沒有被映射。在實際的硬件中,會使用一個 在/不在(Present/absent bit)位記錄頁面在內存中的實際存在情況。
未映射的頁如何映射
當程序訪問一個未映射的頁面,如執行指令
MOV REG, 32780
將會發生什么情況呢?虛擬頁面 8 (從 32768 開始)的第 12 個字節所對應的物理地址是什么?MMU 注意到該頁面沒有被映射(在圖中用 X 號表示),于是 CPU 會陷入(trap)到操作系統中。這個陷入稱為 缺頁中斷(page fault) 或者是 缺頁錯誤。操作系統會選擇一個很少使用的頁并把它的內容寫入磁盤(如果它不在磁盤上)。隨后把需要訪問的頁面讀到剛才回收的頁框中,修改映射關系,然后重新啟動引起陷入的指令。有點不太好理解,舉個例子來看一下。
例如,如果操作系統決定放棄頁框 1,那么它將把虛擬機頁面 8 裝入物理地址 4096,并對 MMU 映射做兩處修改。首先,它要將虛擬頁中的 1 表項標記為未映射,使以后任何對虛擬地址 4096 - 8191 的訪問都將導致陷入。隨后把虛擬頁面 8 的表項的叉號改為 1,因此在引起陷阱的指令重新啟動時,它將把虛擬地址 32780 映射為物理地址(4096 + 12)。
下面查看一下 MMU 的內部構造以便了解它們是如何工作的,以及了解為什么我們選用的頁大小都是 2 的整數次冪。下圖我們可以看到一個虛擬地址的例子

虛擬地址 8196 (二進制 0010000000000100)用上面的頁表映射圖所示的 MMU 映射機制進行映射,輸入的 16 位虛擬地址被分為 4 位的頁號和 12 位的偏移量。4 位的頁號可以表示 16 個頁面,12 位的偏移可以為一頁內的全部 4096 個字節。
可用頁號作為頁表(page table) 的索引,以得出對應于該虛擬頁面的頁框號。如果在/不在位則是 0 ,則引起一個操作系統陷入。如果該位是 1,則將在頁表中查到的頁框號復制到輸出寄存器的高 3 位中,再加上輸入虛擬地址中的低 12 位偏移量。如此就構成了 15 位的物理地址。輸出寄存器的內容隨即被作為物理地址送到總線。
頁表
在上面這個簡單的例子中,虛擬地址到物理地址的映射可以總結如下:虛擬地址被分為虛擬頁號(高位部分)和偏移量(低位部分)。例如,對于 16 位地址和 4 KB 的頁面大小,高 4 位可以指定 16 個虛擬頁面中的一頁,而低 12 位接著確定了所選頁面中的偏移量(0-4095)。
虛擬頁號可作為頁表的索引用來找到虛擬頁中的內容。由頁表項可以找到頁框號(如果有的話)。然后把頁框號拼接到偏移量的高位端,以替換掉虛擬頁號,形成物理地址。

