
隨著數(shù)字化進程的加快,文檔、圖像等載體的結(jié)構(gòu)化分析和內(nèi)容提取成為關(guān)乎企業(yè)數(shù)字化轉(zhuǎn)型成敗的關(guān)鍵一環(huán),自動、精準、快速的信息處理對于生產(chǎn)力的提升至關(guān)重要。以商業(yè)文檔為例,不僅包含了公司內(nèi)外部事務(wù)的處理細節(jié)和知識沉淀,還有大量行業(yè)相關(guān)的實體和數(shù)字信息。人工提取這些信息既耗時費力且精度低,而且可復(fù)用性也不高,因此,文檔智能技術(shù)(Document Intelligence)應(yīng)運而生。
文檔智能技術(shù)深層次地結(jié)合了人工智能和人類智能,在金融、醫(yī)療、保險、能源、物流等多個行業(yè)都有不同類型的應(yīng)用。例如:在金融領(lǐng)域,它可以實現(xiàn)財報分析和智能決策分析,為企業(yè)戰(zhàn)略的制定和投資決策提供科學(xué)、系統(tǒng)的數(shù)據(jù)支撐;在醫(yī)療領(lǐng)域,它可以實現(xiàn)病例的數(shù)字化,提高診斷的精準度,并通過分析醫(yī)學(xué)文獻和病例的關(guān)聯(lián)性,定位潛在的治療方案。
什么是文檔智能?
文檔智能主要是指對于網(wǎng)頁、數(shù)字文檔或掃描文檔所包含的文本以及豐富的排版格式等信息,通過人工智能技術(shù)進行理解、分類、提取以及信息歸納的過程。
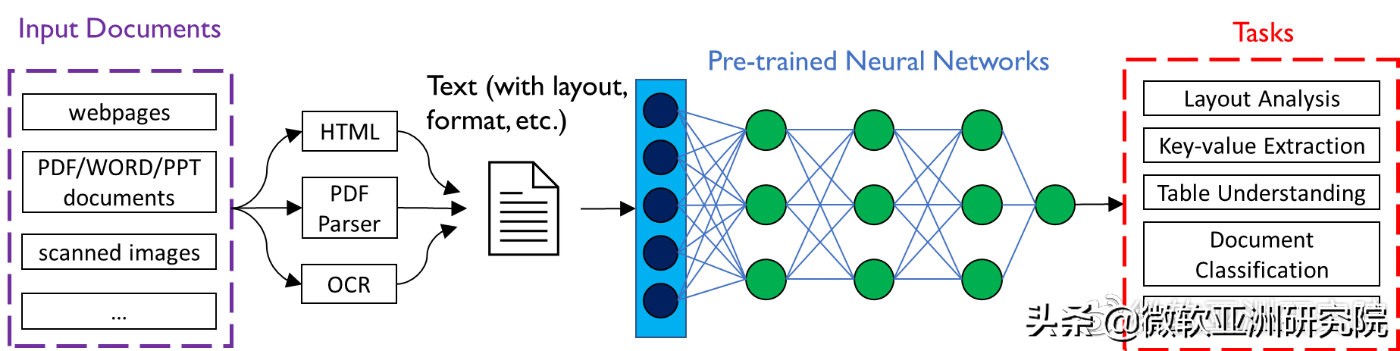
文檔智能技術(shù)
在過去的30年中,文檔智能的發(fā)展大致經(jīng)歷了三個階段。90年代初期,研究人員大多使用基于啟發(fā)式規(guī)則的方法進行文檔的理解與分析,通過人工觀察文檔的布局信息,總結(jié)歸納一些處理規(guī)則,對固定布局信息的文檔進行處理。然而,傳統(tǒng)基于規(guī)則的方法往往需要較大的人力成本,而且這些人工總結(jié)的規(guī)則可擴展性不強,因此研究人員開始采用基于統(tǒng)計學(xué)習(xí)的方法。隨著機器學(xué)習(xí)技術(shù)的發(fā)展和進步,基于大規(guī)模標注數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)模型成為了文檔智能的主流方法,它通過人工設(shè)計的特征模板,利用有監(jiān)督學(xué)習(xí)的方式在標注數(shù)據(jù)中學(xué)習(xí)不同特征的權(quán)重,以此來理解、分析文檔的內(nèi)容和布局。
基于深度學(xué)習(xí)特別是預(yù)訓(xùn)練技術(shù)的文檔智能模型,近幾年受到越來越多的重視,大型科技公司紛紛推出相應(yīng)的文檔智能服務(wù),包括微軟、亞馬遜、谷歌、IBM、阿里巴巴、百度等在內(nèi)的很多公司在這個領(lǐng)域持續(xù)發(fā)力,對于許多傳統(tǒng)行業(yè)的數(shù)字化轉(zhuǎn)型提供了有力的支撐。
隨著各類實際業(yè)務(wù)和產(chǎn)品的出現(xiàn),文檔智能領(lǐng)域的基準數(shù)據(jù)集也百花齊放,這些基準數(shù)據(jù)集通常包含了基于自然語言文本或圖像的標注信息,涵蓋了文檔布局分析、表格識別、信息抽取等重要的文檔智能任務(wù),它們的出現(xiàn)也推動了文檔智能技術(shù)的進一步發(fā)展。

文檔智能相關(guān)的基準數(shù)據(jù)集
