

作者:MARCIN ZAB?OCKI
編譯:ronghuaiyang
導讀
如何使用SimCLR框架進行對比學習,看這個就明白了。
在過去的幾個月中,NLP和計算機視覺的遷移學習和預訓練受到了廣泛的關注。研究表明,精心設計的無監督/自監督訓練可以產生高質量的基礎模型和嵌入,這大大減少了下游獲得良好分類模型所需的數據量。這種方法變得越來越重要,因為公司收集了大量的數據,但其中只有一部分可以被人類標記 —— 要么是由于標記過程的巨大成本,要么是由于一些時間限制。
在這里,我將探討谷歌在這篇arxiv論文中提出的SimCLR預訓練框架。我將逐步解釋SimCLR和它的對比損失函數,從簡單的實現開始,然后是更快的向量化的實現。然后,我將展示如何使用SimCLR的預訓練例程,首先使用EfficientNet網絡架構構建圖像嵌入,最后,我將展示如何在它的基礎上構建一個分類器。
理解SimCLR框架
一般來說,SimCLR是一個簡單的視覺表示的對比學習框架。這不是什么新的深度學習框架,它是一套固定的步驟,為了訓練高質量的圖像嵌入。我畫了一個圖來解釋這個流程和整個表示學習過程。

流程如下(從左到右):
- 取一個輸入圖像
- 準備2個隨機的圖像增強,包括:旋轉,顏色/飽和度/亮度變化,縮放,裁剪等。文中詳細討論了增強的范圍,并分析了哪些增廣效果最好。
- 運行一個深度神經網絡(最好是卷積神經網絡,如ResNet50)來獲得那些增強圖像的圖像表示(嵌入)。
- 運行一個小的全連接線性神經網絡,將嵌入投影到另一個向量空間。
- 計算對比損失并通過兩個網絡進行反向傳播。當來自同一圖像的投影相似時,對比損失減少。投影之間的相似度可以是任意的,這里我使用余弦相似度,和論文中一樣。
對比損失函數
對比損失函數背后的理論
對比損失函數可以從兩個角度來解釋:
- 當來自相同輸入圖像的增強圖像投影相似時,對比損失減小。
- 對于兩個增強的圖像(i), (j)(來自相同的輸入圖像 — 我稍后將稱它們為“正”樣本對),(i)的對比損失試圖在同一個batch中的其他圖像(“負”樣本)中識別出(j)。
對正樣本對(i)和(j)的損失的形式化定義為:
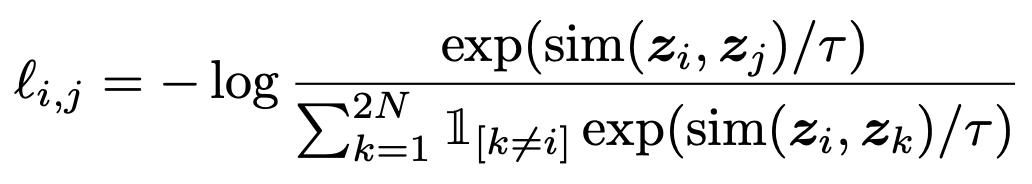
最終的損失是batch中所有正樣本對損失的算術平均值:
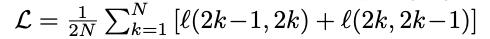
請記住,在*l(2k- 1,2k) + l(2k, 2k-1)中的索引完全取決于你如何實現損失 —— 我發現當我把它們解釋為l(i,j) + l(j, i)*時,更容易理解。
對比損失函數 — PyTorch的實現
如果不先進行矢量化,那么實現損失函數就容易得多,然后再進行矢量化。
import torch
from torch import nn
import torch.nn.functional as F
class ContrastiveLossELI5(nn.Module):
def __init__(self, batch_size, temperature=0.5, verbose=True):
super().__init__()
self.batch_size = batch_size
self.register_buffer("temperature", torch.tensor(temperature))
self.verbose = verbose
def forward(self, emb_i, emb_j):
"""
emb_i and emb_j are batches of embeddings, where corresponding indices are pairs
z_i, z_j as per SimCLR paper
"""
z_i = F.normalize(emb_i, dim=1)
z_j = F.normalize(emb_j, dim=1)
representations = torch.cat([z_i, z_j], dim=0)
similarity_matrix = F.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0), dim=2)
if self.verbose: print("Similarity matrixn", similarity_matrix, "n")
def l_ij(i, j):
z_i_, z_j_ = representations[i], representations[j]
sim_i_j = similarity_matrix[i, j]
if self.verbose: print(f"sim({i}, {j})={sim_i_j}")
numerator = torch.exp(sim_i_j / self.temperature)
one_for_not_i = torch.ones((2 * self.batch_size, )).to(emb_i.device).scatter_(0, torch.tensor([i]), 0.0)
