
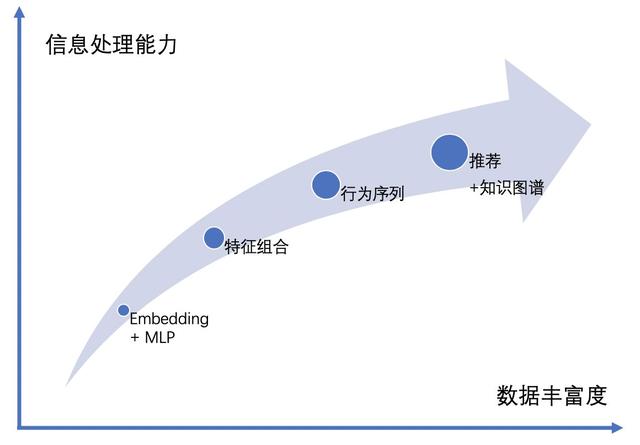
近些年,隨著深度學習理論,GPU 和 CPU 等計算機硬件,TensorFlow、Caffe、PyTorch 等算法平臺的發展,深度學習算法在個性化推薦、計算機視覺、自然語言處理、語音識別等領域大放光彩。本文從神經網絡結構的角度梳理深度推薦算法的發展,把近幾年業界主流的算法歸納為四個階段的網絡結構:Embedding+MLP 的網絡結構,基于特征組合的網絡結構,基于用戶行為序列的網絡結構和融入知識圖譜的網絡結構。
1 基于 Embedding+MLP 的網絡結構
2016 年,谷歌發表的 Wide&Deep 模型[1]和 YouTube 深度學習推薦模型[2]在業界引起了廣泛的關注。在當時,推薦領域的深度學習算法落地還非常少,大多數公司還處在使用 CF(協同過濾)進行召回和 LR(邏輯回歸)進行排序的階段,工程師們把主要精力花在特征挖掘上來提升效果。這兩篇論文的發表給大家帶來了新方向,深度學習推薦算法的相關論文也如雨后春筍般涌現。
谷歌的這兩個模型都是基于 Embedding + MLP 的網絡結構。Embedding 的應用使得深度學習算法有了強有力的離散特征處理能力,MLP(多層感知機)使得算法有了強大的非線性擬合能力。兩者的配合使用,模型的擬合能力大大超越了使用 0-1 離散特征的 LR 模型。Embedding + MLP 的網絡結構也成為了當前深度學習推薦算法的基礎結構。
1.1 YouTube Model
谷歌在《Deep Neural Networks for YouTube Recommendations》[2]論文中提出的召回模型不僅算法具有創新性,而且在大規模召回的工業場景中非常實用。通過抽取最后一層的用戶向量和視頻向量,配合高效的近鄰搜索算法,可以實現工業級的在線大規模召回。這篇論文有更多的技術細節值得深究,可參考知乎的一些解讀,這里不在贅述。e.g. https://zhuanlan.zhihu.com/p/52169807
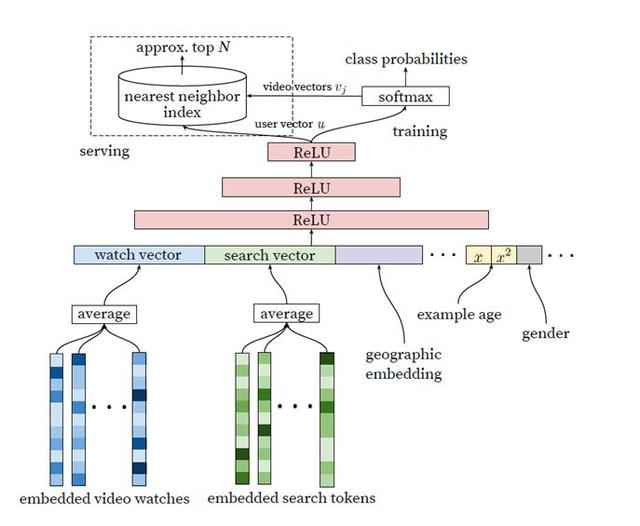
1.2 Wide&Deep Model
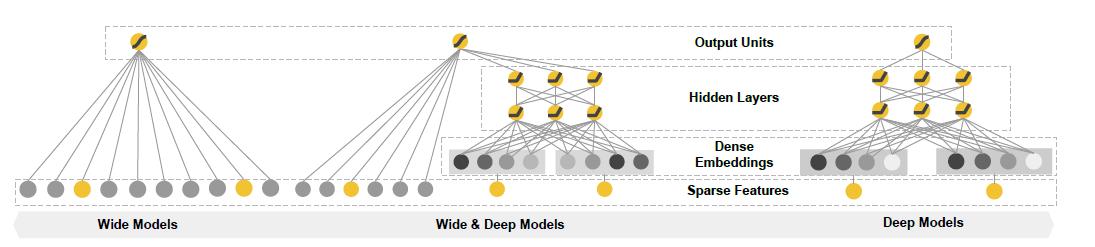
在《Wide & Deep Learning for Recommender Systems》[1]中,Wide 側使用的是線性結構 y= w*x +b,通過對 0-1 離散特征的交叉組合,模型可以非常有效地學到這部分可解釋性非常強的信息。Deep 側則采用了 Embedding+MLP 的結構,通過 Embedding 把稀疏高維離散特征轉化成了低維稠密的連續特征,并將該特征和連續類特征拼接在一起放入 MLP 層,通過 MLP 的非線性處理能力去發現線性模型無法捕捉的更深層次特征組合效應。兩部分模型的聯合使用帶來了超越傳統模型的效果。
2 基于特征組合的網絡結構
