

作者 | L的存在
來源 | 我是程序員小賤(ID:Lanj1995Q)
說到后端開發,難免會遇到各種所謂高大上的「關鍵詞 」,對于我們應屆生小白,難免會覺得比較陌生,因為在學校確實比較少遇見這些所謂高大上的東西,那么今天就帶著學習的態度和大家分享這些看似可以裝逼可以飛的帶逼格的關鍵詞吧。

大綱

分布式
在學校里的項目中,一個 Web 系統可能咋們一個人就搞定,因為幾乎不考慮并發量,性能咋樣,所謂「過得去 」足矣,但是為了面試考慮,我們又不得不找點類似秒殺系統作為我們簡歷的支撐項目(即使已經爛大街)。那么先問你第一個問題,為什么就采用了分布式的方案落地這個項目?
當一個人或者幾十個使用你的系統,哎呀我去,請求秒回,效果倍棒,于是乎簡歷砰砰寫上卻多么牛X,當面試官就會問你你這項目做了啥,測試過沒,并發量如何,性能如何?你就…..
當訪問系統的用戶越來越多,可是我們的系統資源有限,所以需要更多的 CPU 和內存去處理用戶的計算請求,當然也就要求更大的網絡帶寬去處理數據的傳輸,也需要更多的磁盤空間存儲數據。
資源不夠,消耗過度,服務器崩潰,系統也就不干活了,那么在這樣的情況怎么處理?
-
垂直伸縮
縱向生長。通過提升單臺服務器的計算處理能力來抵抗更大的請求訪問量。比如使用更快頻率的CPU,更快的網卡,塞更多的磁盤等。
其實這樣的處理方式在電信,銀行等企業比較常見,讓摩托車變為小汽車,更強大的計算機,處理能力也就越強,但是對于運維而言也就越來越復雜。那真的就這樣花錢買設備就完事了?
當然不,單臺服務器的計算處理能力是有限的,而且也會嚴重受到計算機硬件水平的制約。
-
水平伸縮
一臺機器處理不過來,我就用多臺廉價的機器合并同時處理,人多力量大嘛,通過多臺服務器構成分布式集群從而提升系統的整體處理能力。這里說到了分布式,那我們看看分布式的成長過程
記住一句話:系統的技術架構是需求所驅動
最初的單體系統,只需要部分用戶訪問:

單體結構
做系統的原因當然是有需求,有價值,可賺錢。隨著使用系統的用戶越來越多,這時候關注的人越來越多,單臺服務器扛不住了,關注的人覺得響應真慢,沒啥意思,就開始吐槽,但是這一吐槽,導致用戶更多,畢竟大家都愛吃瓜。
這樣下去不得不進行系統的升級,將數據庫和應用分離。

數據庫應用分離
這樣子,咋們將數據庫和應用程序分離后,部署在不同的服務器中,從1臺服務器變為多臺服務器,處理響應更快,內容也夠干,訪問的用戶呈指數增長,這多臺服務器都有點扛不住了,怎么辦?
加一個緩存吧,我們不每次從數據庫中讀取數據,而將應用程序需要的數據暫存在緩沖中。緩存呢,又分為本地緩存和分布式的緩存。分布式緩存,顧名思義,使用多臺服務器構成集群,存儲更多的數據并提供緩存服務,從而提升緩存的能力。
加了緩存哪些好處?
-
應用程序不再直接訪問數據庫,提升訪問效率。因為緩存內容在內存中,不用每次連接存放磁盤中的數據庫。
系統越來越火,于是考慮將應用服務器也作為集群。

集群

緩存架構
干啥啥不行,緩存第一名。不吹牛,緩存應用在計算機的各個角落。緩存可說是軟件技術中的的殺手锏,無論是程序代碼使用buffer,還是網絡架構中使用緩存,虛擬機也會使用大量的緩存。
其實最初在CPU中也就開始使用緩存。緩存分為兩種,一種是通讀緩存,一種是旁路緩存
-
通讀緩存
假設當前應用程序獲取數據,如果數據存在于通讀緩存中就直接返回。如果不存在于通讀緩存,那么就訪問數據源,同時將數據存放于緩存中。
下次訪問就直接從緩存直接獲取。比較常見的為CDN和反向代理。

通讀緩存
CDN
CDN稱為內容分發網絡。想象我們京東購物的時候,假設我們在成都,如果買的東西在成都倉庫有就直接給我們寄送過來,可能半天就到了,用戶體驗也非常好,就不用從北京再寄過來。
同樣的道理,用戶就可以近距離獲得自己需要的數據,既提高了響應速度,又節約了網絡帶寬和服務器資源。
-
旁路緩存
應用程序需要自己從數據源讀取數據,然后將這個數據寫入到旁路緩存中。這樣,下次應用程序需要數據的時候,就可以通過旁路緩存直接獲得數據了。

旁路緩存
緩存的好處
-
因為大部分緩存的數據存儲在內存中,相比于硬盤或者從網絡中獲取效率更高,響應時間更快,性能更好;
-
通過 CDN 等通讀緩存可以降低服務器的負載能力;
-
因為緩存通常會記錄計算結果。如果緩存命中直接返回,否則需要進行大量的運算。所以使用緩存也減少了CPU 的計算小號,加快處理速度。
緩存缺點
我們緩存的數據來自源數據,如果源數據被修改了,俺么緩存數據很肯能也是被修改過的,成為臟數據,所以怎么辦?
-
過期失效
在每次寫入緩存數據的時候標記失效時間,讀取數據的時候檢查數據是否失效,如果失效了就重新從數據源獲取數據。
-
失效通知
應用程序在更新數據源的時候,通知清除緩存中的數據。
是不是數據使用緩存都有意義呢?
非也,通常放入緩存中的數據都是帶有熱點的數據,比如當日熱賣商品,或者熱門吃瓜新聞,這樣將數據存放在緩存中,會被多次讀取,從而緩存的命中率也會比較高。