if self.verbose: print(f"1{{k!={i}}}",one_for_not_i)
denominator = torch.sum(
one_for_not_i * torch.exp(similarity_matrix[i, :] / self.temperature)
)
if self.verbose: print("Denominator", denominator)
loss_ij = -torch.log(numerator / denominator)
if self.verbose: print(f"loss({i},{j})={loss_ij}n")
return loss_ij.squeeze(0)
N = self.batch_size
loss = 0.0
for k in range(0, N):
loss += l_ij(k, k + N) + l_ij(k + N, k)
return 1.0 / (2*N) * loss解釋
對比損失需要知道batch大小和temperature(尺度)參數。你可以在論文中找到設置最佳temperature參數的細節。
我的對比損失的forward的實現中有兩個參數。第一個是第一次增強后的圖像batch的投影,第二個是第二次增強后的圖像batch的投影。
投影首先需要標準化,因此:
z_i = F.normalize(emb_i, dim=1)
z_j = F.normalize(emb_j, dim=1)所有的表示被拼接在一起,以有效地計算每個圖像對之間的余弦相似度。
representations = torch.cat([z_i, z_j], dim=0)
similarity_matrix = F.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0), dim=2)接下來是簡單的*l(i,j)*實現,便于理解。下面的代碼幾乎直接實現了這個等式:
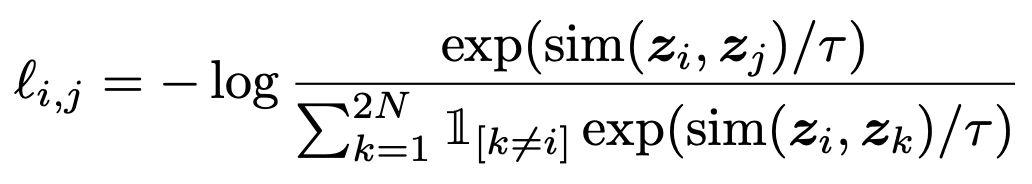
def l_ij(i, j):
z_i_, z_j_ = representations[i], representations[j]
sim_i_j = similarity_matrix[i, j]
numerator = torch.exp(sim_i_j / self.temperature)
one_for_not_i = torch.ones((2 * self.batch_size, )).to(emb_i.device).scatter_(0, torch.tensor([i]), 0.0)
denominator = torch.sum(
one_for_not_i * torch.exp(similarity_matrix[i, :] / self.temperature)
)
loss_ij = -torch.log(numerator / denominator)
return loss_ij.squeeze(0)然后,該batch的最終損失計算為所有正樣本組合的算術平均值:
N = self.batch_size
loss = 0.0
for k in range(0, N):
loss += l_ij(k, k + N) + l_ij(k + N, k)
return 1.0 / (2*N) * loss現在,讓我們在verbose模式下運行它,看看里面有什么。
I = torch.tensor([[1.0, 2.0], [3.0, -2.0], [1.0, 5.0]])
J = torch.tensor([[1.0, 0.75], [2.8, -1.75], [1.0, 4.7]])
loss_eli5 = ContrastiveLossELI5(batch_size=3, temperature=1.0, verbose=True)
loss_eli5(I, J)
Similarity matrix
tensor([[ 1.0000, -0.1240, 0.9648, 0.8944, -0.0948, 0.9679],
[-0.1240, 1.0000, -0.3807, 0.3328, 0.9996, -0.3694],
[ 0.9648, -0.3807, 1.0000, 0.7452, -0.3534, 0.9999],
[ 0.8944, 0.3328, 0.7452, 1.0000, 0.3604, 0.7533],
[-0.0948, 0.9996, -0.3534, 0.3604, 1.0000, -0.3419],
[ 0.9679, -0.3694, 0.9999, 0.7533, -0.3419, 1.0000]])
sim(0, 3)=0.8944272398948669
1{k!=0} tensor([0., 1., 1., 1., 1., 1.])