特征工程是整個推薦工作中的重要組成部分,特征工程能帶來很好的效果提升,但同時也耗時耗力。深度學習算法天然有著強大的擬合能力,隨著神經網絡結構的發展,特征工程的復雜度和必要性在不斷的在降低,工程師們可以把更多的精力聚焦于算法的優化上。
2.1 DeepFM
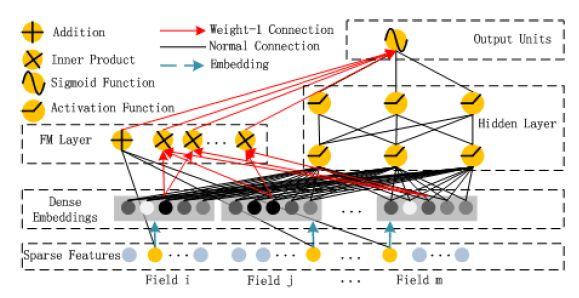
在 Wide&Deep 的模型中,Wide 側 0-1 離散特征的交叉組合帶來了很好的效果,但需要人工進行特征工程。在 2017 年發表的《DeepFM:A Factorization-machine based Neural Network for CTR Prediction》[3]的模型中,離散特征經過 Embedding 層后獲得的低維稠密向量,通過在 FM Layer 進行兩兩的 Inner product 操作實現了 Order-2 的特征組合。DeepFM 的應用,使得這個模型基本不需要特征工程,而且性能在某些數據集上超過了 Wide&Deep 模型。
仔細對比 Wide&Deep 和 DeepFM,會發現 DeepFM 只進行了 Order-2 和 Order-1 的特征組合,而 Wide&Deep 模型中的 Wide 側實現了更高階的特征組合。DeepFM 是否可以做更高階的特征組合呢?直觀的推想,在 FM Layer 可以加入 Order-3、Order-4 的特征組合,但是參數會急劇上升。在 FM Layer,假設有 m 個 field,每個 field 經 Embedding 層后形成了 k 維稠密向量,Order-2 的特征組合需要 O(k*m^2)的參數,Order-3 的特征組合則需要 O(k *m^3)的參數,參數量的快速增長導致 DeepFM 不適合進行更高階的特征組合。
2.2 Deep&Cross Net
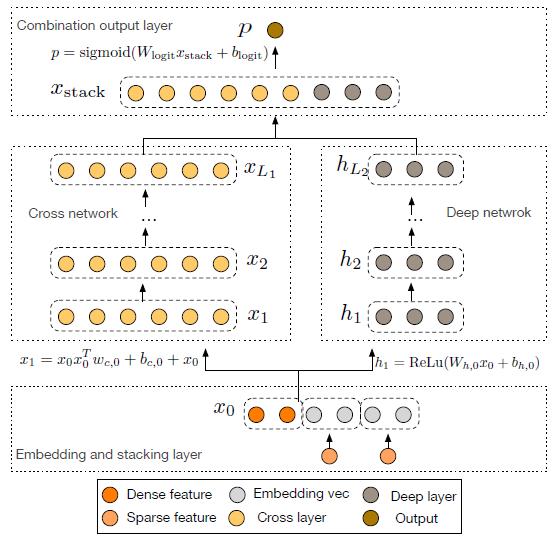
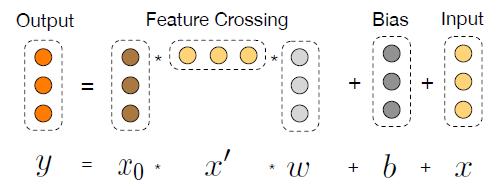
在《Deep & Cross Network for Ad Click Predictions》[4]這篇論文里直接提到了 FM、FFM 類的算法由于參數爆炸無法生成并處理高階特征組合的問題。如圖 5 所示采用了一種比較巧妙的方式進行特征組合,在 DCN 的每一層 cross net 中,參數 w 是一個 n *1 維的向量(n 為交叉特征的維數),隨著層數 k 的增長,參數是以 O(k *n)的速度增長,通過這樣的設計,Order-3、Order-4 甚至更高階的特征組合并不會帶來參數的爆炸。當然這里還是會有一些信息損失,與 DeepFM 相比較,每個交叉特征的參數并非完全獨立。
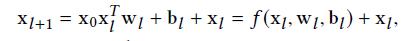
3 基于行為序列的網絡結構
