

論文摘要
任何給定的人工智能系統(tǒng)都不能被接受,除非它的可信度被證明。值得信賴的人工智能系統(tǒng)的一個重要特征是沒有算法偏見。“個體歧視”存在于給定個體與另一個體僅在“受保護屬性”(如年齡、性別、種族等)上不同,但是它們會從給定的機器學(xué)習(xí)(ML)模型中得到不同的決策結(jié)果。目前的工作是解決給定 ML 模型中存在的個體歧視問題。在黑盒環(huán)境下,個體歧視的檢測是測試密集型的,這對于非平凡的系統(tǒng)是不可行的。我們提出了一種自動生成測試用例進行輸入的方法,用于檢測個體歧視的任務(wù)。我們的方法結(jié)合了兩種成熟的技術(shù)——符號執(zhí)行和局部可解釋性,以實現(xiàn)有效的測試案例生成。我們實證表明,與所研究的最著名的基準(zhǔn)系統(tǒng)相比,我們生成測試用例的方法是非常有效的。
論文介紹
模型的偏見。這十年隨著人工智能(AI)的復(fù)蘇,AI 模型已經(jīng)開始在很多系統(tǒng)中承擔(dān)關(guān)鍵性的決策--從招聘決策、審批貸款到設(shè)計無人駕駛汽車。因此,為了確保人工智能系統(tǒng)被廣泛接受,人工智能模型的可靠性是最重要的。可靠的 AI 系統(tǒng)的一個重要方面是確保其決策的公平性。偏見可能以多種方式存在于決策系統(tǒng)中。它可以以群體歧視的形式存在,即兩個不同的群體(例如,基于性別/種族等“受保護的屬性”)獲得不同的決策。需要注意的是,歧視感知系統(tǒng)需要經(jīng)過訓(xùn)練,以避免對敏感的特征進行歧視,這些特征被稱為“受保護的屬性”。受保護的屬性是特定于應(yīng)用的。年齡、性別、種族等特征是一些經(jīng)常出現(xiàn)的例子,許多應(yīng)用實際都將其作為受保護屬性。
個體歧視。在本文中,我們討論了機器學(xué)習(xí)模型中檢測個體歧視的問題。我們在本文中使用的個體公平性/偏見的定義是一種簡化的、非概率的反事實公平性,這也符合 Dwork 的個體公平性框架。如本工作所述,如果對于任何兩個僅在受保護屬性上有差異的有效輸入,總是被分配到相同的類別,那么系統(tǒng)就被稱為是公平的(如果對于某對有效輸入,產(chǎn)生了不同的分類,那么就被稱為存在偏差)。這樣的偏差情況在之前的模型中已經(jīng)被注意到了,并對模型生成者造成了不利的后果。因此,檢測這類情況是最重要的。需要注意的是,從訓(xùn)練數(shù)據(jù)中刪除受保護的屬性并不能消除這種偏見,因為由于受保護屬性和非受保護屬性之間可能存在的共同關(guān)系,個體歧視可能仍然存在,就像成人人口普查收入數(shù)據(jù)中的種族(受保護)和郵編(非受保護)一樣。因此,我們面臨的挑戰(zhàn)是,如何評估和找到非保護和保護屬性的所有值,讓模型顯示出這種個體歧視行為。