Denominator tensor(9.4954)
loss(0,3)=1.3563847541809082
sim(3, 0)=0.8944272398948669
1{k!=3} tensor([1., 1., 1., 0., 1., 1.])
Denominator tensor(9.5058)
loss(3,0)=1.357473373413086
sim(1, 4)=0.9995677471160889
1{k!=1} tensor([1., 0., 1., 1., 1., 1.])
Denominator tensor(6.3699)
loss(1,4)=0.8520082831382751
sim(4, 1)=0.9995677471160889
1{k!=4} tensor([1., 1., 1., 1., 0., 1.])
Denominator tensor(6.4733)
loss(4,1)=0.8681114912033081
sim(2, 5)=0.9999250769615173
1{k!=2} tensor([1., 1., 0., 1., 1., 1.])
Denominator tensor(8.8348)
loss(2,5)=1.1787779331207275
sim(5, 2)=0.9999250769615173
1{k!=5} tensor([1., 1., 1., 1., 1., 0.])
Denominator tensor(8.8762)
loss(5,2)=1.1834462881088257
tensor(1.1327)這里發生了一些事情,但是通過在冗長的日志和方程之間來回切換,一切都應該變得清楚了。由于相似度矩陣的構造方式,索引按batch大小跳躍,首先是l(0,3), l(3,0),然后是l(1,4), l(4,1)。similarity_matrix的第一行為:
[ 1.0000, -0.1240, 0.9648, 0.8944, -0.0948, 0.9679]記住這個輸入:
I = torch.tensor([[1.0, 2.0], [3.0, -2.0], [1.0, 5.0]])
J = torch.tensor([[1.0, 0.75], [2.8, -1.75], [1.0, 4.7]])現在:
1.0000 是 I[0] and I[0]([1.0, 2.0] and [1.0, 2.0]) 之間的余弦相似度
-0.1240是I[0] and I[1] ([1.0, 2.0] and [3.0, -2.0])之間的余弦相似度
-0.0948是I[0] and J[2] ([1.0, 2.0] and [2.8, -1.75])之間的余弦相似度
等等
第一次的圖像投影之間的相似性越高,損失越小:
I = torch.tensor([[1.0, 2.0], [3.0, -2.0], [1.0, 5.0]])
J = torch.tensor([[1.0, 0.75], [2.8, -1.75], [1.0, 4.7]])
J = torch.tensor([[1.0, 1.75], [2.8, -1.75], [1.0, 4.7]]) # note the change
ContrastiveLossELI5(3, 1.0, verbose=False)(I, J)
tensor(1.0996)的確,損失減少了!現在我將繼續介紹向量化的實現。
對比損失函數 — PyTorch的實現,向量版本
樸素的實現的性能真的很差(主要是由于手動循環),看看結果:
contrastive_loss_eli5 = ContrastiveLossELI5(3, 1.0, verbose=False)
I = torch.tensor([[1.0, 2.0], [3.0, -2.0], [1.0, 5.0]], requires_grad=True)
J = torch.tensor([[1.0, 0.75], [2.8, -1.75], [1.0, 4.7]], requires_grad=True)
%%timeit
contrastive_loss_eli5(I, J)
838 µs ± 23.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)一旦我理解了損失的內在,就很容易對其進行向量化并去掉手動循環:
class ContrastiveLoss(nn.Module):
def __init__(self, batch_size, temperature=0.5):
super().__init__()
self.batch_size = batch_size
self.register_buffer("temperature", torch.tensor(temperature))
self.register_buffer("negatives_mask", (~torch.eye(batch_size * 2, batch_size * 2, dtype=bool)).float())
def forward(self, emb_i, emb_j):
"""
emb_i and emb_j are batches of embeddings, where corresponding indices are pairs
z_i, z_j as per SimCLR paper
"""
z_i = F.normalize(emb_i, dim=1)
z_j = F.normalize(emb_j, dim=1)
representations = torch.cat([z_i, z_j], dim=0)
similarity_matrix = F.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0), dim=2)
sim_ij = torch.diag(similarity_matrix, self.batch_size)
sim_ji = torch.diag(similarity_matrix, -self.batch_size)
positives = torch.cat([sim_ij, sim_ji], dim=0)
nominator = torch.exp(positives / self.temperature)
denominator = self.negatives_mask * torch.exp(similarity_matrix / self.temperature)
loss_partial = -torch.log(nominator / torch.sum(denominator, dim=1))