在電商推薦、信息流推薦和短視頻推薦等領域,行為序列有效的代表了用戶偏好。傳統的機器學習算法,或是 Embedding+MLP 的神經網絡很難使用原始的序列作為特征,一般是把序列做進一步的特征工程才能放入模型。2017 年前后,基于行為序列的算法不斷的發展完善,逐漸成為主流的推薦算法。
基于行為序列的推薦模型總體來看存在五個挑戰[5]:
- 如何處理用戶的長行為序列;
- 如何處理行為序列中的順序,比如,相鄰兩個物品間不一定存在順序關系;
- 如何處理行為序列中的噪聲,比如,兩個有關聯的物品間可能間隔著很多其他不相關的物品;
- 如何處理行為序列中物品的異構關系,比如,物品的特征是相似的;
- 如何處理行為序列中的層次關系,比如,整個序列是由多個子序列構成,如何處理這些子序列。
3.1 RNN 型網絡結構
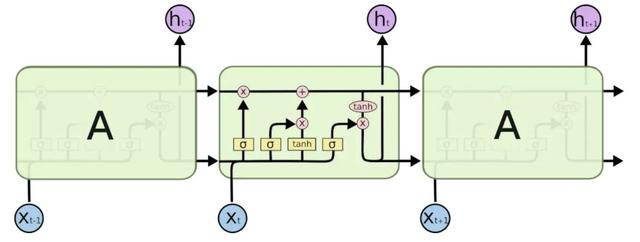
RNN、GRU 和 LSTM 被設計用來處理序列結構的數據,其計算方式是順序的,能從左往右、或從右往左依次計算。這樣的計算方式存在一些問題:時間片 t 的計算只依賴于 t-1 的結果,計算過程中信息會丟失,盡管 GRU 和 LSTM 的機制在一定程度上緩解了長期依賴的問題,但對于特別長的序列,GRU 和 LSTM 依然處理不好。一般在 RNN、GRU、LSTM 在處理序列時,會結合 pooling layer 一起使用,一方面長序列不適合直接放入下一層的全連接網絡,另一方面通過 max pooling 或者 mean pooling,可以做一定的信息抽取。總體來看,RNN 類型的網絡結構,基本無法解決前述的五個挑戰,另一方面這樣串行式的計算,在當前 GPU 的結構上運行效率較低。
3.2 Attention-Based 的網絡結構
Attention 機制的出現帶來了神經網絡發展的新方向,RNN(GRU、LSTM)結合 Attention 機制的網絡結構取得了不錯的效果。阿里巴巴的 DIN(Deep Interest Net)中 Activation Unit 也使用了相似的思想,因為用戶的興趣并不是唯一的,在面對不同的物品時,這樣 Activation Unit 的機制能夠在用戶歷史行為中行挑選出相關的信息。
谷歌的 Transformer[6]和 BERT[7]是 Attention Based Model 中的集大成者,這兩個網絡結構先后在自然語言處理領域中把算法效果提升到了新高度。
3.2.1 Transformer
在 Encoder-Decoder 架構的模型中以前一般以 RNN 為主導,Transformer 是第一個完全基于 attention 的序列模型。Transformer 的網絡結構可以把序列中任意兩個位置的距離縮小為常量,并且具有很好的并行性。在文本翻譯任務中,Transformer 的運行速度要遠遠快于 RNN 類的模型。Github 上對 Transformer 由非常好的解讀[8],這里不再贅述。
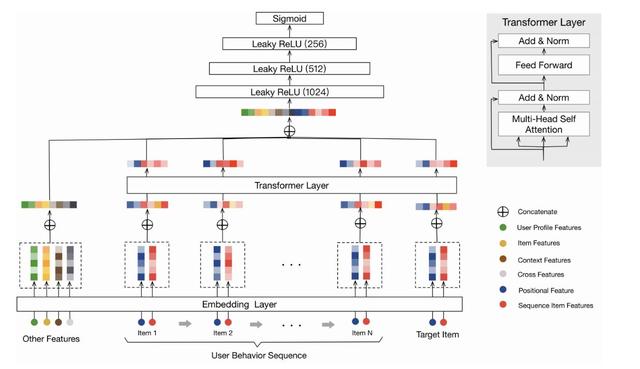