因此,頁表的目的是把虛擬頁映射到頁框中。從數學上說,頁表是一個函數,它的參數是虛擬頁號,結果是物理頁框號。

通過這個函數可以把虛擬地址中的虛擬頁轉換為頁框,從而形成物理地址。
頁表項的結構
下面我們探討一下頁表項的具體結構,上面你知道了頁表項的大致構成,是由頁框號和在/不在位構成的,現在我們來具體探討一下頁表項的構成
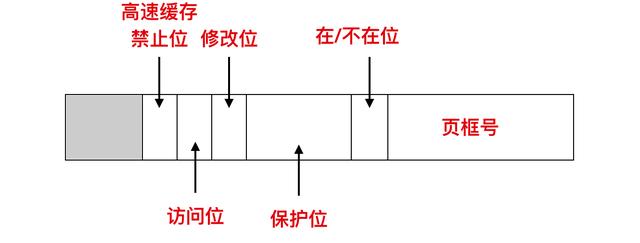
頁表項的結構是與機器相關的,但是不同機器上的頁表項大致相同。上面是一個頁表項的構成,不同計算機的頁表項可能不同,但是一般來說都是 32 位的。頁表項中最重要的字段就是頁框號(Page frame number)。畢竟,頁表到頁框最重要的一步操作就是要把此值映射過去。下一個比較重要的就是在/不在位,如果此位上的值是 1,那么頁表項是有效的并且能夠被使用。如果此值是 0 的話,則表示該頁表項對應的虛擬頁面不在內存中,訪問該頁面會引起一個缺頁異常(page fault)。
保護位(Protection) 告訴我們哪一種訪問是允許的,啥意思呢?最簡單的表示形式是這個域只有一位,0 表示可讀可寫,1 表示的是只讀。
修改位(Modified) 和 訪問位(Referenced) 會跟蹤頁面的使用情況。當一個頁面被寫入時,硬件會自動的設置修改位。修改位在頁面重新分配頁框時很有用。如果一個頁面已經被修改過(即它是 臟 的),則必須把它寫回磁盤。如果一個頁面沒有被修改過(即它是 干凈的),那么重新分配時這個頁框會被直接丟棄,因為磁盤上的副本仍然是有效的。這個位有時也叫做 臟位(dirty bit),因為它反映了頁面的狀態。
訪問位(Referenced) 在頁面被訪問時被設置,不管是讀還是寫。這個值能夠幫助操作系統在發生缺頁中斷時選擇要淘汰的頁。不再使用的頁要比正在使用的頁更適合被淘汰。這個位在后面要討論的頁面置換算法中作用很大。
最后一位用于禁止該頁面被高速緩存,這個功能對于映射到設備寄存器還是內存中起到了關鍵作用。通過這一位可以禁用高速緩存。具有獨立的 I/O 空間而不是用內存映射 I/O 的機器來說,并不需要這一位。
在深入討論下面問題之前,需要強調一下:虛擬內存本質上是用來創造一個地址空間的抽象,可以把它理解成為進程是對 CPU 的抽象,虛擬內存的實現,本質是將虛擬地址空間分解成頁,并將每一項映射到物理內存的某個頁框。因為我們的重點是如何管理這個虛擬內存的抽象。
加速分頁過程
到現在我們已經虛擬內存(virtual memory) 和 分頁(paging) 的基礎,現在我們可以把目光放在具體的實現上面了。在任何帶有分頁的系統中,都會需要面臨下面這兩個主要問題:
- 虛擬地址到物理地址的映射速度必須要快
- 如果虛擬地址空間足夠大,那么頁表也會足夠大
第一個問題是由于每次訪問內存都需要進行虛擬地址到物理地址的映射,所有的指令最終都來自于內存,并且很多指令也會訪問內存中的操作數。
操作數:操作數是計算機指令中的一個組成部分,它規定了指令中進行數字運算的量 。操作數指出指令執行的操作所需要數據的來源。操作數是匯編指令的一個字段。比如,MOV、ADD 等。
因此,每條指令可能會多次訪問頁表,如果執行一條指令需要 1 ns,那么頁表查詢需要在 0.2 ns 之內完成,以避免映射成為一個主要性能瓶頸。
第二個問題是所有的現代操作系統都會使用至少 32 位的虛擬地址,并且 64 位正在變得越來越普遍。假設頁大小為 4 KB,32 位的地址空間將近有 100 萬頁,而 64 位地址空間簡直多到無法想象。
對大而且快速的頁映射的需要成為構建計算機的一個非常重要的約束。就像上面頁表中的圖一樣,每一個表項對應一個虛擬頁面,虛擬頁號作為索引。在啟動一個進程時,操作系統會把保存在內存中進程頁表讀副本放入寄存器中。
最后一句話是不是不好理解?還記得頁表是什么嗎?它是虛擬地址到內存地址的映射頁表。頁表是虛擬地址轉換的關鍵組成部分,它是訪問內存中數據所必需的。在進程啟動時,執行很多次虛擬地址到物理地址的轉換,會把物理地址的副本從內存中讀入到寄存器中,再執行這一轉換過程。
所以,在進程的運行過程中,不必再為頁表而訪問內存。使用這種方法的優勢是簡單而且映射過程中不需要訪問內存。缺點是 頁表太大時,代價高昂,而且每次上下文切換的時候都必須裝載整個頁表,這樣會造成性能的降低。鑒于此,我們討論一下加速分頁機制和處理大的虛擬地址空間的實現方案
轉換檢測緩沖區
我們首先先來一起探討一下加速分頁的問題。大部分優化方案都是從內存中的頁表開始的。這種設計對效率有著巨大的影響。考慮一下,例如,假設一條 1 字節的指令要把一個寄存器中的數據復制到另一個寄存器。在不分頁的情況下,這條指令只訪問一次內存,即從內存取出指令。有了分頁機制后,會因為要訪問頁表而需要更多的內存訪問。由于執行速度通常被 CPU 從內存中取指令和數據的速度所限制,這樣的話,兩次訪問才能實現一次的訪問效果,所以內存訪問的性能會下降一半。在這種情況下,根本不會采用分頁機制。
什么是 1 字節的指令?我們以 8085 微處理器為例來說明一下,在 8085 微處理中,一共有 3 種字節指令,它們分別是 1-byte(1 字節)、2-byte(2 字節)、3-byte(3 字節),我們分別來說一下
1-byte:1 字節的操作數和操作碼共同以 1 字節表示;操作數是內部寄存器,并被編碼到指令中;指令需要一個存儲位置來將單個寄存器存儲在存儲位置中。沒有操作數的指令也是 1-byte 指令。
例如:MOV B,C 、LDAX B、NOP、HLT(這塊不明白的讀者可以自行查閱)
2-byte: 2 字節包括:第一個字節指定的操作碼;第二個字節指定操作數;指令需要兩個存儲器位置才能存儲在存儲器中。
例如 MVI B, 26 H、IN 56 H
3-byte: 在 3 字節指令中,第一個字節指定操作碼;后面兩個字節指定 16 位的地址;第二個字節保存低位地址;第三個字節保存 高位地址。指令需要三個存儲器位置才能將單個字節存儲在存儲器中。
例如 LDA 2050 H、JMP 2085 H
大多數程序總是對少量頁面進行多次訪問,而不是對大量頁面進行少量訪問。因此,只有很少的頁面能夠被再次訪問,而其他的頁表項很少被訪問。
頁表項一般也被稱為 Page Table Entry(PTE)。
基于這種設想,提出了一種方案,即從硬件方面來解決這個問題,為計算機設置一個小型的硬件設備,能夠將虛擬地址直接映射到物理地址,而不必再訪問頁表。這種設備被稱為轉換檢測緩沖區(Translation Lookaside Buffer, TLB),有時又被稱為 相聯存儲器(associate memory) 。

? TLB 加速分頁
TLB 通常位于 MMU 中,包含少量的表項,每個表項都記錄了頁面的相關信息,除了虛擬頁號外,其他表項都和頁表是一一對應的

是不是你到現在還是有點不理解什么是 TLB,TLB 其實就是一種內存緩存,用于減少訪問內存所需要的時間,它就是 MMU 的一部分,TLB 會將虛擬地址到物理地址的轉換存儲起來,通常可以稱為地址翻譯緩存(address-translation cache)。TLB 通常位于 CPU 和 CPU 緩存之間,它與 CPU 緩存是不同的緩存級別。下面我們來看一下 TLB 是如何工作的。
當一個 MMU 中的虛擬地址需要進行轉換時,硬件首先檢查虛擬頁號與 TLB 中所有表項進行并行匹配,判斷虛擬頁是否在 TLB 中。如果找到了有效匹配項,并且要進行的訪問操作沒有違反保護位的話,則將頁框號直接從 TLB 中取出而不用再直接訪問頁表。如果虛擬頁在 TLB 中但是違反了保護位的權限的話(比如只允許讀但是是一個寫指令),則會生成一個保護錯誤(protection fault) 返回。
上面探討的是虛擬地址在 TLB 中的情況,那么如果虛擬地址不再 TLB 中該怎么辦?如果 MMU 檢測到沒有有效的匹配項,就會進行正常的頁表查找,然后從 TLB 中逐出一個表項然后把從頁表中找到的項放在 TLB 中。當一個表項被從 TLB 中清除出,將修改位復制到內存中頁表項,除了訪問位之外,其他位保持不變。當頁表項從頁表裝入 TLB 中時,所有的值都來自于內存。