loss = torch.sum(loss_partial) / (2 * self.batch_size)
return loss
contrastive_loss = ContrastiveLoss(3, 1.0)
contrastive_loss(I, J).item() - contrastive_loss_eli5(I, J).item()
0.0差應為零或接近零,性能比較:
I = torch.tensor([[1.0, 2.0], [3.0, -2.0], [1.0, 5.0]], requires_grad=True)
J = torch.tensor([[1.0, 0.75], [2.8, -1.75], [1.0, 4.7]], requires_grad=True)
%%timeit
contrastive_loss_eli5(I, J)
918 µs ± 60.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%%timeit
contrastive_loss(I, J)
272 µs ± 9.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)幾乎是4倍的提升,非常有效。
使用SimCLR和EfficientNet預訓練圖像嵌入
一旦建立并理解了損失函數,就是時候好好利用它了。我將使用EfficientNet架構,按照SimCLR框架對圖像嵌入進行預訓練。為了方便起見,我實現了幾個實用函數和類,我將在下面簡要解釋它們。訓練代碼使用PyTorch-Lightning構造。
我使用了EfficientNet,在ImageNet上進行了預訓練,我選擇的數據集是STL10,包含了訓練和未標記的分割,用于無監督/自監督學習任務。
我在這里的目標是演示整個SimCLR流程。我并不是要使用當前的配置獲得新的SOTA。
圖像增強函數
使用SimCLR進行訓練可以生成良好的圖像嵌入,而不會受到圖像變換的影響 —— 這是因為在訓練期間,進行了各種數據增強,以迫使網絡理解圖像的內容,而不考慮圖像的顏色或圖像中物體的位置。SimCLR的作者說,數據增強的組成在定義有效的預測任務中扮演著關鍵的角色,而且對比學習需要比監督學習更強的數據增強。綜上所述:在對圖像嵌入進行預訓練時,最好通過對圖像進行強增強,使網絡學習變得困難一些,以便以后更好地進行泛化。
我強烈建議閱讀SimCLR的論文和附錄,因為他們做了消融研究,數據增加對嵌入帶來最好的效果。
為了讓這篇博文更簡單,我將主要使用內置的Torchvision數據增強功能,還有一個額外功能 —— 隨機調整縮放旋轉。
def random_rotate(image):
if random.random() > 0.5:
return tvf.rotate(image, angle=random.choice((0, 90, 180, 270)))
return image
class ResizedRotation():
def __init__(self, angle, output_size=(96, 96)):
self.angle = angle
self.output_size = output_size
def angle_to_rad(self, ang): return np.pi * ang / 180.0
def __call__(self, image):
w, h = image.size
new_h = int(np.abs(w * np.sin(self.angle_to_rad(90 - self.angle))) + np.abs(h * np.sin(self.angle_to_rad(self.angle))))
new_w = int(np.abs(h * np.sin(self.angle_to_rad(90 - self.angle))) + np.abs(w * np.sin(self.angle_to_rad(self.angle))))
img = tvf.resize(image, (new_w, new_h))
img = tvf.rotate(img, self.angle)
img = tvf.center_crop(img, self.output_size)
return img
class WrapWithRandomParams():
def __init__(self, constructor, ranges):
self.constructor = constructor
self.ranges = ranges
def __call__(self, image):
randoms = [float(np.random.uniform(low, high)) for _, (low, high) in zip(range(len(self.ranges)), self.ranges)]
return self.constructor(*randoms)(image)
from torchvision.datasets import STL10
import torchvision.transforms.functional as tvf
from torchvision import transforms
import numpy as np簡單看一下變換結果:
stl10_unlabeled = STL10(".", split="unlabeled", download=True)
idx = 123
random_resized_rotation = WrapWithRandomParams(lambda angle: ResizedRotation(angle), [(0.0, 360.0)])
random_resized_rotation(tvf.resize(stl10_unlabeled[idx][0], (96, 96)))
自動數據增強wrApper
在這里,我還實現了一個dataset wrapper,它在每次檢索圖像時自動應用隨機數據擴充。它可以很容易地與任何圖像數據集一起使用,只要它遵循簡單的接口返回 tuple ,(PIL Image, anything)。當把debug 標志設置為True,可以將這個wrapper設置為返回一個確定性轉換。請注意,有一個preprocess步驟,應用ImageNet的數據標準化,因為我使用的是預訓練好的EfficientNet。
from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler, SequentialSampler
import random
class PretrainingDatasetWrapper(Dataset):