異步架構
在前面中,通過緩存實際上很多時候是解決了讀的問題,加快了讀取數據的能力。因為緩存通常很難保證數據的持久性和一致性,所以我們通常不會將數據直接寫入緩存中,而是寫入 RDBMAS 等數據中,那如何提升系統的寫操作性能呢?
此時假設兩個系統分別為A,B,其中A系統依賴B系統,兩者通信采用遠程調用的方式,此時如果B系統出故障,很可能引起A系統出故障。
從而不得不單獨進行升級,怎么辦?
使用消息隊列的異步架構,也成為事件驅動模型。
異步相對于同步而言,同步通常是當應用程序調用服務的時候,不得不阻塞等待服務期完成,此時CPU空閑比較浪費,直到返回服務結果后才會繼續執行。

同步
舉個例子,小藍今天想在系統中加一個發郵件的功能,通過SMTP和遠程服務器通信,但是遠程服務器有很多郵件需要等待發送呢,當前郵件就可能等待比較長時間才能發送成功,發送成功后反饋與應用程序。
這個過程中,遠程服務器發送郵件的時候,應用程序就阻塞,準確的說是執行應用程序的線程阻塞。
這樣阻塞帶來什么問題“?
-
不能釋放占用的系統資源,導致系統資源不足,影響系統性能
-
無法快速給用戶響應結果
但是在實際情況中,我們發送郵件,并不需要得到發送結果。比如用戶注冊,發送賬號激活郵件,無論郵件是否發送成功都會收到"返回郵件已經發送,請查收郵件確認激活",怎樣才能讓應用程序不阻塞?

消息隊列的異步模型
此時就比較清晰了,調用者將消息發送給消息隊列直接返回,應用程序收到返回以后繼續執行,快讀響應用戶釋放資源。
有專門的消費隊列程序從中消息隊列取出數據并進行消費。如果遠程服務出現故障,只會傳遞給消費者程序而不會影響到應用程序。

消息隊列
消息隊列模型中通常有三個角色,分別為生產者,消息隊列和消費者。生產者產生數據封裝為消息發送給消息隊列,專門的消費程序從消息隊列中取出數據,消費數據。
在我看來,消息隊列主要是緩沖消息,等待消費者消費。其中消費的方式分為兩種:
-
點對點
對生產者多消費者的情況。一個消息被一個消費者消費
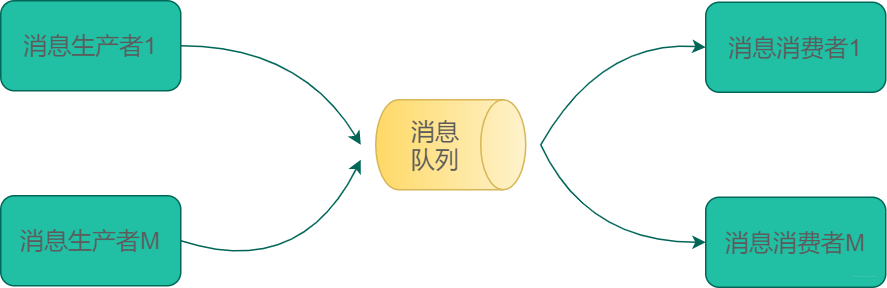
多生產消費
上述的發郵件例子就是典型的點對點模式。互不干擾,其中某個服務出現問題不會印象到全局。
-
訂閱模式
開發人員在消息隊列中設置主題,生產者往相應的主題發送數據,消費者從對應的主題中消費數據,每個消費者按照自己業務邏輯分別進行計算

訂閱模式
這個比較好理解,比如在用戶注冊的時候,我們將注冊信息放入主題用戶中,消費者訂閱了這個主題,可能有構造短信消息的消費者,也有推廣產品的消費者,都可以根據自己業務邏輯進行數據處理。

用戶注冊案例
使用異步模型的優點
-
快速響應
不在需要等待。生產者將數據發送消息隊列后,可繼續往下執行,不虛等待耗時的消費處理
-
削峰填谷(需要修改)
互聯網產品會在不同的場景其并發請求量不同。互聯網應用的訪問壓力隨時都在變化,系統的訪問高峰和低谷的并發壓力可能也有非常大的差距。
如果按照壓力最大的情況部署服務器集群,那么服務器在絕大部分時間內都處于閑置狀態。
但利用消息隊列,我們可以將需要處理的消息放入消息隊列,而消費者可以控制消費速度,因此能夠降低系統訪問高峰時壓力,而在訪問低谷的時候還可以繼續消費消息隊列中未處理的消息,保持系統的資源利用率。
-
降低耦合
如果調用是同步,如果調用是同步的,那么意味著調用者和被調用者必然存在依賴,一方面是代碼上的依賴,應用程序需要依賴發送郵件相關的代碼,如果需要修改發送郵件的代碼,就必須修改應用程序,而且如果要增加新的功能
那么目前主要的消息隊列有哪些,其有缺點是什么?(好好記下這個高頻題目啦)

負載均衡
一臺機器扛不住了,需要多臺機器幫忙,既然使用多臺機器,就希望不要把壓力都給一臺機器,所以需要一種或者多種策略分散高并發的計算壓力,從而引入負載均衡,那么到底是如何分發到不同的服務器的呢?
砸錢
最初實現負載均衡采取的方案很直接,直接上硬件,當然也就比較貴,互聯網的普及,和各位科學家的無私奉獻,各個企業開始部署自己的方案,從而出現負載均衡服務器。
HTTP重定向負載均衡
也屬于比較直接,當HTTP請求叨叨負載均衡服務器后,使用一套負載均衡算法計算到后端服務器的地址,然后將新的地址給用戶瀏覽器,瀏覽器收到重定向響應后發送請求到新的應用服務器從而實現負載均衡,如下圖所示:

HTTP重定向負載均衡
優點:
-
簡單,如果是JAVA開發工程師,只需要servlet中幾句代碼即可
缺點:
-
加大請求的工作量。第一次請求給負載均衡服務器,第二次請求給應用服務器
-
因為要先計算到應用服務器的 IP 地址,所以 IP 地址可能暴露在公網,既然暴露在了公網還有什么安全可言
DNS負載均衡
了解計算機網絡的你應該很清楚如何獲取 IP 地址,其中比較常見的就是 DNS 解析獲取 IP 地址。
用戶通過瀏覽器發起HTTP請求的時候,DNS 通過對域名進行即系得到 IP 地址,用戶委托協議棧的 IP 地址簡歷 HTTP 連接訪問真正的服務器。這樣不同的用戶進行域名解析將會獲取不同的IP地址從而實現負載均衡。

DNS負載均衡
乍一看,和HTTP重定向的方案不是很相似嗎而且還有 DNS 解析這一步驟,也會解析出 IP 地址,不一樣的暴露?
每次都需要解析嗎,當然不,通常本機就會有緩存,在實際的工程項目中通常是怎么樣的呢?
-
通過 DNS 解析獲取負載均衡集群某臺服務器的地址;
-
負載均衡服務器再一次獲取某臺應用服務器,這樣子就不會將應用服務器的 IP 地址暴露在官網了。
反向代理負載均衡
這里典型的就是Nginx提供的反向代理和負載均衡功能。用戶的請求直接叨叨反向代理服務器,服務器先看本地是緩存過,有直接返回,沒有則發送給后臺的應用服務器處理。
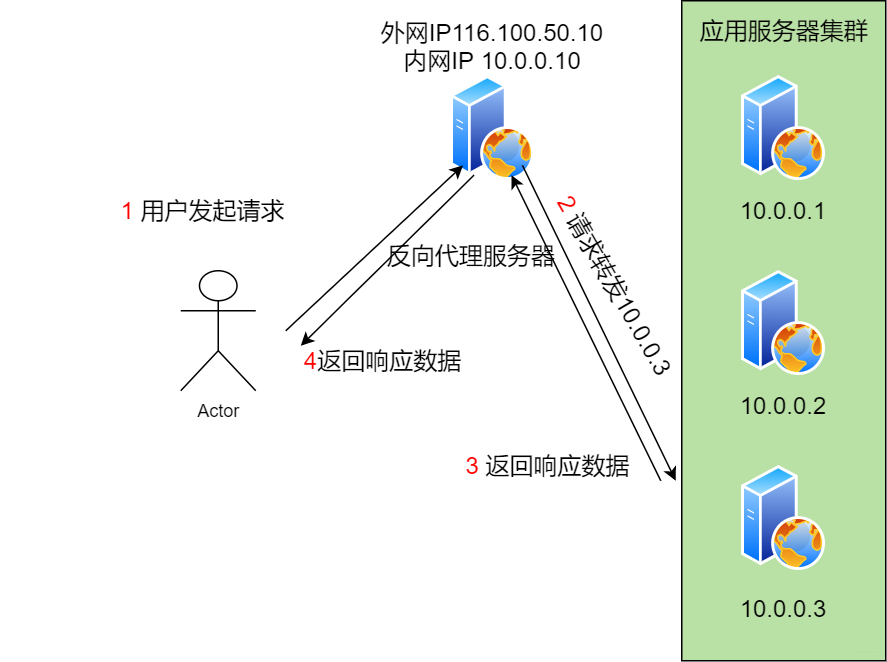
反向代理負載均衡
IP負載均衡
上面一種方案是基于應用層的,IP很明顯是從網絡層進行負載均衡。TCP./IP協議棧是需要上下層結合的方式達到目標,當請求到達網絡層的黑猴。
負載均衡服務器對數據包中的IP地址進行轉換,從而發送給應用服務器。

IP負載均衡
注意,這種方案通常屬于內核級別,如果數據比較小還好,但是大部分情況是圖片等資源文件,這樣負載均衡服務器會出現響應或者請求過大所帶來的瓶頸。
數據鏈路負載均衡
它可以解決因為數據量他打而導致負載均衡服務器帶寬不足這個問題。怎么實現的呢。它不修改數據包的IP地址,而是更改mac地址。
應用服務器和負載均衡服務器使用相同的虛擬IP。
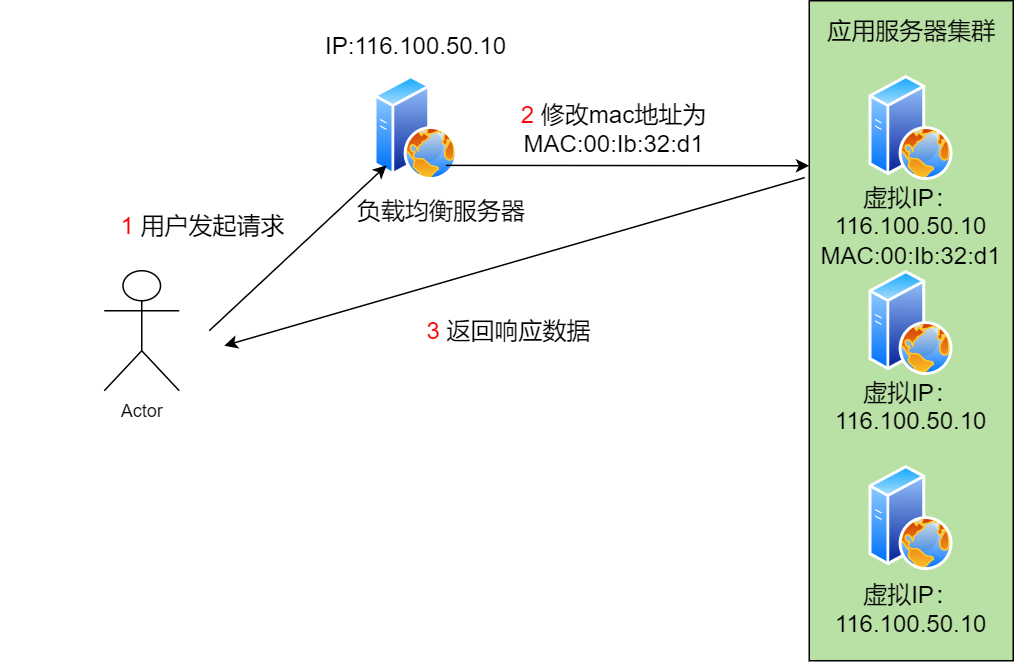
數據鏈路負載均衡
以上介紹了幾種負載均衡的方式,但是很重要的負載均衡算法卻沒有設計,其中包含了輪詢,隨機,最少連接,下面分別對此進行介紹。

