擊這里在線咨詢客服")
前面我們?cè)u(píng)估了不同大小基因組構(gòu)建索引所需的計(jì)算資源和時(shí)間資源和不同大小數(shù)據(jù)集比對(duì)所需的計(jì)算資源和時(shí)間資源。
下面我們進(jìn)一步看下不同線程數(shù)的影響。
測(cè)試電腦配置
- 這是一個(gè)10核、20線程的處理器,主頻2.8 G HZ,可超頻到5.2 GhZ。
- 在windows系統(tǒng)上安裝了Ubuntu子系統(tǒng)進(jìn)行的測(cè)試。


測(cè)試指定不同線程數(shù)對(duì)速度提升的影響
因?yàn)闇y(cè)試電腦是最多20線程,這里指定1-25共25個(gè)測(cè)試線程,程序如下:
# 10核心 20 線程
for thread in `seq 1 25`; do
i=SRR1039517
mkdir -p ${i}
/usr/bin/time -v -o star.${i}.thread${thread}.log STAR --runMode alignReads
--runThreadN ${thread}
--readFilesIn ${i}_1.fastq.gz ${i}_2.fastq.gz
--readFilesCommand zcat --genomeDir star_GRCh38
--outFileNamePrefix ${i}/${i}. --outFilterType BySJout --outSAMattributes NH HI AS NM MD
--outFilterMultimapNmax 20 --alignSJoverhangMin 8 --alignSJDBoverhangMin 1
--alignIntronMin 20 --alignIntronMax 1000000
--alignMatesGapMax 1000000
--outFilterMatchNminOverLread 0.66 --outFilterScoreMinOverLread 0.66
--winAnchorMultimapNmax 70 --seedSearchStartLmax 45
--outSAMattrIHstart 0 --outSAMstrandField intronMotif
--genomeLoad LoadAndKeep
--outTmpDir /tmp/${i}/
--outSAMtype BAM Unsorted --quantMode GeneCounts
du -s ${i} | awk 'BEGIN{OFS="t"}{print "Output_size: "$1/10^6}' >>star.${i}.thread${thread}.log
done
運(yùn)行完成后,整理所需的計(jì)算資源和時(shí)間資源數(shù)據(jù)。
/bin/rm -f GRCh38_39517_star_reads_map_thread.summary
i=SRR1039517
for thread in `seq 1 25`; do
echo ${thread} |
awk 'BEGIN{OFS="t"}{print "nThreads"; print $1}' |
awk -v outputHeader=${thread} -f ./timeIntegrate2.awk - star.${i}.thread${thread}.log
>>GRCh38_39517_star_reads_map_thread.summary
done
匯總后的數(shù)據(jù)如下:
Time_cost Memory_cost nCPU Output_size nThreads
25.962 28.9048 0.98 5.58423 1
13.98 29.311 1.97 5.58424 2
9.95217 29.5176 2.93 5.58425 3
7.77033 29.7221 3.85 5.58426 4
6.356 29.9266 4.78 5.58428 5
5.1585 30.1311 5.61 5.58422 6
4.69233 30.3356 6.37 5.58426 7
4.51 30.5401 6.69 5.58429 8
4.39683 30.7445 6.94 5.58423 9
4.38017 30.949 6.99 5.58426 10
4.41233 31.1535 6.99 5.58424 11
4.45333 31.358 6.94 5.58424 12
4.41033 31.5624 6.95 5.58429 13
4.44267 31.7669 6.88 5.58428 14
4.4595 31.9714 6.87 5.58426 15
4.50567 32.0859 6.85 5.58424 16
4.458 32.2639 6.92 5.58429 17
4.46417 32.4802 6.86 5.58428 18
4.497 32.6487 6.91 5.58425 19
4.4425 32.8489 6.95 5.58426 20
4.46817 32.9927 6.92 5.5843 21
4.4555 33.1738 6.97 5.58426 22
4.45483 33.3675 6.94 5.58426 23
4.46133 33.5499 6.99 5.58428 24
4.42733 33.7143 6.99 5.58426 25
STAR比對(duì)的時(shí)間隨指定的線程數(shù)的變化
- 在給定的線程數(shù)少于10個(gè)時(shí),隨著線程數(shù)增加時(shí)間逐漸減少,尤其是在線程數(shù)從1-6的過程中,下降幅度更明顯。
- 線程也不是越多越好,給定多于10個(gè)進(jìn)程對(duì)速度提升基本沒有貢獻(xiàn)。
- (因?yàn)闇y(cè)試電腦只有10個(gè)核心,不知道這里的節(jié)點(diǎn)10是否是受此影響;
- 還需要后續(xù)在服務(wù)器更多測(cè)試來判斷;
- 如果是這樣,對(duì)我們的指導(dǎo)是設(shè)定的線程數(shù)不應(yīng)該超過CPU的核心數(shù)。
- )

