擊這里在線咨詢客服")
作者:mosun,騰訊 PCG 后臺(tái)開發(fā)工程師
一、虛擬內(nèi)存 1.1 虛擬內(nèi)存引入
我們知道計(jì)算機(jī)由 CPU、存儲(chǔ)器、輸入/輸出設(shè)備三大核心部分組成,如下:
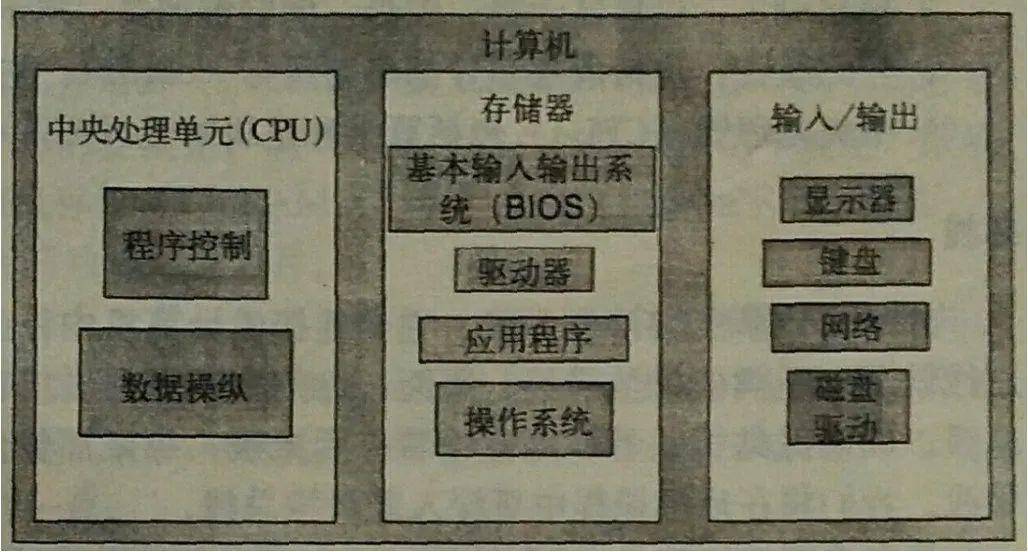
CPU 運(yùn)行速度很快,在完全理想的狀態(tài)下,存儲(chǔ)器應(yīng)該要同時(shí)具備以下三種特性:
- 速度足夠快:這樣 CPU 的效率才不會(huì)受限于存儲(chǔ)器;
- 容量足夠大:容量能夠存儲(chǔ)計(jì)算機(jī)所需的全部數(shù)據(jù);
- 價(jià)格足夠便宜:價(jià)格低廉,所有類型的計(jì)算機(jī)都能配備;
然而,出于成本考慮,當(dāng)前計(jì)算機(jī)體系中,存儲(chǔ)都是采用分層設(shè)計(jì)的,常見層次如下:
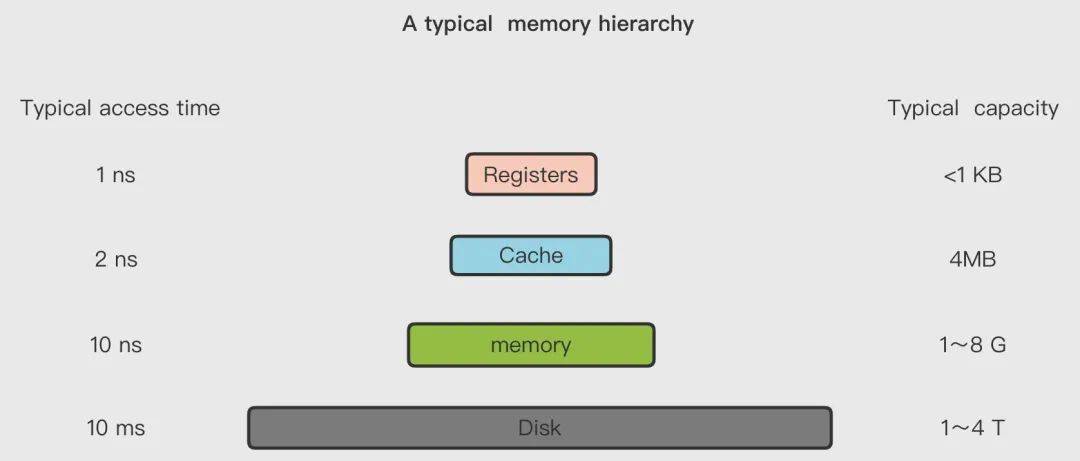
上圖分別為寄存器、高速緩存、主存和磁盤,它們的速度逐級遞減、成本逐級遞減,在計(jì)算機(jī)中的容量逐級遞增。通常我們所說的物理內(nèi)存即上文中的主存,常作為操作系統(tǒng)或其他正在運(yùn)行中的程序的臨時(shí)資料存儲(chǔ)介質(zhì)。在嵌入式以及一些老的操作系統(tǒng)中,系統(tǒng)直接通過物理尋址方式和主存打交道。然而,隨著科技發(fā)展,遇到如下窘境:
- 一臺(tái)機(jī)器可能同時(shí)運(yùn)行多臺(tái)大型應(yīng)用程序;
- 每個(gè)應(yīng)用程序都需要在主存存儲(chǔ)大量臨時(shí)數(shù)據(jù);
- 早期,單個(gè) CPU 尋址能力 2^32,導(dǎo)致內(nèi)存最大 4G;
主存成了計(jì)算機(jī)系統(tǒng)的瓶頸。此時(shí),科學(xué)家提出了一個(gè)概念:虛擬內(nèi)存。
以 32 位操作系統(tǒng)為例,虛擬內(nèi)存的引入,使得操作系統(tǒng)可以為每個(gè)進(jìn)程分配大小為 4GB 的虛擬內(nèi)存空間,而實(shí)際上物理內(nèi)存在需要時(shí)才會(huì)被加載,有效解決了物理內(nèi)存有限空間帶來的瓶頸。在虛擬內(nèi)存到物理內(nèi)存轉(zhuǎn)換的過程中,有很重要的一步就是進(jìn)行地址翻譯,下面介紹。
1.2 地址翻譯
進(jìn)程在運(yùn)行期間產(chǎn)生的內(nèi)存地址都是虛擬地址,如果計(jì)算機(jī)沒有引入虛擬內(nèi)存這種存儲(chǔ)器抽象技術(shù)的話,則 CPU 會(huì)把這些地址直接發(fā)送到內(nèi)存地址總線上,然后訪問和虛擬地址相同值的物理地址;如果使用虛擬內(nèi)存技術(shù)的話,CPU 則是把這些虛擬地址通過地址總線送到內(nèi)存管理單元(Memory Management Unit,簡稱 MMU),MMU 將虛擬地址翻譯成物理地址之后再通過內(nèi)存總線去訪問物理內(nèi)存:
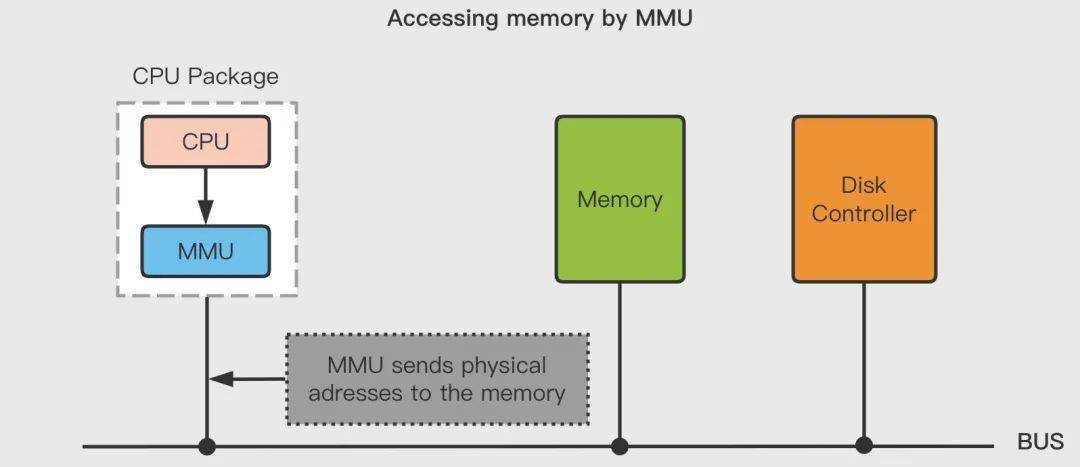
虛擬地址(比如 16 位地址 8196=0010 000000000100)分為兩部分:虛擬頁號(hào)(Virtual Page Number,簡稱 VPN,這里是高 4 位部分)和偏移量(Virtual Page Offset,簡稱 VPO,這里是低 12 位部分),虛擬地址轉(zhuǎn)換成物理地址是通過頁表(page table)來實(shí)現(xiàn)的。頁表由多個(gè)頁表項(xiàng)(Page Table Entry, 簡稱 PTE)組成,一般頁表項(xiàng)中都會(huì)存儲(chǔ)物理頁框號(hào)、修改位、訪問位、保護(hù)位和 "在/不在" 位(有效位)等信息。
這里我們基于一個(gè)例子來分析當(dāng)分析當(dāng)頁面命中時(shí),計(jì)算機(jī)各個(gè)硬件是如何交互的:
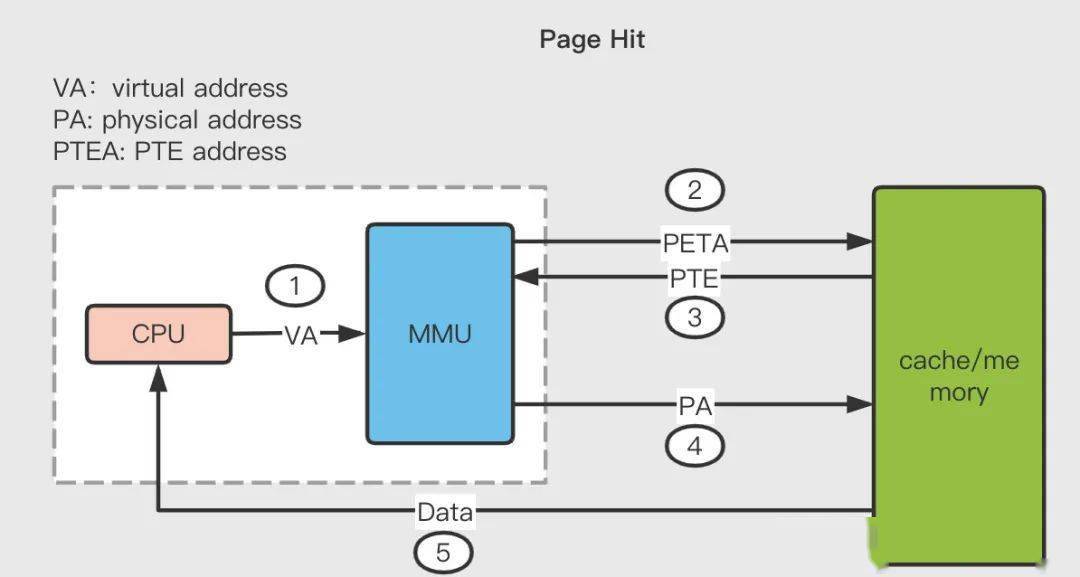
- 第 1 步:處理器生成一個(gè)虛擬地址 VA,通過總線發(fā)送到 MMU;
- 第 2 步:MMU 通過虛擬頁號(hào)得到頁表項(xiàng)的地址 PTEA,通過內(nèi)存總線從 CPU 高速緩存/主存讀取這個(gè)頁表項(xiàng) PTE;
- 第 3 步:CPU 高速緩存或者主存通過內(nèi)存總線向 MMU 返回頁表項(xiàng) PTE;
- 第 4 步:MMU 先把頁表項(xiàng)中的物理頁框號(hào) PPN 復(fù)制到寄存器的高三位中,接著把 12 位的偏移量 VPO 復(fù)制到寄存器的末 12 位構(gòu)成 15 位的物理地址,即可以把該寄存器存儲(chǔ)的物理內(nèi)存地址 PA 發(fā)送到內(nèi)存總線,訪問高速緩存/主存;
- 第 5 步:CPU 高速緩存/主存返回該物理地址對應(yīng)的數(shù)據(jù)給處理器。
在 MMU 進(jìn)行地址轉(zhuǎn)換時(shí),如果頁表項(xiàng)的有效位是 0,則表示該頁面并沒有映射到真實(shí)的物理頁框號(hào) PPN,則會(huì)引發(fā)一個(gè)缺頁中斷,CPU 陷入操作系統(tǒng)內(nèi)核,接著操作系統(tǒng)就會(huì)通過頁面置換算法選擇一個(gè)頁面將其換出 (swap),以便為即將調(diào)入的新頁面騰出位置,如果要換出的頁面的頁表項(xiàng)里的修改位已經(jīng)被設(shè)置過,也就是被更新過,則這是一個(gè)臟頁 (Dirty Page),需要寫回磁盤更新該頁面在磁盤上的副本,如果該頁面是"干凈"的,也就是沒有被修改過,則直接用調(diào)入的新頁面覆蓋掉被換出的舊頁面即可。缺頁中斷的具體流程如下:
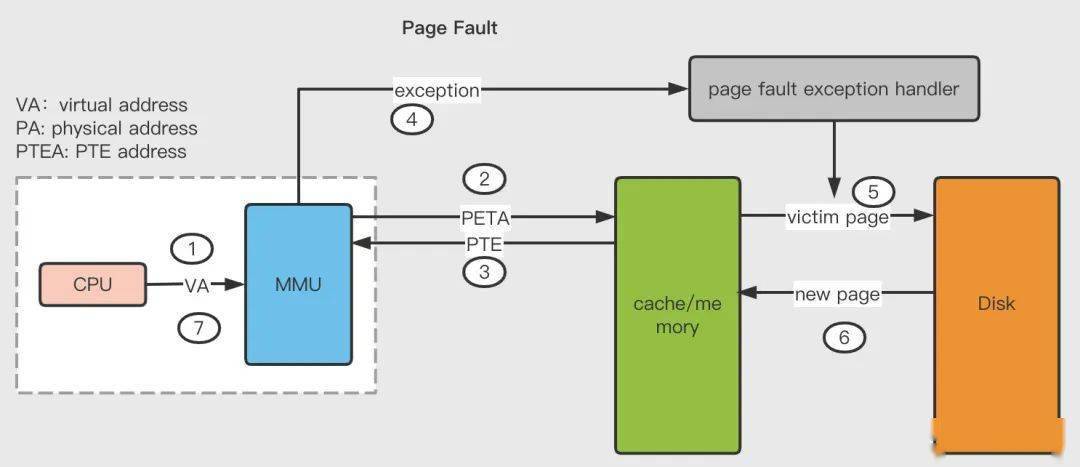
- 第 1 步到第 3 步:和前面的頁面命中的前 3 步是一致的;
- 第 4 步:檢查返回的頁表項(xiàng) PTE 發(fā)現(xiàn)其有效位是 0,則 MMU 觸發(fā)一次缺頁中斷異常,然后 CPU 轉(zhuǎn)入到操作系統(tǒng)內(nèi)核中的缺頁中斷處理器;