傳統(tǒng)的文檔理解和分析技術(shù)往往基于人工定制的規(guī)則或少量標注數(shù)據(jù)進行學(xué)習(xí),這些方法雖然能夠帶來一定程度的性能提升,但由于定制規(guī)則和可學(xué)習(xí)的樣本數(shù)量不足,其通用性往往不盡如人意,而且針對不同類別文檔的分析遷移成本較高。隨著深度學(xué)習(xí)預(yù)訓(xùn)練技術(shù)的發(fā)展,以及大量無標注電子文檔的積累,文檔分析與識別技術(shù)進入了一個全新的時代。
微軟亞洲研究院提出的 LayoutLM 便是一個全新的文檔理解模型,通過引入預(yù)訓(xùn)練技術(shù),同時利用文本布局的局部不變性特征,可有效地將未標注文檔的信息遷移到下游任務(wù)中。LayoutLM 的論文(論文鏈接:https://arxiv.org/abs/1912.13318)已被KDD 2020 接收,并將在下周舉行的 KDD 大會上進行分享。同時,為了解決文檔理解領(lǐng)域現(xiàn)有的數(shù)據(jù)集標注規(guī)模小、標注粒度大、多模態(tài)信息缺失等缺陷,微軟亞洲研究院的研究員們還提出了大規(guī)模表格識別數(shù)據(jù)集 TableBank和大規(guī)模文檔布局標注數(shù)據(jù)集 DocBank(論文鏈接:https://arxiv.org/abs/2006.01038),利用弱監(jiān)督的方法,構(gòu)建了高質(zhì)量的文檔布局細粒度標注。
LayoutLM:在預(yù)訓(xùn)練階段實現(xiàn)文本和布局信息對齊
大量的研究成果表明,大規(guī)模預(yù)訓(xùn)練語言模型通過自監(jiān)督任務(wù),可在預(yù)訓(xùn)練階段有效捕捉文本中蘊含的語義信息,經(jīng)過下游任務(wù)微調(diào)后能有效的提升模型效果。然而,現(xiàn)有的預(yù)訓(xùn)練語言模型主要針對文本單一模態(tài)進行,忽視了文檔本身與文本天然對齊的視覺結(jié)構(gòu)信息。為了解決這一問題,研究員們提出了一種通用文檔預(yù)訓(xùn)練模型LayoutLM[1][2],選擇了文檔結(jié)構(gòu)信息(Document Layout Information)和視覺信息(Visual Information)進行建模,讓模型在預(yù)訓(xùn)練階段進行多模態(tài)對齊。
在實際使用的過程中,LayoutLM 僅需要極少的標注數(shù)據(jù)即可達到行業(yè)領(lǐng)先的水平。研究員們在三個不同類型的下游任務(wù)中進行了驗證:表單理解(Form Understanding)、票據(jù)理解(Receipt Understanding),以及文檔圖像分類(Document Image Classification)。實驗結(jié)果表明,在預(yù)訓(xùn)練中引入的結(jié)構(gòu)和視覺信息,能夠有效地遷移到下游任務(wù)中,最終在三個下游任務(wù)中都取得了顯著的準確率提升。
文檔結(jié)構(gòu)和視覺信息不可忽視
很多情況下,文檔中文字的位置關(guān)系蘊含著豐富的語義信息。以下圖的表單為例,表單通常是以鍵值對(key-value pair)的形式展示的(例如 “DATE: 11/28/84”)。一般情況下,鍵值對的排布是以左右或者上下的形式,并且有特殊的類型關(guān)系。類似地,在表格文檔中,表格中的文字通常是網(wǎng)格狀排列,并且表頭一般出現(xiàn)在第一列或第一行。通過預(yù)訓(xùn)練,這些與文本天然對齊的位置信息可以為下游的信息抽取任務(wù)提供更豐富的語義信息。

表單示例