軟件 TLB 管理
直到現在,我們假設每臺電腦都有可以被硬件識別的頁表,外加一個 TLB。在這個設計中,TLB 管理和處理 TLB 錯誤完全由硬件來完成。僅僅當頁面不在內存中時,才會發生操作系統的陷入(trap)。
在以前,我們上面的假設通常是正確的。但是,許多現代的 RISC 機器,包括 SPARC、MIPS 和 HP PA,幾乎所有的頁面管理都是在軟件中完成的。
精簡指令集計算機或 RISC 是一種計算機指令集,它使計算機的微處理器的每條指令(CPI)周期比復雜指令集計算機(CISC)少
在這些計算機上,TLB 條目由操作系統顯示加載。當發生 TLB 訪問丟失時,不再是由 MMU 到頁表中查找并取出需要的頁表項,而是生成一個 TLB 失效并將問題交給操作系統解決。操作系統必須找到該頁,把它從 TLB 中移除(移除頁表中的一項),然后把新找到的頁放在 TLB 中,最后再執行先前出錯的指令。然而,所有這些操作都必須通過少量指令完成,因為 TLB 丟失的發生率要比出錯率高很多。
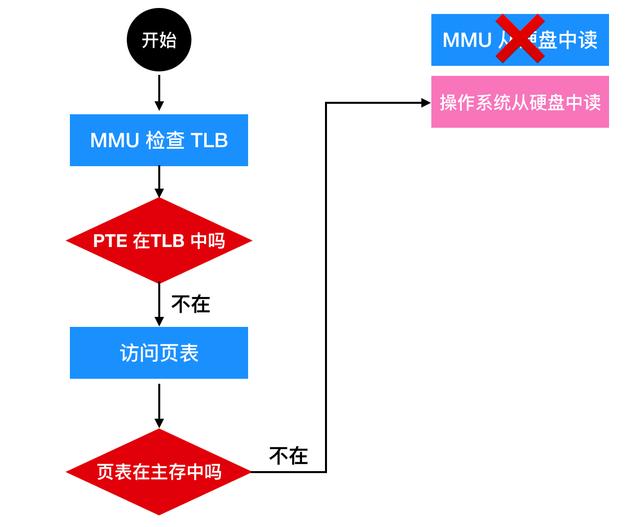
無論是用硬件還是用軟件來處理 TLB 失效,常見的方式都是找到頁表并執行索引操作以定位到將要訪問的頁面,在軟件中進行搜索的問題是保存頁表的頁可能不在 TLB 中,這將在處理過程中導致其他 TLB 錯誤。改善方法是可以在內存中的固定位置維護一個大的 TLB 表項的高速緩存來減少 TLB 失效。通過首先檢查軟件的高速緩存,操作系統 能夠有效的減少 TLB 失效問題。
TLB 軟件管理會有兩種 TLB 失效問題,當一個頁訪問在內存中而不在 TLB 中時,將產生 軟失效(soft miss),那么此時要做的就是把頁表更新到 TLB 中(我們上面探討的過程),而不會產生磁盤 I/O,處理僅僅需要一些機器指令在幾納秒的時間內完成。然而,當頁本身不在內存中時,將會產生硬失效(hard miss),那么此時就需要從磁盤中進行頁表提取,硬失效的處理時間通常是軟失效的百萬倍。在頁表結構中查找映射的過程稱為 頁表遍歷(page table walk)。
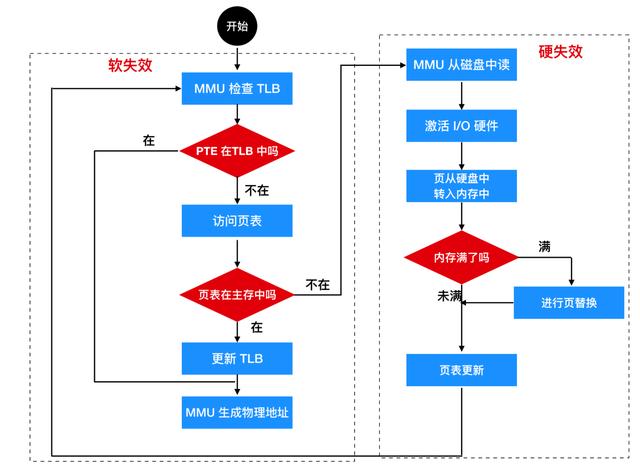
上面的這兩種情況都是理想情況下出現的現象,但是在實際應用過程中情況會更加復雜,未命中的情況可能既不是硬失效又不是軟失效。一些未命中可能更軟或更硬(偷笑)。比如,如果頁表遍歷的過程中沒有找到所需要的頁,那么此時會出現三種情況:
- 所需的頁面就在內存中,但是卻沒有記錄在進程的頁表中,這種情況可能是由其他進程從磁盤掉入內存,這種情況只需要把頁正確映射就可以了,而不需要在從硬盤調入,這是一種軟失效,稱為 次要缺頁錯誤(minor page fault)。
- 基于上述情況,如果需要從硬盤直接調入頁面,這就是嚴重缺頁錯誤(major page falut)。
- 還有一種情況是,程序可能訪問了一個非法地址,根本無需向 TLB 中增加映射。此時,操作系統會報告一個 段錯誤(segmentation fault) 來終止程序。只有第三種缺頁屬于程序錯誤,其他缺頁情況都會被硬件或操作系統以降低程序性能為代價來修復
針對大內存的頁表
還記得我們討論的是什么問題嗎?(捂臉),可能討論的太多你有所不知道了,我再提醒你一下,上面加速分頁過程討論的是虛擬地址到物理地址的映射速度必須要快的問題,還有一個問題是 如果虛擬地址空間足夠大,那么頁表也會足夠大的問題,如何處理巨大的虛擬地址空間,下面展開我們的討論。
多級頁表
第一種方案是使用多級頁表(multi),下面是一個例子