數據存儲
公司存在的價值在于流量,流量需要數據,可想而知數據的存儲,數據的高可用可說是公司的靈魂。那么改善數據的存儲都有哪些手段或方法呢?
-
數據主從復制
主從復制比較好理解,需要使用兩個數據庫存儲一樣的數據。其原理為當應用程序A發送更新命令到主服務器的時候,數據庫會將這條命令同步記錄到Binlog中。
然后其它線程會從Binlog中讀取并通過遠程通訊的方式復制到另外服務器。服務器收到這更新日志后加入到自己Relay Log中,然后SQL執行線程從Relay Log中讀取次日志并在本地數據庫執行一遍,從而實現主從數據庫同樣的數據。

主從復制
主從復制可以方便進行讀寫分離,可以使用一主多從的方式保證高可用,如果從數據庫A掛了,可以將讀操作遷移到從數據庫完成高可用。
但是如果主數據庫掛了咋搞,那就MySQL的主主復制。可是不管上面說的那種方式都不是提升它的存儲能力,這就需要進行數據庫的分片了。
-
數據庫分片
將一張表分成若干片,其中每一片都包含一部分行記錄,然后將每一片存儲在不同的服務器中,這樣就實現一張表存放在多臺服務器中,哪都有哪些分片存儲的方案?
最開始使用"硬編碼"的方式,此方式從字面上可以理解為直接在代碼中指定。假定表為用戶表,通過ID的奇偶存放在不同的服務器上,如下圖:

這種方式的缺點很明顯,當需要增加服務器的時候,就需要改動代碼,這就不友好了。比較常見的數據庫分片算法是通過余數Hash算法,根據主鍵ID和服務器的數量取模,根據余數確定服務器。

搜索引擎
我們使用谷歌瀏覽器的時候,輸入搜索關鍵字,就會出現搜索到多少條結果,用時多少,它是如何做到在如此短的時間完成這么大數據量的搜索。
先來想第一個問題,全世界這么多網頁在哪里?
互聯網的存在讓你和我隔著屏幕都知道你多帥。當然,每個網頁中都會存在很多其他網頁的超鏈接,這樣構成了龐大的網絡。
對于搜索引擎而言,目標為解析這些網頁獲取超鏈接,下載鏈接內容(過濾),具體一些說。
將URL存放于池子中,從池子中取出URL模擬請求,下載對應的html,并存放于服務器上,解析HTML內容時如果有超鏈接URL,檢測是否已經爬取過,如果沒有暫存隊列,后面再依次爬取。架構圖如下:

爬蟲常規方法
將獲取的所有網頁進行編號并得到網頁集合。然后通過分詞技術獲得每一個單詞,組成矩陣如下所示:

分詞
就這樣按照單詞-文檔的方式組織起來就叫做倒排索引了。

倒排索引
google通過建立<單詞,地址>這樣的文檔,主要搜索到單詞就能定位到文檔的地址列表,然后根據列表中文檔的編號就展現文檔信息從而實現快速的檢索。
如果搜索出來結果很多,Google是如何能更精準的將我們需要的信息呈現給我們呢。它很明顯有個排序功能,那是如何排序的?
Google使用了一種叫做"PageRank"的算法,通過計算每個網頁的權重,并按照權重排序,權重高的自然就在顯示在前面,那問題來了,為啥權重高的,排在前面的通常就是用戶所需要的呢?這就得了解下pagerank算法了。
在pagerank中,如果網頁A包含網頁B說明A認可B,即投一票。如下圖ABCD四個網頁所示,箭頭代表超鏈接的方向,比如A->B代表A網頁包含B的超鏈接
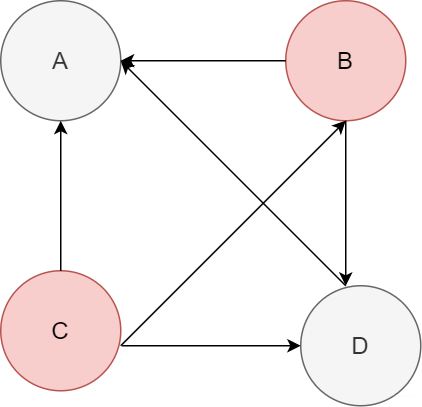
pagerank
怎么計算的?
ABCD 初始值都為1,然后根據關系計算權重。比如此時B包含了AD兩個網頁,那么權重1被分為兩個1/2分別給A和D,此時A包含BCD,那么此時A頁面新的權重為1/2 + 1/3 + 1 = 11/6。
pagerank 值越受推薦,代表用戶越想看到。基于每個網頁的 pagerank 值對倒排索引中的文檔列表排序,靠前者則是用戶想看到的文檔。
這種是因為超鏈接,引入權值的方式排序。還有其他諸如對于商品售賣次數排序或者電影點贊或評價分數排序。
還有通過關鍵字查找,希望找到和搜索詞相關,這個時候可能就會采用詞頻TF進行排序,詞頻代表所查詞和文檔的相關程度。
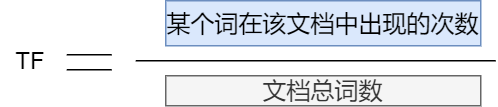
詞頻TF
比如我們搜索"Java后端"出現的結果以"后端"的相關技術。
在大部分的應用中都會涉及到搜索引擎技術,技術龐大且復雜,希望各位老鐵根據自身情況搜索相關所需學習,校招面試中不出現盲點即可。

