擊這里在線咨詢客服")
負(fù)載均衡是將客戶端請求訪問,通過提前約定好的規(guī)則轉(zhuǎn)發(fā)給各個server。其中有好幾個種經(jīng)典的算法,下面我們用JAVA實(shí)現(xiàn)這幾種算法。
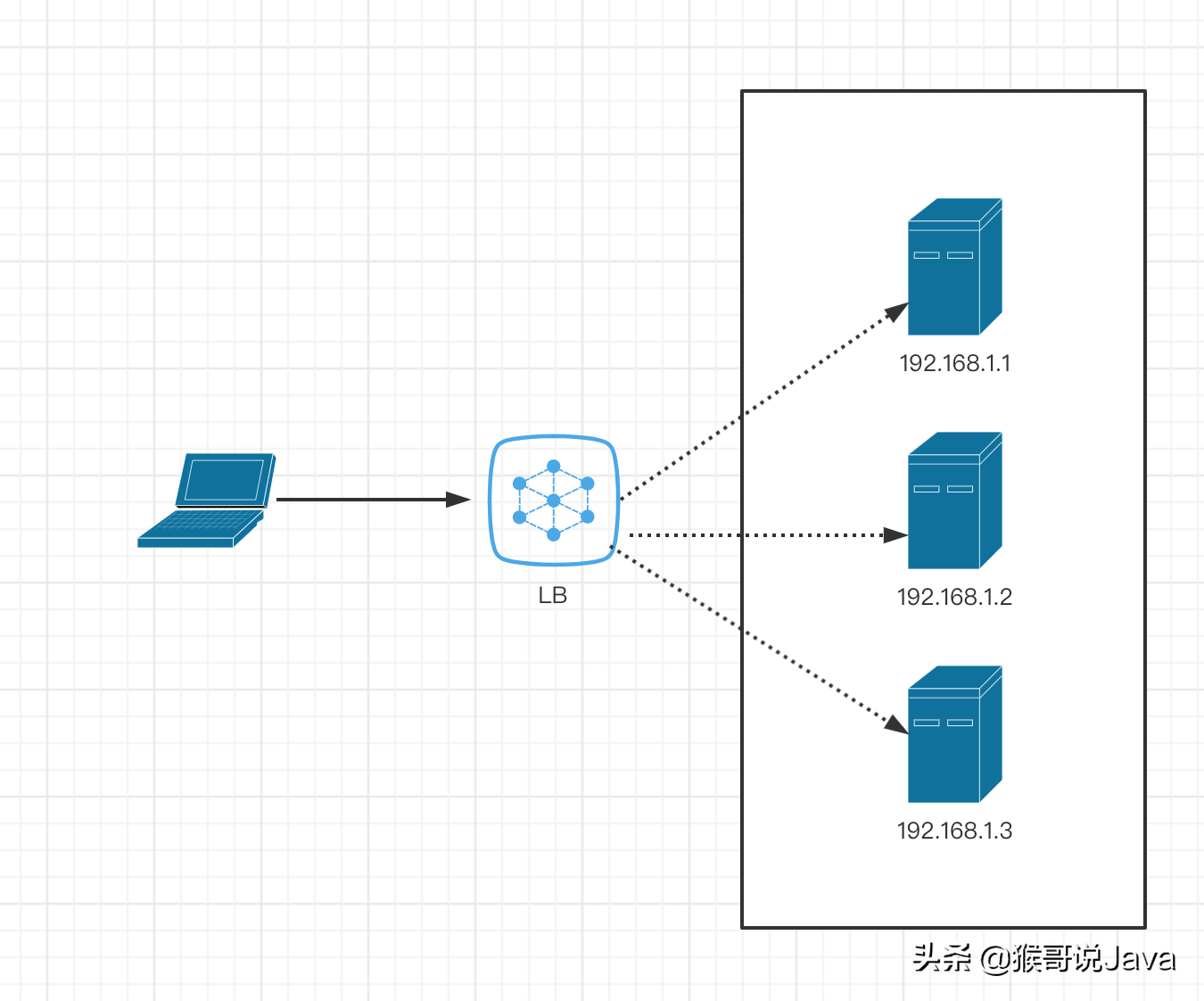
輪詢算法
輪詢算法按順序把每個新的連接請求分配給下一個服務(wù)器,最終把所有請求平分給所有的服務(wù)器。
優(yōu)點(diǎn):絕對公平
缺點(diǎn):無法根據(jù)服務(wù)器性能去分配,無法合理利用服務(wù)器資源。
package com.monkeyjava.learn.basic.robin;
import com.google.common.collect.Lists;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class TestRound {
private Integer index = 0;
private List<String> ips = Lists.newArrayList("192.168.1.1", "192.168.1.2", "192.168.1.3");
public String roundRobin(){
String serverIp;
synchronized(index){
if (index >= ips.size()){
index = 0;
}
serverIp= ips.get(index);
//輪詢+1
index ++;
}
return serverIp;
}
public static void main(String[] args) {
TestRound testRoundRobin =new TestRound();
for (int i=0;i< 10 ;i++){
String serverIp= testRoundRobin.roundRobin();
System.out.println(serverIp);
}
}
}
輸出結(jié)果:
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.1
192.168.1.2
192.168.1.3
192.168.1.1
加權(quán)輪詢法
該算法中,每個機(jī)器接受的連接數(shù)量是按權(quán)重比例分配的。這是對普通輪詢算法的改進(jìn),比如你可以設(shè)定:第三臺機(jī)器的處理能力是第一臺機(jī)器的兩倍,那么負(fù)載均衡器會把兩倍的連接數(shù)量分配給第3臺機(jī)器,輪詢可以將請求順序按照權(quán)重分配到后端。
package com.monkeyjava.learn.basic.robin;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class TestWeight {
private Integer index = 0;
static Map<String, Integer> ipMap=new HashMap<String, Integer>(16);
static {
// 1.map, key-ip,value-權(quán)重
ipMap.put("192.168.1.1", 1);
ipMap.put("192.168.1.2", 2);
ipMap.put("192.168.1.3", 4);
}
public List<String> getServerIpByWeight() {
List<String> ips = new ArrayList<String>(32);
for (Map.Entry<String, Integer> entry : ipMap.entrySet()) {
String ip = entry.getKey();
Integer weight = entry.getValue();
// 根據(jù)權(quán)重不同,放入list 中的數(shù)量等同于權(quán)重,輪詢出的的次數(shù)等同于權(quán)重
for (int ipCount =0; ipCount < weight; ipCount++) {