對于富文本文檔,除了文字本身的位置關(guān)系之外,文字格式所呈現(xiàn)的視覺信息同樣可以幫助下游任務(wù)。對文本級(token-level)任務(wù)來說,文字大小、是否傾斜、是否加粗,以及字體等富文本格式都能夠體現(xiàn)相應(yīng)的語義。例如,表單鍵值對的鍵位(key)通常會以加粗的形式給出;而在一般文檔中,文章的標題通常會放大加粗呈現(xiàn),特殊概念名詞會以斜體呈現(xiàn),等等。對文檔級(document-level)任務(wù)來說,整體的文檔圖像能提供全局的結(jié)構(gòu)信息。例如個人簡歷的整體文檔結(jié)構(gòu)與科學(xué)文獻的文檔結(jié)構(gòu)是有明顯的視覺差異的。這些模態(tài)對齊的富文本格式所展現(xiàn)的視覺特征,可以通過視覺模型抽取,再結(jié)合到預(yù)訓(xùn)練階段,從而有效地幫助下游任務(wù)。
將視覺信息與文檔結(jié)構(gòu)融入到通用預(yù)訓(xùn)練方案
建模上述信息需要尋找這些信息的有效表示方式。然而現(xiàn)實中的文檔格式豐富多樣,除了格式明確的電子文檔外,還有大量掃描式報表和票據(jù)等圖片式文檔。對于計算機生成的電子文檔,可以使用對應(yīng)的工具獲取文本和對應(yīng)的位置以及格式信息;對于掃描圖片文檔,則可以使用 OCR 技術(shù)進行處理,從而獲得相應(yīng)的信息。兩種不同的手段幾乎可以使用現(xiàn)存的所有文檔數(shù)據(jù)進行預(yù)訓(xùn)練,保證了預(yù)訓(xùn)練數(shù)據(jù)的規(guī)模。

基于文檔結(jié)構(gòu)和視覺信息的 LayoutLM 模型結(jié)構(gòu)
利用上述信息,微軟亞洲研究院的研究員們在現(xiàn)有的預(yù)訓(xùn)練模型基礎(chǔ)上添加了二維位置嵌入(2-D Position Embedding)和圖嵌入(Image Embedding)兩種新的 Embedding 層,可以有效地結(jié)合文檔結(jié)構(gòu)和視覺信息:
1) 二維位置嵌入 2-D Position Embedding:根據(jù) OCR 獲得的文本邊界框 (Bounding Box),能獲取文本在文檔中的具體位置。在將對應(yīng)坐標轉(zhuǎn)化為虛擬坐標之后,則可以計算該坐標對應(yīng)在 x、y、w、h 四個 Embedding 子層的表示,最終的 2-D Position Embedding 為四個子層的 Embedding 之和。
2) 圖嵌入 Image Embedding:將每個文本相應(yīng)的邊界框 (Bounding Box) 當(dāng)作 Faster R-CNN 中的候選框(Proposal),從而提取對應(yīng)的局部特征。其特別之處在于,由于 [CLS] 符號用于表示整個輸入文本的語義,所以同樣使用整張文檔圖像作為該位置的 Image Embedding,從而保持模態(tài)對齊。
在預(yù)訓(xùn)練階段,研究員們針對 LayoutLM 的特點提出了兩個自監(jiān)督預(yù)訓(xùn)練任務(wù):
1) 掩碼視覺語言模型(Masked Visual-Language Model,MVLM):大量實驗已經(jīng)證明 MLM 能夠在預(yù)訓(xùn)練階段有效地進行自監(jiān)督學(xué)習(xí)。研究員們在此基礎(chǔ)上進行了修改:在遮蓋當(dāng)前詞之后,保留對應(yīng)的 2-D Position Embedding 暗示,讓模型預(yù)測對應(yīng)的詞。在這種方法下,模型根據(jù)已有的上下文和對應(yīng)的視覺暗示預(yù)測被掩碼的詞,從而讓模型更好地學(xué)習(xí)文本位置和文本語義的模態(tài)對齊關(guān)系。
2) 多標簽文檔分類(Multi-label Document Classification,MDC):MLM 能夠有效的表示詞級別的信息,但是對于文檔級的表示,還需要將文檔級的預(yù)訓(xùn)練任務(wù)引入更高層的語義信息。在預(yù)訓(xùn)練階段研究員們使用的 IIT-CDIP 數(shù)據(jù)集為每個文檔提供了多標簽的文檔類型標注,并引入 MDC 多標簽文檔分類任務(wù)。該任務(wù)使得模型可以利用這些監(jiān)督信號,聚合相應(yīng)的文檔類別并捕捉文檔類型信息,從而獲得更有效的高層語義表示。