- 第 5 步:缺頁中斷處理程序檢查所需的虛擬地址是否合法,確認(rèn)合法后系統(tǒng)則檢查是否有空閑物理頁框號(hào) PPN 可以映射給該缺失的虛擬頁面,如果沒有空閑頁框,則執(zhí)行頁面置換算法尋找一個(gè)現(xiàn)有的虛擬頁面淘汰,如果該頁面已經(jīng)被修改過,則寫回磁盤,更新該頁面在磁盤上的副本;
- 第 6 步:缺頁中斷處理程序從磁盤調(diào)入新的頁面到內(nèi)存,更新頁表項(xiàng) PTE;
- 第 7 步:缺頁中斷程序返回到原先的進(jìn)程,重新執(zhí)行引起缺頁中斷的指令,CPU 將引起缺頁中斷的虛擬地址重新發(fā)送給 MMU,此時(shí)該虛擬地址已經(jīng)有了映射的物理頁框號(hào) PPN,因此會(huì)按照前面『Page Hit』的流程走一遍,最后主存把請求的數(shù)據(jù)返回給處理器。
前面在分析虛擬內(nèi)存的工作原理之時(shí),談到頁表的存儲(chǔ)位置,為了簡化處理,都是默認(rèn)把主存和高速緩存放在一起,而實(shí)際上更詳細(xì)的流程應(yīng)該是如下的原理圖:
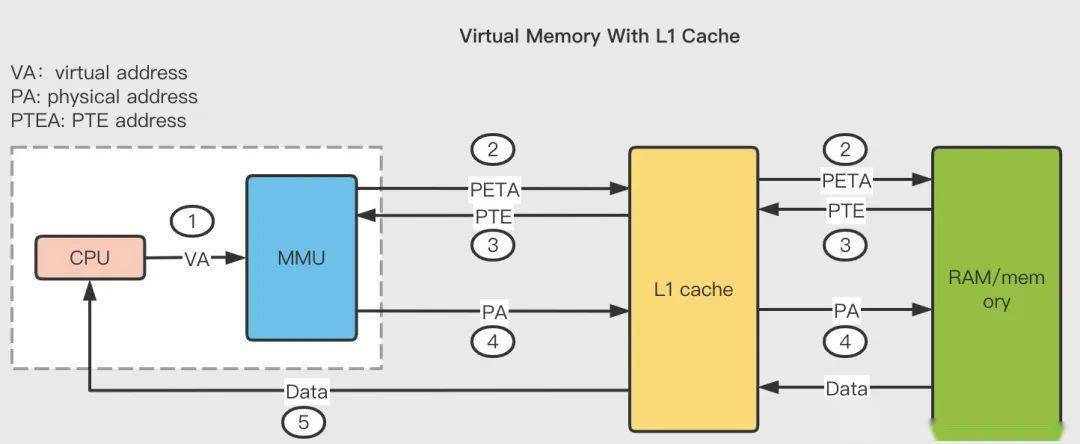
如果一臺(tái)計(jì)算機(jī)同時(shí)配備了虛擬內(nèi)存技術(shù)和 CPU 高速緩存,那么 MMU 每次都會(huì)優(yōu)先嘗試到高速緩存中進(jìn)行尋址,如果緩存命中則會(huì)直接返回,只有當(dāng)緩存不命中之后才去主存尋址。
通常來說,大多數(shù)系統(tǒng)都會(huì)選擇利用物理內(nèi)存地址去訪問高速緩存,因?yàn)楦咚倬彺嫦啾扔谥鞔嬉〉枚啵允褂梦锢韺ぶ芬膊粫?huì)太復(fù)雜;另外也因?yàn)楦咚倬彺嫒萘亢苄。韵到y(tǒng)需要盡量在多個(gè)進(jìn)程之間共享數(shù)據(jù)塊,而使用物理地址能夠使得多進(jìn)程同時(shí)在高速緩存中存儲(chǔ)數(shù)據(jù)塊以及共享來自相同虛擬內(nèi)存頁的數(shù)據(jù)塊變得更加直觀。
1.2.2 加速翻譯&優(yōu)化頁表
虛擬內(nèi)存這項(xiàng)技術(shù)能不能真正地廣泛應(yīng)用到計(jì)算機(jī)中,還需要解決如下兩個(gè)問題:
- 虛擬地址到物理地址的映射過程必須要非常快,地址翻譯如何加速。
- 虛擬地址范圍的增大必然會(huì)導(dǎo)致頁表的膨脹,形成大頁表。
"計(jì)算機(jī)科學(xué)領(lǐng)域的任何問題都可以通過增加一個(gè)間接的中間層來解決"。雖然虛擬內(nèi)存本身就已經(jīng)是一個(gè)中間層了,但是中間層里的問題同樣可以通過再引入一個(gè)中間層來解決。加速地址翻譯過程的方案目前是通過引入頁表緩存模塊 -- TLB,而大頁表則是通過實(shí)現(xiàn)多級頁表或倒排頁表來解決。
1.2.2.1 TLB 加速
翻譯后備緩沖器(Translation Lookaside Buffer,TLB),也叫快表,是用來加速虛擬地址翻譯的,因?yàn)樘摂M內(nèi)存的分頁機(jī)制,頁表一般是保存在內(nèi)存中的一塊固定的存儲(chǔ)區(qū),而 MMU 每次翻譯虛擬地址的時(shí)候都需要從頁表中匹配一個(gè)對應(yīng)的 PTE,導(dǎo)致進(jìn)程通過 MMU 訪問指定內(nèi)存數(shù)據(jù)的時(shí)候比沒有分頁機(jī)制的系統(tǒng)多了一次內(nèi)存訪問,一般會(huì)多耗費(fèi)幾十到幾百個(gè) CPU 時(shí)鐘周期,性能至少下降一半,如果 PTE 碰巧緩存在 CPU L1 高速緩存中,則開銷可以降低到一兩個(gè)周期,但是我們不能寄希望于每次要匹配的 PTE 都剛好在 L1 中,因此需要引入加速機(jī)制,即 TLB 快表。
TLB 可以簡單地理解成頁表的高速緩存,保存了最高頻被訪問的頁表項(xiàng) PTE。由于 TLB 一般是硬件實(shí)現(xiàn)的,因此速度極快,MMU 收到虛擬地址時(shí)一般會(huì)先通過硬件 TLB 并行地在頁表中匹配對應(yīng)的 PTE,若命中且該 PTE 的訪問操作不違反保護(hù)位(比如嘗試寫一個(gè)只讀的內(nèi)存地址),則直接從 TLB 取出對應(yīng)的物理頁框號(hào) PPN 返回,若不命中則會(huì)穿透到主存頁表里查詢,并且會(huì)在查詢到最新頁表項(xiàng)之后存入 TLB,以備下次緩存命中,如果 TLB 當(dāng)前的存儲(chǔ)空間不足則會(huì)替換掉現(xiàn)有的其中一個(gè) PTE。
下面來具體分析一下 TLB 命中和不命中。
TLB 命中:
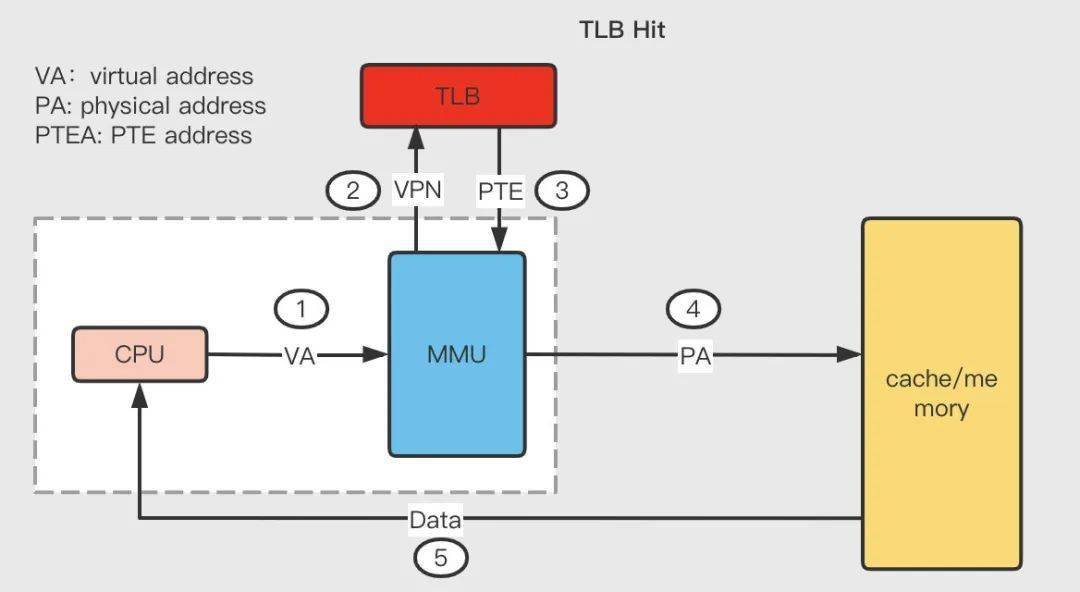
- 第 1 步:CPU 產(chǎn)生一個(gè)虛擬地址 VA;
- 第 2 步和第 3 步:MMU 從 TLB 中取出對應(yīng)的 PTE;
- 第 4 步:MMU 將這個(gè)虛擬地址 VA 翻譯成一個(gè)真實(shí)的物理地址 PA,通過地址總線發(fā)送到高速緩存/主存中去;
- 第 5 步:高速緩存/主存將物理地址 PA 上的數(shù)據(jù)返回給 CPU。
TLB 不命中:
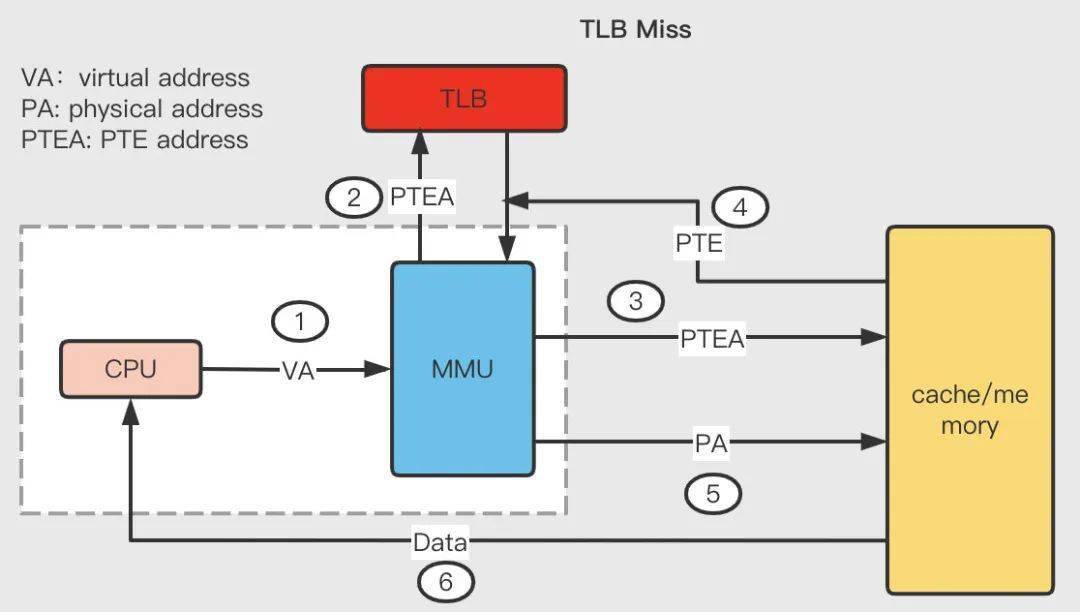
- 第 1 步:CPU 產(chǎn)生一個(gè)虛擬地址 VA;
- 第 2 步至第 4 步:查詢 TLB 失敗,走正常的主存頁表查詢流程拿到 PTE,然后把它放入 TLB 緩存,以備下次查詢,如果 TLB 此時(shí)的存儲(chǔ)空間不足,則這個(gè)操作會(huì)汰換掉 TLB 中另一個(gè)已存在的 PTE;
- 第 5 步:MMU 將這個(gè)虛擬地址 VA 翻譯成一個(gè)真實(shí)的物理地址 PA,通過地址總線發(fā)送到高速緩存/主存中去;
- 第 6 步:高速緩存/主存將物理地址 PA 上的數(shù)據(jù)返回給 CPU。