現(xiàn)有技術(shù)及其缺點。衡量個體歧視需要進行詳盡的測試,這對于一個非平凡的系統(tǒng)來說是不可行的。現(xiàn)有的技術(shù)能生成一個測試套件來確定模型中是否存在個體歧視以及個體歧視的程度。THEMIS 從域中選擇所有屬性的隨機值,以確定系統(tǒng)是否在個體之間進行歧視。AEQUITAS 分兩個階段生成測試用例。第一階段通過對輸入空間進行隨機采樣來生成測試用例。第二階段開始時,將第一階段產(chǎn)生的每個判別輸入作為輸入,并對其進行擾動,以產(chǎn)生更多的測試用例。這兩種技術(shù)的目的都是為了產(chǎn)生更多的測試輸入。盡管上述這兩種技術(shù)適用于任何黑盒系統(tǒng),但我們的實驗表明,它們會遺漏許多這樣的非保護屬性值組合,而這些組合可能存在單獨的判別。我們還希望覆蓋模型更多樣化的路徑,以生成更多的測試輸入。
我們的方法。我們的目的是對特征空間進行系統(tǒng)化搜索,以覆蓋更多的空間,而不需要太多的冗余。存在基于符號評估的技術(shù),通過系統(tǒng)地探索程序中的不同執(zhí)行路徑來自動生成測試輸入。這種方法避免了生成多個輸入,因為這些輸入傾向于探索相同的程序路徑。這類技術(shù)本質(zhì)上是白盒技術(shù),利用約束求解器的能力來自動創(chuàng)建測試輸入。符號執(zhí)行從一個隨機輸入開始,分析路徑生成一組路徑約束條件(即輸入屬性的條件),并迭代地切換(或否定)路徑中的約束條件,生成一組新的路徑約束條件。然后,它使用約束求解器對所得的路徑約束進行求解,以生成一個新的輸入,這個輸入可能會把控制帶到新的路徑上。我們的想法是使用這種動態(tài)符號執(zhí)行來生成測試輸入,這有可能導(dǎo)致發(fā)現(xiàn) ML 模型中的個體歧視。然而,現(xiàn)有的這種技術(shù)已經(jīng)被用來生成可解釋程序的程序輸入。我們的主要挑戰(zhàn)是如何將這種技術(shù)應(yīng)用于不可解釋的機器學(xué)習(xí)模型。
- 限制條件。可以使用現(xiàn)成的局部解釋器來生成路徑的線性近似。從一個這樣的解釋器中得到的線性約束可以用于符號評價,這將不需要任何專門的約束求解器。
- 數(shù)據(jù)驅(qū)動。我們的算法可以利用已知的數(shù)據(jù),這些數(shù)據(jù)可以作為種子數(shù)據(jù)開始搜索。
- 全局和局部搜索。一旦找到一個單獨的判別,我們就進行局部搜索,以發(fā)現(xiàn)許多輸入組合,從而發(fā)現(xiàn)更多的判別。否則,我們使用符號執(zhí)行進行全局搜索,以覆蓋模型中的不同路徑。
- 優(yōu)化。局部解釋器呈現(xiàn)與謂詞相關(guān)的置信度。我們的算法根據(jù)約束條件的置信度得分來執(zhí)行對其進行切換的選擇。
- 可擴展性。我們的算法通過切換特征相關(guān)的約束來系統(tǒng)地遍歷特征空間中的路徑。這使得它具有可擴展性,不像其他技術(shù)那樣考慮基于結(jié)構(gòu)的覆蓋標(biāo)準(zhǔn)。