實驗結(jié)果:LayoutLM 的表單、票據(jù)理解和文檔圖像分類水平顯著提升
預(yù)訓(xùn)練過程使用了 IIT-CDIP 數(shù)據(jù)集,這是一個大規(guī)模的掃描圖像公開數(shù)據(jù)集,經(jīng)過處理后的文檔數(shù)量達到約11,000,000。研究員們隨機采樣了1,000,000個進行測試實驗,最終使用全量數(shù)據(jù)進行完全預(yù)訓(xùn)練。通過千萬文檔量級的預(yù)訓(xùn)練并在下游任務(wù)微調(diào),LayoutLM 在測試的三個不同類型的下游任務(wù)中都取得了 SOTA 的成績,具體如下:
1) 表單理解(Form Understanding):表單理解任務(wù)上,使用了 FUNSD 作為測試數(shù)據(jù)集,該數(shù)據(jù)集中的199個標注文檔包含了31,485個詞和9,707個語義實體。在該數(shù)據(jù)集上,需要對數(shù)據(jù)集中的表單進行鍵值對(key-value)抽取。通過引入位置信息的訓(xùn)練,LayoutLM 模型在該任務(wù)上取得了顯著的提升,將表單理解的 F1 值從70.72 提高至79.2。
2) 票據(jù)理解(Receipt Understanding):票據(jù)理解任務(wù)中,選擇了 SROIE 測評比賽作為測試。SROIE 票據(jù)理解包含1000張已標注的票據(jù),每張票據(jù)都標注了店鋪名、店鋪地址、總價、消費時間四個語義實體。通過在該數(shù)據(jù)集上微調(diào),LayoutLM 模型在 SROIE 測評中的 F1 值高出第一名(2019)1.2個百分點,達到95.24%。
3) 文檔圖像分類(Document Image Classification):對于文檔圖像分類任務(wù),則選擇了 RVL-CDIP 數(shù)據(jù)集進行測試。RVL-CDIP 數(shù)據(jù)集包含有16類總記40萬個文檔,每一類都包含25,000個文檔數(shù)據(jù)。LayoutLM 模型在該數(shù)據(jù)集上微調(diào)之后,將分類準確率提高了1.35個百分點,達到了94.42%。
DocBank數(shù)據(jù)集:50萬文檔頁面,以弱監(jiān)督方法獲取高質(zhì)量標注
在許多文檔理解應(yīng)用中,文檔布局分析是一項重要任務(wù),因為它可以將半結(jié)構(gòu)化信息轉(zhuǎn)換為結(jié)構(gòu)化表示形式,同時從文檔中提取關(guān)鍵信息。由于文檔的布局和格式不同,因此這一直是一個具有挑戰(zhàn)性的問題。目前,最先進的計算機視覺和自然語言處理模型通常采用“預(yù)訓(xùn)練-微調(diào)”范式來解決這個問題,首先在預(yù)先訓(xùn)練的模型上初始化,然后對特定的下游任務(wù)進行微調(diào),從而獲得十分可觀的結(jié)果。
但是,模型的預(yù)訓(xùn)練過程不僅需要大規(guī)模的無標記數(shù)據(jù)進行自我監(jiān)督學(xué)習(xí),還需要高質(zhì)量的標記數(shù)據(jù)進行特定任務(wù)的微調(diào)以實現(xiàn)良好的性能。對于文檔布局分析任務(wù),目前已經(jīng)有一些基于圖像的文檔布局數(shù)據(jù)集,但其中大多數(shù)是為計算機視覺方法而構(gòu)建的,很難應(yīng)用于自然語言處理方法。此外,基于圖像的標注主要包括頁面圖像和大型語義結(jié)構(gòu)的邊界框,精準度遠不如細粒度的文本級標注。然而,人工標注細粒度的 Token 級別文本的人力成本和時間成本非常高昂。因此,利用弱監(jiān)督方法,以較少的人力物力來獲得帶標簽的細粒度文檔標注,同時使數(shù)據(jù)易于應(yīng)用在任何自然語言處理和計算機視覺方法上至關(guān)重要。