TLB 的引入可以一定程度上解決虛擬地址到物理地址翻譯的開銷問題,接下來還需要解決另一個(gè)問題:大頁表。理論上一臺(tái) 32 位的計(jì)算機(jī)的尋址空間是 4GB,也就是說每一個(gè)運(yùn)行在該計(jì)算機(jī)上的進(jìn)程理論上的虛擬尋址范圍是 4GB。到目前為止,我們一直在討論的都是單頁表的情形,如果每一個(gè)進(jìn)程都把理論上可用的內(nèi)存頁都裝載進(jìn)一個(gè)頁表里,但是實(shí)際上進(jìn)程會(huì)真正使用到的內(nèi)存其實(shí)可能只有很小的一部分,而我們也知道頁表也是保存在計(jì)算機(jī)主存中的,那么勢必會(huì)造成大量的內(nèi)存浪費(fèi),甚至有可能導(dǎo)致計(jì)算機(jī)物理內(nèi)存不足從而無法并行地運(yùn)行更多進(jìn)程。
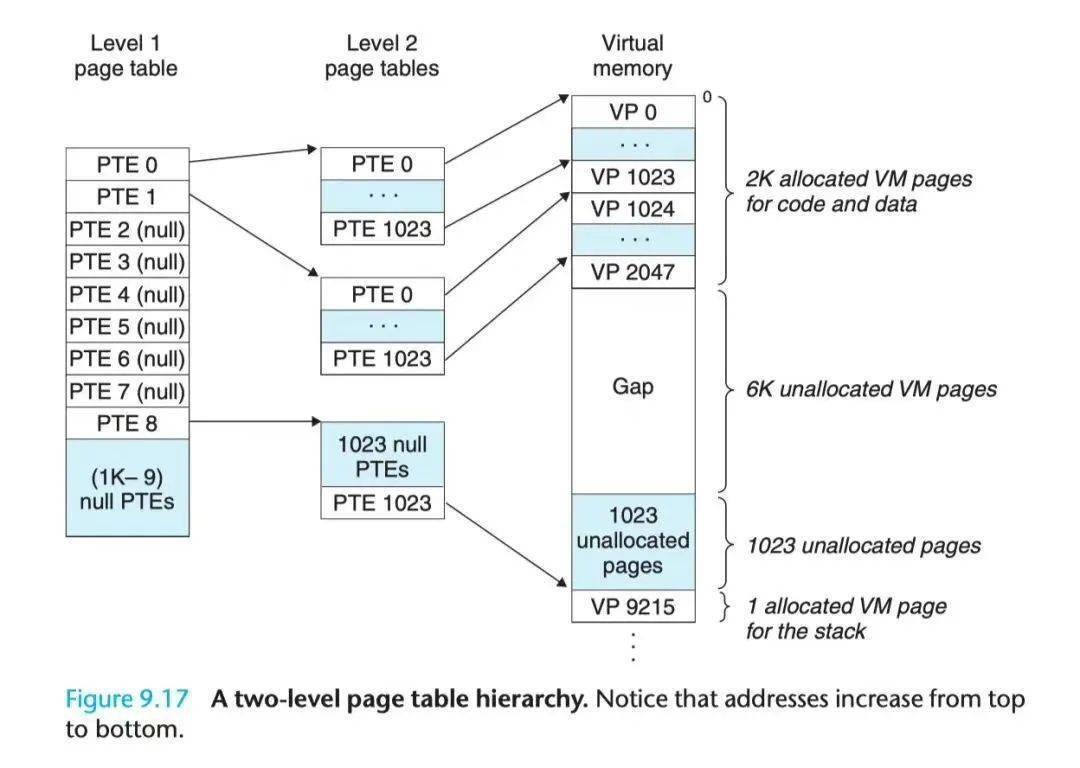
這個(gè)問題一般通過多級頁表(Multi-Level Page Tables)來解決,通過把一個(gè)大頁表進(jìn)行拆分,形成多級的頁表,我們具體來看一個(gè)二級頁表應(yīng)該如何設(shè)計(jì):假定一個(gè)虛擬地址是 32 位,由 10 位的一級頁表索引、10 位的二級頁表索引以及 12 位的地址偏移量,則 PTE 是 4 字節(jié),頁面 page 大小是 2^12 = 4KB,總共需要 2^20 個(gè) PTE,一級頁表中的每個(gè) PTE 負(fù)責(zé)映射虛擬地址空間中的一個(gè) 4MB 的 chunk,每一個(gè) chunk 都由 1024 個(gè)連續(xù)的頁面 Page 組成,如果尋址空間是 4GB,那么一共只需要 1024 個(gè) PTE 就足夠覆蓋整個(gè)進(jìn)程地址空間。二級頁表中的每一個(gè) PTE 都負(fù)責(zé)映射到一個(gè) 4KB 的虛擬內(nèi)存頁面,和單頁表的原理是一樣的。
多級頁表的關(guān)鍵在于,我們并不需要為一級頁表中的每一個(gè) PTE 都分配一個(gè)二級頁表,而只需要為進(jìn)程當(dāng)前使用到的地址做相應(yīng)的分配和映射。因此,對于大部分進(jìn)程來說,它們的一級頁表中有大量空置的 PTE,那么這部分 PTE 對應(yīng)的二級頁表也將無需存在,這是一個(gè)相當(dāng)可觀的內(nèi)存節(jié)約,事實(shí)上對于一個(gè)典型的程序來說,理論上的 4GB 可用虛擬內(nèi)存地址空間絕大部分都會(huì)處于這樣一種未分配的狀態(tài);更進(jìn)一步,在程序運(yùn)行過程中,只需要把一級頁表放在主存中,虛擬內(nèi)存系統(tǒng)可以在實(shí)際需要的時(shí)候才去創(chuàng)建、調(diào)入和調(diào)出二級頁表,這樣就可以確保只有那些最頻繁被使用的二級頁表才會(huì)常駐在主存中,此舉亦極大地緩解了主存的壓力。
二、 內(nèi)核空間 & 用戶空間
對 32 位操作系統(tǒng)而言,它的尋址空間(虛擬地址空間,或叫線性地址空間)為 4G(2 的 32 次方)。也就是說一個(gè)進(jìn)程的最大地址空間為 4G。操作系統(tǒng)的核心是內(nèi)核(kernel),它獨(dú)立于普通的應(yīng)用程序,可以訪問受保護(hù)的內(nèi)存空間,也有訪問底層硬件設(shè)備的所有權(quán)限。為了保證內(nèi)核的安全,現(xiàn)在的操作系統(tǒng)一般都強(qiáng)制用戶進(jìn)程不能直接操作內(nèi)核。具體的實(shí)現(xiàn)方式基本都是由操作系統(tǒng)將虛擬地址空間劃分為兩部分,一部分為內(nèi)核空間,另一部分為用戶空間。針對 linux 操作系統(tǒng)而言,最高的 1G 字節(jié)(從虛擬地址 0xC0000000 到 0xFFFFFFFF)由內(nèi)核使用,稱為內(nèi)核空間。而較低的 3G 字節(jié)(從虛擬地址 0x00000000 到 0xBFFFFFFF)由各個(gè)進(jìn)程使用,稱為用戶空間。
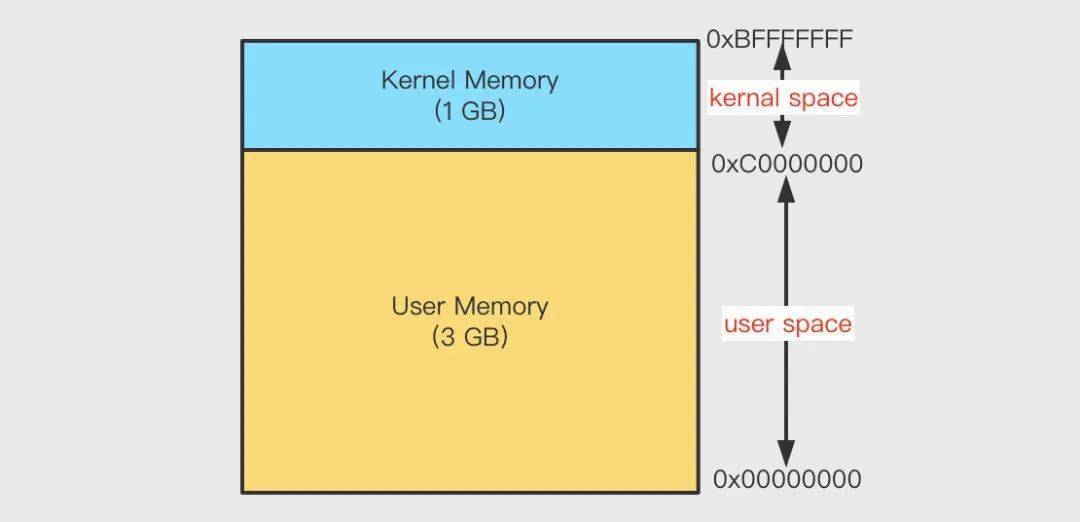
為什么需要區(qū)分內(nèi)核空間與用戶空間?在 CPU 的所有指令中,有些指令是非常危險(xiǎn)的,如果錯(cuò)用,將導(dǎo)致系統(tǒng)崩潰,比如清內(nèi)存、設(shè)置時(shí)鐘等。如果允許所有的程序都可以使用這些指令,那么系統(tǒng)崩潰的概率將大大增加。所以,CPU 將指令分為特權(quán)指令和非特權(quán)指令,對于那些危險(xiǎn)的指令,只允許操作系統(tǒng)及其相關(guān)模塊使用,普通應(yīng)用程序只能使用那些不會(huì)造成災(zāi)難的指令。區(qū)分內(nèi)核空間和用戶空間本質(zhì)上是要提高操作系統(tǒng)的穩(wěn)定性及可用性。
2.1 內(nèi)核態(tài)與用戶態(tài)
當(dāng)進(jìn)程運(yùn)行在內(nèi)核空間時(shí)就處于內(nèi)核態(tài),而進(jìn)程運(yùn)行在用戶空間時(shí)則處于用戶態(tài)。
在內(nèi)核態(tài)下,進(jìn)程運(yùn)行在內(nèi)核地址空間中,此時(shí) CPU 可以執(zhí)行任何指令。運(yùn)行的代碼也不受任何的限制,可以自由地訪問任何有效地址,也可以直接進(jìn)行端口的訪問。
在用戶態(tài)下,進(jìn)程運(yùn)行在用戶地址空間中,被執(zhí)行的代碼要受到 CPU 的諸多檢查,它們只能訪問映射其地址空間的頁表項(xiàng)中規(guī)定的在用戶態(tài)下可訪問頁面的虛擬地址,且只能對任務(wù)狀態(tài)段(TSS)中 I/O 許可位圖(I/O Permission Bitmap)中規(guī)定的可訪問端口進(jìn)行直接訪問。
對于以前的 DOS 操作系統(tǒng)來說,是沒有內(nèi)核空間、用戶空間以及內(nèi)核態(tài)、用戶態(tài)這些概念的。可以認(rèn)為所有的代碼都是運(yùn)行在內(nèi)核態(tài)的,因而用戶編寫的應(yīng)用程序代碼可以很容易的讓操作系統(tǒng)崩潰掉。
對于 Linux 來說,通過區(qū)分內(nèi)核空間和用戶空間的設(shè)計(jì),隔離了操作系統(tǒng)代碼(操作系統(tǒng)的代碼要比應(yīng)用程序的代碼健壯很多)與應(yīng)用程序代碼。即便是單個(gè)應(yīng)用程序出現(xiàn)錯(cuò)誤也不會(huì)影響到操作系統(tǒng)的穩(wěn)定性,這樣其它的程序還可以正常的運(yùn)行。
如何從用戶空間進(jìn)入內(nèi)核空間?
