擊這里在線(xiàn)咨詢(xún)客服")
今天給大家分享的內(nèi)容是LSM樹(shù),它的英文是Log-structed Merge-tree。看著有些發(fā)怵,但其實(shí)它的原理不難,和B樹(shù)相比簡(jiǎn)直算是小兒科了。
并且這也是一個(gè)非常經(jīng)典的數(shù)據(jù)結(jié)構(gòu),并且在大數(shù)據(jù)系統(tǒng)當(dāng)中有非常廣泛的應(yīng)用。有許多耳熟能詳?shù)慕?jīng)典系統(tǒng),底層就是基于LSM樹(shù)實(shí)現(xiàn)的。因此,今天就和大家一起來(lái)深入學(xué)習(xí)一下它的原理。
背景知識(shí)
首先,我們先從背景知識(shí)開(kāi)始。我們之前介紹B+樹(shù)的時(shí)候說(shuō)過(guò),B+樹(shù)和B樹(shù)最大的不同就是將所有的數(shù)據(jù)都放在了葉子節(jié)點(diǎn)。從而優(yōu)化了我們批量插入以及批量查詢(xún)的效率,而優(yōu)化的核心邏輯就是因?yàn)闊o(wú)論是什么存儲(chǔ)介質(zhì),順序存儲(chǔ)的效率一定要比隨機(jī)存儲(chǔ)更高,并且高的還不是一點(diǎn)半點(diǎn)。這個(gè)已經(jīng)算是老生常談了,如果我沒(méi)記錯(cuò)的話(huà),這已經(jīng)是我第三次在文章當(dāng)中提到這一點(diǎn)了。
我最近看到了一張圖,很好地闡述了隨機(jī)讀取和順序讀取兩者的效率差,我們來(lái)看下面這張圖。其中綠色的部分表示硬盤(pán)順序讀取的最大速度,而紅色表示隨機(jī)讀取時(shí)的速度。

我們看下縱坐標(biāo)就知道,這兩者差的不是一點(diǎn)半點(diǎn),已經(jīng)有數(shù)量級(jí)的差距了。而且還不止是一個(gè)數(shù)量級(jí),至少相差了三個(gè)數(shù)量級(jí),顯然這是非常恐怖的。另外,這個(gè)差距并不只是在傳統(tǒng)的機(jī)械硬盤(pán)上存在,即使是現(xiàn)在比較先進(jìn)的SSD固態(tài)硬盤(pán)上,也一樣存在。也就是說(shuō)這個(gè)差距是介質(zhì)無(wú)關(guān)的。
直觀優(yōu)化
既然隨機(jī)讀取和順序讀取的效率差了這么多,不由得不讓人心動(dòng)。如果能夠發(fā)明一個(gè)數(shù)據(jù)結(jié)構(gòu)可以充分地利用上這一點(diǎn),那么我們的系統(tǒng)對(duì)數(shù)據(jù)的吞吐能力一定可以再上一個(gè)臺(tái)階。對(duì)于許多科技公司而言,尤其是大數(shù)據(jù)公司,因?yàn)閿?shù)據(jù)量帶來(lái)的機(jī)器開(kāi)銷(xiāo)的費(fèi)用占據(jù)了日常支出的大頭。如果能夠很好地解決這個(gè)問(wèn)題,顯然可以節(jié)約大量的資源。
一個(gè)樸素的想法就是將所有的讀寫(xiě)都設(shè)計(jì)成順序讀寫(xiě),比如日志系統(tǒng)就是一個(gè)典型的例子。在我們記錄日志的時(shí)候,總是添加在文件的末尾,而不會(huì)插入在文件的中間。由于我們總是添加在文件末尾,在磁盤(pán)上這是一個(gè)順序的讀寫(xiě)。但我們把讀寫(xiě)都設(shè)計(jì)成順序的,也就意味著我們當(dāng)我們要查找的內(nèi)容在文件中間的時(shí)候,我們必須要讀入文件中的所有內(nèi)容。