為此,微軟亞洲研究院的研究員們構(gòu)建了 DocBank 數(shù)據(jù)集[3][4],這是一個文檔基準數(shù)據(jù)集,其中包含了50萬文檔頁面以及用于文檔布局分析的細粒度 Token 級標注。與常規(guī)的人工標注數(shù)據(jù)集不同,微軟亞洲研究院的方法以簡單有效的方式利用弱監(jiān)督的方法獲得了高質(zhì)量標注。DocBank 數(shù)據(jù)集是文檔布局標注數(shù)據(jù)集 TableBank[5][6] 的擴展,基于互聯(lián)網(wǎng)上大量的數(shù)字化文檔進行開發(fā)而來。例如當(dāng)下很多研究論文的 PDF 文件,都是由 LaTeX 工具編譯而成。LaTeX 系統(tǒng)的命令中包含了標記作為構(gòu)造塊的顯式語義結(jié)構(gòu)信息,例如摘要、作者、標題、公式、圖形、頁腳、列表、段落、參考、節(jié)標題、表格和文章標題。為了區(qū)分不同的語義結(jié)構(gòu),研究員們修改了 LaTeX 源代碼,為不同語義結(jié)構(gòu)的文本指定不同的顏色,從而能清楚地劃分不同的文本區(qū)域,并標識為對應(yīng)的語義結(jié)構(gòu)。
從自然語言處理的角度來看,DocBank 數(shù)據(jù)集的優(yōu)勢是可用于任何序列標注模型,同時還可以輕松轉(zhuǎn)換為基于圖像的標注,以支持計算機視覺中的物體檢測模型。通過這種方式,可以使用 DocBank 公平地比較來自不同模態(tài)的模型,并且進一步研究多模態(tài)方法,提高文檔布局分析的準確性。
為了驗證 DocBank 的有效性,研究員們使用了 BERT、RoBERTa 和 LayoutLM 三個基線模型進行實驗。實驗結(jié)果表明,對于文檔布局分析任務(wù),LayoutLM 模型明顯優(yōu)于 DocBank 上的 BERT 和 RoBERTa 模型。微軟亞洲研究院希望 DocBank 可以驅(qū)動更多文檔布局分析模型,同時促進更多的自定義網(wǎng)絡(luò)結(jié)構(gòu)在這個領(lǐng)域取得實質(zhì)性進展。

DocBank 數(shù)據(jù)集的數(shù)據(jù)樣例
四步構(gòu)建 DocBank 數(shù)據(jù)集

DocBank 的處理步驟
研究員們使用 Token 級標注構(gòu)建 DocBank 數(shù)據(jù)集,以支持自然語言處理和計算機視覺模型的研究。DocBank 的構(gòu)建包括四個步驟:文檔獲取、語義結(jié)構(gòu)檢測、Token 級別文本標注、后處理。DocBank 數(shù)據(jù)集總共包括50萬個文檔頁面,其中訓(xùn)練集包括40萬個文檔頁面,驗證集和測試集分別包括5萬個文檔頁面(點擊閱讀原文,訪問DocBank 數(shù)據(jù)集網(wǎng)站了解更多具體信息)。
文檔獲取
研究員們在 arXiv.com 上獲取了大量科研論文的 PDF 文件,以及對應(yīng)的 LaTeX 源文件,因為需要通過修改源代碼來檢測語義結(jié)構(gòu)。這些論文包含物理、數(shù)學(xué)、計算機科學(xué)以及許多其他領(lǐng)域,非常有利于 DocBank 數(shù)據(jù)集的多樣性覆蓋,同時也可以使其訓(xùn)練出的模型更加魯棒。目前這項工作聚焦在英文文檔上,未來將會擴展到其他語言。
語義結(jié)構(gòu)檢測
