
要解決一個機器學習問題,我們不能僅僅通過將算法應用到提供的數據上。比如.fit() 。我們首先需要構建一個數據集。
將原始數據轉換為數據集的任務稱為特征工程。
例如,預測客戶是否堅持訂閱特定產品。這將有助于進一步提高產品或用戶體驗,還有助于業務增長。
原始數據將包含每個客戶的詳細信息,如位置、年齡、興趣、在產品上花費的平均時間、客戶續訂訂閱的次數。這些細節是數據集的特性。創建數據集的任務是從原始數據中了解有用的特性,并從對結果有影響的現有特性中創建新特性,或者操作這些特性,使它們可以用于建模或增強結果。整個過程被簡稱為特性工程。
有多種方法可以實現特征工程。根據數據和應用程序不同來分類。
在本文中,我們將了解為什么使用特征工程和特征工程的各種方法。
為什么使用特征工程?
特征工程出現在機器學習工作流程的最初階段。特性工程是決定結果成敗的最關鍵和決定性的因素。
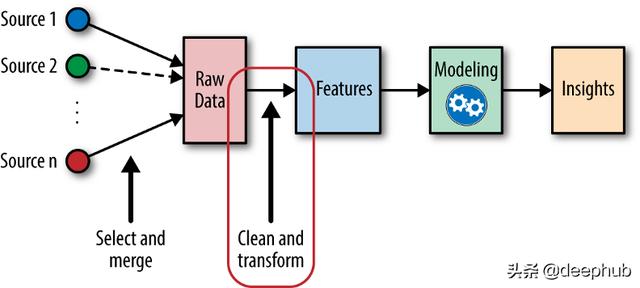
特征工程在機器學習工作流程中的地位
許多Kaggle比賽都是通過基于問題創建適當的功能而獲勝的。例如,在一場汽車轉售比賽中,獲勝者的解決方案包含一個分類特征——普通汽車的顏色,稀有汽車的顏色。這一特性增加了汽車轉售的預測效果。既然我們已經理解了特性工程的重要性,現在讓我們深入研究用于實現的各種標準方法。
現在讓我們了解如何實現特性工程。以下是廣泛使用的基本特征工程技術,
· 編碼
· 分箱
· 歸一化
· 標準化
· 處理缺失值
· 數據歸責技術
編碼
有些算法只處理數值特征。但是,我們可能有其他數據,比如在我們的例子中"用戶觀看的內容類型"。為了轉換這種數據,我們使用編碼。
One-Hot編碼
將分類數據轉換為列,并將每個惟一的類別作為列值,這是一種One-Hot編碼。
下面是實現One-Hot編碼的代碼片段,
encoded_columns = pd.get_dummies(data['column'])
data = data.join(encoded_columns).drop('column', axis=1)
當分類特征具有不那么獨特的類別時,這種方法被廣泛使用。我們需要記住,當分類特征的獨特類別增加時,維度也會增加。
標簽編碼
通過為每個類別分配一個唯一的整數值,將分類數據轉換為數字,稱為標簽編碼。
比如"喜劇"為0,"恐怖"為1,"浪漫"為2。但是,這樣劃分可能會使分類具有不必要的一般性。
當類別是有序的(特定的順序)時,可以使用這種技術,比如3代表"優秀",2代表"好",1代表"壞"。在這種情況下,對類別進行排序是有用的。
下面是要實現標簽編碼器的代碼片段。
from sklearn.preprocessing import ColumnTransformer
labelencoder = ColumnTransformer()
x[:, 0] = labelencoder.fit_transform(x[:, 0])
分箱
另一種相反的情況,在實踐中很少出現,當我們有一個數字特征,但我們需要把它轉換成分類特征。分箱(也稱為bucketing)是將一個連續的特性轉換成多個二進制特性的過程,通常基于數值。
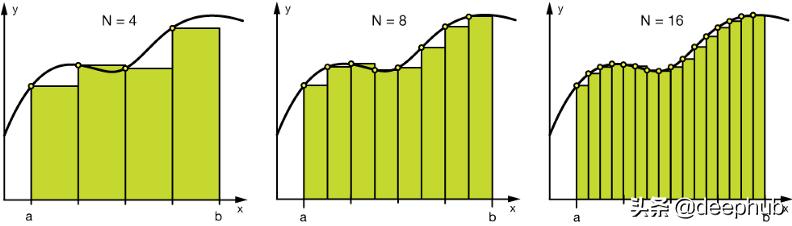
將數值數據分成4、8、16個箱子
#Numerical Binning Example
Value Bin
0-30 -> Low
31-70 -> Mid
71-100 -> High#Categorical Binning Example