其實(shí)所有的系統(tǒng)資源管理都是在內(nèi)核空間中完成的。比如讀寫磁盤文件,分配回收內(nèi)存,從網(wǎng)絡(luò)接口讀寫數(shù)據(jù)等等。我們的應(yīng)用程序是無法直接進(jìn)行這樣的操作的。但是我們可以通過內(nèi)核提供的接口來完成這樣的任務(wù)。比如應(yīng)用程序要讀取磁盤上的一個(gè)文件,它可以向內(nèi)核發(fā)起一個(gè) “系統(tǒng)調(diào)用” 告訴內(nèi)核:“我要讀取磁盤上的某某文件”。
其實(shí)就是通過一個(gè)特殊的指令讓進(jìn)程從用戶態(tài)進(jìn)入到內(nèi)核態(tài)(到了內(nèi)核空間),在內(nèi)核空間中,CPU 可以執(zhí)行任何的指令,當(dāng)然也包括從磁盤上讀取數(shù)據(jù)。具體過程是先把數(shù)據(jù)讀取到內(nèi)核空間中,然后再把數(shù)據(jù)拷貝到用戶空間并從內(nèi)核態(tài)切換到用戶態(tài)。此時(shí)應(yīng)用程序已經(jīng)從系統(tǒng)調(diào)用中返回并且拿到了想要的數(shù)據(jù),可以開開心心的往下執(zhí)行了。簡單說就是應(yīng)用程序把高科技的事情(從磁盤讀取文件)外包給了系統(tǒng)內(nèi)核,系統(tǒng)內(nèi)核做這些事情既專業(yè)又高效。
三、 IO
在進(jìn)行 IO 操作時(shí),通常需要經(jīng)過如下兩個(gè)階段:
- 數(shù)據(jù)準(zhǔn)備階段:數(shù)據(jù)從硬件到內(nèi)核空間
- 數(shù)據(jù)拷貝階段:數(shù)據(jù)從內(nèi)核空間到用戶空間
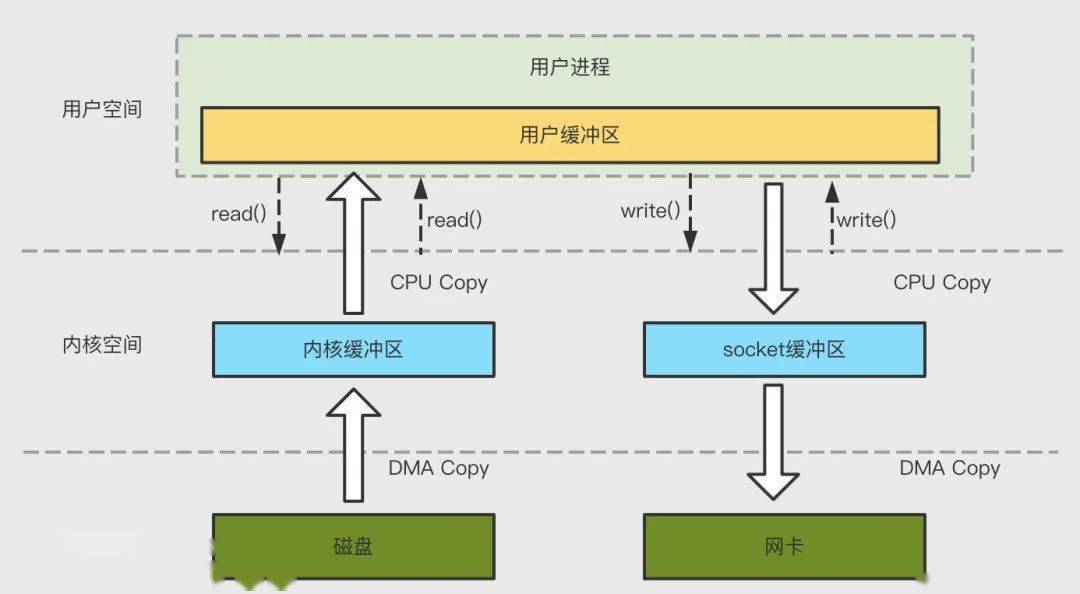
通常我們所說的 IO 的阻塞/非阻塞以及同步/異步,和這兩個(gè)階段關(guān)系密切:
- 阻塞 IO 和非阻塞 IO 判定標(biāo)準(zhǔn):數(shù)據(jù)準(zhǔn)備階段,應(yīng)用程序是否阻塞等待操作系統(tǒng)將數(shù)據(jù)從硬件加載到內(nèi)核空間;
- 同步 IO 和異步 IO 判定標(biāo)準(zhǔn):數(shù)據(jù)拷貝階段,數(shù)據(jù)是否備好后直接通知應(yīng)用程序使用,無需等待拷貝;
阻塞 IO :當(dāng)用戶發(fā)生了系統(tǒng)調(diào)用后,如果數(shù)據(jù)未從網(wǎng)卡到達(dá)內(nèi)核態(tài),內(nèi)核態(tài)數(shù)據(jù)未準(zhǔn)備好,此時(shí)會(huì)一直阻塞。直到數(shù)據(jù)就緒,然后從內(nèi)核態(tài)拷貝到用戶態(tài)再返回。
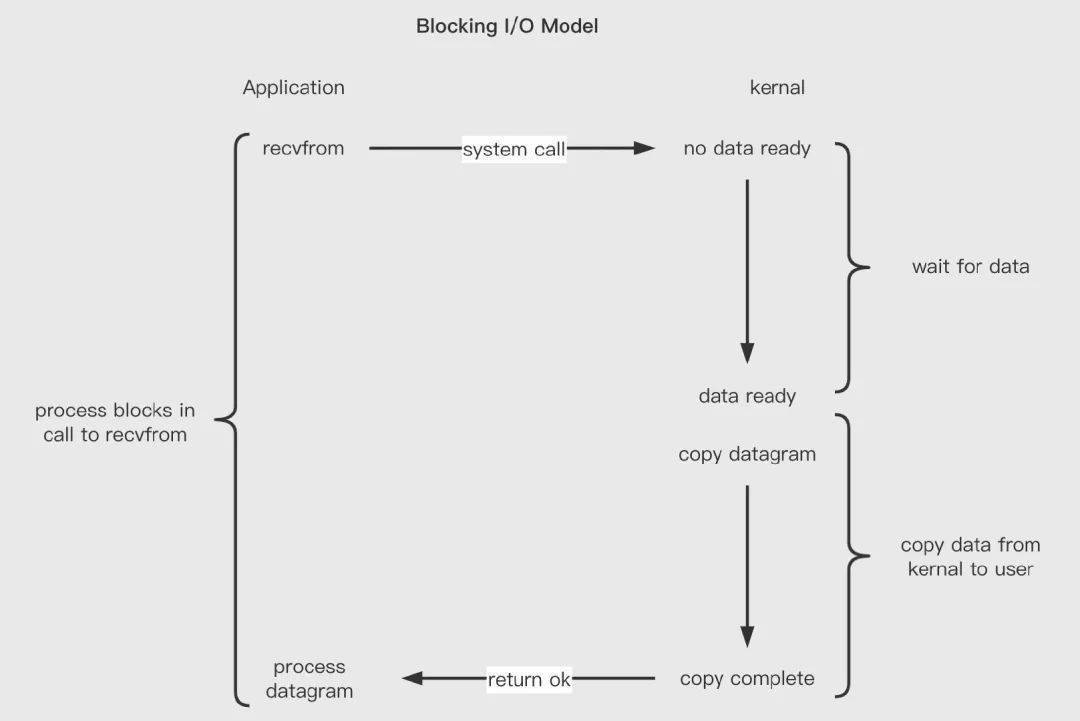
阻塞 IO 每個(gè)連接一個(gè)單獨(dú)的線程進(jìn)行處理,通常搭配多線程來應(yīng)對大流量,但是,開辟線程的開銷比較大,一個(gè)程序可以開辟的線程是有限的,面對百萬連接的情況,是無法處理。非阻塞 IO 可以一定程度上解決上述問題。
3.2 (同步)非阻塞 IO
非阻塞 IO :在第一階段(網(wǎng)卡-內(nèi)核態(tài))數(shù)據(jù)未到達(dá)時(shí)不等待,然后直接返回。數(shù)據(jù)就緒后,從內(nèi)核態(tài)拷貝到用戶態(tài)再返回。
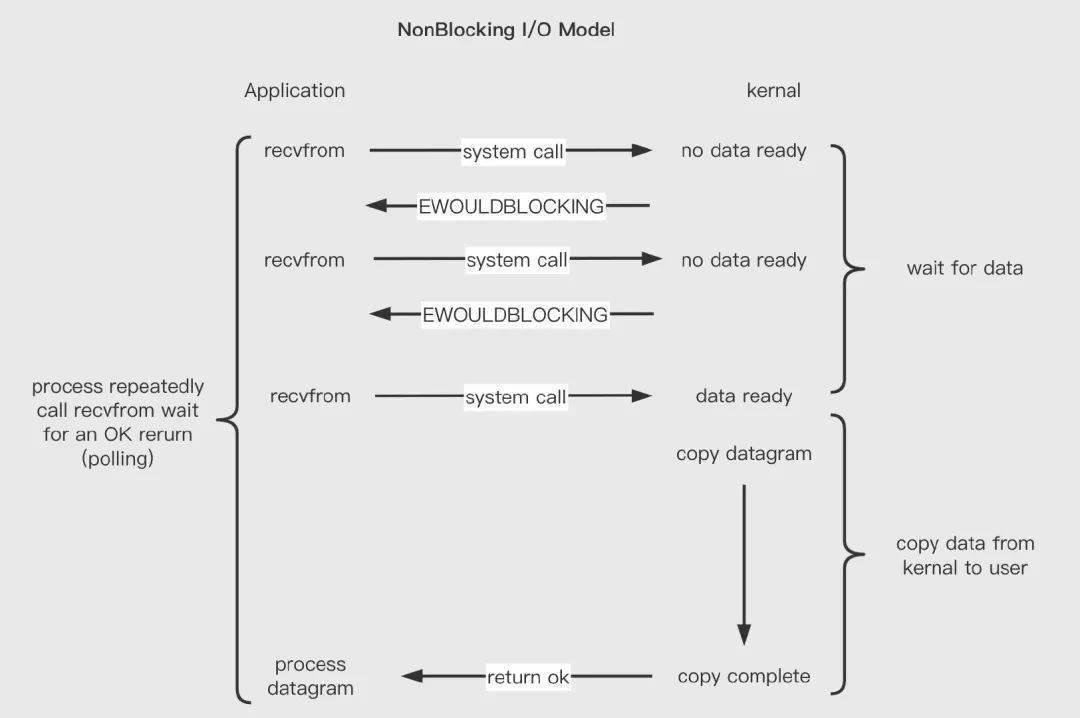
非阻塞 IO 解決了阻塞 IO每個(gè)連接一個(gè)線程處理的問題,所以其最大的優(yōu)點(diǎn)就是 一個(gè)線程可以處理多個(gè)連接。然而,非阻塞 IO 需要用戶多次發(fā)起系統(tǒng)調(diào)用。頻繁的系統(tǒng)調(diào)用是比較消耗系統(tǒng)資源的。
3.3 IO 多路復(fù)用
為了解決非阻塞 IO 存在的頻繁的系統(tǒng)調(diào)用這個(gè)問題,隨著內(nèi)核的發(fā)展,出現(xiàn)了 IO 多路復(fù)用模型。
IO 多路復(fù)用:通過一種機(jī)制一個(gè)進(jìn)程能同時(shí)等待多個(gè)文件描述符,而這些文件描述符(套接字描述符)其中的任意一個(gè)進(jìn)入讀就緒狀態(tài),就可以返回。
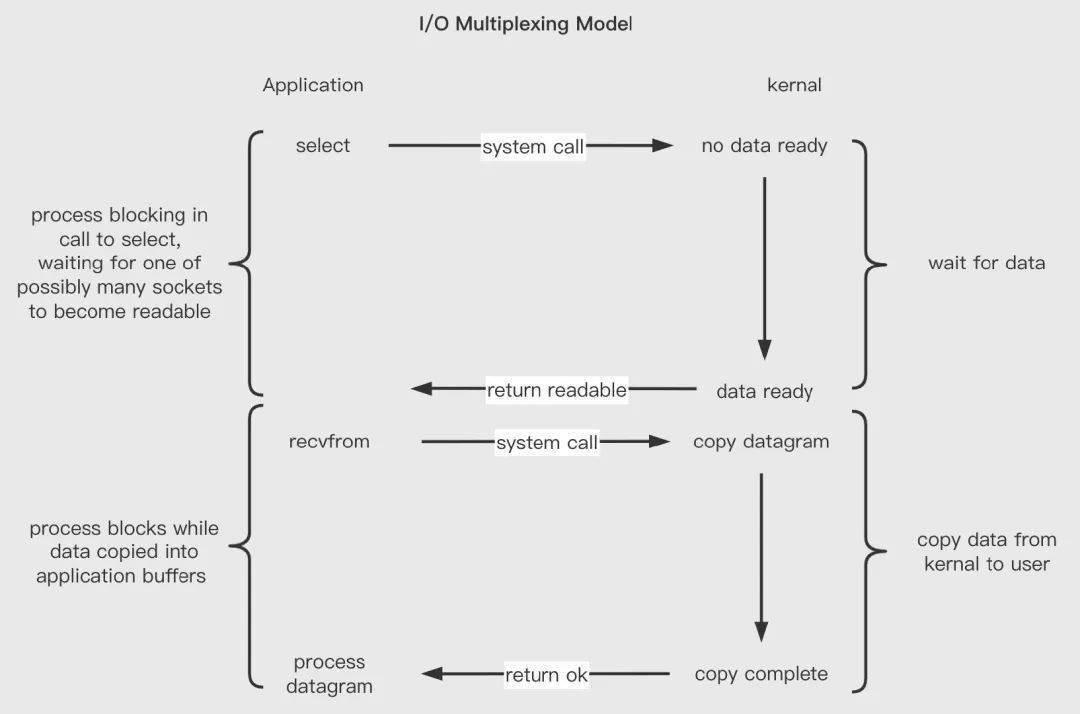