ips.add(ip);
}
}
return ips;
}
public String weightRobin(){
List<String> ips = this.getServerIpByWeight();
if (index >= ips.size()){
index = 0;
}
String serverIp= ips.get(index);
index ++;
return serverIp;
}
public static void main(String[] args) {
TestWeight testWeightRobin=new TestWeight();
for (int i =0;i< 10 ;i++){
String server=testWeightRobin.weightRobin();
System.out.println(server);
}
}
}
輸出結(jié)果:
192.168.1.1
192.168.1.3
192.168.1.3
192.168.1.3
192.168.1.3
192.168.1.2
192.168.1.2
192.168.1.1
192.168.1.3
192.168.1.3
加權(quán)隨機(jī)法
獲取帶有權(quán)重的隨機(jī)數(shù)字,隨機(jī)這種東西,不能看絕對,只能看相對,我們不用index 控制下標(biāo)進(jìn)行輪詢,只用random 進(jìn)行隨機(jī)取ip,即實(shí)現(xiàn)算法。
package com.monkeyjava.learn.basic.robin;
import java.util.*;
public class TestRandomWeight {
static Map<String, Integer> ipMap=new HashMap<String, Integer>(16);
static {
// 1.map, key-ip,value-權(quán)重
ipMap.put("192.168.1.1", 1);
ipMap.put("192.168.1.2", 2);
ipMap.put("192.168.1.3", 4);
}
public List<String> getServerIpByWeight() {
List<String> ips = new ArrayList<String>(32);
for (Map.Entry<String, Integer> entry : ipMap.entrySet()) {
String ip = entry.getKey();
Integer weight = entry.getValue();
// 根據(jù)權(quán)重不同,放入list 中的數(shù)量等同于權(quán)重,輪詢出的的次數(shù)等同于權(quán)重
for (int ipCount =0; ipCount < weight; ipCount++) {
ips.add(ip);
}
}
return ips;
}
public String randomWeightRobin(){
List<String> ips = this.getServerIpByWeight();
//循環(huán)隨機(jī)數(shù)
Random random=new Random();
int index =random.nextInt(ips.size());
String serverIp = ips.get(index);
return serverIp;
}
public static void main(String[] args) {
TestRandomWeight testRandomWeightRobin=new TestRandomWeight();
for (int i =0;i< 10 ;i++){
String server= testRandomWeightRobin.randomWeightRobin();
System.out.println(server);
}
}
}
輸出結(jié)果:
192.168.1.3
192.168.1.3
192.168.1.2
192.168.1.1
192.168.1.2
192.168.1.1