貢獻:我們的貢獻如下。
- 我們提出了一種新的技術(shù)來尋找模型中的個體歧視。
- 我們開發(fā)了一種新的動態(tài)符號執(zhí)行和局部解釋的組合,以生成非可解釋模型的測試用例。我們相信,局部解釋器的使用將為黑盒 AI 模型的基于路徑的分析開辟許多途徑。
- 我們在幾個具有已知偏差的開源分類模型上展示了我們技術(shù)的有效性。我們將我們的技術(shù)與現(xiàn)有的算法即 THEMIS、AEQUITAS 進行了實證比較,并展示了我們的方法比這些先前的工作所帶來的性能改進。
算法
我們將我們的算法分為兩種不同的搜索算法,分別稱為全局搜索和局部搜索。
下面是我們想通過設(shè)計的測試用例生成技術(shù)達(dá)到兩個優(yōu)化標(biāo)準(zhǔn)。有效的測試用例生成:給定一個模型 M,一組領(lǐng)域約束條件 C 和受保護屬性集 P,目的是生成測試用例,以最大限度地提高|Succ|/|Gen|的比率,其中 Gen 是算法生成的非受保護屬性值組合的集合,Succ ⊆Gen 可導(dǎo)致歧視,即 Succ 中的每個實例對不同的受保護屬性值組合至少產(chǎn)生一個不同的決定。下面是關(guān)于這個標(biāo)準(zhǔn)的幾個指標(biāo):
- 測試用例。每個測試用例不被視為所有屬性值的集合,而只被視為非保護屬性的集合。這確保了多個判別性測試用例不會被計入相同的非保護屬性值組合。
- 領(lǐng)域約束。我們假設(shè)應(yīng)用領(lǐng)域約束 C 可以過濾掉不真實的測試用例。
- 生成和判別測試的順序。優(yōu)化標(biāo)準(zhǔn)并沒有規(guī)定所有的測試用例是否一次生成,也沒有規(guī)定檢查判別和生成是否可以同時進行。這樣測試用例的生成也可以依賴于判別檢查。
在軟件測試領(lǐng)域,存在一些預(yù)定義的覆蓋標(biāo)準(zhǔn)。在最近關(guān)于機器學(xué)習(xí)的著作中也定義了許多這樣的覆蓋標(biāo)準(zhǔn)。接下來,我們定義路徑覆蓋標(biāo)準(zhǔn),使其適用于不同類型的模型。
覆蓋標(biāo)準(zhǔn):請注意,為任何黑盒模型定義路徑覆蓋標(biāo)準(zhǔn)都不是簡單的。可以根據(jù)不同類型的模型的操作特點來定義其路徑。例如,可以根據(jù)神經(jīng)元的激活來定義神經(jīng)網(wǎng)絡(luò)中的路徑,也可以定義決策樹分類器中的決策路徑。
我們將覆蓋標(biāo)準(zhǔn)定義如下。給定一個分類模型 M 和一組測試用例 T,我們將 T 的覆蓋率定義為 M 的決策區(qū)域被 T 執(zhí)行的數(shù)量。
在本文中,我們使用決策樹分類器來逼近模型 M 的行為,我們生成高精度的決策樹模型來逼近 M 的決策區(qū)域,我們測試用例生成技術(shù)的目的是最大化路徑覆蓋率和個體歧視檢測。