32 位的虛擬地址被劃分為 10 位的 PT1 域,10 位的 PT2 域,還有 12 位的 Offset 域。因為偏移量是 12 位,所以頁面大小是 4KB,公有 2^20 次方個頁面。
引入多級頁表的原因是避免把全部頁表一直保存在內存中。不需要的頁表就不應該保留。
多級頁表是一種分頁方案,它由兩個或多個層次的分頁表組成,也稱為分層分頁。級別1(level 1)頁面表的條目是指向級別 2(level 2) 頁面表的指針,級別2頁面表的條目是指向級別 3(level 3) 頁面表的指針,依此類推。最后一級頁表存儲的是實際的信息。
下面是一個二級頁表的工作過程
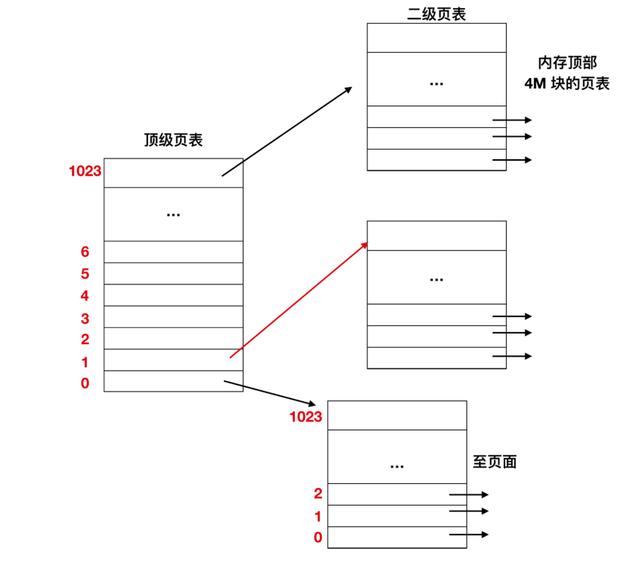
在最左邊是頂級頁表,它有 1024 個表項,對應于 10 位的 PT1 域。當一個虛擬地址被送到 MMU 時,MMU 首先提取 PT1 域并把該值作為訪問頂級頁表的索引。因為整個 4 GB (即 32 位)虛擬地址已經按 4 KB 大小分塊,所以頂級頁表中的 1024 個表項的每一個都表示 4M 的塊地址范圍。
由索引頂級頁表得到的表項中含有二級頁表的地址或頁框號。頂級頁表的表項 0 指向程序正文的頁表,表項 1 指向含有數據的頁表,表項 1023 指向堆棧的頁表,其他的項(用陰影表示)表示沒有使用。現在把 PT2 域作為訪問選定的二級頁表的索引,以便找到虛擬頁面的對應頁框號。
倒排頁表
針對分頁層級結構中不斷增加的替代方法是使用 倒排頁表(inverted page tables)。采用這種解決方案的有 PowerPC、UltraSPARC 和 Itanium。在這種設計中,實際內存中的每個頁框對應一個表項,而不是每個虛擬頁面對應一個表項。
雖然倒排頁表節省了大量的空間,但是它也有自己的缺陷:那就是從虛擬地址到物理地址的轉換會變得很困難。當進程 n 訪問虛擬頁面 p 時,硬件不能再通過把 p 當作指向頁表的一個索引來查找物理頁。而是必須搜索整個倒排表來查找某個表項。另外,搜索必須對每一個內存訪問操作都執行一次,而不是在發生缺頁中斷時執行。
解決這一問題的方式時使用 TLB。當發生 TLB 失效時,需要用軟件搜索整個倒排頁表。一個可行的方式是建立一個散列表,用虛擬地址來散列。當前所有內存中的具有相同散列值的虛擬頁面被鏈接在一起。如下圖所示

如果散列表中的槽數與機器中物理頁面數一樣多,那么散列表的沖突鏈的長度將會是 1 個表項的長度,這將會大大提高映射速度。一旦頁框被找到,新的(虛擬頁號,物理頁框號)就會被裝在到 TLB 中。
頁面置換算法
當發生缺頁異常時,操作系統會選擇一個頁面進行換出從而為新進來的頁面騰出空間。如果要換出的頁面在內存中已經被修改,那么必須將其寫到磁盤中以使磁盤副本保持最新狀態。如果頁面沒有被修改過,并且磁盤中的副本也已經是最新的,那么就不需要進行重寫。那么就直接使用調入的頁面覆蓋需要移除的頁面就可以了。
當發生缺頁中斷時,雖然可以隨機的選擇一個頁面進行置換,但是如果每次都選擇一個不常用的頁面會提升系統的性能。如果一個經常使用的頁面被換出,那么這個頁面在短時間內又可能被重復使用,那么就可能會造成額外的性能開銷。在關于頁面的主題上有很多頁面置換算法(page replacement algorithms),這些已經從理論上和實踐上得到了證明。
需要指出的是,頁面置換問題在計算機的其他領域中也會出現。例如,多數計算機把最近使用過的 32 字節或者 64 字節的存儲塊保存在一個或多個高速緩存中。當緩存滿的時候,一些塊就被選擇和移除。這些塊的移除除了花費時間較短外,這個問題同頁面置換問題完全一樣。之所以花費時間較短,是因為丟掉的高速緩存可以從內存中獲取,而內存沒有尋找磁道的時間也不存在旋轉延遲。
第二個例子是 Web 服務器。服務器會在內存中緩存一些經常使用到的 Web 頁面。然而,當緩存滿了并且已經引用了新的頁面,那么必須決定退出哪個 Web 頁面。在高速緩存中的 Web 頁面不會被修改。因此磁盤中的 Web 頁面經常是最新的,同樣的考慮也適用在虛擬內存中。在虛擬系統中,內存中的頁面可能會修改也可能不會修改。
下面我們就來探討一下有哪些頁面置換算法。
最優頁面置換算法
最優的頁面置換算法很容易描述但在實際情況下很難實現。它的工作流程如下:在缺頁中斷發生時,這些頁面之一將在下一條指令(包含該指令的頁面)上被引用。其他頁面則可能要到 10、100 或者 1000 條指令后才會被訪問。每個頁面都可以用在該頁首次被訪問前所要執行的指令數作為標記。
最優化的頁面算法表明應該標記最大的頁面。如果一個頁面在 800 萬條指令內不會被使用,另外一個頁面在 600 萬條指令內不會被使用,則置換前一個頁面,從而把需要調入這個頁面而發生的缺頁中斷推遲。計算機也像人類一樣,會把不愿意做的事情盡可能的往后拖。
這個算法最大的問題時無法實現。當缺頁中斷發生時,操作系統無法知道各個頁面的下一次將在什么時候被訪問。這種算法在實際過程中根本不會使用。
最近未使用頁面置換算法
為了能夠讓操作系統收集頁面使用信息,大部分使用虛擬地址的計算機都有兩個狀態位,R 和 M,來和每個頁面進行關聯。每當引用頁面(讀入或寫入)時都設置 R,寫入(即修改)頁面時設置 M,這些位包含在每個頁表項中,就像下面所示