def __init__(self, ds: Dataset, target_size=(96, 96), debug=False):
super().__init__()
self.ds = ds
self.debug = debug
self.target_size = target_size
if debug:
print("DATASET IN DEBUG MODE")
# I will be using network pre-trained on ImageNet first, which uses this normalization.
# Remove this, if you're training from scratch or apply different transformations accordingly
self.preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
random_resized_rotation = WrapWithRandomParams(lambda angle: ResizedRotation(angle, target_size), [(0.0, 360.0)])
self.randomize = transforms.Compose([
transforms.RandomResizedCrop(target_size, scale=(1/3, 1.0), ratio=(0.3, 2.0)),
transforms.RandomChoice([
transforms.RandomHorizontalFlip(p=0.5),
transforms.Lambda(random_rotate)
]),
transforms.RandomApply([
random_resized_rotation
], p=0.33),
transforms.RandomApply([
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.2)
], p=0.8),
transforms.RandomGrayscale(p=0.2)
])
def __len__(self): return len(self.ds)
def __getitem_internal__(self, idx, preprocess=True):
this_image_raw, _ = self.ds[idx]
if self.debug:
random.seed(idx)
t1 = self.randomize(this_image_raw)
random.seed(idx + 1)
t2 = self.randomize(this_image_raw)
else:
t1 = self.randomize(this_image_raw)
t2 = self.randomize(this_image_raw)
if preprocess:
t1 = self.preprocess(t1)
t2 = self.preprocess(t2)
else:
t1 = transforms.ToTensor()(t1)
t2 = transforms.ToTensor()(t2)
return (t1, t2), torch.tensor(0)
def __getitem__(self, idx):
return self.__getitem_internal__(idx, True)
def raw(self, idx):
return self.__getitem_internal__(idx, False)
ds = PretrainingDatasetWrapper(stl10_unlabeled, debug=False)
tvf.to_pil_image(ds[idx][0][0])
tvf.to_pil_image(ds[idx][0][1])
tvf.to_pil_image(ds.raw(idx)[0][1])
tvf.to_pil_image(ds.raw(idx)[0][0])
SimCLR神經網絡生成嵌入
這里我定義了基于EfficientNet-b0架構的ImageEmbedding神經網絡。我用identity函數替換了EfficientNet 的最后一層,在它的上面(跟在SimCLR的后面)添加了Linear-ReLU-Linear 層得到圖像嵌入。本文表明,非線性投影頭,也就是Linear-ReLU-Linear提高嵌入的質量。
from efficientnet_pytorch import EfficientNet
class ImageEmbedding(nn.Module):
class Identity(nn.Module):
def __init__(self): super().__init__()
def forward(self, x):
return x
def __init__(self, embedding_size=1024):
super().__init__()
base_model = EfficientNet.from_pretrained("efficientnet-b0")
internal_embedding_size = base_model._fc.in_features
base_model._fc = ImageEmbedding.Identity()
self.embedding = base_model
self.projection = nn.Sequential(
nn.Linear(in_features=internal_embedding_size, out_features=embedding_size),
nn.ReLU(),
nn.Linear(in_features=embedding_size, out_features=embedding_size)
)
def calculate_embedding(self, image):
return self.embedding(image)
def forward(self, X):
image = X
embedding = self.calculate_embedding(image)
projection = self.projection(embedding)
return embedding, projection接下來是基于PyTorch-Lightning的訓練模塊的實現,它將所有的事情協調在一起:
- 超參數處理
- SimCLR圖像嵌入網絡
- STL10數據集
- 優化器
- 前向步驟