微服務
技術的引進一定是想解決某個痛點。我不希望在一個系統中,一小點改動就影響到全局,希望各個功能模塊拆分清晰,不管是測試還是運維都能節省更多的時間。
那么單體的架構出現了哪些問題?
-
代碼分支管理困難
各個部門分別完成各自的任務,但是最后需要 merge 在一起成為整個系統,merge過程經歷的人都知道,問題是真XX多。所以不再是996
-
新增功能麻煩
隨著項目的效益越來越好,用戶的需求也更多,招聘的人可能更多,對于新手來說上來是一臉懵逼的,老員工忙的要死,新員工成為了摸魚專家
-
耗盡連接
用戶的增多,每個應用都得和數據庫連接,給數據庫的連接造成太大的壓力甚至耗盡連接
微服務
“微"-------微微一笑很傾城,微笑,微小。顧名思義,講一個大的系統,拆分為一個個小的服務,分別對各個小服務進行管理。這樣說感覺太不專業了,專業點
-
大應用拆分為小模塊
-
小模塊不屬于集群中
-
通過遠程調用的方式依賴各個獨立的模塊完成業務的處理
這些小的模塊就叫做------微服務,整體也就是所謂的微服務架構。
既然拆分成了小服務,這么多小服務怎么協調成為一個問題,甚至都不知道怎么掉這個服務,所以在微服務的整體架構中出現了注冊中心,誰需要調用使用提供的接口即可。如下圖所示:

注冊中心
從上圖我們能知道主要是三個概念:
-
服務提供者
微服務的具體提供者,其他微服務通過接口調用即可
-
服務消費者
對應于服務提供者,按照提供者接口編程即可。這么輕松的嘛,當然很多細節。舉個例子,注明的dubbo服務框架,服務接口通過Dubbo框架代理機制訪問Dubbo客戶端,客戶端通過服務接口聲明去注冊中心查看有哪些服務器,并將這服務器列表給客戶端。
客戶端然后根據負載均衡策略選擇其中一個服務器,通過遠程調用的方式發送服務調用。那么使用微服務需要注重哪幾點?

選擇中的注意事項
不要拿工具硬上需求,結合業務也許會更佳!

高可用
高可用,意味著一臺機器掛了沒事,其他機器可以照常工作,用戶體驗一樣倍棒,用戶壓根就不知道,臥槽,你居然升級了系統,我居然一點感受都沒有。那么高可用總有個標準吧,是百分之80就行還是90?
一個系統突然不能訪問的原因很多:
-
硬件故障
-
數據庫宕機
-
磁盤孫歡
-
bug
-
光纜斷了
可用性指標
通過多少個9來衡量,比如大寶系統可用性為4個9,意味著是99.99%,說明它的服務保證運行時間只有0.01不可用。
高可用涉及到技術成本和設備成本,不是說高可用值越高越好,而是根據具體工具具體場景而定,這里分享一些高可用策略。
冗余備份
任何一個服務都有備份,就反復我們都會對我們筆記本電腦相關文件進行備份一樣,以防萬一。即使一臺服務器掛了,可以很快的切換以致于讓用戶不會覺得"這系統怎么這么渣"。
負載均衡
使用多臺服務器分擔一臺服務器的壓力,滿足高并發的請求。怎么實現的呢,應用程序會有一個心跳檢測/健康檢查機制,如果發現不妥切換即可。上面提到的數據庫主主復制也是高可用的方案之一,技術思想果然是相通的
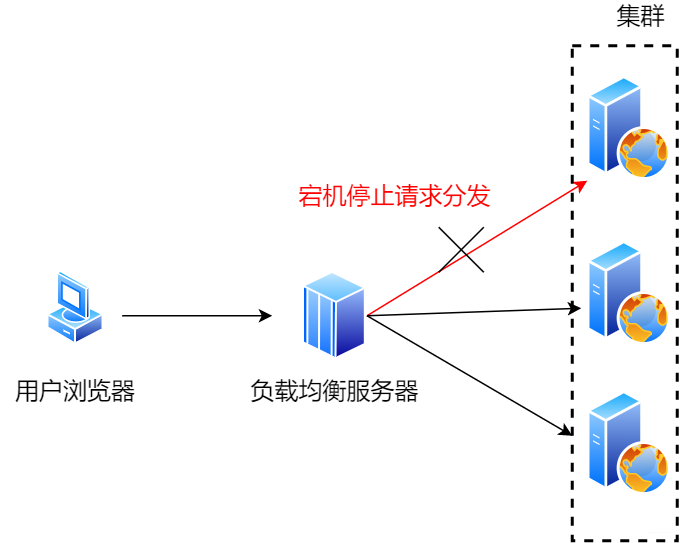
負載均衡
限流降級
我們的目標不是沒有蛀牙,而是希望整個系統不要掛掉。限流是對部分請求進行丟棄處理,保證大部分的用戶可以正常的請求完成任務。
降級:
可以屏蔽部分當前看來不是很有用的任務。比如電商系統做秒殺活動的過程中,確認收貨功能給予的壓力挺大,暫時看來并不是核心任務,而且系統到期也會自動確認收貨,所以暫時關閉,將系統的資源留給準備下單,放購物車的太太們
異地多活:
有時候我在想要是地震,火災等自然災害發生的時候,很多系統的數據怎么辦啊。想多了撒,大些的系統多會在各個地方部署數據中心,采用異地多活的多機房策略。用戶可以訪問任何數據中心,那問題來了,用戶的請求是如何到達不同的機房去的?
-
域名解析