IO 多路復(fù)用本質(zhì)上復(fù)用了系統(tǒng)調(diào)用,使多個(gè)文件的狀態(tài)可以復(fù)用一個(gè)系統(tǒng)調(diào)用獲取,有效減少了系統(tǒng)調(diào)用。select、poll、epoll均是基于 IO 多路復(fù)用思想實(shí)現(xiàn)的。

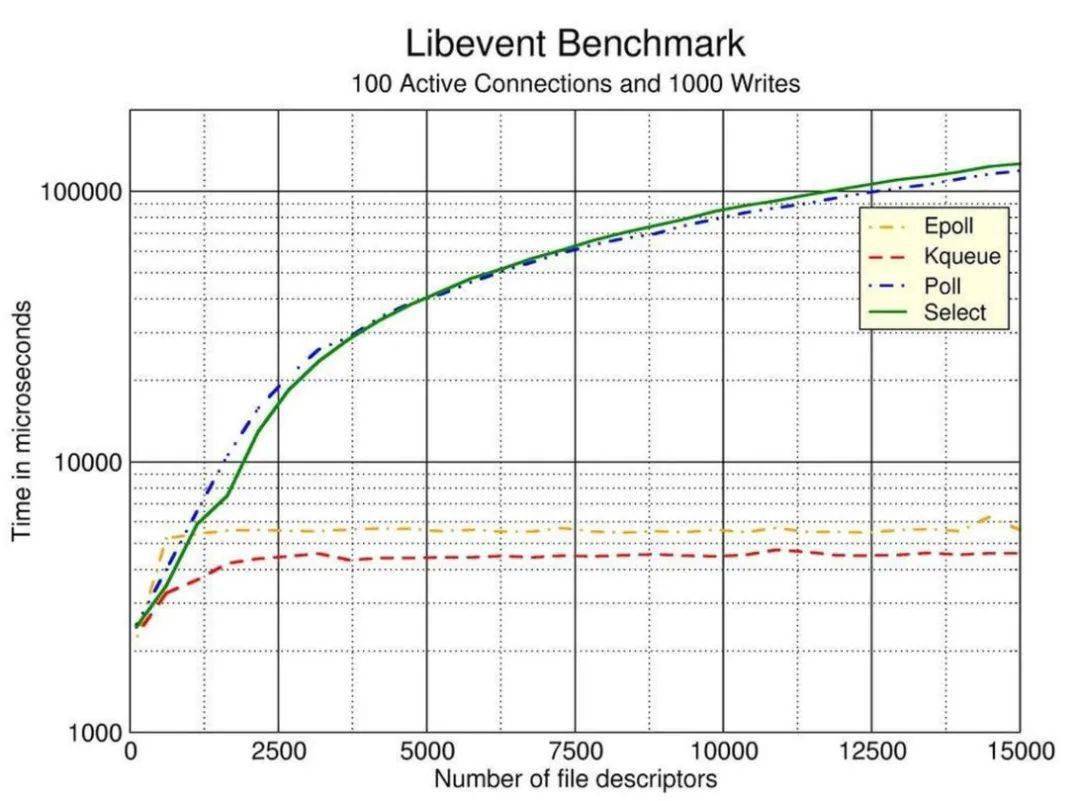
select 和 poll 的工作原理比較相似,通過 select或者 poll將多個(gè) socket fds 批量通過系統(tǒng)調(diào)用傳遞給內(nèi)核,由內(nèi)核進(jìn)行循環(huán)遍歷判斷哪些 fd 上數(shù)據(jù)就緒了,然后將就緒的 readyfds 返回給用戶。再由用戶進(jìn)行挨個(gè)遍歷就緒好的 fd,讀取或者寫入數(shù)據(jù)。所以通過 IO 多路復(fù)用+非阻塞 IO,一方面降低了系統(tǒng)調(diào)用次數(shù),另一方面可以用極少的線程來處理多個(gè)網(wǎng)絡(luò)連接。select 和 poll 的最大區(qū)別是:select 默認(rèn)能處理的最大連接是 1024 個(gè),可以通過修改配置來改變,但終究是有限個(gè);而 poll 理論上可以支持無限個(gè)。而 select 和 poll 則面臨相似的問題在管理海量的連接時(shí),會(huì)頻繁的從用戶態(tài)拷貝到內(nèi)核態(tài),比較消耗資源。
epoll 有效規(guī)避了將 fd 頻繁的從用戶態(tài)拷貝到內(nèi)核態(tài),通過使用紅黑樹(RB-tree)搜索被監(jiān)視的文件描述符(file deor)。在 epoll 實(shí)例上注冊事件時(shí),epoll 會(huì)將該事件添加到epoll 實(shí)例的紅黑樹上并注冊一個(gè)回調(diào)函數(shù),當(dāng)事件發(fā)生時(shí)會(huì)將事件添加到就緒鏈表中。
3.3.1 epoll 數(shù)據(jù)結(jié)構(gòu) + 算法
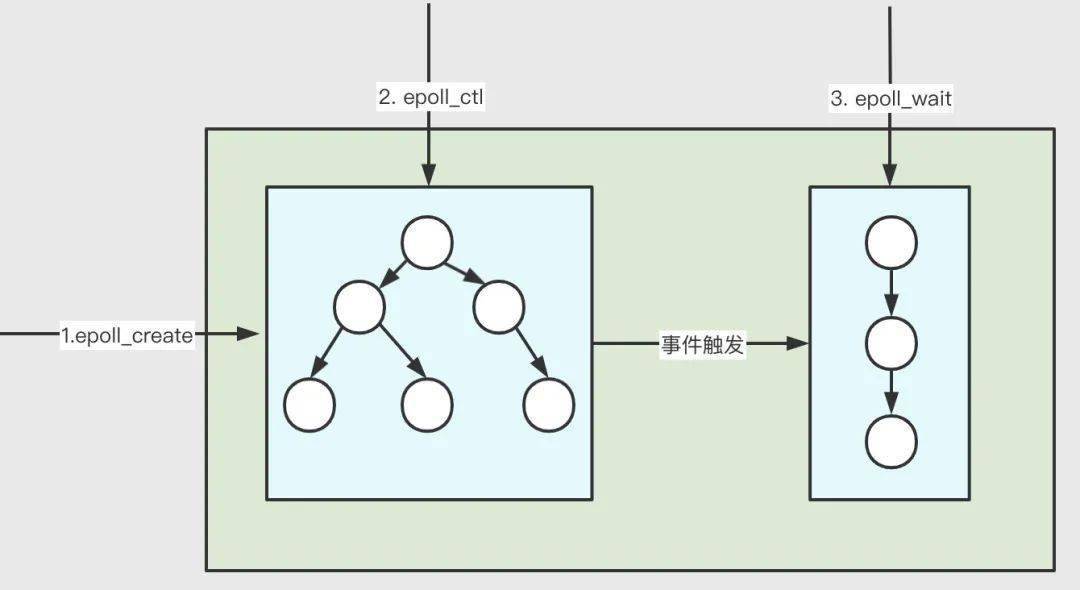
epoll 的核心數(shù)據(jù)結(jié)構(gòu)是:1 個(gè) 紅黑樹和 1 個(gè) 雙向鏈表,還有 3個(gè)核心API。
3.3.2 監(jiān)視 socket 索引-紅黑樹
為什么采用紅黑樹呢?因?yàn)楹?epoll 的工作機(jī)制有關(guān)。epoll 在添加一個(gè) socket 或者刪除一個(gè) socket 或者修改一個(gè) socket 的時(shí)候,它需要查詢速度更快,操作效率最高,因此需要一個(gè)更加優(yōu)秀的數(shù)據(jù)結(jié)構(gòu)能夠管理這些 socket。我們想到的比如鏈表,數(shù)組,二叉搜索樹,B+樹等都無法滿足要求,
- 因?yàn)殒湵碓诓樵儯瑒h除的時(shí)候毫無疑問時(shí)間復(fù)雜度是 O(n);
- 數(shù)組查詢很快,但是刪除和新增時(shí)間復(fù)雜度是 O(n);
- 二叉搜索樹雖然查詢效率是 lgn,但是如果不是平衡的,那么就會(huì)退化為線性查找,復(fù)雜度直接來到 O(n);
- B+樹是平衡多路查找樹,主要是通過降低樹的高度來存儲(chǔ)上億級別的數(shù)據(jù),但是它的應(yīng)用場景是內(nèi)存放不下的時(shí)候能夠用最少的 IO 訪問次數(shù)從磁盤獲取數(shù)據(jù)。比如數(shù)據(jù)庫聚簇索引,成百上千萬的數(shù)據(jù)內(nèi)存無法滿足查找就需要到內(nèi)存查找,而因?yàn)?B+樹層高很低,只需要幾次磁盤 IO 就能獲取數(shù)據(jù)到內(nèi)存,所以在這種磁盤到內(nèi)存訪問上 B+樹更適合。
因?yàn)槲覀兲幚砩先f級的 fd,它們本身的存儲(chǔ)空間并不會(huì)很大,所以傾向于在內(nèi)存中去實(shí)現(xiàn)管理,而紅黑樹是一種非常優(yōu)秀的平衡樹,它完全是在內(nèi)存中操作,而且查找,刪除和新增時(shí)間復(fù)雜度都是 lgn,效率非常高,因此選擇用紅黑樹實(shí)現(xiàn) epoll 是最佳的選擇。當(dāng)然不選擇用 AVL 樹是因?yàn)榧t黑樹是不符合 AVL 樹的平衡條件的,紅黑是用非嚴(yán)格的平衡來換取增刪節(jié)點(diǎn)時(shí)候旋轉(zhuǎn)次數(shù)的降低,任何不平衡都會(huì)在三次旋轉(zhuǎn)之內(nèi)解決;而 AVL 樹是嚴(yán)格平衡樹,在增加或者刪除節(jié)點(diǎn)的時(shí)候,根據(jù)不同情況,旋轉(zhuǎn)的次數(shù)比紅黑樹要多。所以紅黑樹的插入效率更高。
