
摘要:
計算機操作系統(tǒng)內(nèi)存管理是十分重要的,因為其中涉及到很多設(shè)計很多算法。《深入理解計算機系統(tǒng)》這本書曾提到過,現(xiàn)在操作系統(tǒng)存儲的設(shè)計就是“帶著鐐銬跳舞”,造成計算機一種一種容量多,速度快的假象。包括現(xiàn)在很多系統(tǒng)比如數(shù)據(jù)庫系統(tǒng)的設(shè)計和操作系統(tǒng)做法相似。所以在學習操作系統(tǒng)之余我來介紹并總結(jié)一些操作系統(tǒng)的內(nèi)存管理。
首先我們看一下計算機的存儲層次結(jié)構(gòu)

按照金字塔結(jié)構(gòu)可以分為四種類型: 寄存器,快速緩存,主存和外存。而
寄存器和L1緩存都在Processor內(nèi)部。在金字塔中,越往下價格越低速度越慢但容量越大。
還有兩種存儲空間需要分清:
- 地址空間:又稱邏輯地址空間,源程序經(jīng)過編譯后得到的目標程序,存在于它所限定的地址范圍內(nèi),這個范圍稱為地址空間。地址空間是邏輯地址的集合。
- 內(nèi)存空間: 又稱存儲空間或物理地址空間。是指主存中一系列存儲信息的物理單元(劃重點)的集合,這些單元的編號稱為物理地址或絕對地址。
簡言之就這兩個空間分別是程序員能夠觀測到的存儲空間和真實的物理空間。
需求與管理的目標
需求:
- 每個程序員希望沒有第三方因素干擾程序運行
- 計算機希望將有限的資源盡可能為多個用戶提供服務
為了滿足需求的目標:
- 計算機至少同時存在一個用戶程序和一個服務器程序(操作系統(tǒng)內(nèi)核管理)
- 每個程序互不干擾,所以其地址空間應該相互獨立。
- 每個程序使用的空間應該被保護,最怕運行的時候程序中斷。就和看電影的時候無法播放一樣難受。
程序的內(nèi)存管理
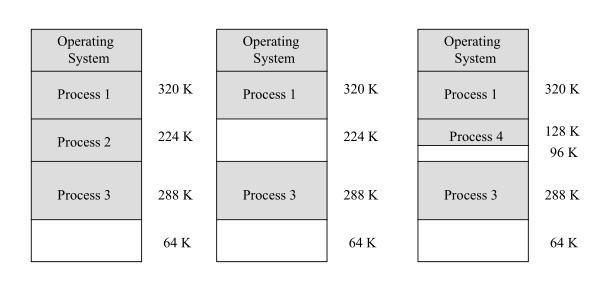
操作系統(tǒng)在內(nèi)存中的位置有以下三種可能

只有一個程序的環(huán)境下的內(nèi)存管理
此時整個內(nèi)存只有兩個程序,即用戶程序和操作系統(tǒng)。
操作系統(tǒng)所占的空間是固定的,則用戶程序空間也是固定的,因此可以將用戶程序永遠加載到同一個地址,即用戶程序永遠從同一個地方開始運行。這種情況下,用戶程序地址可以在運行之前就可以計算出來。
我們通過加載器計算程序運行之前的物理地址靜態(tài)翻譯。此時既不需要額外實現(xiàn)地址獨立和地址保護。因為用戶不需要知道物理內(nèi)存的相關(guān)知識,而且也沒有其它用戶程序。
多個程序的環(huán)境下的內(nèi)存管理
此時用戶的程序空間需要通過分區(qū)來分給多個不同的程序了。每個應用程序占用一個或幾個分區(qū),這種分配支持多個程序并發(fā)執(zhí)行,但難以進行內(nèi)存分區(qū)的共享。
其中分區(qū)有兩種方法:
一種方法: 固定(靜態(tài))式 分區(qū)分配, 讓程序適應分區(qū)
顧名思義就是把內(nèi)存劃分為若干個固定大小的連續(xù)分區(qū),這幾個分區(qū)或者大小相等以適合多個相同程序并發(fā),或者大小不等的分區(qū)以適合不同大小的程序。
這種分配方法優(yōu)點很明顯,在于非常容易實現(xiàn),開銷小。