在實踐中,自動測試用例生成過程總是有一個極限,在這個極限范圍內(nèi),需要完成這兩個目標(biāo)的最大化。在我們的案例中,我們考慮了兩個這樣可能的限制:1)生成測試用例的數(shù)量 2)生成時間。
路徑覆蓋率最大化是通過利用符號執(zhí)行算法的能力來實現(xiàn)的,該算法迎合了對不同執(zhí)行路徑的系統(tǒng)探索。。最大化路徑覆蓋率是在全局搜索模塊中完成的,正如我們在最終算法所提到的。


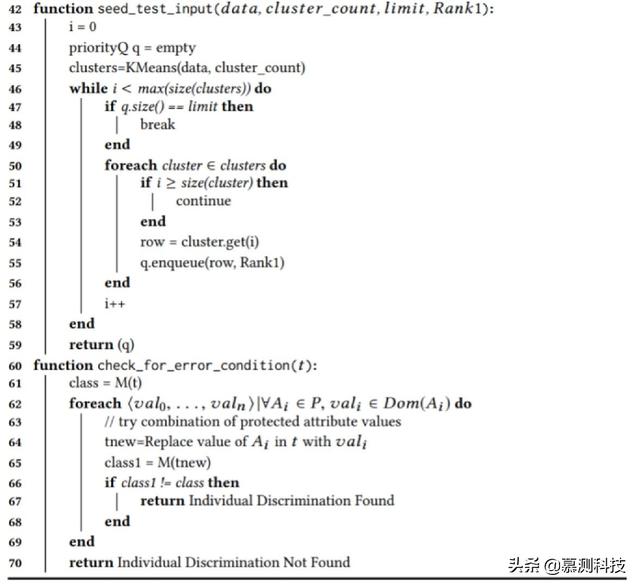
符號執(zhí)行和局部模型近似路徑的思想的直接應(yīng)用有三大挑戰(zhàn)。前兩者的產(chǎn)生是由于局部模型中存在的固有近似,而符號執(zhí)行則是第三種的原因。
- 近似。決策樹路徑根據(jù)可解釋的特征近似于實際執(zhí)行路徑。由于這樣的近似,可以生成實際程序路徑的重復(fù)。
- 可信度。決策樹路徑有一個與所有組成的謂詞相關(guān)聯(lián)的置信度得分(而程序路徑則不是這樣)。因此,挑戰(zhàn)在于設(shè)計一種方法來使用這個置信度分?jǐn)?shù)來更好地探索路徑。
- 程序測試中的符號執(zhí)行存在路徑爆炸問題,尤其是在深度優(yōu)先搜索方式下。它可以一直探索程序樹深度的路徑,而不探索程序其他部分的路徑。研究者們已經(jīng)探索出各種技術(shù)來解決這個問題——應(yīng)用需求驅(qū)動或定向技術(shù),向著程序中的某個特定位置生成測試用例,以及組合技術(shù),試圖分別分析各種功能模塊,然后再將它們組合起來,在整個程序中生成更長的路徑。所有這些技術(shù)都利用了被測程序的結(jié)構(gòu)。
最大限度地提高歧視檢測效率
檢查個體歧視。首先,讓我們考慮一下檢查個體歧視的情況,如算法 2 所示。該算法按照個體歧視的定義來執(zhí)行檢查。如果一個測試用例保持其非保護屬性集的值不變,但通過嘗試各種可能的組合來改變其保護屬性集的值,從而產(chǎn)生不同的類標(biāo)簽,那么這個測試用例被認(rèn)為是具有個體歧視性的。
本地搜索。如前文所討論的符號執(zhí)行,試圖找到測試輸入以最大化路徑覆蓋率。我們把這樣的符號搜索策略稱為全局搜索。通過種子數(shù)據(jù)或符號執(zhí)行產(chǎn)生的一些測試輸入將具有鑒別性。為了增加歧視性測試用例的可能性,我們利用了這樣一個事實:我們可以執(zhí)行測試用例并檢查它們是否具有判別性,然后根據(jù)這一點,生成更多的測試用例。
一旦發(fā)現(xiàn)了一個具有歧視性的測試用例,比如說 t,我們就嘗試進一步生成更多的測試輸入,這可能會導(dǎo)致個體歧視。關(guān)鍵思想是否定 t 的決策樹的非保護屬性約束,以生成更多的測試輸入。通過切換一個與非保護屬性相關(guān)的約束,并生成一個解決結(jié)果約束的輸入,算法試圖探索判別路徑 p 的鄰域,這種形式的符號執(zhí)行就是我們所說的局部搜索,因為它傾向于搜索判別測試案例的局部性。這種方式之所以有效,是因為機器學(xué)習(xí)模型固有的對抗性魯棒性屬性,它證明了輸入的微小擾動會導(dǎo)致分類器決策的改變。