在PretrainingDatasetWrapper中,我實現了返回元組:(Image1, Image2), dummy class,這個模塊的前向步驟是很簡單的,它需要產生兩個batch的嵌入和計算對比損失函數:
(X, Y), y = batch
embX, projectionX = self.forward(X)
embY, projectionY = self.forward(Y)
loss = self.loss(projectionX, projectionY)
from torch.multiprocessing import cpu_count
from torch.optim import RMSprop
import pytorch_lightning as pl
class ImageEmbeddingModule(pl.LightningModule):
def __init__(self, hparams):
hparams = Namespace(**hparams) if isinstance(hparams, dict) else hparams
super().__init__()
self.hparams = hparams
self.model = ImageEmbedding()
self.loss = ContrastiveLoss(hparams.batch_size)
def total_steps(self):
return len(self.train_dataloader()) // self.hparams.epochs
def train_dataloader(self):
return DataLoader(PretrainingDatasetWrapper(stl10_unlabeled,
debug=getattr(self.hparams, "debug", False)),
batch_size=self.hparams.batch_size,
num_workers=cpu_count(),
sampler=SubsetRandomSampler(list(range(hparams.train_size))),
drop_last=True)
def val_dataloader(self):
return DataLoader(PretrainingDatasetWrapper(stl10_unlabeled,
debug=getattr(self.hparams, "debug", False)),
batch_size=self.hparams.batch_size,
shuffle=False,
num_workers=cpu_count(),
sampler=SequentialSampler(list(range(hparams.train_size + 1, hparams.train_size + hparams.validation_size))),
drop_last=True)
def forward(self, X):
return self.model(X)
def step(self, batch, step_name = "train"):
(X, Y), y = batch
embX, projectionX = self.forward(X)
embY, projectionY = self.forward(Y)
loss = self.loss(projectionX, projectionY)
loss_key = f"{step_name}_loss"
tensorboard_logs = {loss_key: loss}
return { ("loss" if step_name == "train" else loss_key): loss, 'log': tensorboard_logs,
"progress_bar": {loss_key: loss}}
def training_step(self, batch, batch_idx):
return self.step(batch, "train")
def validation_step(self, batch, batch_idx):
return self.step(batch, "val")
def validation_end(self, outputs):
if len(outputs) == 0:
return {"val_loss": torch.tensor(0)}
else:
loss = torch.stack([x["val_loss"] for x in outputs]).mean()
return {"val_loss": loss, "log": {"val_loss": loss}}
def configure_optimizers(self):
optimizer = RMSprop(self.model.parameters(), lr=self.hparams.lr)
return [optimizer], []超參數初始化。Batch size大小為128,在GTX1070上使用EfficientNet-B0運行的很好。注意,為了方便以Jupyter Notebook /google Colab的形式運行這篇博客文章,我將訓練數據集限制為STL10的前10k圖像。
重要!SimCLR從大Batch size中得到了極大的好處 —— 它應該在GPU/集群限制下被設置為盡可能高。
from argparse import Namespace
hparams = Namespace(
lr=1e-3,
epochs=50,
batch_size=160,
train_size=10000,
validation_size=1000
)使用LRFinder算法尋找好的初始學習率
我使用pytorch-lightning的內置LRFinder算法來查找初始學習率。
module = ImageEmbeddingModule(hparams)
t = pl.Trainer(gpus=1)
lr_finder = t.lr_find(module)
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
------------------------------------------
0 | model | ImageEmbedding | 6 M
1 | loss | ContrastiveLoss | 0
lr_finder.plot(show=False, suggest=True)
lr_finder.suggestion()
0.000630957344480193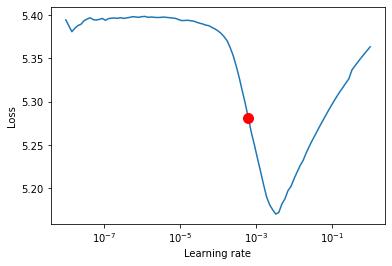
我也使用W&B日志記錄我的實驗:
from pytorch_lightning.loggers import WandbLogger
hparams = Namespace(
lr=0.000630957344480193,
epochs=10,
batch_size=160,
train_size=20000,
validation_size=1000
)
module = ImageEmbeddingModule(hparams)
logger = WandbLogger(project="simclr-blogpost")
logger.watch(module, log="all", log_freq=50)
trainer = pl.Trainer(gpus=1, logger=logger)
trainer.fit(module)
| Name | Type | Params
------------------------------------------
0 | model | ImageEmbedding | 6 M
1 | loss | ContrastiveLoss | 0 訓練完成后,圖像嵌入就可以用于下游任務了。
在SimCLR嵌入上進行圖像分類
一旦訓練好嵌入,它們就可以用來訓練在它們之上的分類器 —— 可以通過微調整個網絡,也可以通過用嵌入凍結基礎網絡并在其之上學習線性分類器 ——下面我將展示后者。
使用嵌入保存神經網絡的權值
我以檢查點的形式保存整個網絡。之后,只有網絡的內部部分將與分類器一起使用(投影層將被丟棄)。
checkpoint_file = "efficientnet-b0-stl10-embeddings.ckpt"
trainer.save_checkpoint(checkpoint_file)
trainer.logger.experiment.log_artifact(checkpoint_file, type="model")分類器模塊
同樣,我定義了一個自定義模塊 —— 這次它使用了已經存在的嵌入并根據需要凍結了基礎模型的權重。注意SimCLRClassifier.embeddings只是整個網絡之前使用的EfficientNet的一部分 —— 投影頭被丟棄。
class SimCLRClassifier(nn.Module):
def __init__(self, n_classes, freeze_base, embeddings_model_path, hidden_size=512):
super().__init__()
base_model = ImageEmbeddingModule.load_from_checkpoint(embeddings_model_path).model
self.embeddings = base_model.embedding
if freeze_base:
print("Freezing embeddings")
for param in self.embeddings.parameters():
param.requires_grad = False
# Only linear projection on top of the embeddings should be enough
self.classifier = nn.Linear(in_features=base_model.projection[0].in_features,
out_features=n_classes if n_classes > 2 else 1)
def forward(self, X, *args):
emb = self.embeddings(X)
return self.classifier(emb)分類器訓練代碼
分類器訓練代碼再次使用PyTorch lightning,所以我跳過了深入的解釋。
from torch import nn
from torch.optim.lr_scheduler import CosineAnnealingLR
class SimCLRClassifierModule(pl.LightningModule):
def __init__(self, hparams):
super().__init__()
hparams = Namespace(**hparams) if isinstance(hparams, dict) else hparams
self.hparams = hparams
self.model = SimCLRClassifier(hparams.n_classes, hparams.freeze_base,
hparams.embeddings_path,
self.hparams.hidden_size)
self.loss = nn.CrossEntropyLoss()
def total_steps(self):
return len(self.train_dataloader()) // self.hparams.epochs
def preprocessing(seff):
return transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
def get_dataloader(self, split):
return DataLoader(STL10(".", split=split, transform=self.preprocessing()),
batch_size=self.hparams.batch_size,
shuffle=split=="train",
num_workers=cpu_count(),
drop_last=False)
def train_dataloader(self):
return self.get_dataloader("train")
def val_dataloader(self):
return self.get_dataloader("test")
def forward(self, X):
return self.model(X)
def step(self, batch, step_name = "train"):
X, y = batch
y_out = self.forward(X)
loss = self.loss(y_out, y)
loss_key = f"{step_name}_loss"
tensorboard_logs = {loss_key: loss}
return { ("loss" if step_name == "train" else loss_key): loss, 'log': tensorboard_logs,
"progress_bar": {loss_key: loss}}