這個(gè)思路應(yīng)用最廣泛的地方有兩個(gè),一個(gè)是數(shù)據(jù)庫(kù)的日志當(dāng)中。在我們用數(shù)據(jù)庫(kù)執(zhí)行寫(xiě)入或者修改操作的時(shí)候,數(shù)據(jù)庫(kù)會(huì)將所有的變更寫(xiě)成log記錄下來(lái)。還有一處是消息系統(tǒng)的中間件,比如kafka。
但是在復(fù)雜的增刪查改的場(chǎng)景當(dāng)中,尤其是涉及到批量讀寫(xiě)的場(chǎng)景,簡(jiǎn)單的文件順序讀寫(xiě)就不能滿(mǎn)足需求了。當(dāng)然我們可以引入哈希表或者是B+樹(shù)這些數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)功能,但這些復(fù)雜的數(shù)據(jù)結(jié)構(gòu)都避免不了比較慢的隨機(jī)讀寫(xiě)操作,而我們希望隨機(jī)讀寫(xiě)能盡量減少,正是基于這個(gè)原理,LSMT被發(fā)明了出來(lái)。LSMT使用了一種獨(dú)特的機(jī)制犧牲了一些讀操作的性能,保證了寫(xiě)操作的能力,它能夠讓所有的操作順序化,幾乎完全避免了隨機(jī)讀寫(xiě)。
在我們介紹LSMT的原理之前,我們先來(lái)介紹一下它的子結(jié)構(gòu)SSTable。
SSTable
第一次看到這個(gè)單詞的時(shí)候覺(jué)得一頭霧水是正常的,SSTable的全稱(chēng)是Sorted String Table,本質(zhì)就是一個(gè)KV結(jié)構(gòu)順序排列的文件。我們來(lái)看下下圖:

最基礎(chǔ)的SSTable就是上圖當(dāng)中右側(cè)的部分,即key和value的鍵值對(duì)按照key值的大小排序,并存儲(chǔ)在文件當(dāng)中。當(dāng)我們需要查找某個(gè)key值對(duì)應(yīng)的數(shù)據(jù)的時(shí)候,我們會(huì)將整個(gè)文件讀入進(jìn)內(nèi)存,進(jìn)行查找。同樣,寫(xiě)入也是如此,我們會(huì)將插入的操作在內(nèi)存中進(jìn)行,得到結(jié)果之后,直接覆蓋原本的文件,而不會(huì)在文件當(dāng)中修改,因?yàn)檫@會(huì)牽扯到移動(dòng)大量的數(shù)據(jù)。
如果文件中的數(shù)據(jù)量過(guò)大,我們需要另外建立一個(gè)索引文件,存儲(chǔ)不同的key值對(duì)應(yīng)的offset,方便我們?cè)谧x取文件的時(shí)候快速查找到我們想要查找的文件。索引文件即上圖當(dāng)中左邊部分。
需要注意,SSTable是不可修改的,我們只會(huì)用新的SSTable去覆蓋舊的,而不會(huì)再原本的基礎(chǔ)上修改。因?yàn)樾薷臅?huì)涉及隨機(jī)讀寫(xiě),這是我們不希望的。
LSM的增刪改查
理解了SSTable之后,我們來(lái)看下基本的LSM實(shí)現(xiàn)原理。
其實(shí)最基本的LSM原理非常簡(jiǎn)單,本質(zhì)上就是在SSTable的基礎(chǔ)上增加了一個(gè)Memtable,Memtable顧名思義就是存放在內(nèi)存當(dāng)中的表結(jié)構(gòu)。當(dāng)然也不一定是表結(jié)構(gòu),也可以是樹(shù)結(jié)構(gòu),這并不影響,總之是一個(gè)可以快速增刪改查的數(shù)據(jù)結(jié)構(gòu),比如紅黑樹(shù)、SkipList都行。其次我們還需要一個(gè)log文件,和數(shù)據(jù)庫(kù)當(dāng)中的log一樣,記錄數(shù)據(jù)發(fā)生的變化。方便系統(tǒng)故障或者是數(shù)據(jù)丟失的時(shí)候進(jìn)行找回,所以整體的架構(gòu)如下:
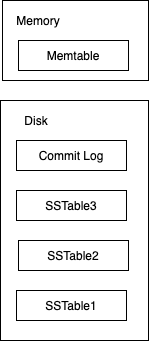
查找
我們先來(lái)看查找的情況,當(dāng)我們需要查找一個(gè)元素的時(shí)候,我們會(huì)先查找Memtable。原因也很好理解,它就在內(nèi)存當(dāng)中,不需要額外讀取文件,如果Memtable當(dāng)中沒(méi)有找到,我們?cè)僖粋€(gè)一個(gè)查找SSTable,由于SSTable當(dāng)中的數(shù)據(jù)也是順序存儲(chǔ)的,所以我們可以使用二分查找,整個(gè)查找的速度也會(huì)非常快。
但是有一點(diǎn),由于SSTable的數(shù)量可能會(huì)很多,而且我們必須要順序查找,所以當(dāng)SSTable數(shù)量很大的時(shí)候,也會(huì)影響查找的速度。為了解決這個(gè)問(wèn)題,我們可以引入布隆過(guò)濾器進(jìn)行優(yōu)化。我們對(duì)每一個(gè)SSTable建立一個(gè)布隆過(guò)濾器,可以快速地判斷元素是否在某一個(gè)SSTable當(dāng)中。布隆過(guò)濾器判斷元素不存在是一定準(zhǔn)確的,而判斷存在可能會(huì)有一個(gè)很小的幾率失誤,但這個(gè)失誤率是可以控制的,我們可以設(shè)置合理的參數(shù),使得失誤率足夠低。
加上了布隆過(guò)濾器之后的查找操作是這樣的:

上圖的星星表示布隆過(guò)濾器,也就是說(shuō)我們先通過(guò)布隆過(guò)濾器判斷元素是否存在之后,再進(jìn)行查找。
布隆過(guò)濾器在之前的文章當(dāng)中曾經(jīng)和大家介紹過(guò),有遺忘或者是新關(guān)注的同學(xué)可以點(diǎn)擊下方鏈接回顧一下。
大數(shù)據(jù)算法——布隆過(guò)濾器
增刪改
除了查找之外的其他操作都發(fā)生在Memtable當(dāng)中,比如當(dāng)我們要增加一個(gè)元素的時(shí)候,我們直接增加在Memtable,而不是寫(xiě)入文件。這也保證了增加的速度可以做到非常快。
除此之外,修改和刪除也一樣,如果需要修改的元素剛好在Memtable當(dāng)中,沒(méi)什么好說(shuō)的我們直接進(jìn)行修改。那如果不在Memtable當(dāng)中,如果我們要先查找到再去修改免不了需要進(jìn)行磁盤(pán)讀寫(xiě),這會(huì)消耗大量資源。所以我們還是在Memtable當(dāng)中進(jìn)行操作,我們會(huì)插入這個(gè)元素,標(biāo)記成修改或者是刪除。
所以我們可以把增刪改這三個(gè)操作都看成是添加,但是這就帶來(lái)了一個(gè)問(wèn)題,這么操作會(huì)導(dǎo)致很快Memtable當(dāng)中就積累了大量數(shù)據(jù),而我們的內(nèi)存資源也是有限的,顯然不能無(wú)限拓張。為了解決這個(gè)問(wèn)題,我們需要定期將Memtable當(dāng)中的內(nèi)容存儲(chǔ)到磁盤(pán),存儲(chǔ)成一個(gè)SSTable。這也是SSTable的來(lái)源,SSTable當(dāng)中的數(shù)據(jù)不是憑空出現(xiàn)的,而是LSM落盤(pán)產(chǎn)生的。