DocBank 是 TableBank 數(shù)據(jù)集的擴展,其中除了表格之外還包括其他語義單元,用于文檔布局分析。在 DocBank 數(shù)據(jù)集中標注了以下語義結(jié)構(gòu):摘要、作者、標題、公式、圖形、頁腳、列表、段落、參考文獻、節(jié)標題、表格和文章標題。
之前的 TableBank 研究使用了 “fcolorbox” 命令標記表格。但是,對于 DocBank 數(shù)據(jù)集,目標結(jié)構(gòu)主要由文本組成,因此無法很好地應(yīng)用 “fcolorbox” 命令。所以此次使用 “color” 命令來改變這些語義結(jié)構(gòu)的字體顏色,通過特定于結(jié)構(gòu)的顏色來區(qū)分它們。有兩種類型的命令可以表示語義結(jié)構(gòu)。
一類是 LaTeX 命令的簡單單詞,后接反斜杠。例如,LaTeX 文檔中的節(jié)標題通常采用以下格式:
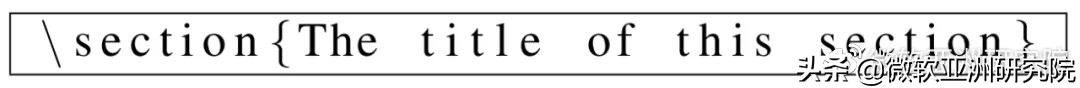
另一類命令通常會啟動一個環(huán)境。例如,LaTeX 文檔中的列表聲明如下所示:

begin{itemize} 命令啟動一個環(huán)境,而 end{itemize} 命令結(jié)束該環(huán)境。實際命令名稱是 “begin” 命令和 “end” 命令的參數(shù)。將 “color” 命令插入到語義結(jié)構(gòu)的代碼中(如下所示),然后重新編譯 LaTeX 文檔。同時,為所有語義結(jié)構(gòu)定義特定的顏色,使它們更好地被區(qū)分。不同的結(jié)構(gòu)命令要求將 “color” 命令放置在不同的位置才能生效。最后,重新編譯 LaTeX 文檔來獲取更新的 PDF 頁面,其中每個目標結(jié)構(gòu)的字體顏色已修改為特定于結(jié)構(gòu)的顏色。

Token 級別文本標注
研究員們使用 PDFPlumber(基于 PDFMiner 構(gòu)建的 PDF 解析器)來提取文本行和非文本元素,以及它們的邊界框。通過劃分空格將文本行分詞,由于只能從解析器中獲得字符的邊界框,因此 Token 的邊界框定義是組成 Token 的單詞中最左上角坐標和最右下角坐標的集合。對于沒有任何文本的元素(例如 PDF 文件中的圖形和線條),則在 PDFMiner 中使用其類名和兩個“#”符號將其組成一個特殊標記。表示圖形和線條的類名分別是 “LTFigure” 和 “LTLine”。
PDFPlumber 可以從 PDF 文件中以 RGB 值的形式,提取字符和非文本元素的顏色。通常,每個 Token 由具有相同顏色的字符組成。如果不是的話,則使用第一個字符的顏色作為 Token 的顏色。根據(jù)上述的顏色到結(jié)構(gòu)的映射,可以確定 Token 級別的文本標簽。此外,語義結(jié)構(gòu)可以同時包含文本和非文本元素。例如,表格由單詞和組成表格的線條構(gòu)成。在這項工作中,為了使模型在元素被切分之后能夠盡可能地獲取表格的布局,單詞和線條都被標注為“表格”類。
后處理
在某些情況下,一些 Token 天然具有多種顏色,并且無法通過 “ color” 命令進行轉(zhuǎn)換,例如 PDF 文件中的超鏈接和引用,這些不變的顏色將導(dǎo)致標記的標注錯誤。因此,為了更正這些 Token 的標簽,還需要對 DocBank 數(shù)據(jù)集進行一些后處理步驟。
通常,相同語義結(jié)構(gòu)的 Token 將按閱讀順序組織在一起。因此,一般在相同的語義結(jié)構(gòu)中連續(xù)的標記都具有相同的標簽。當(dāng)語義結(jié)構(gòu)交替時,邊界處相鄰 Token 的標簽將不一致。研究員們會根據(jù)文檔中的閱讀順序檢查所有標簽。當(dāng)單個 Token 的標簽與其上文和下文的標簽不同,但上文和下文的標簽相同時,會將此 Token 的標簽校正為與上下文標記相同。通過手動檢查,研究員們發(fā)現(xiàn)這些后處理步驟大大改善了DocBank 數(shù)據(jù)集的質(zhì)量。