因為每次訪問時都會更新這些位,因此由硬件來設置它們非常重要。一旦某個位被設置為 1,就會一直保持 1 直到操作系統下次來修改此位。
如果硬件沒有這些位,那么可以使用操作系統的缺頁中斷和時鐘中斷機制來進行模擬。當啟動一個進程時,將其所有的頁面都標記為不在內存;一旦訪問任何一個頁面就會引發一次缺頁中斷,此時操作系統就可以設置 R 位(在它的內部表中),修改頁表項使其指向正確的頁面,并設置為 READ ONLY 模式,然后重新啟動引起缺頁中斷的指令。如果頁面隨后被修改,就會發生另一個缺頁異常。從而允許操作系統設置 M 位并把頁面的模式設置為 READ/WRITE。
可以用 R 位和 M 位來構造一個簡單的頁面置換算法:當啟動一個進程時,操作系統將其所有頁面的兩個位都設置為 0。R 位定期的被清零(在每個時鐘中斷)。用來將最近未引用的頁面和已引用的頁面分開。
當出現缺頁中斷后,操作系統會檢查所有的頁面,并根據它們的 R 位和 M 位將當前值分為四類:
- 第 0 類:沒有引用 R,沒有修改 M
- 第 1 類:沒有引用 R,已修改 M
- 第 2 類:引用 R ,沒有修改 M
- 第 3 類:已被訪問 R,已被修改 M
盡管看起來好像無法實現第一類頁面,但是當第三類頁面的 R 位被時鐘中斷清除時,它們就會發生。時鐘中斷不會清除 M 位,因為需要這個信息才能知道是否寫回磁盤中。清除 R 但不清除 M 會導致出現一類頁面。
NRU(Not Recently Used) 算法從編號最小的非空類中隨機刪除一個頁面。此算法隱含的思想是,在一個時鐘內(約 20 ms)淘汰一個已修改但是沒有被訪問的頁面要比一個大量引用的未修改頁面好,NRU 的主要優點是易于理解并且能夠有效的實現。
先進先出頁面置換算法
另一種開銷較小的方式是使用 FIFO(First-In,First-Out) 算法,這種類型的數據結構也適用在頁面置換算法中。由操作系統維護一個所有在當前內存中的頁面的鏈表,最早進入的放在表頭,最新進入的頁面放在表尾。在發生缺頁異常時,會把頭部的頁移除并且把新的頁添加到表尾。
還記得缺頁異常什么時候發生嗎?我們知道應用程序訪問內存會進行虛擬地址到物理地址的映射,缺頁異常就發生在虛擬地址無法映射到物理地址的時候。因為實際的物理地址要比虛擬地址小很多(參考上面的虛擬地址和物理地址映射圖),所以缺頁經常會發生。
先進先出頁面可能是最簡單的頁面替換算法了。在這種算法中,操作系統會跟蹤鏈表中內存中的所有頁。下面我們舉個例子看一下(這個算法我剛開始看的時候有點懵逼,后來才看懂,我還是很菜)

- 初始化的時候,沒有任何頁面,所以第一次的時候會檢查頁面 1 是否位于鏈表中,沒有在鏈表中,那么就是 MISS,頁面1 進入鏈表,鏈表的先進先出的方向如圖所示。
- 類似的,第二次會先檢查頁面 2 是否位于鏈表中,沒有在鏈表中,那么頁面 2 進入鏈表,狀態為 MISS,依次類推。
- 我們來看第四次,此時的鏈表為 1 2 3,第四次會檢查頁面 2 是否位于鏈表中,經過檢索后,發現 2 在鏈表中,那么狀態就是 HIT,并不會再進行入隊和出隊操作,第五次也是一樣的。
- 下面來看第六次,此時的鏈表還是 1 2 3,因為之前沒有執行進入鏈表操作,頁面 5 會首先進行檢查,發現鏈表中沒有頁面 5 ,則執行頁面 5 的進入鏈表操作,頁面 2 執行出鏈表的操作,執行完成后的鏈表順序為 2 3 5。
第二次機會頁面置換算法
我們上面學到的 FIFO 鏈表頁面有個缺陷,那就是出鏈和入鏈并不會進行 check 檢查,這樣就會容易把經常使用的頁面置換出去,為了避免這一問題,我們對該算法做一個簡單的修改:我們檢查最老頁面的 R 位,如果是 0 ,那么這個頁面就是最老的而且沒有被使用,那么這個頁面就會被立刻換出。如果 R 位是 1,那么就清除此位,此頁面會被放在鏈表的尾部,修改它的裝入時間就像剛放進來的一樣。然后繼續搜索。
這種算法叫做 第二次機會(second chance)算法,就像下面這樣,我們看到頁面 A 到 H 保留在鏈表中,并按到達內存的時間排序。