同樣,由于我們不斷地落盤(pán)同樣也會(huì)導(dǎo)致SSTable的數(shù)量增加,前面我們也已經(jīng)分析過(guò)了,SSTable的數(shù)量增加會(huì)影響我們查找的效率,所以我們不能放任它無(wú)限增加。再加上我們還存儲(chǔ)了許多修改和刪除的信息,我們需要把這些信息落實(shí)。為了達(dá)成這點(diǎn),我們需要定期將所有的SSTable合并,在合并的過(guò)程當(dāng)中我們完成數(shù)據(jù)的刪除以及修改工作。換句話(huà)說(shuō),之前的刪除、修改操作只是被記錄了下來(lái),直到合并的時(shí)候才真正執(zhí)行。

整個(gè)歸并的過(guò)程并不難,類(lèi)似于歸并排序當(dāng)中的歸并操作,只是我們需要加上狀態(tài)的判斷。
總結(jié)
我們回顧一下LSMT的整個(gè)過(guò)程,雖然說(shuō)是樹(shù),但其實(shí)樹(shù)形結(jié)構(gòu)并不明顯。但如果我們觀察一下查找元素時(shí)候的查詢(xún)順序,其實(shí)是從Memtable,然后沿著SSTable順序往下的,這點(diǎn)和樹(shù)形結(jié)構(gòu)是一致的,可以看成一個(gè)比較”窄“的樹(shù)。如果還是覺(jué)得這個(gè)數(shù)據(jù)結(jié)構(gòu)長(zhǎng)得不那么像一棵樹(shù)是正常的,我們不用糾結(jié)。另外,從原理上來(lái)看,簡(jiǎn)直有些簡(jiǎn)單粗暴地過(guò)頭,但是從實(shí)際結(jié)果來(lái)看,它的效果卻非常好,在Hbase、kudu當(dāng)中有著廣泛應(yīng)用。
我們對(duì)比一下它和B+樹(shù),在B+樹(shù)當(dāng)中,我們?yōu)榱四軌蚩焖僮x取而使用了多路平衡樹(shù),這樣可以迅速找到對(duì)應(yīng)key的節(jié)點(diǎn)。我們只需要讀入節(jié)點(diǎn)當(dāng)中的內(nèi)容即可,但也正因?yàn)槠胶鈽?shù)的結(jié)構(gòu),導(dǎo)致了我們?cè)趯?xiě)入數(shù)據(jù)的時(shí)候會(huì)引起樹(shù)結(jié)構(gòu)的變動(dòng),也就涉及到多次文件的隨機(jī)讀寫(xiě)。當(dāng)我們數(shù)據(jù)的吞吐量很大的時(shí)候,會(huì)帶來(lái)巨大的開(kāi)銷(xiāo)。而LSMT則不然,我們讀取的時(shí)候效率比B+樹(shù)要低,但是對(duì)于大數(shù)據(jù)的寫(xiě)入支持得更好。在大數(shù)據(jù)場(chǎng)景當(dāng)中,許多對(duì)于數(shù)據(jù)的吞吐量有著很高的要求,比如消息系統(tǒng)、分布式存儲(chǔ)等。這個(gè)時(shí)候B+樹(shù)就有些無(wú)能為力了,但是同樣,如果我們需要保證查找的效率,那LSMT也不太合適,因此兩者其實(shí)并沒(méi)有誰(shuí)比誰(shuí)更優(yōu),而是針對(duì)的場(chǎng)景不同。
最后,關(guān)于LSMT,其實(shí)也有很多個(gè)變種,其中比較有名的是Jeff Dean寫(xiě)的Leveldb,它在LSMT的基礎(chǔ)上做了一些改動(dòng),進(jìn)一步提升了性能,相關(guān)的內(nèi)容我們放到下篇文章。
今天的文章就是這些,如果覺(jué)得有所收獲,請(qǐng)順手點(diǎn)個(gè)關(guān)注或者轉(zhuǎn)發(fā)吧,你們的舉手之勞對(duì)我來(lái)說(shuō)很重要。