安全性
公司中的數據財產,其重要程度不言而喻。系統的健壯性和安全性是保證系統持久運行的基礎。不要因為數據泄露才去關注安全問題。
也許說到安全問題,首先想到的是“用戶名密碼”泄漏,數據庫被脫褲導致數據泄露,hack直接拿到用戶的敏感信息,所以我們通常有哪些手段或方法來盡全力的抵抗hack嘞,辦法總比問題多嘛。
-
數據加解密
通過對用戶密碼,身份證等敏感數據加密是常用方法。加密方法通常分為:單向散列加密,對稱加密和非對稱加密。
所謂單向散列加密,主要體現在單向二字,意味著對明文加密后是不可以解密,你即使是給明文加密的加密者,也無法通過密文知道其明文是什么,即加密單向,不支持解密。說的這么絕對?這么無敵?
那只是理論上而已,常用的MD5算法就是大象散列加密,我們完全可以通過彩虹表等方式進行破解。怎么破解?
說個簡單的道理,我們設置密碼的時候,通常會使用生日?手機號?什么love?什么520?,這些組合是有限的,我們就可以建立一個比如生日和密文的映射表,然后通過XX彩虹表就可得到密碼明文。

單向散列加密
所以,通常的情況,使用單向散列加密的時候需要加一點鹽,這樣一來,hack拿到密文,不知道鹽,無法建立彩虹表,就更難還原明文。
應用場景:通常應用在用戶密碼加密。其加密和校驗過程如下:
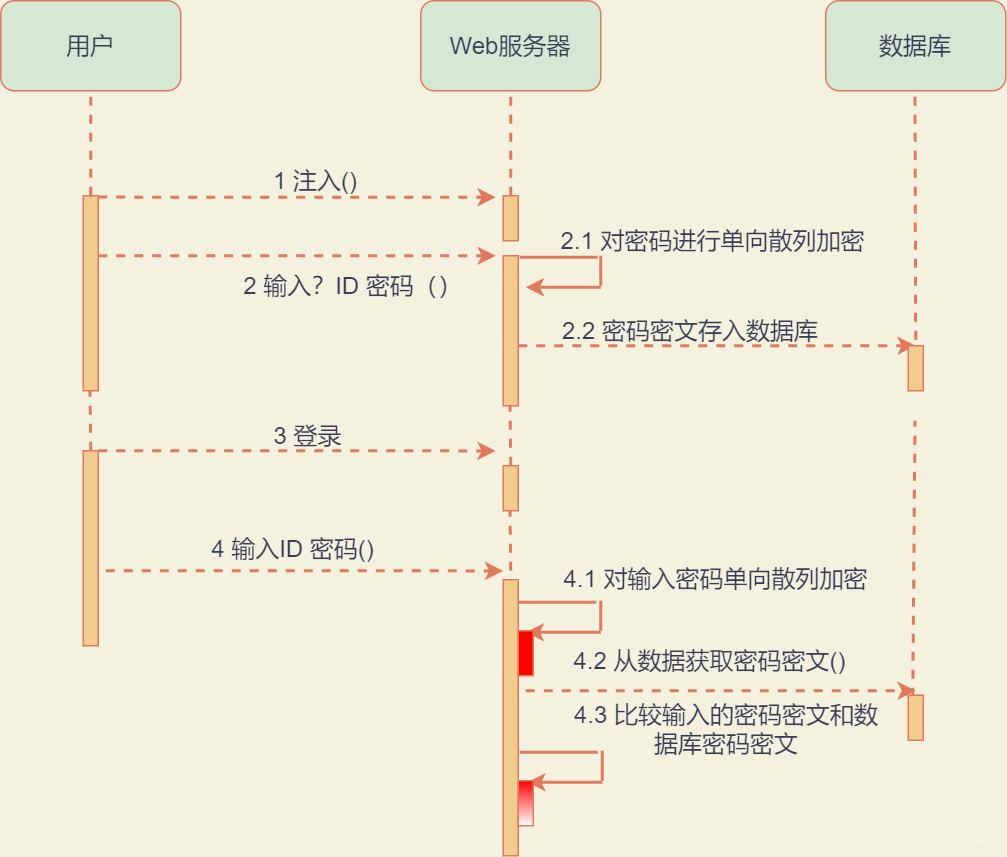
應用場景
我們通過上圖來回顧一下一個網站的注冊登錄模塊中的用戶部分,用戶注冊需要輸入用戶名和密碼,我們一般不會將裸露的將密碼直接存放在數據庫,不然被脫褲直接算裸奔。
所以,用戶輸入密碼,應用服務器獲得密碼后,調用單向散列加密算法,將加密的密文存放于數據庫,用戶下一次登錄的時候,用戶依然會輸入密碼。
只是到了Web服務器后,Web服務器會對輸入的密碼再進行一次單向散列加密,然后和數據庫中取出來的密文進行對比,如果相同,則用戶的驗證成功,通常這樣的方式可以保證用戶密碼的安全性,當然如果加一點鹽,會增加破解的難度。
對稱加密
對稱加密是通過一個加密算法和密鑰,對一段明文進行加密后得到密文,然后使用相同的密鑰和對應的解密算法進行解密得到明文。