缺點就是會產(chǎn)生很多內(nèi)部碎片(也就是未被利用的存儲空間),固定的分區(qū)總數(shù)也限制了并發(fā)執(zhí)行的程序數(shù)目。我們簡單介紹下靜態(tài)分配的幾種方法。
- 單一隊列的分配方式
- 多隊列分配方式
- 固定分區(qū)管理先使用表進行大小初始化,固定分區(qū)大小
另一種方法:可變(動態(tài))式 分區(qū)分配, 讓分區(qū)適應程序
此時分區(qū)的邊界可以移動,但也產(chǎn)生了分區(qū)與分區(qū)之間狹小的外部碎片。
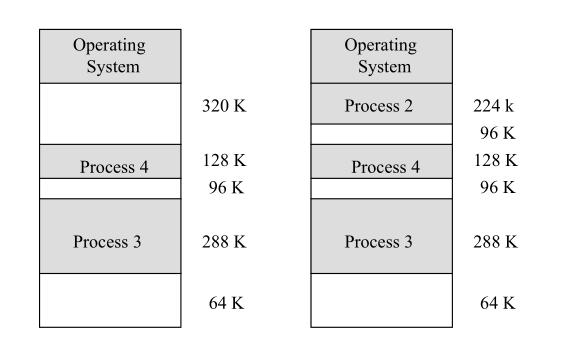
在可變分區(qū)中,知道內(nèi)存的空閑空間大小就十分重要了。OS通過跟蹤內(nèi)存使用計算出內(nèi)存有多少空閑。跟蹤的方法有兩種:
位圖表示法:
也就是所謂的bitmap,用每一位來存放某種狀態(tài)。將內(nèi)存每一個分配單元賦予一個判斷的用于判斷狀態(tài)的字位,字位取值位0表示單元閑置;字位為1表示單元被占用
- 特點
- 空間成本固定:不受內(nèi)存程序數(shù)量影響
- 時間成本低:操作的時候只需要將狀態(tài)值改變
- 缺少容錯能力:由于內(nèi)存單元發(fā)生錯誤的時會將狀態(tài)值改變,對操作系統(tǒng)來講,這個狀態(tài)值是因為發(fā)生錯誤發(fā)生的改變還是原來的狀態(tài)很難判斷。
鏈表表示法
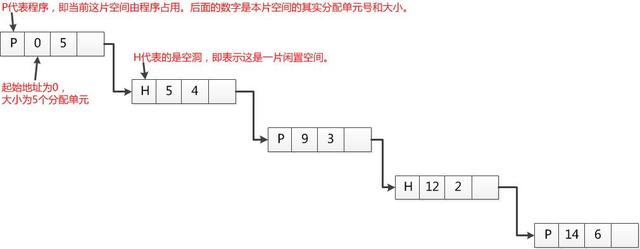
? 將分配單元按照是否閑置鏈接,P代表這個空間被占用,H代表這個這是一片閑置空間。為了方便遍歷查詢,每個程序空間的結(jié)點接著一個空閑空間的結(jié)點每個鏈表結(jié)點還有一個起始地址,與分配單元的大小,用代碼表示為
enum Status{P=0,H=1};
struct LinkNode{
enum Status status;//P表示程序,H表示空閑
struct LinkNode *begin_address;//起始地址
size_t size;//閑置空間大小
struct LinkNode *next;
};
- 特點空間成本:取決于程序數(shù)量時間成本:鏈表不停的遍歷速度很慢,同時還要進行鏈表的插入和刪除修改。有一定的容錯能力,可以通過程序空間結(jié)點和空閑空間結(jié)點相互驗證。
可變分區(qū)的內(nèi)存分配
OS通過上面兩種跟蹤方法知道內(nèi)存空閑容量,而現(xiàn)在操作系統(tǒng)一般都以鏈表的形式進行內(nèi)存空閑容量跟蹤。如果有新的程序需要讀入內(nèi)存,可變分區(qū)就要對空閑的分區(qū)進行內(nèi)存分配。
內(nèi)存分配使用兩張表:已分配分區(qū)表和未分配分區(qū)表。用C++描述如下:
//未分配分區(qū)表
struct FreeBlock {
int id; // 內(nèi)存分區(qū)號
int address; // 該分區(qū)的首地址
unsigned length; // 分區(qū)長度
};
//已分配分區(qū)表
struct AllocatedBlock {
int id; // 內(nèi)存分區(qū)號