3.3.2 就緒 socket 列表-雙向鏈表
就緒列表存儲(chǔ)的是就緒的 socket,所以它應(yīng)能夠快速的插入數(shù)據(jù)。程序可能隨時(shí)調(diào)用 epoll_ctl 添加監(jiān)視 socket,也可能隨時(shí)刪除。當(dāng)刪除時(shí),若該 socket 已經(jīng)存放在就緒列表中,它也應(yīng)該被移除。(事實(shí)上,每個(gè) epoll_item 既是紅黑樹節(jié)點(diǎn),也是鏈表節(jié)點(diǎn),刪除紅黑樹節(jié)點(diǎn),自然刪除了鏈表節(jié)點(diǎn)) 所以就緒列表應(yīng)是一種能夠快速插入和刪除的數(shù)據(jù)結(jié)構(gòu)。雙向鏈表就是這樣一種數(shù)據(jù)結(jié)構(gòu),epoll 使用 雙向鏈表來實(shí)現(xiàn)就緒隊(duì)列(rdllist)
3.3.3 三個(gè) API 3.3.3.1 int epoll_create(int size)
功能:內(nèi)核會(huì)產(chǎn)生一個(gè) epoll 實(shí)例數(shù)據(jù)結(jié)構(gòu)并返回一個(gè)文件描述符 epfd,這個(gè)特殊的描述符就是 epoll 實(shí)例的句柄,后面的兩個(gè)接口都以它為中心。同時(shí)也會(huì)創(chuàng)建紅黑樹和就緒列表,紅黑樹來管理注冊 fd,就緒列表來收集所有就緒 fd。size 參數(shù)表示所要監(jiān)視文件描述符的最大值,不過在后來的 Linux 版本中已經(jīng)被棄用(同時(shí),size 不要傳 0,會(huì)報(bào) invalid argument 錯(cuò)誤)
3.3.3.2 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
功能:將被監(jiān)聽的 socket 文件描述符添加到紅黑樹或從紅黑樹中刪除或者對監(jiān)聽事件進(jìn)行修改;同時(shí)向內(nèi)核中斷處理程序注冊一個(gè)回調(diào)函數(shù),內(nèi)核在檢測到某文件描述符可讀/可寫時(shí)會(huì)調(diào)用回調(diào)函數(shù),該回調(diào)函數(shù)將文件描述符放在就緒鏈表中。
3.3.3.3 int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
功能:阻塞等待注冊的事件發(fā)生,返回事件的數(shù)目,并將觸發(fā)的事件寫入 events 數(shù)組中。events: 用來記錄被觸發(fā)的 events,其大小應(yīng)該和 maxevents 一致 maxevents: 返回的 events 的最大個(gè)數(shù)處于 ready 狀態(tài)的那些文件描述符會(huì)被復(fù)制進(jìn) ready list 中,epoll_wait 用于向用戶進(jìn)程返回 ready list(就緒列表)。events 和 maxevents 兩個(gè)參數(shù)描述一個(gè)由用戶分配的 struct epoll event 數(shù)組,調(diào)用返回時(shí),內(nèi)核將就緒列表(雙向鏈表)復(fù)制到這個(gè)數(shù)組中,并將實(shí)際復(fù)制的個(gè)數(shù)作為返回值。注意,如果就緒列表比 maxevents 長,則只能復(fù)制前 maxevents 個(gè)成員;反之,則能夠完全復(fù)制就緒列表。另外,struct epoll event 結(jié)構(gòu)中的 events 域在這里的解釋是:在被監(jiān)測的文件描述符上實(shí)際發(fā)生的事件。
3.3.4 工作模式
epoll 對文件描述符的操作有兩種模式:LT(level trigger)和 ET(edge trigger)。
- LT 模式 LT(level triggered)是缺省的工作方式,并且同時(shí)支持 block 和 no-block socket.在這種做法中,內(nèi)核告訴你一個(gè)文件描述符是否就緒了,然后你可以對這個(gè)就緒的 fd 進(jìn)行 IO 操作。如果你不作任何操作,內(nèi)核還是會(huì)繼續(xù)通知你。