library(ImageGP) 、sp_scatterplot(“GRCh38_39517_star_reads_map_thread.summary”, melted = T, xvariable = “nThreads”, yvariable = “Time_cost”, smooth_method = “auto”, x_label =”Number of specified threads”, y_label = “Running time (minutes)”) + scale_x_continuous(breaks=seq(1,25, by=1)) + scale_y_continuous(breaks=seq(1,25, by=1))
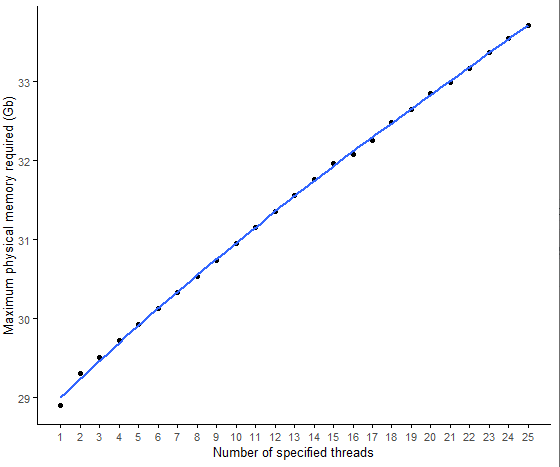
STAR比對(duì)所需內(nèi)存隨指定的線程數(shù)的變化
- 線程數(shù)越多,內(nèi)存需求越大;
- 但整體相差不大。
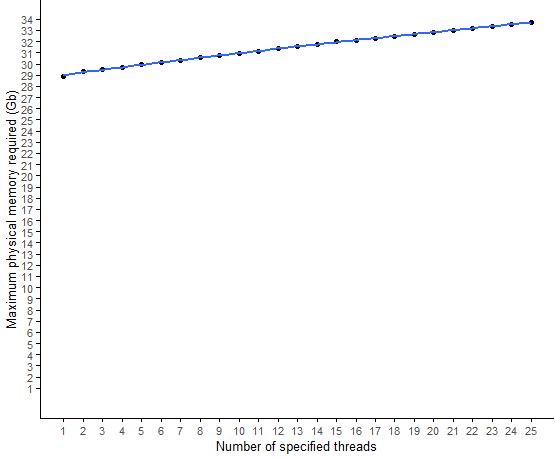
# 這時(shí)繪圖要注意,是否加limits=c(0,34)圖給人的第一印象不同。
sp_scatterplot("GRCh38_39517_star_reads_map_thread.summary", melted = T, xvariable = "nThreads",
yvariable = "Memory_cost", smooth_method = "auto",
x_label ="Number of specified threads", y_label = "Maximum physical memory required (Gb)") +
scale_x_continuous(breaks=seq(1,25, by=1)) +
scale_y_continuous(breaks=seq(1,34, by=1),limits=c(0,34))
不加limits=c(0,34)的效果。是不是感覺內(nèi)存變化很大???
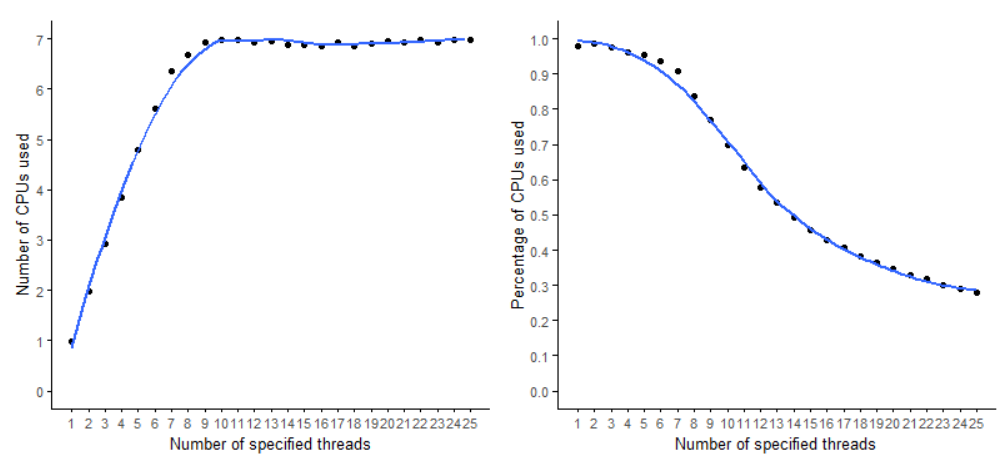
STAR比對(duì)過程中CPU利用率隨指定的線程數(shù)的變化
多線程的效率一般很難達(dá)到100%。如下圖,在指定線程數(shù)小于10時(shí),給定的線程越多,利用起來的線程也越多,但整體利用率是越來越低的。
不同線程是不影響程序輸出的
這個(gè)統(tǒng)計(jì)沒什么意義。

sp_scatterplot("GRCh38_39517_star_reads_map_thread.summary", melted = T, xvariable = "nThreads",
yvariable = "Output_size", smooth_method = "auto",
x_label ="Number of specified threads", y_label = "Disk space usages (Gb)") +
scale_x_continuous(breaks=seq(1,25, by=1)) +
scale_y_continuous(breaks=seq(0,6, by=1),limits=c(0,6))