a)按照先進先出的方法排列的頁面;b)在時刻 20 處發生缺頁異常中斷并且 A 的 R 位已經設置時的頁面鏈表。
假設缺頁異常發生在時刻 20 處,這時最老的頁面是 A ,它是在 0 時刻到達的。如果 A 的 R 位是 0,那么它將被淘汰出內存,或者把它寫回磁盤(如果它已經被修改過),或者只是簡單的放棄(如果它是未被修改過)。另一方面,如果它的 R 位已經設置了,則將 A 放到鏈表的尾部并且重新設置裝入時間為當前時刻(20 處),然后清除 R 位。然后從 B 頁面開始繼續搜索合適的頁面。
尋找第二次機會的是在最近的時鐘間隔中未被訪問過的頁面。如果所有的頁面都被訪問過,該算法就會被簡化為單純的 FIFO 算法。具體來說,假設圖 a 中所有頁面都設置了 R 位。操作系統將頁面依次移到鏈表末尾,每次都在添加到末尾時清除 R 位。最后,算法又會回到頁面 A,此時的 R 位已經被清除,那么頁面 A 就會被執行出鏈處理,因此算法能夠正常結束。
時鐘頁面置換算法
即使上面提到的第二次頁面置換算法也是一種比較合理的算法,但它經常要在鏈表中移動頁面,既降低了效率,而且這種算法也不是必須的。一種比較好的方式是把所有的頁面都保存在一個類似鐘面的環形鏈表中,一個表針指向最老的頁面。如下圖所示

當缺頁錯誤出現時,算法首先檢查表針指向的頁面,如果它的 R 位是 0 就淘汰該頁面,并把新的頁面插入到這個位置,然后把表針向前移動一位;如果 R 位是 1 就清除 R 位并把表針前移一個位置。重復這個過程直到找到了一個 R 位為 0 的頁面位置。了解這個算法的工作方式,就明白為什么它被稱為 時鐘(clokc)算法了。
最近最少使用頁面置換算法
最近最少使用頁面置換算法的一個解釋會是下面這樣:在前面幾條指令中頻繁使用的頁面和可能在后面的幾條指令中被使用。反過來說,已經很久沒有使用的頁面有可能在未來一段時間內仍不會被使用。這個思想揭示了一個可以實現的算法:在缺頁中斷時,置換未使用時間最長的頁面。這個策略稱為 LRU(Least Recently Used) ,最近最少使用頁面置換算法。
雖然 LRU 在理論上是可以實現的,但是從長遠看來代價比較高。為了完全實現 LRU,會在內存中維護一個所有頁面的鏈表,最頻繁使用的頁位于表頭,最近最少使用的頁位于表尾。困難的是在每次內存引用時更新整個鏈表。在鏈表中找到一個頁面,刪除它,然后把它移動到表頭是一個非常耗時的操作,即使使用硬件來實現也是一樣的費時。
然而,還有其他方法可以通過硬件實現 LRU。讓我們首先考慮最簡單的方式。這個方法要求硬件有一個 64 位的計數器,它在每條指令執行完成后自動加 1,每個頁表必須有一個足夠容納這個計數器值的域。在每次訪問內存后,將當前的值保存到被訪問頁面的頁表項中。一旦發生缺頁異常,操作系統就檢查所有頁表項中計數器的值,找到值最小的一個頁面,這個頁面就是最少使用的頁面。
用軟件模擬 LRU
盡管上面的 LRU 算法在原則上是可以實現的,但是很少有機器能夠擁有那些特殊的硬件。上面是硬件的實現方式,那么現在考慮要用軟件來實現 LRU 。一種可以實現的方案是 NFU(Not Frequently Used,最不常用)算法。它需要一個軟件計數器來和每個頁面關聯,初始化的時候是 0 。在每個時鐘中斷時,操作系統會瀏覽內存中的所有頁,會將每個頁面的 R 位(0 或 1)加到它的計數器上。這個計數器大體上跟蹤了各個頁面訪問的頻繁程度。當缺頁異常出現時,則置換計數器值最小的頁面。
NFU 最主要的問題是它不會忘記任何東西,想一下是不是這樣?例如,在一個多次(掃描)的編譯器中,在第一遍掃描中頻繁使用的頁面會在后續的掃描中也有較高的計數。事實上,如果第一次掃描的執行時間恰好是各次掃描中最長的,那么后續遍歷的頁面的統計次數總會比第一次頁面的統計次數小。結果是操作系統將置換有用的頁面而不是不再使用的頁面。
幸運的是只需要對 NFU 做一個簡單的修改就可以讓它模擬 LRU,這個修改有兩個步驟
- 首先,在 R 位被添加進來之前先把計數器右移一位;
- 第二步,R 位被添加到最左邊的位而不是最右邊的位。
修改以后的算法稱為 老化(aging) 算法,下圖解釋了老化算法是如何工作的。

我們假設在第一個時鐘周期內頁面 0 - 5 的 R 位依次是 1,0,1,0,1,1,(也就是頁面 0 是 1,頁面 1 是 0,頁面 2 是 1 這樣類推)。也就是說,在 0 個時鐘周期到 1 個時鐘周期之間,0,2,4,5 都被引用了,從而把它們的 R 位設置為 1,剩下的設置為 0 。在相關的六個計數器被右移之后 R 位被添加到 左側 ,就像上圖中的 a。剩下的四列顯示了接下來的四個時鐘周期內的六個計數器變化。
CPU正在以某個頻率前進,該頻率的周期稱為時鐘滴答或時鐘周期。一個 100Mhz 的處理器每秒將接收100,000,000個時鐘滴答。
當缺頁異常出現時,將置換(就是移除)計數器值最小的頁面。如果一個頁面在前面 4 個時鐘周期內都沒有被訪問過,那么它的計數器應該會有四個連續的 0 ,因此它的值肯定要比前面 3 個時鐘周期內都沒有被訪問過的頁面的計數器小。
這個算法與 LRU 算法有兩個重要的區別:看一下上圖中的 e,第三列和第五列