Transformer 也被應用到了推薦領域,阿里巴巴發表的《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》[9]通過 Transformer 抽取用戶行為序列中的信息,并與其他特征拼接到一起放入 MLP 層,最終建模成一個二分類問題。當然這里做了一些適配,比如原始版本的 Transformer 中使用了 positional embedding 來捕捉句子中的順序信息,在推薦中,作者使用了物品曝光時間與點擊時間之間的差作為“positional embedding”的輸入。在文中,Transformer 的輸入層只使用了物品的 item_id 和 category_id 作為特征。回顧上文描述的五個挑戰,基于 Transformer 的推薦可以很好的解決前三個挑戰,后兩個問題,從網絡結構上來看,并不能很好的解決。
3.2.2 BERT
2018 年,谷歌發表了論文《Bert: Pre-training of deep bidirectional transformers for language understanding》,BERT 的全稱是 Bidirectional Encoder Representations from Transformer,從名稱上也可以看出來 BERT 從 Transformer 中取 Encoder 部分,進行雙向的表示學習。BERT 有兩個版本的模型,Base 版本使用了 12 層的 Encoder,Large 版本的使用了 24 層的 Encoder,在 NLP 領域應用時,都需要大量的數據進行預訓練,因為一般在實際應用時會使用谷歌預訓練好的 BERT 模型,然后再基于應用場景的數據進行 fine-tuning 使之很好的適用于當前的場景。論文的題目中有四個關鍵詞,Pre-training,Deep,Bidirectional,Transformer,正是這四個關鍵詞使得算法在 Language Understanding 場景中取得了 state of art 的效果。
BERT 也被應用到了推薦場景,在《BERT4Rec-Sequential Recommendation with Bidirectional》[10]中問題被定義為基于用戶的歷史行為序列來預測下一個物品。文中使用 BERT 來處理用戶的行為序列,可以說是一種比較“完美”的結構,在序列推薦中,個人認為很難再有模型在結構上能超越 BERT。不過在該文中,用戶側的特征和場景的特征沒有被應用起來,只是用了用戶行為序列,這一點其實也值得探索。和基于 Transformer 的推薦類似,序列推薦的五個挑戰中,前三個能夠很好的解決,后兩個問題從結構上看也不能很好的解決。
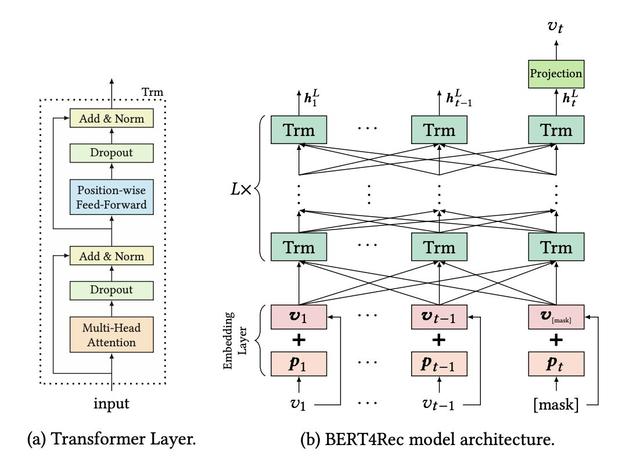