- ET 模式 ET(edge-triggered)是高速工作方式,只支持 no-block socket。在這種模式下,當(dāng)描述符從未就緒變?yōu)榫途w時(shí),內(nèi)核通過 epoll 告訴你。然后它會(huì)假設(shè)你知道文件描述符已經(jīng)就緒,并且不會(huì)再為那個(gè)文件描述符發(fā)送更多的就緒通知,直到你做了某些操作導(dǎo)致那個(gè)文件描述符不再為就緒狀態(tài)了(比如,你在發(fā)送,接收或者接收請求,或者發(fā)送接收的數(shù)據(jù)少于一定量時(shí)導(dǎo)致了一個(gè) EWOULDBLOCK 錯(cuò)誤)。注意,如果一直不對這個(gè) fd 作 IO 操作(從而導(dǎo)致它再次變成未就緒),內(nèi)核不會(huì)發(fā)送更多的通知(only once)ET 模式在很大程度上減少了 epoll 事件被重復(fù)觸發(fā)的次數(shù),因此效率要比 LT 模式高。epoll 工作在 ET 模式的時(shí)候,必須使用非阻塞套接口,以避免由于一個(gè)文件句柄的阻塞讀/阻塞寫操作把處理多個(gè)文件描述符的任務(wù)餓死。
實(shí)際的網(wǎng)絡(luò)模型常結(jié)合 I/O 復(fù)用和線程池實(shí)現(xiàn),如 Reactor 模式:
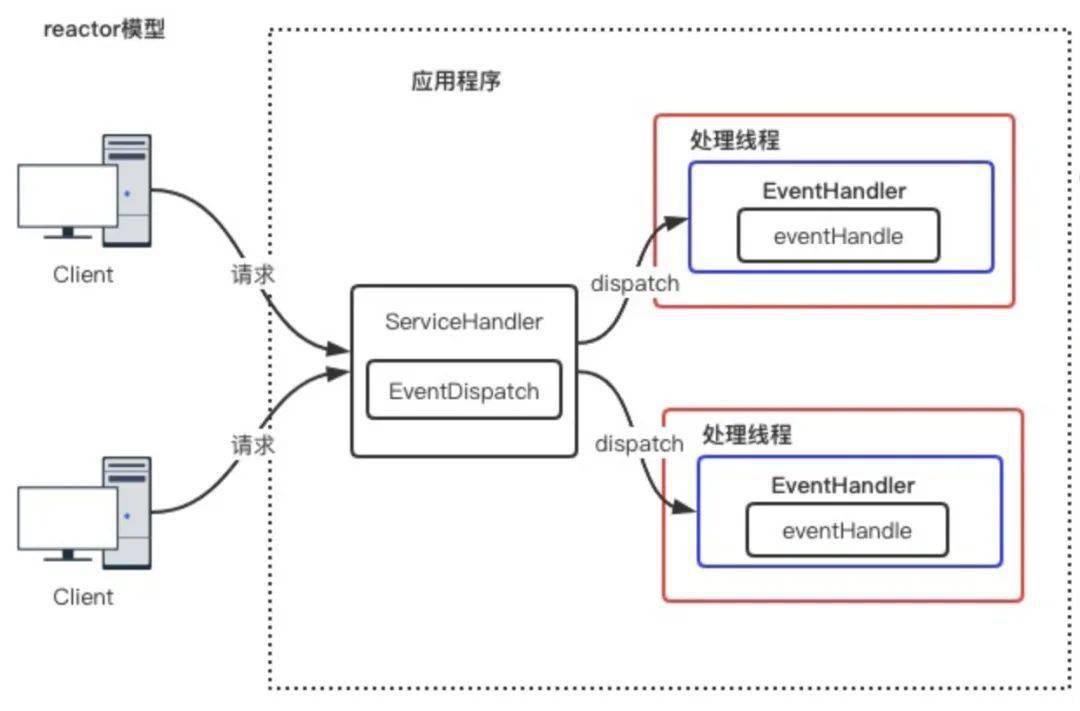
3.4.1 單 reactor 單線程模型
此種模型通常只有一個(gè) epoll 對象,所有的接收客戶端連接、客戶端讀取、客戶端寫入操作都包含在一個(gè)線程內(nèi)。
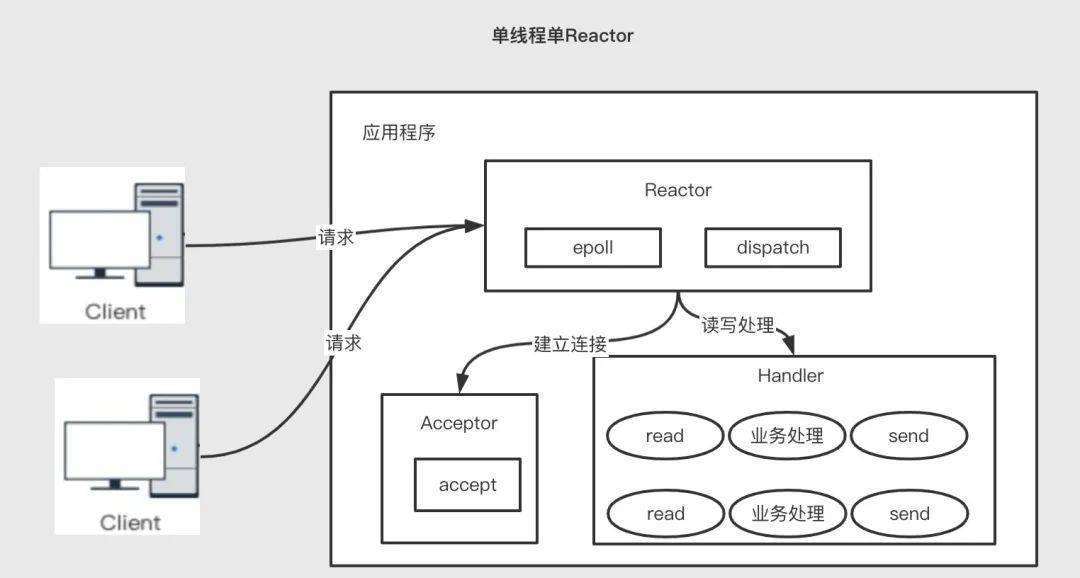
3.4.2 單 reactor 多線程模型優(yōu)點(diǎn):模型簡單,沒有多線程、進(jìn)程通信、競爭的問題,全部都在一個(gè)線程中完成 缺點(diǎn):單線程無法完全發(fā)揮多核 CPU 的性能;I/O 操作和非 I/O 的業(yè)務(wù)操作在一個(gè) Reactor 線程完成,這可能會(huì)大大延遲 I/O 請求的響應(yīng);線程意外終止,或者進(jìn)入死循環(huán),會(huì)導(dǎo)致整個(gè)系統(tǒng)通信模塊不可用,不能接收和處理外部消息,造成節(jié)點(diǎn)故障;使用場景:客戶端的數(shù)量有限,業(yè)務(wù)處理非常快速,比如 redis 在業(yè)務(wù)處理的時(shí)間復(fù)雜度 O(1) 的情況
該模型將讀寫的業(yè)務(wù)邏輯交給具體的線程池來處理
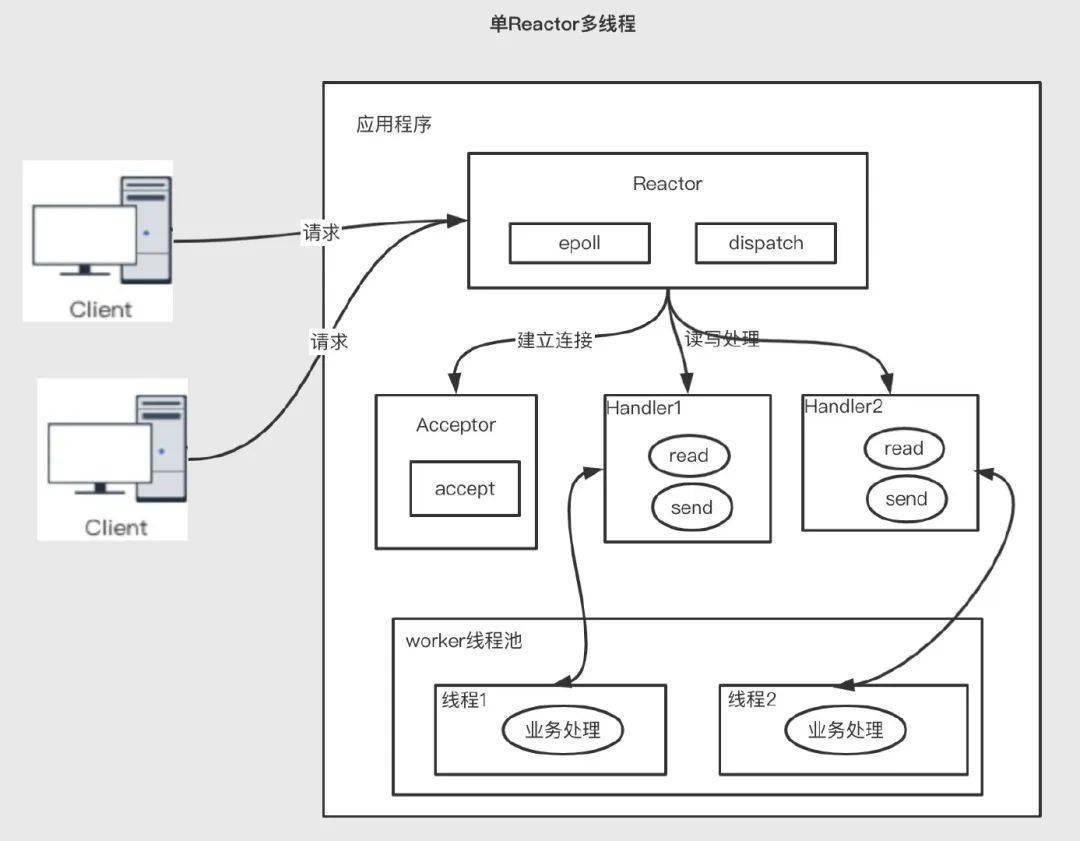
3.4.3 multi-reactor 多線程模型優(yōu)點(diǎn):充分利用多核 cpu 的處理能力,提升 I/O 響應(yīng)速度;缺點(diǎn):在該模式中,雖然非 I/O 操作交給了線程池來處理,但是所有的 I/O 操作依然由 Reactor 單線程執(zhí)行,在高負(fù)載、高并發(fā)或大數(shù)據(jù)量的應(yīng)用場景,依然容易成為瓶頸。
在這種模型中,主要分為兩個(gè)部分:mainReactor、subReactors。mainReactor 主要負(fù)責(zé)接收客戶端的連接,然后將建立的客戶端連接通過負(fù)載均衡的方式分發(fā)給 subReactors,subReactors 來負(fù)責(zé)具體的每個(gè)連接的讀寫 對于非 IO 的操作,依然交給工作線程池去做。
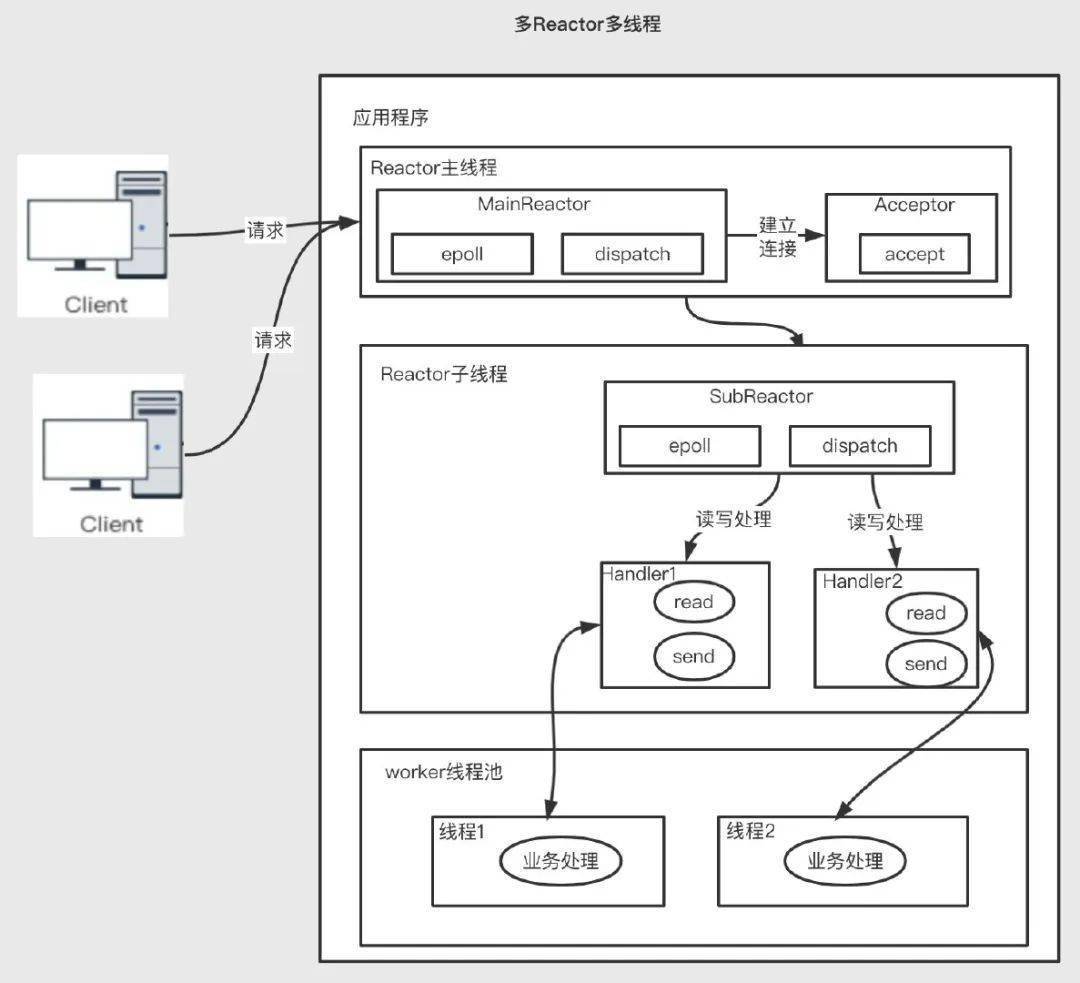
3.4.4 主流的中間件所采用的網(wǎng)絡(luò)模型 3.5 異步 IO優(yōu)點(diǎn):父線程與子線程的數(shù)據(jù)交互簡單職責(zé)明確,父線程只需要接收新連接,子線程完成后續(xù)的業(yè)務(wù)處理。Reactor 主線程只需要把新連接傳給子線程,子線程無需返回?cái)?shù)據(jù)。缺點(diǎn):編程復(fù)雜度較高。
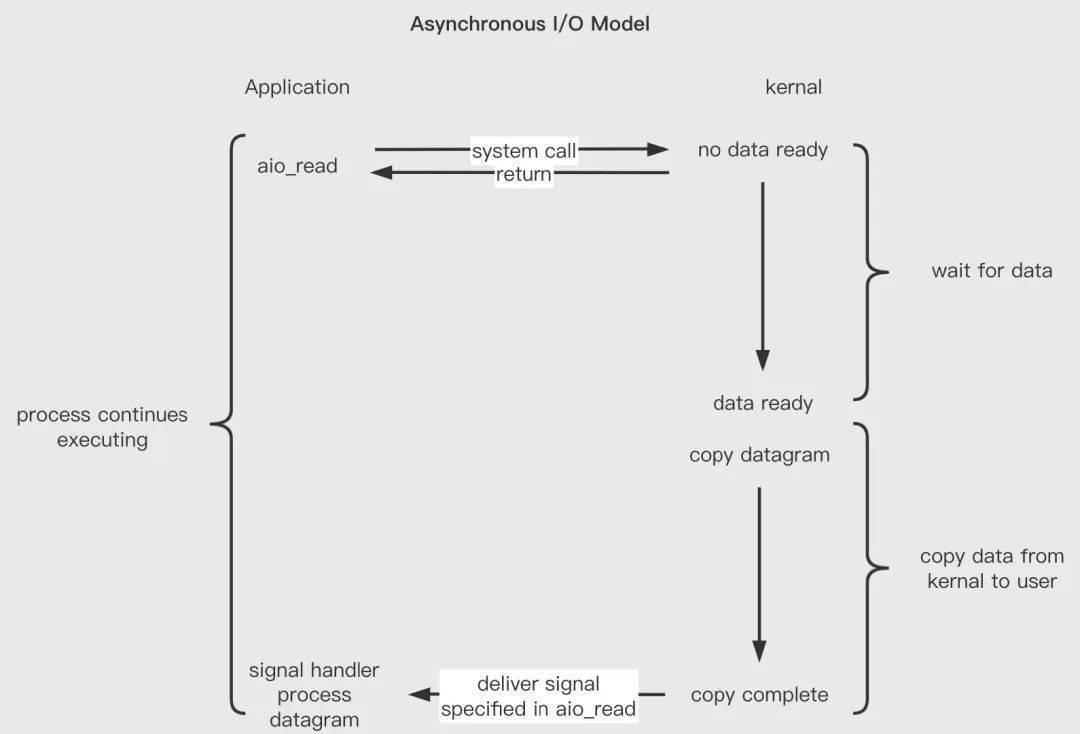
前面介紹的所有網(wǎng)絡(luò) IO 都是同步 IO,因?yàn)楫?dāng)數(shù)據(jù)在內(nèi)核態(tài)就緒時(shí),在內(nèi)核態(tài)拷貝用用戶態(tài)的過程中,仍然會(huì)有短暫時(shí)間的阻塞等待。而異步 IO 指:內(nèi)核態(tài)拷貝數(shù)據(jù)到用戶態(tài)這種方式也是交給系統(tǒng)線程來實(shí)現(xiàn),不由用戶線程完成,如 windows 的 IOCP ,Linux 的 AIO。