它們在兩個時鐘周期內都沒有被訪問過,在此之前的時鐘周期內都引用了兩個頁面。根據 LRU 算法,如果需要置換的話,那么應該在這兩個頁面中選擇一個。那么問題來了,我萌應該選擇哪個?現在的問題是我們不知道時鐘周期 1 到時鐘周期 2 內它們中哪個頁面是后被訪問到的。因為在每個時鐘周期內只記錄了一位,所以無法區分在一個時鐘周期內哪個頁面最早被引用,哪個頁面是最后被引用的。因此,我們能做的就是置換頁面3,因為頁面 3 在周期 0 - 1 內都沒有被訪問過,而頁面 5 卻被引用過。
LRU 與老化之前的第 2 個區別是,在老化期間,計數器具有有限數量的位(這個例子中是 8 位),這就限制了以往的訪問記錄。如果兩個頁面的計數器都是 0 ,那么我們可以隨便選擇一個進行置換。實際上,有可能其中一個頁面的訪問次數實在 9 個時鐘周期以前,而另外一個頁面是在 1000 個時鐘周期之前,但是我們卻無法看到這些。在實際過程中,如果時鐘周期是 20 ms,8 位一般是夠用的。所以我們經常拿 20 ms 來舉例。
工作集頁面置換算法
在最單純的分頁系統中,剛啟動進程時,在內存中并沒有頁面。此時如果 CPU 嘗試匹配第一條指令,就會得到一個缺頁異常,使操作系統裝入含有第一條指令的頁面。其他的錯誤比如 全局變量和 堆棧 引起的缺頁異常通常會緊接著發生。一段時間以后,進程需要的大部分頁面都在內存中了,此時進程開始在較少的缺頁異常環境中運行。這個策略稱為 請求調頁(demand paging),因為頁面是根據需要被調入的,而不是預先調入的。
在一個大的地址空間中系統的讀所有的頁面,將會造成很多缺頁異常,因此會導致沒有足夠的內存來容納這些頁面。不過幸運的是,大部分進程不是這樣工作的,它們都會以局部性方式(locality of reference) 來訪問,這意味著在執行的任何階段,程序只引用其中的一小部分。
一個進程當前正在使用的頁面的集合稱為它的 工作集(working set),如果整個工作集都在內存中,那么進程在運行到下一運行階段(例如,編譯器的下一遍掃面)之前,不會產生很多缺頁中斷。如果內存太小從而無法容納整個工作集,那么進程的運行過程中會產生大量的缺頁中斷,會導致運行速度也會變得緩慢。因為通常只需要幾納秒就能執行一條指令,而通常需要十毫秒才能從磁盤上讀入一個頁面。如果一個程序每 10 ms 只能執行一到兩條指令,那么它將需要很長時間才能運行完。如果只是執行幾條指令就會產生中斷,那么就稱作這個程序產生了 顛簸(thrashing)。
在多道程序的系統中,通常會把進程移到磁盤上(即從內存中移走所有的頁面),這樣可以讓其他進程有機會占用 CPU 。有一個問題是,當進程想要再次把之前調回磁盤的頁面調回內存怎么辦?從技術的角度上來講,并不需要做什么,此進程會一直產生缺頁中斷直到它的工作集 被調回內存。然后,每次裝入一個進程需要 20、100 甚至 1000 次缺頁中斷,速度顯然太慢了,并且由于 CPU 需要幾毫秒時間處理一個缺頁中斷,因此由相當多的 CPU 時間也被浪費了。
因此,不少分頁系統中都會設法跟蹤進程的工作集,確保這些工作集在進程運行時被調入內存。這個方法叫做 工作集模式(working set model)。它被設計用來減少缺頁中斷的次數的。在進程運行前首先裝入工作集頁面的這一個過程被稱為 預先調頁(prepaging),工作集是隨著時間來變化的。
根據研究表明,大多數程序并不是均勻的訪問地址空間的,而訪問往往是集中于一小部分頁面。一次內存訪問可能會取出一條指令,也可能會取出數據,或者是存儲數據。在任一時刻 t,都存在一個集合,它包含所喲歐最近 k 次內存訪問所訪問過的頁面。這個集合 w(k,t) 就是工作集。因為最近 k = 1次訪問肯定會訪問最近 k > 1 次訪問所訪問過的頁面,所以 w(k,t) 是 k 的單調遞減函數。隨著 k 的增大,w(k,t) 是不會無限變大的,因為程序不可能訪問比所能容納頁面數量上限還多的頁面。

事實上大多數應用程序只會任意訪問一小部分頁面集合,但是這個集合會隨著時間而緩慢變化,所以為什么一開始曲線會快速上升而 k 較大時上升緩慢。為了實現工作集模型,操作系統必須跟蹤哪些頁面在工作集中。一個進程從它開始執行到當前所實際使用的 CPU 時間總數通常稱作 當前實際運行時間。進程的工作集可以被稱為在過去的 t 秒實際運行時間中它所訪問過的頁面集合。
下面來簡單描述一下工作集的頁面置換算法,基本思路就是找出一個不在工作集中的頁面并淘汰它。下面是一部分機器頁表

