
作者 | 云昭
可觀測對于微服務盛行的年代來講,十分必要。成千上萬的微服務給開發和運維團隊帶來了指數級的維護成本。要解決這個難題,就勢必引入高效的監控工具來輔助技術管理和決策。而K8s作為當下微服務領域的一個熱門選手,如何有效選擇和部署監控K8s集群工具就成為了一個大家共同關注的話題。
PART 01
問題
在K8s環境中,應用程序運行在跨集群內的多個節點,同時服務也將分布在多個集群和多個云中,這就使得追蹤、監控這些應用程序及其所依賴的基礎設施的健康狀況,非常具有挑戰性。
K8s監控涉及從K8s集群收集指標、識別關鍵事件,目的是確保所有硬件、軟件和應用程序按預期運行。因此,將指標集中匯總在一個中心位置,將有效幫助開發者了解和維護整個 K8s隊列以及在其上運行的應用或服務的健康狀況。
而要做到全方位監控非常困難,其中的兩個難點在于:
1、容器化和K8s創建的抽象層之間的監控;
2、K8s環境中運行的應用程序的動態特性之間的監控。
這篇文章探討了一些不錯的K8s監控和日志工具,包括用于監控的Prometheus和用于可視化和儀表板的Grafana等。
PART 02
K8s可觀測工具
目前業界流行的用于K8s容器監控的開源工具并不少,比較常見的有:Prometheus、Grafana、Elasticsearch、Thanos等。
1. Prometheus
Prometheus是一個開源系統監控和警報工具包,最初在 SoundCloud 構建,靈感來自 google 使用的 Borgmon 工具。自 2012 年成立以來,許多公司和組織都采用了 Prometheus,該項目擁有非常活躍的開發者和用戶社區。
Prometheus 于 2016 年加入云原生計算基金會,成為繼K8s之后的第二個托管項目。雖然本文在K8s監控的背景下討論 Prometheus,但它可以滿足各種各樣的監控需求,比如幫助簡化指標收集、關聯事件和警報、提供安全性以及進行大規模故障排除和跟蹤。
Prometheus的主要功能之一就是指標收集,這里的指標是什么?這要根據用戶想要測量的內容或應用程序而異。對于 Web 服務器,它可能是請求時間,對于數據庫,它可能是活動連接數或活動查詢數等。Prometheus收集并存儲用戶指定的指標作為時間序列數據。可以分析指標以了解集群及其組件的運行狀態。