粘性解決方案。局部搜索和全局搜索的目的是遍歷盡可能多的路徑。局部搜索集中在探索判別路徑附近的路徑,即由判別輸入產(chǎn)生的路徑。因此,我們只能得到一個約束的解。但是,為了照顧到局部線性模型可能引起的相似情況,我們使用與前一個約束(與判別輸入有關(guān))的解接近的約束求解器的解。我們把這樣的解稱為粘性解。由于粘性,如果我們否定了一個謂詞,那么對于剩下的謂詞,它就會趨向于取與前一個解相同的值。
本地搜索和全局搜索的排序。在綜合算法 2 中,提出了三個參考等級,即 Rank1、Rank2 和 Rank3,分別為種子輸入、本地搜索和全局搜索各一個。這些等級的設(shè)置方式是:根據(jù)其發(fā)現(xiàn)引起歧視的輸入的能力,給予本地搜索最高的優(yōu)先級,其次是種子輸入,進一步是全局搜索(見算法 2 的第 3、18、32 行)。
實驗評估
基線特征。我們對表 1 所列的 8 個不同來源的開源公平性基線進行了實驗。

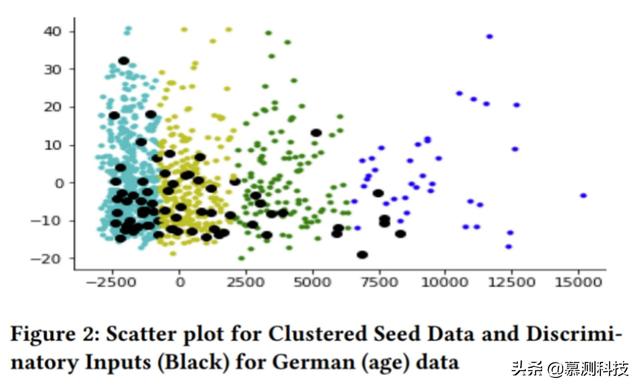
配置。我們的代碼是用 Python 寫的,用 Python 2.7.12 執(zhí)行。所有的實驗都是在運行 Ubuntu 16.04 的機器上進行的,有 16GB 內(nèi)存,2.4Ghz 的 CPU,運行 Intel Core i5。我們使用了 LIME 來進行局部解釋。我們使用 K-means 對輸入的種子數(shù)據(jù)進行聚類。由于我們的用例需要在較少的時間內(nèi)生成更多的測試用例,K-means 是最簡單和最快的聚類算法之一,被證明是一個合理的選擇。事實上,用于運行我們的實驗的數(shù)據(jù)集具有兩個或四個真正的類標(biāo)簽,這推動了將聚類數(shù)設(shè)置為 4 的邏輯假設(shè)。 這一點使用散點圖進一步驗證,如圖 2 所示,它清楚地描繪了種子數(shù)據(jù)中的四個不同的聚類。
與 THEMIS 的比較。我們從他們的 GitHub 倉庫中獲取了 THEMIS 的代碼,在仔細(xì)分析他們的代碼后,我們發(fā)現(xiàn)了開放源碼中的一個意外行為。THEMIS 實際上生成了重復(fù)的測試用例,他們報告的實驗統(tǒng)計也包含了這些重復(fù)的測試用例。這是隨機測試用例生成帶來的問題之一,因為它會產(chǎn)生重復(fù)的測試用例。我們對 THEMIS 的代碼進行了修改,以去除重復(fù)的測試案例,用于我們的實驗評估。

與 AEQUITAS 比較。AEQUITAS 算法在兩個搜索階段運行--全局和局部。全局階段考慮測試用例數(shù)量的限制,并通過對輸入空間的隨機抽樣來生成測試用例。在所有這些生成的測試用例中,有少數(shù)測試用例具有鑒別性。然后,局部階段開始將全局搜索階段確定的每個判別性輸入作為輸入,并對其進行擾動,以進一步生成更多的測試用例。這個階段就像之前的全局搜索一樣,考慮了對生成的測試用例數(shù)量的限制。他們應(yīng)用了三種不同類型的擾動,導(dǎo)致算法的三種不同變化。