def training_step(self, batch, batch_idx):
return self.step(batch, "train")
def validation_step(self, batch, batch_idx):
return self.step(batch, "val")
def test_step(self, batch, batch_idx):
return self.step(Batch, "test")
def validation_end(self, outputs):
if len(outputs) == 0:
return {"val_loss": torch.tensor(0)}
else:
loss = torch.stack([x["val_loss"] for x in outputs]).mean()
return {"val_loss": loss, "log": {"val_loss": loss}}
def configure_optimizers(self):
optimizer = RMSprop(self.model.parameters(), lr=self.hparams.lr)
schedulers = [
CosineAnnealingLR(optimizer, self.hparams.epochs)
] if self.hparams.epochs > 1 else []
return [optimizer], schedulers這里值得一提的是,使用frozen的基礎模型進行訓練可以在訓練過程中極大地提高性能,因為只需要計算單個層的梯度。此外,利用良好的嵌入,只需幾個epoch就能得到高質量的單線性投影分類器。
hparams_cls = Namespace(
lr=1e-3,
epochs=5,
batch_size=160,
n_classes=10,
freeze_base=True,
embeddings_path="./efficientnet-b0-stl10-embeddings.ckpt",
hidden_size=512
)
module = SimCLRClassifierModule(hparams_cls)
logger = WandbLogger(project="simclr-blogpost-classifier")
logger.watch(module, log="all", log_freq=10)
trainer = pl.Trainer(gpus=1, max_epochs=hparams_cls.epochs, logger=logger)
lr_find_cls = trainer.lr_find(module)
| Name | Type | Params
-------------------------------------------
0 | model | SimCLRClassifier | 4 M
1 | loss | CrossEntropyLoss | 0
LR finder stopped early due to diverging loss.
lr_find_cls.plot(show=False, suggest=True)
lr_find_cls.suggestion()
0.003981071705534969
hparams_cls = Namespace(
lr=0.003981071705534969,
epochs=5,
batch_size=160,
n_classes=10,
freeze_base=True,
embeddings_path="./efficientnet-b0-stl10-embeddings.ckpt",
hidden_size=512
)
module = SimCLRClassifierModule(hparams_cls)
trainer.fit(module)
| Name | Type | Params
-------------------------------------------
0 | model | SimCLRClassifier | 4 M
1 | loss | CrossEntropyLoss | 0 評估
這里我定義了一個utility函數,用來評估模型。注意,對于大的數據集,在GPU和CPU之間的傳輸和存儲所有的結果在內存中是不可能的。
from sklearn.metrics import classification_report
def evaluate(data_loader, module):
with torch.no_grad():
progress = ["/", "-", "\", "|", "/", "-", "\", "|"]
module.eval().cuda()
true_y, pred_y = [], []
for i, batch_ in enumerate(data_loader):
X, y = batch_
print(progress[i % len(progress)], end="r")
y_pred = torch.argmax(module(X.cuda()), dim=1)
true_y.extend(y.cpu())
pred_y.extend(y_pred.cpu())
print(classification_report(true_y, pred_y, digits=3))
return true_y, pred_y
_ = evaluate(module.val_dataloader(), module)
precision recall f1-score support
0 0.856 0.864 0.860 800
1 0.714 0.701 0.707 800
2 0.903 0.919 0.911 800
3 0.678 0.599 0.636 800
4 0.665 0.746 0.703 800
5 0.633 0.564 0.597 800
6 0.729 0.781 0.754 800
7 0.678 0.709 0.693 800
8 0.868 0.910 0.888 800
9 0.862 0.801 0.830 800
accuracy 0.759 8000
macro avg 0.759 0.759 0.758 8000
weighted avg 0.759 0.759 0.758 8000總結
我希望我對SimCLR框架的解釋對你有所幫助。
英文原文:https://zablo.net/blog/post/understanding-implementing-simclr-guide-eli5-pytorch/