實驗數(shù)據(jù)統(tǒng)計
DocBank 數(shù)據(jù)集具有12種語義單元,DocBank 中訓(xùn)練集、驗證集和測試集的統(tǒng)計信息,顯示了每個語義單元的數(shù)量(定義為包含該語義單元的文檔頁面數(shù)量),以及占總文檔頁面數(shù)量的百分比。由于這些文檔頁面是隨機抽取并進行劃分的,因此語義單元在不同集合中的分布幾乎是一致的。
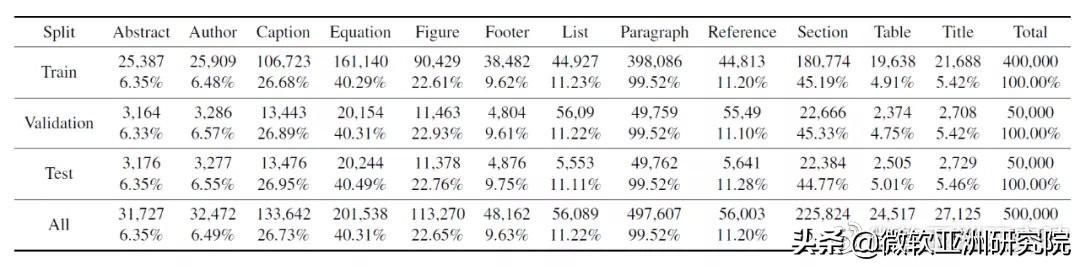
DocBank 中訓(xùn)練、驗證和測試集的語義結(jié)構(gòu)統(tǒng)計信息
年份統(tǒng)計信息中展示了不同年份文檔頁面的分布,可以看到論文的數(shù)量是逐年增加的。為了保持這種自然分布,研究員們隨機抽取了不同年份的文檔樣本以構(gòu)建 DocBank,而沒有平衡不同年份的數(shù)量。

DocBank 中訓(xùn)練、驗證和測試集的年份統(tǒng)計信息
DocBank 與現(xiàn)有的文檔布局分析數(shù)據(jù)集(包括 Article Regions、GROTOAP2、PubLayNet 和 TableBank)的比較顯示,DocBank 在數(shù)據(jù)集的規(guī)模和語義結(jié)構(gòu)的種類上都超過了現(xiàn)有的數(shù)據(jù)集。而且,表格中所有數(shù)據(jù)集都是基于圖像的,只有DocBank 同時支持基于文本和基于圖像的模型。由于 DocBank 是基于公開論文自動構(gòu)建的,因此具有可擴展性,可以隨著時間繼續(xù)擴大數(shù)據(jù)規(guī)模。

DocBank 與現(xiàn)有的文檔布局分析數(shù)據(jù)集的比較
評價指標
由于模型的輸入是序列化的二維文檔,所以典型的 BIO 標簽評估并不適合這個任務(wù)。每個語義單元的 Token 可以在輸入序列中不連續(xù)地分布。針對基于文本的文檔布局分析方法,研究員們提出了一個新的指標,其定義如下:

實驗結(jié)果
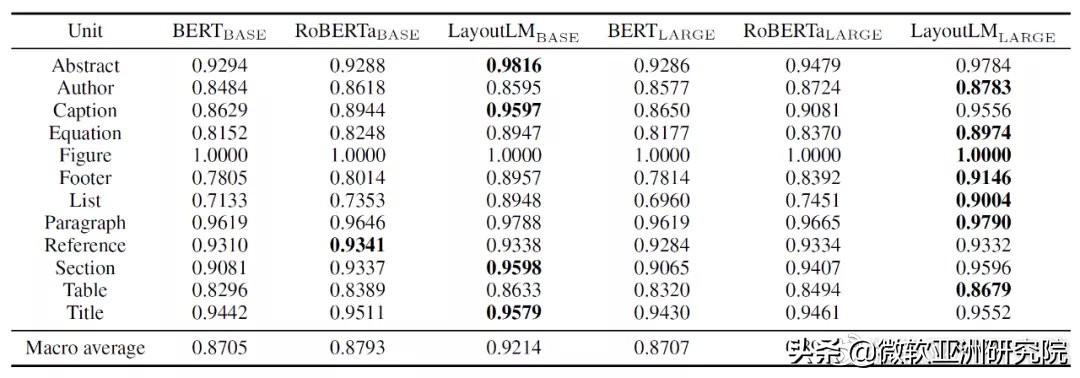
LayoutLM、BERT、RoBERTa 模型在 DocBank 測試集的準確性
在 DocBank 的測試集上評估了六個模型后,研究員們發(fā)現(xiàn) LayoutLM 在摘要、作者、表格標題、方程式、圖形、頁腳、列表、段落、節(jié)標題、表格、文章標題標簽上得分最高。在其他標簽上 LayoutLM 與其他模型的差距也較小。這表明在文檔布局分析任務(wù)中,LayoutLM 結(jié)構(gòu)明顯優(yōu)于 BERT 和 RoBERTa 結(jié)構(gòu)。

測試集上預(yù)訓(xùn)練 BERT 模型和預(yù)訓(xùn)練 LayoutLM 模型的樣例輸出
研究員們又選取了測試集的一些樣本,將預(yù)訓(xùn)練 BERT 和預(yù)訓(xùn)練 LayoutLM 的輸出進行了可視化。可以觀察到,序列標記方法在 DocBank 數(shù)據(jù)集上表現(xiàn)良好,它可以識別不同的語義單元。對于預(yù)訓(xùn)練的 BERT 模型,某些 Token 沒有被正確標記,這表明僅使用文本信息仍不足以完成文檔布局分析任務(wù),還應(yīng)考慮視覺信息。
與預(yù)訓(xùn)練的 BERT 模型相比,預(yù)訓(xùn)練的 LayoutLM 模型集成了文本和布局信息,因此它在基準數(shù)據(jù)集上實現(xiàn)了更好的性能。這是因為二維的位置嵌入可以在統(tǒng)一的框架中對語義結(jié)構(gòu)的空間距離和邊界進行建模,從而提高了檢測精度。
結(jié)束語