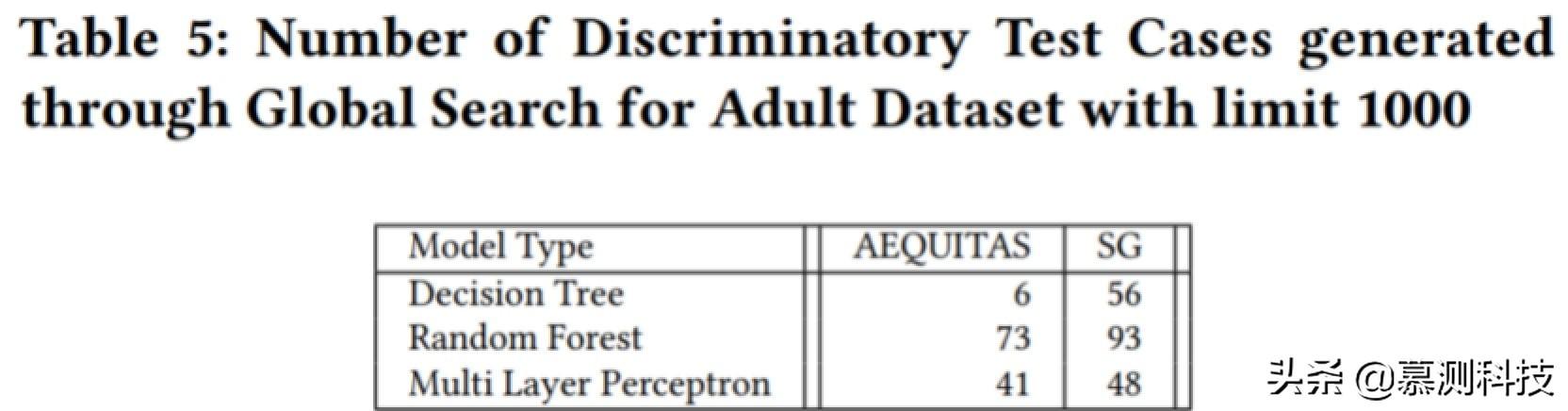
全球搜索比較。表 5 是 SG 與 AEQUITAS 在全局搜索策略方面的比較。我們的全局搜索方法使用聚類種子數(shù)據(jù)和符號執(zhí)行,而他們的策略則使用輸入空間的隨機采樣。從統(tǒng)計結(jié)果可以看出,一般來說,我們的算法生成的輸入有更多的判別性。
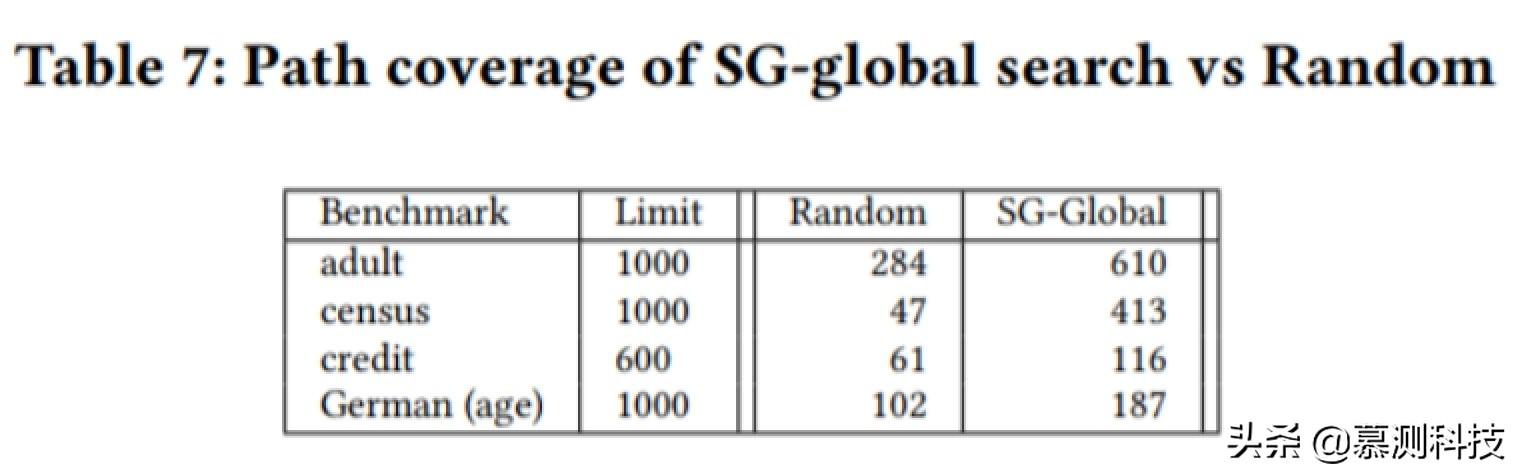
我們進行了一個實驗來比較我們的全局搜索和基于隨機數(shù)據(jù)的搜索的路徑覆蓋率。基于隨機數(shù)據(jù)的搜索已經(jīng)被應(yīng)用于 THEMIS 和 AEQUITAS。因此,本實驗提出了與現(xiàn)有相關(guān)工作的比較。為了進行路徑覆蓋,我們學(xué)習(xí)了一個精度為 85%-95%的決策樹模型,對每個基準(zhǔn)使用 5 倍交叉驗證來測量,并將每個生成的測試輸入映射到?jīng)Q策樹模型的路徑上。表 7 的結(jié)果顯示,在所有的基準(zhǔn)中,SG 的平均路徑覆蓋率是隨機數(shù)據(jù)的 2.66 倍。這個結(jié)果表明,在路徑覆蓋率指標(biāo)上,我們優(yōu)于其他算法。因此,我們的算法將能夠在模型的各個不同地方找到偏見性的輸入。這一點很重要,因為在一次實驗中,如果我們使用測試用例進行再訓(xùn)練,我們可以對模型的多個部分進行去偏見。
論文總結(jié)
在本文中,我們提出了一種測試用例生成算法,用于識別機器學(xué)習(xí)模型中的個體歧視問題。我們的方法結(jié)合了符號評價的概念,它為任何程序系統(tǒng)地生成測試輸入,并使用線性和可解釋的模型來近似模型中的執(zhí)行路徑的局部解釋。我們的技術(shù)還提供了一個額外的優(yōu)勢,因為它是黑盒性質(zhì)的。我們的搜索策略主要橫跨兩種方法,即全局搜索和局部搜索。全局搜索迎合了路徑覆蓋率的要求,有助于發(fā)現(xiàn)初始的判別輸入集。為了實現(xiàn)這一點,我們使用種子數(shù)據(jù)與符號執(zhí)行,同時考慮本地模型中存在的近似,并智能地使用與本地模型中獲取的路徑約束相關(guān)的置信度。此外,局部搜索的目的是尋找越來越多的判別性輸入。它從初始的可用判別路徑集開始,并生成屬于附近執(zhí)行路徑的其他輸入,從而系統(tǒng)地進行局部解釋,同時依靠對抗性魯棒性屬性。我們的實驗評估清楚地表明,我們的方法比所有現(xiàn)有的工具表現(xiàn)得更好。
致謝
本文由南京大學(xué)軟件學(xué)院 2019 級碩士郭子琛翻譯轉(zhuǎn)述。