int address; // 該分區(qū)的首地址
int pid; // 進程 ID
unsigned length; // 分區(qū)長度
};
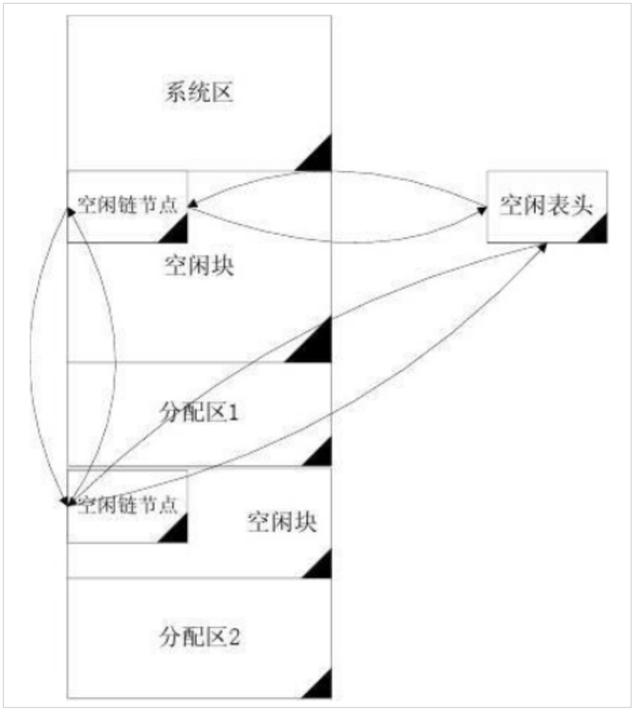
然后OS用雙向鏈表將所有未分配分區(qū)表進行串聯(lián)
struct{
FreeBlock data;
Node* prior;
Node* next;
}Node;
未分配分區(qū)表在整個系統(tǒng)空間上的結(jié)構(gòu)如下:
基于 順序搜索 的分配算法:
這里我們介紹四種基于順序搜索的尋找空閑存儲空間的算法:
- 首次適應算法( First Fit ) :每個空白區(qū)按其地址順序連在一起,從這個空白區(qū)域鏈的始端開始查找,選擇第一個足以滿足請求的空白塊。
- 下次適應算法( Next Fit ) :將存儲空間中空白區(qū)構(gòu)成一個循環(huán)鏈,每次為存儲請求查找合適的分區(qū)時,總是從上次查找結(jié)束的下一個空閑塊開始,只要找到一個足夠大的空白區(qū),就將它劃分后分配出去。
- 最佳適應算法( Best Fit ) : 為一個作業(yè)選擇分區(qū)時,總是尋找其大小最接近(小于等于)于作業(yè)所要求的存儲區(qū)域。
- 最壞適應算法( Worst Fit ) :為作業(yè)選擇存儲區(qū)域時,總是尋找最大的空白區(qū)。
算法舉例!!
系統(tǒng)中空閑分區(qū)表如下按照地址遞增次序排列,現(xiàn)有三個作業(yè)分配申請內(nèi)存空間100K,30K,7K。
區(qū)號大小地址狀態(tài)132K20K未分配28K52K未分配3120K60K未分配4331K180K未分配
- 首次適應:從上到下尋找合適的大小申請作業(yè)100K,從低地址到高地址找到3號分區(qū),分配完后3號分區(qū)起始地址變?yōu)?00K+60K=160K,剩余空間為120K-100K=20K申請作業(yè)30K,從低地址到高地址找到1號分區(qū),分配完后1號分區(qū)起始地址變?yōu)?0K+30K=50K,剩余空間為32K-30K=2K申請作業(yè)7K,從低地址到高地址找到2號分區(qū),分配完后2號分區(qū)起始地址變?yōu)?2K+7K=59K,剩余空間為8K-7K=1K結(jié)論:優(yōu)先利用內(nèi)存低地址部分的空閑分區(qū)。但由于低地址部分不斷被劃分,留下許多難以利用的很小的空閑分區(qū)(碎片或零頭) ,而每次查找又都是從低地址部分開始,增加了查找可用空閑分區(qū)的開銷。
- 下次適應申請作業(yè)100K,找到3號分區(qū),分配完后3號分區(qū)起始地址變?yōu)?00K+60K=160K,剩余空間為120K-100K=20K申請作業(yè)30K,從3號分區(qū)后繼續(xù)出發(fā),找到4號分區(qū),分配完后4號分區(qū)起始地址變?yōu)?80K+30K=210K,剩余空間為331K-30K=301K申請作業(yè)7K,從4號分區(qū)后繼續(xù)出發(fā),找到1號分區(qū),分配完后1號分區(qū)起始地址變?yōu)?0K+7K=27K,剩余空間為32K-7K=25K結(jié)論:使存儲空間的利用更加均衡,不致使小的空閑區(qū)集中在存儲區(qū)的一端,但這會導致缺乏大的空閑分區(qū)。