192.168.1.3
192.168.1.2
192.168.1.2
192.168.1.3
隨機(jī)法
負(fù)載均衡方法隨機(jī)的把負(fù)載分配到各個可用的服務(wù)器上,通過隨機(jī)數(shù)生成算法選取一個服務(wù)器,這種實(shí)現(xiàn)算法最簡單,隨之調(diào)用次數(shù)增大,這種算法可以達(dá)到?jīng)]臺服務(wù)器的請求量接近于平均。
package com.monkeyjava.learn.basic.robin;
import com.google.common.collect.Lists;
import java.util.List;
import java.util.Random;
public class TestRandom {
private List<String> ips = Lists.newArrayList("192.168.1.1", "192.168.1.2", "192.168.1.3");
public String randomRobin(){
//隨機(jī)數(shù)
Random random=new Random();
int index =random.nextInt(ips.size());
String serverIp= ips.get(index);
return serverIp;
}
public static void main(String[] args) {
TestRandom testRandomdRobin =new TestRandom();
for (int i=0;i< 10 ;i++){
String serverIp= testRandomdRobin.randomRobin();
System.out.println(serverIp);
}
}
}
輸出
192.168.1.3
192.168.1.3
192.168.1.1
192.168.1.2
192.168.1.1
192.168.1.3
192.168.1.2
192.168.1.3
192.168.1.3
192.168.1.2
IP_Hash算法
hash(ip)%N算法,通過一種散列算法把客戶端來源IP根據(jù)散列取模算法將請求分配到不同的服務(wù)器上
優(yōu)點(diǎn):保證了相同客戶端IP地址將會被哈希到同一臺后端服務(wù)器,直到后端服務(wù)器列表變更。根據(jù)此特性可以在服務(wù)消費(fèi)者與服務(wù)提供者之間建立有狀態(tài)的session會話
缺點(diǎn): 如果服務(wù)器進(jìn)行了下線操作,源IP路由的服務(wù)器IP就會變成另外一臺,如果服務(wù)器沒有做session 共享話,會造成session丟失。
package com.monkeyjava.learn.basic.robin;
import com.google.common.collect.Lists;
import java.util.List;
public class TestIpHash {
private List<String> ips = Lists.newArrayList("192.168.1.1", "192.168.1.2", "192.168.1.3");
public String ipHashRobin(String clientIp){
int hashCode=clientIp.hashCode();
int serverListsize=ips.size();
int index = hashCode%serverListsize;
String serverIp= ips.get(index);
return serverIp;
}
public static void main(String[] args) {
TestIpHash testIpHash =new TestIpHash();
String servername= testIpHash.ipHashRobin("192.168.88.2");
System.out.println(servername);
}
}
輸出結(jié)果
192.168.1.3
每次運(yùn)行結(jié)果都一樣