Prometheus的可靠性非常出色。這有助于確保在用戶的環境中出現其他問題時,Prometheus仍然可以訪問。每個Prometheus服務器都是獨立的。本地時間序列數據庫使其獨立于遠程存儲或其他遠程服務。這有助于快速識別問題并接收有關受監控集群和應用程序系統性能的實時反饋。
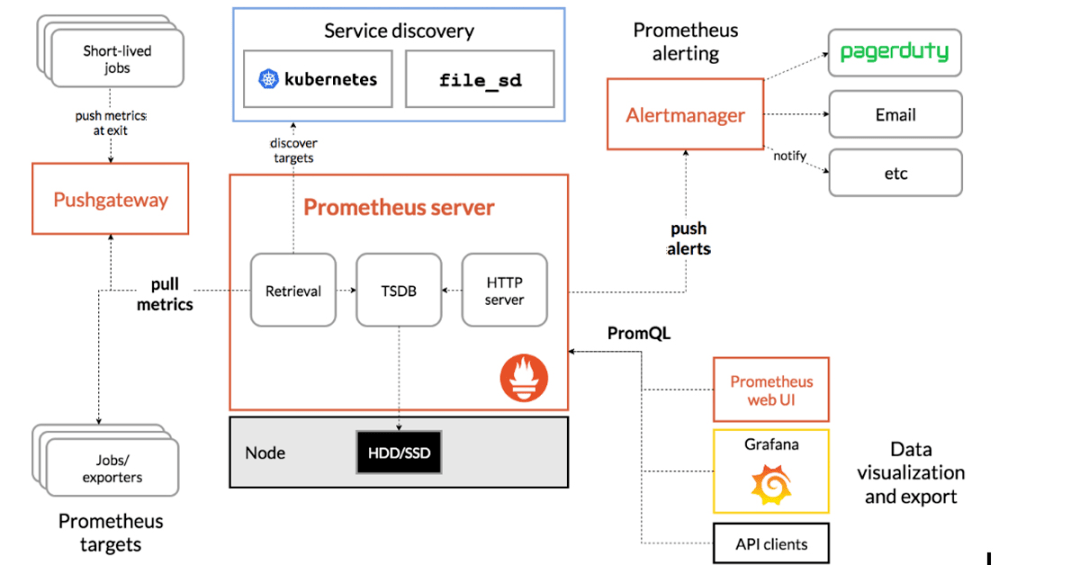
Prometheus的主要組件,包括Prometheus服務器和Alertmanager,整體架構如下圖所示。雖然Prometheus提供了 Web UI,但它通常與Grafana結合使用以實現更靈活的可視化。
2. Grafana
Grafana是一個完全托管的應用程序和基礎設施可視化平臺,可與Prometheus等監控軟件配合使用。Prometheus和Grafana的組合正在成為 devops 團隊用于存儲和可視化時間序列數據的越來越常見的監控堆棧。Prometheus作為存儲后端,Prafana作為分析和可視化的接口。

3. Thanos
Thanos作為度量(Metric)系統,它提供了一種簡單且經濟高效的方式來集中和擴展基于Prometheus的監控系統。
4. Elasticsearch(ES)
Elasticsearch是一個分布式、RESTful風格的搜索和數據分析引擎。它幾乎適用于所有數據類型:數字、文本、地理位置、結構化數據、非結構化數據等。

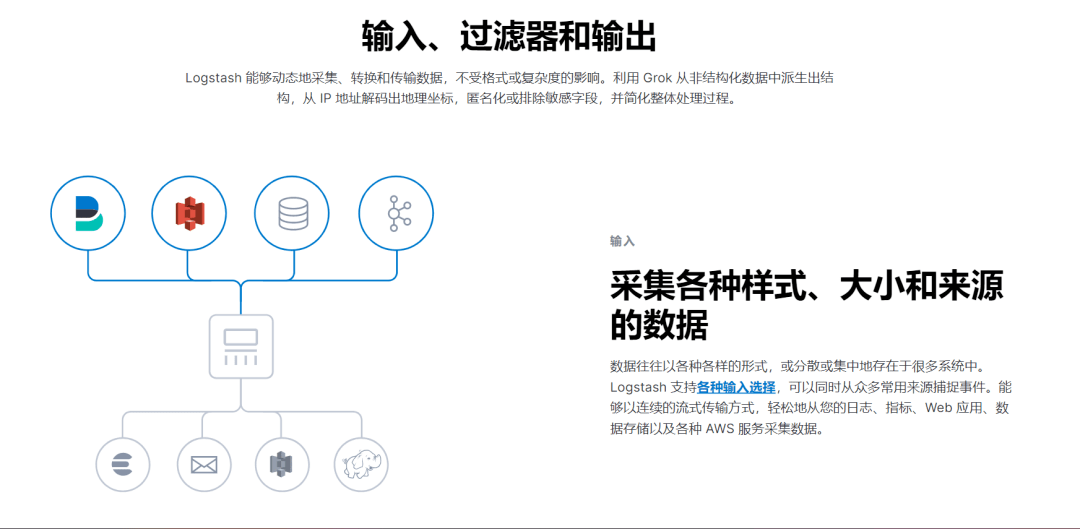
5. Logstash
Logstash是一個開源的服務器端數據處理管道,可同時從多個來源獲取數據,并對其進行轉換,然后將其發送到合適的存儲區。
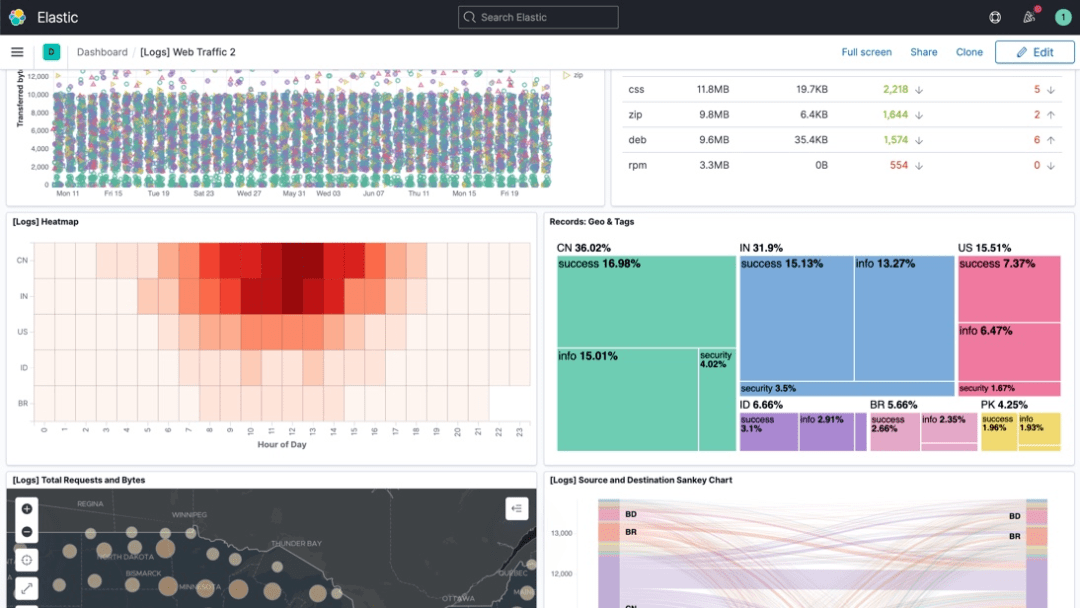
6. Kibana
Kibana提供了 Elasticsearch 數據進行可視化的免費開放的用戶界面,并允許用戶在Elastic Stack中進行導航。它提供了一種數據可視化和探索工具,用于日志和時間序列分析、應用程序監控和運營智能用例。從跟蹤查詢負載,到理解請求在整個應用的運轉,都能有效完成。