四、 零拷貝 4.1 傳統(tǒng) IO 流程
傳統(tǒng) IO 流程會(huì)經(jīng)過如下兩個(gè)過程:
- 數(shù)據(jù)準(zhǔn)備階段:數(shù)據(jù)從硬件到內(nèi)核空間
- 數(shù)據(jù)拷貝階段:數(shù)據(jù)從內(nèi)核空間到用戶空間
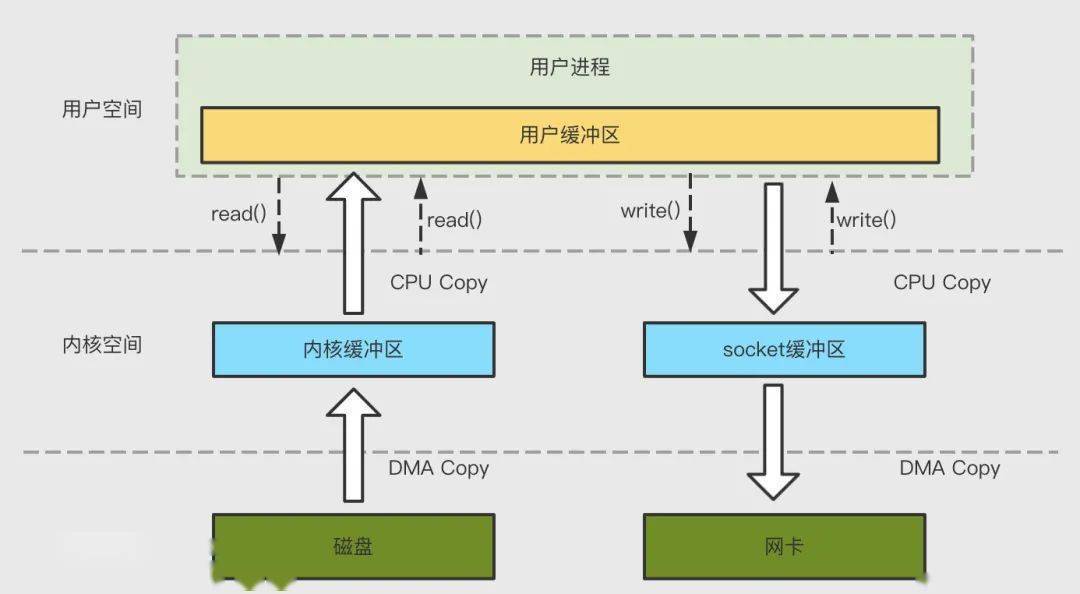
零拷貝:指數(shù)據(jù)無需從硬件到內(nèi)核空間或從內(nèi)核空間到用戶空間。下面介紹常見的零拷貝實(shí)現(xiàn)
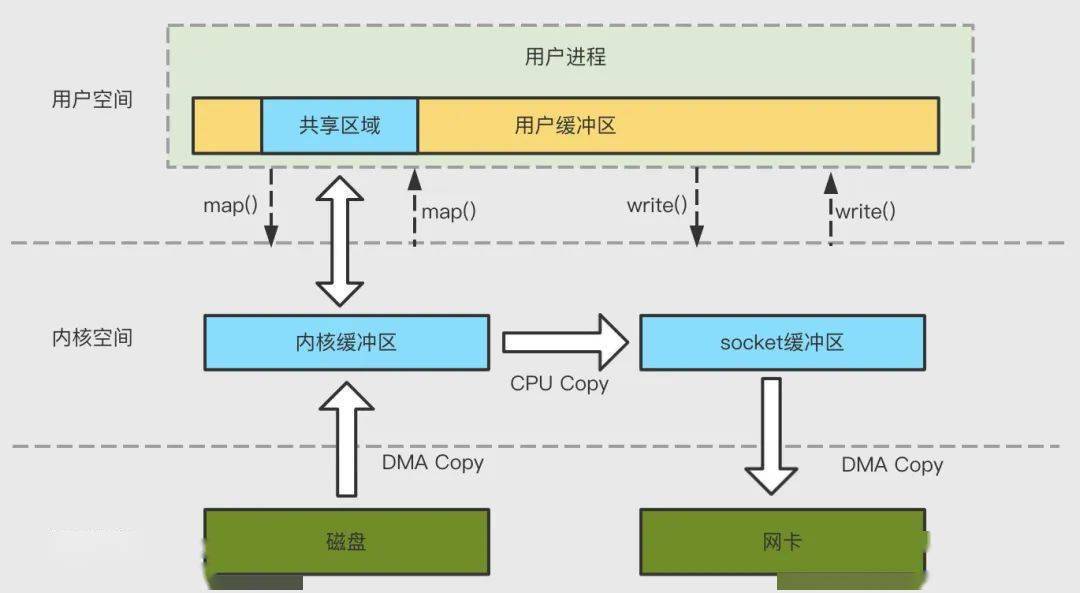
4.2 mmap + write
mmap 將內(nèi)核中讀緩沖區(qū)(read buffer)的地址與用戶空間的緩沖區(qū)(user buffer)進(jìn)行映射,從而實(shí)現(xiàn)內(nèi)核緩沖區(qū)與應(yīng)用程序內(nèi)存的共享,省去了將數(shù)據(jù)從內(nèi)核讀緩沖區(qū)(read buffer)拷貝到用戶緩沖區(qū)(user buffer)的過程,整個(gè)拷貝過程會(huì)發(fā)生 4 次上下文切換,1 次 CPU 拷貝和 2 次 DMA 拷貝。
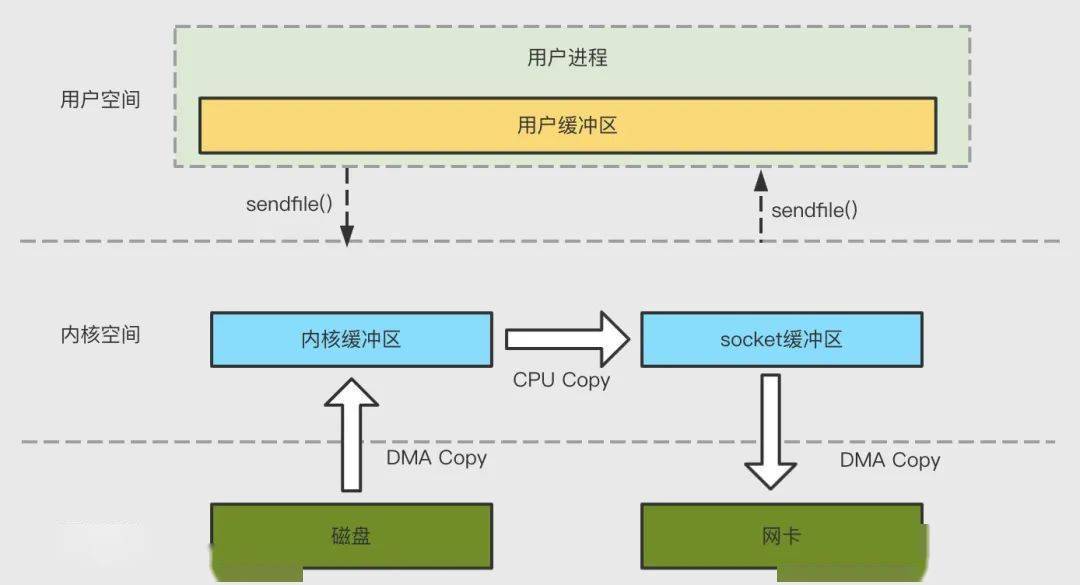
4.3 sendfile
通過 sendfile 系統(tǒng)調(diào)用,數(shù)據(jù)可以直接在內(nèi)核空間內(nèi)部進(jìn)行 I/O 傳輸,從而省去了數(shù)據(jù)在用戶空間和內(nèi)核空間之間的來回拷貝,sendfile 調(diào)用中 I/O 數(shù)據(jù)對用戶空間是完全不可見的,整個(gè)拷貝過程會(huì)發(fā)生 2 次上下文切換,1 次 CPU 拷貝和 2 次 DMA 拷貝。
4.4 Sendfile + DMA gather copy
Linux2.4 引入 ,將內(nèi)核空間的讀緩沖區(qū)(read buffer)中對應(yīng)的數(shù)據(jù)描述信息(內(nèi)存地址、地址偏移量)記錄到相應(yīng)的網(wǎng)絡(luò)緩沖區(qū)(socketbuffer)中,由 DMA 根據(jù)內(nèi)存地址、地址偏移量將數(shù)據(jù)批量地從讀緩沖區(qū)(read buffer)拷貝到網(wǎng)卡設(shè)備中,這樣就省去了內(nèi)核空間中僅剩的 1 次 CPU 拷貝操作,發(fā)生 2 次上下文切換、0 次 CPU 拷貝以及 2 次 DMA 拷貝;
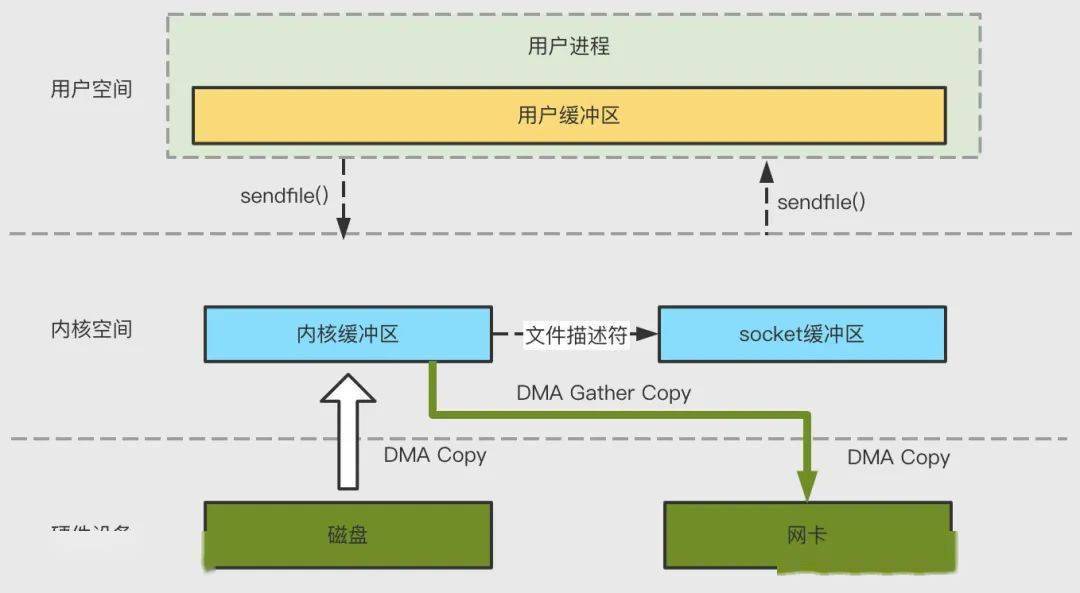
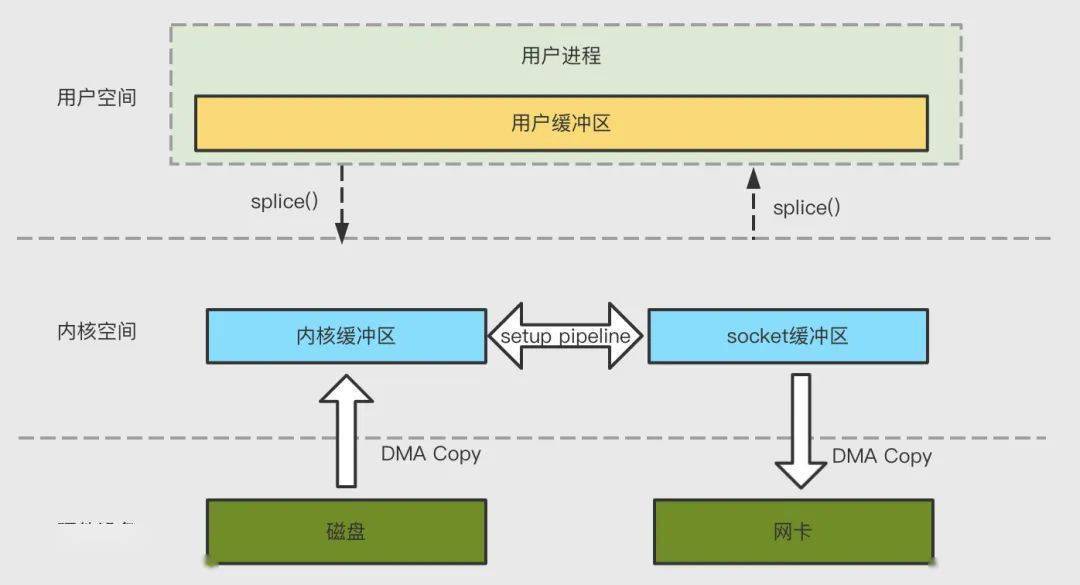
4.5 splice
Linux2.6.17 版本引入,在內(nèi)核空間的讀緩沖區(qū)(read buffer)和網(wǎng)絡(luò)緩沖區(qū)(socket buffer)之間建立管道(pipeline),從而避免了兩者之間的 CPU 拷貝操作,2 次上下文切換,0 次 CPU 拷貝以及 2 次 DMA 拷貝。
4.6 寫時(shí)復(fù)制
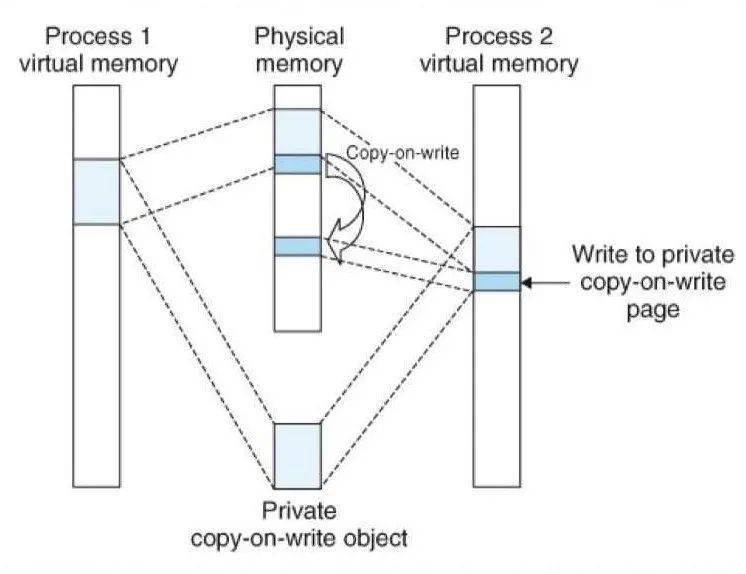
通過盡量延遲產(chǎn)生私有對象中的副本,寫時(shí)復(fù)制最充分地利用了稀有的物理資源。
4.7 JAVA 中零拷貝
MAppedByteBuffer:基于內(nèi)存映射(mmap)這種零拷貝方式的提供的一種實(shí)現(xiàn)。

FileChannel 基于 sendfile 定義了 transferFrom 和 transferTo 兩個(gè)抽象方法,它通過在通道和通道之間建立連接實(shí)現(xiàn)數(shù)據(jù)傳輸?shù)摹?/p>

五、參考
https://mp.weixin.qq.com/s/c81Fvws0J2tHjcdTgxvv6g
https://mp.weixin.qq.com/s/EDzFOo3gcivOe_RgipkTkQ
https://mp.weixin.qq.com/s/G6TfGbc4U8Zhv30wnN0HIg
https://mp.weixin.qq.com/s/r9RU4RoE-qrzXPAwiej5sw