從網絡結構的角度,RNN、CNN,甚至 Transformer、BERT 都可以由全連接神經網絡表示,前者只是從全連接神經網絡中挑選了部分節點組建的網絡,但在具體應用場景中,全連接神經網絡卻無法達到前者的效果。我想原因有兩點:第一,這些具有顯著結構的神經網絡,其實是一種非常有效的先驗知識,而全連接神經網絡在當前所使用的訓練數據、訓練方法下,并不能有效地學習到這些知識;第二,和具有先驗結構的神經網絡相比,全連接神經網絡會有更多的參數,訓練的難度大大提升了。
4 推薦+知識圖譜
伴隨著 Embedding 技術和圖神經網絡算法的發展,知識圖譜在推薦系統、問答系統、社交網絡等領域得到了非常廣泛的應用。知識圖譜在推薦系統中的應用一般可以帶來三方面的收益:第一,多樣性,基于知識圖譜,可以選擇不同關系的物品進行推薦;第二,可解釋性,通過推薦物品與歷史物品間的關系可進行解釋;第三,精確性,知識圖譜刻畫了物品更加立體的信息,通過在模型中加入這些信息提升推薦的效果。
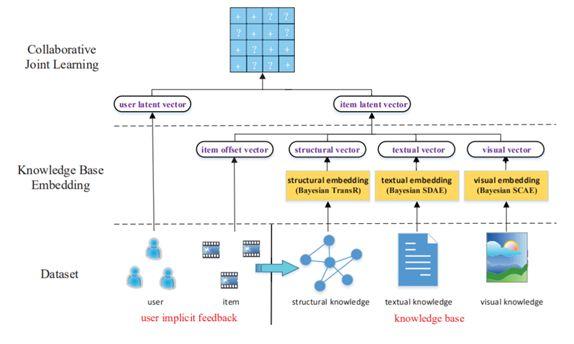
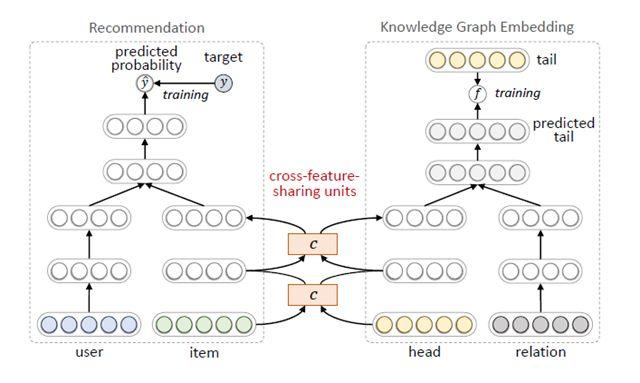
總體來看有三種訓練方式可以把知識圖譜應用到推薦模型中。第一種是依次訓練,基于知識圖譜的表示學習,把用戶和物品用低維稠密的向量表示,再把向量作為用戶和物品的特征放入推薦算法中。這種方法的優點是,知識圖譜模型可以獨立訓練,與推薦模型解耦,不影響推薦模型的訓練、預測效率;缺點是知識圖譜模型本身更適合實體分類、連接預測等知識圖譜的任務,可能并不適合推薦任務,帶來的效果增益比起端到端訓練的差。第二種是聯合訓練[11],如圖 9 所示,從知識圖譜中抽取用戶或物品的結構化信息作為特征放入模型,進行端到端的訓練。第二種方法效果必然比第一種好,但缺點是訓練和預測的效率都會變低,特別是在做在線推理的時候,帶來比較大的挑戰。第三種方法是交替訓練[12],如圖 10 所示,把推薦和知識圖譜表示學習建模成兩個獨立的任務,采用多任務學習的框架使用底層部分網絡參數的共享,在訓練時可固定一端模型的參數,訓練另一端模型,兩個交替地訓練。在推薦算法的推理階段,可獨立運行一端模型,沒有額外的開銷。通過這種方式,把知識圖譜的信息融入到推薦模型中。
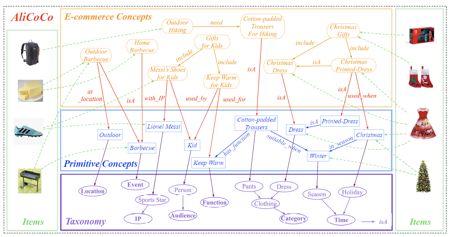
在不同的領域,一般會有基于特定場景的知識圖譜建模。在電商領域,AliCoCo[13]是阿里巴巴為搜索和推薦設計的電商知識圖譜,傳統的推薦算法往往基于用戶歷史行為而不是知識的角度進行推薦,這種推薦方式存在一個盲點,淘寶推薦使用了基于類目-屬性-屬性值的底層數據管理體系,該體系導致缺少必要的知識廣度和深度去描述用戶的需求。當用戶搜索“如何舉辦一次燒烤”時,只能返回單個或幾個類目的商品而不能理解用戶的一整套需求。如圖 11 所示,AliCoCo 設計了四層的概念體系,包括電商概念層、原子概念層、原子概念分類體系和商品層。用電商概念層去表示用戶的需求,而每個電商概念都有一個或多個原子概念組成,每個電商概念或者原子概念都會關聯多個商品。當用戶命中電商概念時,相應的主題推薦界面會被展示,里面不僅僅是食品,也有燒烤相關的工具等。通過這種方式,用戶的需求可以被更好的理解。