對稱加密
舉個例子,我們不會將銀行卡卡號,有效期等直接存儲在數據庫,而是會通過先加密,然后存儲于數據庫。
使用的時候必須對密文進行解密還原出明文。這個時候使用對稱加密算法,存儲的時候加密算法進行加密,使用的時候解密算法解密。
非對稱加密
非對稱加密是說使用一個加密算法和一個加密秘鑰進行加密得到密文,但是在解密出明文的時候,其加解密密鑰和加密密鑰不同,通常加密密鑰叫做公鑰,解密密鑰叫做私鑰。
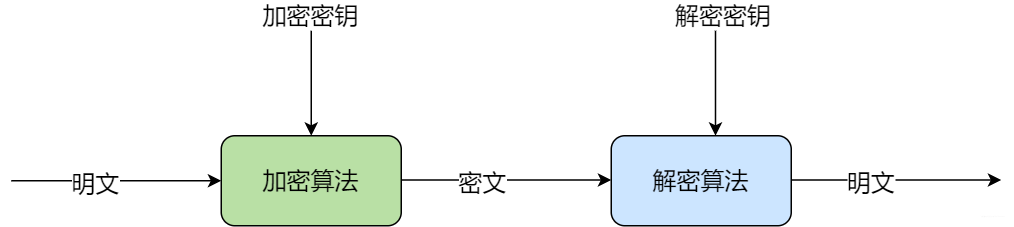
非對稱加密
其實我們常用的 HTTPS 即是非對稱加密的應用場景。用戶在客戶端進行通訊的時候,對數據使用的加密密鑰和加密算法進行加密得到密文,到了服務端以后,使用解密密鑰和算法進行解密得到明文。
但是非對稱消耗的資源比較多,所以HTTPS不是每次請求響應都采用非對稱加密,而是先利用非對稱加密,在客戶單和服務器之間交換一個對稱加密的密鑰,然后每次的請求響應再使用對稱加密。
綜上,使用費對稱加密保證對稱加密迷藥的安全,使用對稱加密密鑰保證請求響應數據的安全。
HTTP攻擊與防護
HTTP明文協議,咋們通過嗅探工具就可以清晰查看會話內容,這也是hack攻擊門檻最低的方式。很常見的也就是SQL注入和XSS攻擊。
SQL注入是攻擊者在提交請求參數的時候,包含了惡意的SQL腳本:

SQL注入
server處理計算后向數據庫提交的SQL如下:
Select id from users where username='Mike';
如果是惡意攻擊,提交的HTTP請求如下:
http://www.a.com?username=Mike';drop table users;--
此時最終生成的SQL是:
Select id from users where username='Mike';drop table users;--';
查詢完就直接給刪除表了。怎么防護?
比較常用的解決方案是使用PrepareStaement預編譯,先將SQL交給數據庫生成執行計劃,后面hack不管提交什么字符串也只能交給這個執行計劃執行,不會生成新的SQL,也就不會被攻擊啦。
XSS攻擊
跨站點腳本攻擊,攻擊者通過構造惡意的瀏覽器腳本文件,使其在其他用戶的瀏覽器運行進而進行攻擊。
假設小A將含有惡意腳本的請求給360服務器,服務器將惡意的腳本存儲在本地的數據庫,當其他正常用戶通過這個服務器瀏覽信息的時候,服務器就會讀取數據庫中含有惡意腳本的數據并呈現給用戶,在用戶正常使用瀏覽器的時候達到攻擊的目的。
防御:
比較常見的是在入口處對危險的請求比如drop table等進行攔截,設置一個Web應用防火墻將危險隔離。

安全防御

大數據
其實在上面提到的分布式中就有涉及大數據相關知識。無外乎是數據量越來越大,我們如何盡可能使用較低的成本存儲更多的數據,給公司企業帶來更好的利潤。上面說過分布式緩存,負載均衡等技術,其共同特點是如何抵抗高并發的壓力,而這里的大數據技術主要談論的是如何滿足大規模的計算。
通過對數據的分析,進而發掘海量數據中的價值,這里的數據包含數據庫數據,日志信息,用戶行為數據等等。那么這么多不同類型的數據,怎么去存儲呢?
分布式文件存儲 HDFS 架構
如何將數以萬計的服務器組成統一的文件存儲系統?其中使用Namenode服務器作為控制塊,負責元數據的管理(記錄文件名,訪問權限,數據存儲地址等),而真正的文件存儲在DataNode中。
Mapreduce
大量的數據存儲下來的目的是通過相應的算法進行數據分析,獲得通過深度學習/機器學習進行預測,從而獲取有效的價值,這么大的文件,我們不可能將HDFS當做普通的文件,從文件中讀取數據然后計算,這樣子不知道算到何時何地。
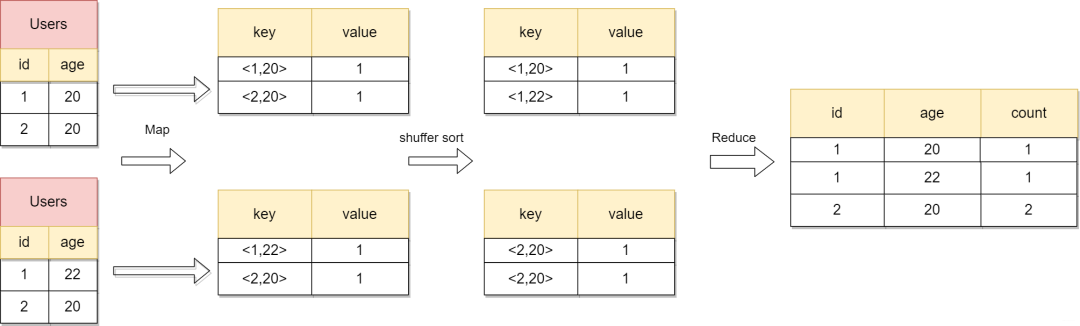
大數據處理經典的處理框架即MapReduce,分為Map和Reduce兩個階段,其中一個Map過程是將每個服務器上啟動Map進程,計算后輸出一個
下面以wordCount統計所有數據中相同的詞頻數據為例,詳細看看Map和Reduce的過程。