- 最佳適應算法申請作業(yè)100K,找到最適合的3號分區(qū),分配完后3號分區(qū)起始地址變?yōu)?00K+60K=160K,剩余空間為120K-100K=20K申請作業(yè)30K,找到最適合的1號分區(qū),分配完后1號分區(qū)起始地址變?yōu)?0K+30K=50K,剩余空間為32K-30K=2K申請作業(yè)7K,找到最適合的2號分區(qū),分配完后1號分區(qū)起始地址變?yōu)?2K+7K=59K,剩余空間為8K-7K=1K結(jié)論:若存在與作業(yè)大小一致的空閑分區(qū),則它必然被選中,若不存在與作業(yè)大小一致的空閑分區(qū),則只劃分比作業(yè)稍大的空閑分區(qū),從而保留了大的空閑分區(qū)。最佳適應算法往往使剩下的空閑區(qū)非常小,從而在存儲器中留下許多難以利用的小空閑區(qū)(碎片) 。
- 最壞適應算法申請作業(yè)100K,找到4號分區(qū),分配完后3號分區(qū)起始地址變?yōu)?80K+60K=240K,剩余空間為331K-100K=231K申請作業(yè)30K,此時被分配過的4號分區(qū)依然容量最大,于是還是找到4號分區(qū),分配完后4號分區(qū)起始地址變?yōu)?40+30K=250K,剩余空間為231K-30K=201K申請作業(yè)7K,此時被分配過的4號分區(qū)依然容量最大,找到4號分區(qū),分配完后4號分區(qū)起始地址變?yōu)?50+7K=257K,剩余空間為201K-7K=194K結(jié)論:總是挑選滿足作業(yè)要求的最大的分區(qū)分配給作業(yè)。這樣使分給作業(yè)后剩下的空閑分區(qū)也較 大,可裝下其它作業(yè)。由于最大的空閑分區(qū)總是因首先分配而劃分,當有大作業(yè)到來時,其存儲空間的申請往往會得不到滿足。
基于順序搜索的分配算法實際上只適合小型的操作系統(tǒng),大中型系統(tǒng)使用了是比較復雜的索引搜索的動態(tài)分配算法。
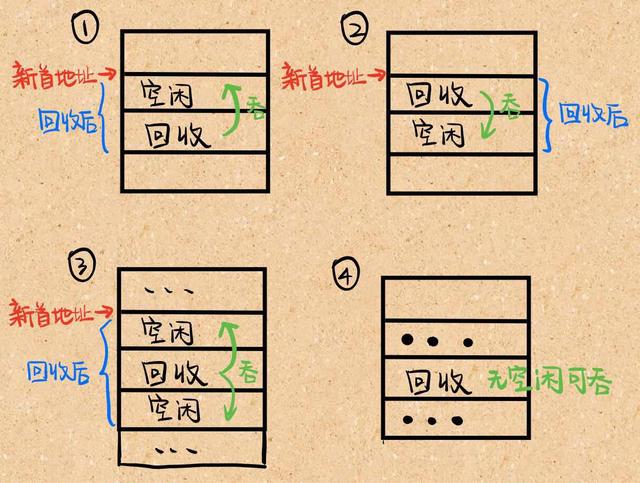
如何回收內(nèi)存
- 回收分區(qū)上鄰接一個空閑分區(qū),合并后首地址為空閑分區(qū)的首地址,大小為二者之和。
- 回收分區(qū)下鄰接一個空閑分區(qū),合并后首地址為回收分區(qū)的首地址,大小為二者之和。
- 回收分區(qū)上下鄰接空閑分區(qū),合并后首地址為上空閑分區(qū)的首地址,大小為三者之和。
- 回收分區(qū)不鄰接空閑分區(qū),這時在空閑分區(qū)表中新建一表項,并填寫分區(qū)大小等信息。
用iPad畫了一個簡單的示意圖如下:
最后
內(nèi)存分配實際上是操作系統(tǒng)非常重要的一環(huán),如果僅限于理論而不寫代碼實踐則容易迷惘,很多具體的實現(xiàn)與都比較困難。如上面的基于順序搜索的最佳適應算法,比如幾個分區(qū)的表示方法,都用到了數(shù)據(jù)結(jié)構(gòu)和算法的知識。如果能用C或者C++完成上述幾個算法和操作的具體實現(xiàn),相信一定會大有脾益的。