Value Bin
Germany-> Europe
Italy -> Europe
India -> Asia
Japan -> Asia
分箱的主要目的是為了使模型更健壯,防止過擬合,但這對性能有一定的影響。每次我們丟棄信息,我們就會犧牲一些信息。
正則化
歸一化(也稱為最小最大歸一化)是一種縮放技術,當應用它時,特征將被重新標定,使數據落在[0,1]的范圍內。
特征的歸一化形式可通過如下方法計算:
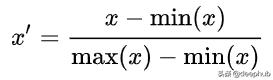
歸一化的數學公式。
這里' x '是原始值而' x '是歸一化值。

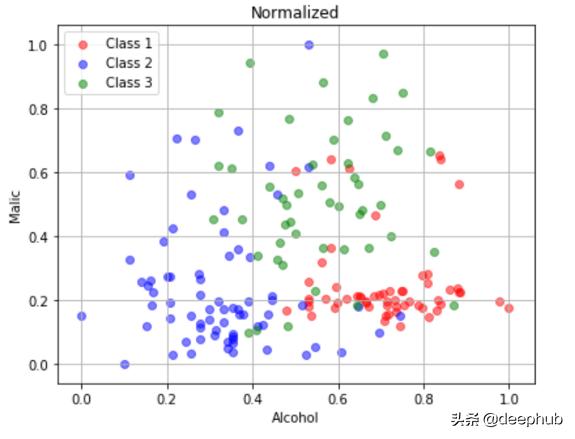
原始數據、歸一化數據的散點圖
在原始數據中,alcohol在[11,15],malic在[0,6]。歸一化數據中,alcohol在[0,1]之間,malic在[0,1]之間。
標準化
標準化(也叫Z-score歸一化)是一種縮放技術,當它被應用時,特征會被重新調整,使它們具有標準正態分布的特性,即均值為0,標準差為=1;其中,μ 為平均值(average),σ為與平均值的標準差。
計算樣本的標準分數(也稱z分數)如下:
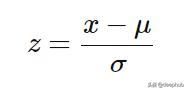
標準化的數學公式
這將特征在[-1,1]之間進行縮放

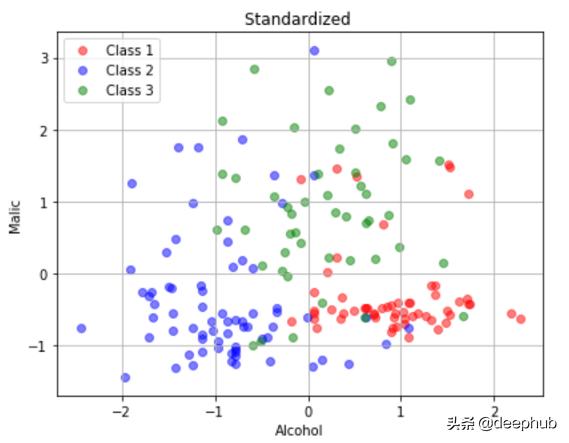
原始數據、標準化數據的散點圖
在原始數據中,alcohol在[11,15],malic在[0,6]。在標準化數據中,二者居中于0。
處理缺失值
數據集可能包含一些缺失的值。這可能是在輸入數據的失誤或出于保密方面的考慮。無論原因是什么,減少它對結果的影響是至關重要的。下面是處理缺失值的方法,
· 簡單地刪除那些缺少值的數據點(當數據很大而缺少值的數據點較少時,這樣做更可取)
· 使用處理缺失值的算法(取決于實現該算法的庫)
· 使用數據注入技術(取決于應用程序和數據)
數據歸責技術
數據填充就是簡單地用一個不會影響結果的值替換缺失的值。
對于數值特征,缺失的值可以替換為:
· 0或默認值
#Filling all missing values with 0
data = data.fillna(0)
· 重復率最高的值
#Filling missing values with mode of the columns
data = data.fillna(data.mode())
· 該特征的均值(受離群值影響,可以用特征的中值替換)
#Filling missing values with medians of the columns
data = data.fillna(data.median())
對于分類特征,缺失的值可以替換為:
· 重復率最高的值
#Most repeated value function for categorical columns
data['column_name'].fillna(data['column_name'].value_counts()
.idxmax(), inplace=True)
· "其他"或任何新命名的類別,這意味著對數據點的估算
在本文中,我們了解了廣泛使用的基本特性工程技術。我們可以根據數據和應用程序創建新特性。但是,如果數據很小而且質量不好,這些方法可能就沒有用了。
作者:Ramya Vidiyala
deephub翻譯組:孟翔杰