在零售領域,沃爾瑪不僅有線下門店也有線上門店,結合自身業務的需求,沃爾瑪建立了商品的知識圖譜[14]。通過把業務中商品與商品間的關系、商品與自然語言的關系歸納為 Describe、IsA、Co-buy、Co-view、Substitute 和 Search 六大類,把商品和詞匯定義為實體完成了圖譜的定義。再基于圖神經網絡和多任務學習,實現了實體和關系的向量化供下游推薦、搜索等場景的使用。
總結
縱觀最近五年業界主流的推薦算法,從一開始 Embedding+MLP 的網絡,發展到特征組合的網絡,再到基于用戶行為序列的網絡,到當前的推薦+知識圖譜,算法的信息處理能力不斷的變強,能夠處理的數據也越來越豐富,未來也將持續沿著這個趨勢發展。
參考文獻
[1]《Wide & Deep Learning for Recommender Systems》
[2]《Deep Neural Networks for YouTube Recommendations》
[3]《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》
[4]《Deep & Cross Network for Ad Click Predictions》
[5]《Sequential Recommender Systems: Challenges, Progress and Prospects》
[6]《Attention Is All You Need》
[7]《Bert: Pre-training of deep bidirectional transformers for language understanding》
[8] http://jalammar.github.io/illustrated-transformer/
[9]《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》
[10]《BERT4Rec-Sequential Recommendation with Bidirectional》
[11]《Collaborative knowledge base embedding for recommender systems》
[12]《Multi-task feature learning for knowledge graph enhanced recommendation》
[13]《AliCoCo: Alibaba E-commerce Cognitive Concept Net》
[14]《Product Knowledge Graph Embedding for E-commerce》
作者:ezewang,騰訊 WXG 應用研究員