wordcoun計算過程
在這個例子中,通過對value中的1組成的列表,reduce對這些1進行求和操作從而得到每個單詞的詞頻。代碼實現如下:
public class WordCount {
// MApper四個參數:第一個Object表示輸入key的類型;第二個Text表示輸入value的類型;第三個Text表示表示輸出鍵的類型;第四個IntWritable表示輸出值的類型。map這里的輸出是指輸出到reduce
public static class doMapper extends Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);//這里的IntWritable相當于Int類型
public static Text word = new Text;//Text相當于String類型
// map參數<keyIn key,valueIn value,Context context>,將處理后的數據寫入context并傳給reduce
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//StringTokenizer是Java工具包中的一個類,用于將字符串進行拆分
StringTokenizer tokenizer = new StringTokenizer(value.toString, " ");
//返回當前位置到下一個分隔符之間的字符串
word.set(tokenizer.nextToken);
//將word存到容器中,記一個數
context.write(word, one);
}
}
//參數同Map一樣,依次表示是輸入鍵類型,輸入值類型,輸出鍵類型,輸出值類型。這里的輸入是來源于map,所以類型要與map的輸出類型對應 。
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable;
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
//for循環遍歷,將得到的values值累加
for (IntWritable value : values) {
sum += value.get;
}
result.set(sum);
context.write(key, result);//將結果保存到context中,最終輸出形式為"key" + "result"
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.out.println("start");
Job job = Job.getInstance;
job.setJobName("wordCount");
Path in = new Path("hdfs://***:9000/user/hadoop/input/buyer_favorite1.txt");//設置這個作業輸入數據的路徑(***部分為自己liunx系統的localhost或者ip地址)
Path out = new Path("hdfs://***:9000/user/hadoop/output/wordCount"); //設置這個作業輸出結果的路徑
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJarByClass(WordCount.class);// 設置運行/處理該作業的類
job.setMapperClass(doMapper.class);//設置實現了Map步的類
job.setReducerClass(doReducer.class);//設置實現了Reduce步的類
job.setOutputKeyClass(Text.class);//設置輸出結果key的類型
job.setOutputValueClass(IntWritable.class);//設置輸出結果value的類型
////執行作業
System.exit(job.waitForCompletion(true) ? 0 : 1);
System.out.println("end");
}
}
那么這個map和reduce進程是怎么在分布式的集群中啟動的呢?

map/reduce啟動過程
上圖比較清晰地闡述的整個過程,再描述一波。MR中主要是兩種進程角色,分別為 JobTracke r和 TaskTracker 兩種。
JobTracker在集群中只有一個,而 TaskTracker 存在多個,當 JobClient 啟動后,往 JobTracker 提交作業,JobTracker查看文件路徑決定在哪些服務器啟動 Map 進程。
然后發送命令給 TaskTracker,告訴它要準備執行任務了,TaskTracker收到任務后就會啟動 TaskRunner 下載任務對應的程序。
map計算完成,TaskTracker對map輸出結果 shuffer 操作然后加載 reduce 函數進行后續計算,這就是各個模塊協同工作的簡單過程。
Hive
上述過程還是比較麻煩,我們能不能直接寫SQL,然后引擎幫助我們生成mapreduce代碼,就反復我們在web開發的時候,不直接寫SQL語句,直接交給引擎那么方便,有的,它就是HIVE。
舉個例子:

SQL

拆分
那么使用MR的計算過程完成這條SQL的處理:
MR TO SQL
Spark
Spark是基于內存計算的大數據并行計算框架。基于此說說上面hadoop中組件的缺點:
-
磁盤IO開銷大。每次執行都需要從磁盤讀取并且計算完成后還需要將將中間結果存放于磁盤
-
表達能力有限。大多數計算都需要轉換為Map和Reduce兩個操作,難以描述復雜的數據處理
spark優點:
-
編程模型不限于map和reduce,具有更加靈活的編程模型
-
spark提供內存計算,帶來更高的迭代運算效率且封裝了良好的機器學習算法
-
采用了基于圖DAG的任務調度機制
Flink
Flink是大數據處理的新規,發展速度之快,這兩年也相繼出現中文資料。作為流式數據流執行引擎,針對數據流的分布式計算提供數據分布,數據通信以及容錯機制等功能。同時Flink也提供了機器學習庫,圖計算庫等。
附一張去年參加會議回答問題中獎的馬克杯,嘻嘻。

去年參會
關于大數據相關知識點可作為擴充點,在面試的過程中經常會有大數問題,除了從算法的角度來闡述,也可以從這些框架中吸取一些經驗。
嘮嗑
對于之前從事c/c++開發的我,很多時候是linux的開發。在學校又沒怎么接觸系統性的項目,更不知道后端技術的博大進深,可能文中涉及的也就一部分,不過希望還在學校的小伙伴可以知道有這些東西,然后通過強大的搜索引擎,給自己個比較明確的方向,也許會少走點彎路,這周的文章就到這了,goodbye!