許多團隊單獨或組合使用這些監控和日志記錄工具來創建自己的解決方案并解決特定的容器監控和K8s應用程序監控需求。目前市面上比較流行的K8s監控工具組合大體上可以分為兩種:
Prometheus+Grafana,Elasticsearch+Logstash+Kibana。后者通常被稱為ELK堆棧或Elastic Stack,目前這套組合是免費和開源的。
PART 03
注意事項
無論是單獨部署還是組合部署,監控工具的使用都必然會帶來一定的復雜性,尤其當遇到情況復雜的K8s集群時——可能在不同的云環境中運行不同的K8s發行版,難度將陡然增加。
一般來說,需要注意以下幾點:
1. Prometheus單獨配置不適用于大規模場景
由于應用程序載入問題、手動配置門檻較高、配置不同步,大規模的Prometheus配置管理會給開發運維團隊帶來十分艱巨的挑戰。
舉個例子,截至 2019 年底,Uber 的工作負載已增長到 4,000 多個微服務。要管理和操作此類復雜的應用程序,技術團隊需要更加高級的可觀測性,這需要為每個應用程序進行抓取、儀表板和警報的專用配置。而創建這些配置,并將它們應用到每個環境——通常是手動完成,并且每次發生變化時都以臨時方式完成,這對于一家起來說是難以承擔的。
2. Prometheus和Grafana在多集群環境中適用性有限制
雖然Prometheus和Grafana可以很好地協同用于單個集群,但在多集群環境中,用戶可能必須將Thanos添加到用戶的工具集中以聚合數據并提供長期存儲和全局視圖。用戶仍然可能面臨數據保留和HA(高可用性)的限制,導致一些人更喜歡 ELK 堆棧。
基于這種多集群的復雜性,許多公司團隊更喜歡使用 Datadog、Cloudwatch 和 New Relic 等商業解決方案將監控作為服務。
PART 04
寫在最后
K8s對于當下的大規模應用的技術架構的重要性不言而喻。而K8s的可觀測性(監控)工具目前也成為了開發運維團隊繞不過去的一道門檻。不管是Prometheus、Grafana 還是ELK,這些工具在業務中已經得到了不錯的性能驗證,希望本文可以給大家到來一些有益的思考。
參考資料:
https://dzone.com/articles/kube.NETes-monitoring-with-prometheus
https://prometheus.io/docs/