信息處理是產(chǎn)業(yè)化的基礎(chǔ)和前提,如今對處理能力、處理速度和處理精度也都有著越來越高的要求。以商業(yè)領(lǐng)域為例,電子商業(yè)文檔就涵蓋了采購單據(jù)、行業(yè)報告、商務(wù)郵件、銷售合同、雇傭協(xié)議、商業(yè)發(fā)票、個人簡歷等大量繁雜的信息。機器人流程自動化(Robotic Process Automation,RPA) 行業(yè)正是在這一背景下應(yīng)運而生,利用人工智能技術(shù)幫助大量人工從繁雜的電子文檔處理任務(wù)中解脫出來,并通過一系列配套的自動化工具提升生產(chǎn)力,RPA的關(guān)鍵核心之一就是文檔智能技術(shù)。
傳統(tǒng)的人工智能技術(shù)往往需要利用大量的人工標注數(shù)據(jù)來構(gòu)建自動化機器學(xué)習(xí)模型,然而標注數(shù)據(jù)的過程費時費力,通常成為產(chǎn)業(yè)化的瓶頸。LayoutLM 文檔理解預(yù)訓(xùn)練技術(shù)的優(yōu)勢在于,利用基于深度神經(jīng)網(wǎng)絡(luò)的自學(xué)習(xí)技術(shù),通過大規(guī)模無標注數(shù)據(jù)學(xué)習(xí)基礎(chǔ)模型,之后再通過遷移學(xué)習(xí)技術(shù)僅需少量標注數(shù)據(jù)即可達到人工處理文檔的水平。目前,LayoutLM 技術(shù)已經(jīng)成功應(yīng)用于微軟的核心產(chǎn)品和服務(wù)中。
為了推動文檔智能技術(shù)的發(fā)展,LayoutLM 的相關(guān)模型代碼和論文也已經(jīng)開源(https://aka.ms/layoutlm),并受到了學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注和好評,據(jù)媒體報道在金融智能分析領(lǐng)域已經(jīng)有機構(gòu)開始采用 LayoutLM 模型[7]進行流程自動化的集成和部署,同時也有相關(guān)機構(gòu)采用 LayoutLM 模型[8]進行文檔視覺問答(Document VQA)方面的研究工作。相信隨著傳統(tǒng)行業(yè)數(shù)字化轉(zhuǎn)型的逐步深入,文檔智能研究工作將被更多的個人和企業(yè)關(guān)注,進一步推動相關(guān)技術(shù)和行業(yè)的發(fā)展。
附錄
[1]LayoutLM 論文:https://arxiv.org/abs/1912.13318
[2]LayoutLM 代碼&模型:https://aka.ms/layoutlm
[3] DocBank 論文:https://arxiv.org/abs/2006.01038
[4] DocBank 數(shù)據(jù)集&模型:https://github.com/doc-analysis/DocBank
[5] TableBank 論文:https://arxiv.org/abs/1903.01949
[6] TableBank 數(shù)據(jù)集&模型:https://github.com/doc-analysis/TableBank
[7] “Injecting Artificial Intelligence into Financial Analysis”:https://medium.com/reimagine-banking/injecting-artificial-intelligence-into-financial-analysis-54718fbd5949
[8] “Document Visual Question Answering”:https://medium.com/@anishagunjal7/document-visual-question-answering-e6090f3bddee