因為只有那些在內存中的頁面才可以作為候選者被淘汰,所以該算法忽略了那些不在內存中的頁面。每個表項至少包含兩條信息:上次使用該頁面的近似時間和 R(訪問)位。空白的矩形表示該算法不需要其他字段,例如頁框數量、保護位、修改位。
算法的工作流程如下,假設硬件要設置 R 和 M 位。同樣的,在每個時鐘周期內,一個周期性的時鐘中斷會使軟件清除 Referenced(引用)位。在每個缺頁異常,頁表會被掃描以找出一個合適的頁面把它置換。
隨著每個頁表項的處理,都需要檢查 R 位。如果 R 位是 1,那么就會將當前時間寫入頁表項的 上次使用時間域,表示的意思就是缺頁異常發生時頁面正在被使用。因為頁面在當前時鐘周期內被訪問過,那么它應該出現在工作集中而不是被刪除(假設 t 是橫跨了多個時鐘周期)。
如果 R 位是 0 ,那么在當前的時鐘周期內這個頁面沒有被訪問過,應該作為被刪除的對象。為了查看是否應該將其刪除,會計算其使用期限(當前虛擬時間 - 上次使用時間),來用這個時間和 t 進行對比。如果使用期限大于 t,那么這個頁面就不再工作集中,而使用新的頁面來替換它。然后繼續掃描更新剩下的表項。
然而,如果 R 位是 0 但是使用期限小于等于 t,那么此頁應該在工作集中。此時就會把頁面臨時保存起來,但是會記生存時間最長(即上次使用時間的最小值)的頁面。如果掃描完整個頁表卻沒有找到適合被置換的頁面,也就意味著所有的頁面都在工作集中。在這種情況下,如果找到了一個或者多個 R = 0 的頁面,就淘汰生存時間最長的頁面。最壞的情況下是,在當前時鐘周期內,所有的頁面都被訪問過了(也就是都有 R = 1),因此就隨機選擇一個頁面淘汰,如果有的話最好選一個未被訪問的頁面,也就是干凈的頁面。
工作集時鐘頁面置換算法
當缺頁異常發生后,需要掃描整個頁表才能確定被淘汰的頁面,因此基本工作集算法還是比較浪費時間的。一個對基本工作集算法的提升是基于時鐘算法但是卻使用工作集的信息,這種算法稱為WSClock(工作集時鐘)。由于它的實現簡單并且具有高性能,因此在實踐中被廣泛應用。
與時鐘算法一樣,所需的數據結構是一個以頁框為元素的循環列表,就像下面這樣

最初的時候,該表是空的。當裝入第一個頁面后,把它加載到該表中。隨著更多的頁面的加入,它們形成一個環形結構。每個表項包含來自基本工作集算法的上次使用時間,以及 R 位(已標明)和 M 位(未標明)。
與時鐘算法一樣,在每個缺頁異常時,首先檢查指針指向的頁面。如果 R 位被是設置為 1,該頁面在當前時鐘周期內就被使用過,那么該頁面就不適合被淘汰。然后把該頁面的 R 位置為 0,指針指向下一個頁面,并重復該算法。該事件序列化后的狀態參見圖 b。
現在考慮指針指向的頁面 R = 0 時會發生什么,參見圖 c,如果頁面的使用期限大于 t 并且頁面為被訪問過,那么這個頁面就不會在工作集中,并且在磁盤上會有一個此頁面的副本。申請重新調入一個新的頁面,并把新的頁面放在其中,如圖 d 所示。另一方面,如果頁面被修改過,就不能重新申請頁面,因為這個頁面在磁盤上沒有有效的副本。為了避免由于調度寫磁盤操作引起的進程切換,指針繼續向前走,算法繼續對下一個頁面進行操作。畢竟,有可能存在一個老的,沒有被修改過的頁面可以立即使用。
原則上來說,所有的頁面都有可能因為磁盤I/O 在某個時鐘周期內被調度。為了降低磁盤阻塞,需要設置一個限制,即最大只允許寫回 n 個頁面。一旦達到該限制,就不允許調度新的寫操作。
那么就有個問題,指針會繞一圈回到原點的,如果回到原點,它的起始點會發生什么?這里有兩種情況:
- 至少調度了一次寫操作
- 沒有調度過寫操作
在第一種情況中,指針僅僅是不停的移動,尋找一個未被修改過的頁面。由于已經調度了一個或者多個寫操作,最終會有某個寫操作完成,它的頁面會被標記為未修改。置換遇到的第一個未被修改過的頁面,這個頁面不一定是第一個被調度寫操作的頁面,因為硬盤驅動程序為了優化性能可能會把寫操作重排序。
對于第二種情況,所有的頁面都在工作集中,否則將至少調度了一個寫操作。由于缺乏額外的信息,最簡單的方法就是置換一個未被修改的頁面來使用,掃描中需要記錄未被修改的頁面的位置,如果不存在未被修改的頁面,就選定當前頁面并把它寫回磁盤。
頁面置換算法小結
我們到現在已經研究了各種頁面置換算法,現在我們來一個簡單的總結,算法的總結歸納如下

- 最優算法在當前頁面中置換最后要訪問的頁面。不幸的是,沒有辦法來判定哪個頁面是最后一個要訪問的,因此實際上該算法不能使用。然而,它可以作為衡量其他算法的標準。
- NRU 算法根據 R 位和 M 位的狀態將頁面氛圍四類。從編號最小的類別中隨機選擇一個頁面。NRU 算法易于實現,但是性能不是很好。存在更好的算法。
- FIFO 會跟蹤頁面加載進入內存中的順序,并把頁面放入一個鏈表中。有可能刪除存在時間最長但是還在使用的頁面,因此這個算法也不是一個很好的選擇。
- 第二次機會算法是對 FIFO 的一個修改,它會在刪除頁面之前檢查這個頁面是否仍在使用。如果頁面正在使用,就會進行保留。這個改進大大提高了性能。
- 時鐘 算法是第二次機會算法的另外一種實現形式,時鐘算法和第二次算法的性能差不多,但是會花費更少的時間來執行算法。
- LRU 算法是一個非常優秀的算法,但是沒有特殊的硬件(TLB)很難實現。如果沒有硬件,就不能使用 LRU 算法。
- NFU 算法是一種近似于 LRU 的算法,它的性能不是非常好。
- 老化 算法是一種更接近 LRU 算法的實現,并且可以更好的實現,因此是一個很好的選擇
- 最后兩種算法都使用了工作集算法。工作集算法提供了合理的性能開銷,但是它的實現比較復雜。WSClock 是另外一種變體,它不僅能夠提供良好的性能,而且可以高效地實現。
總之,最好的算法是老化算法和WSClock算法。他們分別是基于 LRU 和工作集算法。他們都具有良好的性能并且能夠被有效的實現。還存在其他一些好的算法,但實際上這兩個可能是最重要的。





