擊這里在線咨詢客服")
作者:京東科技 徐擁
入門
1、什么是kafka?
Apache Kafka is a distributed streaming platform. What exactly dose that mean?
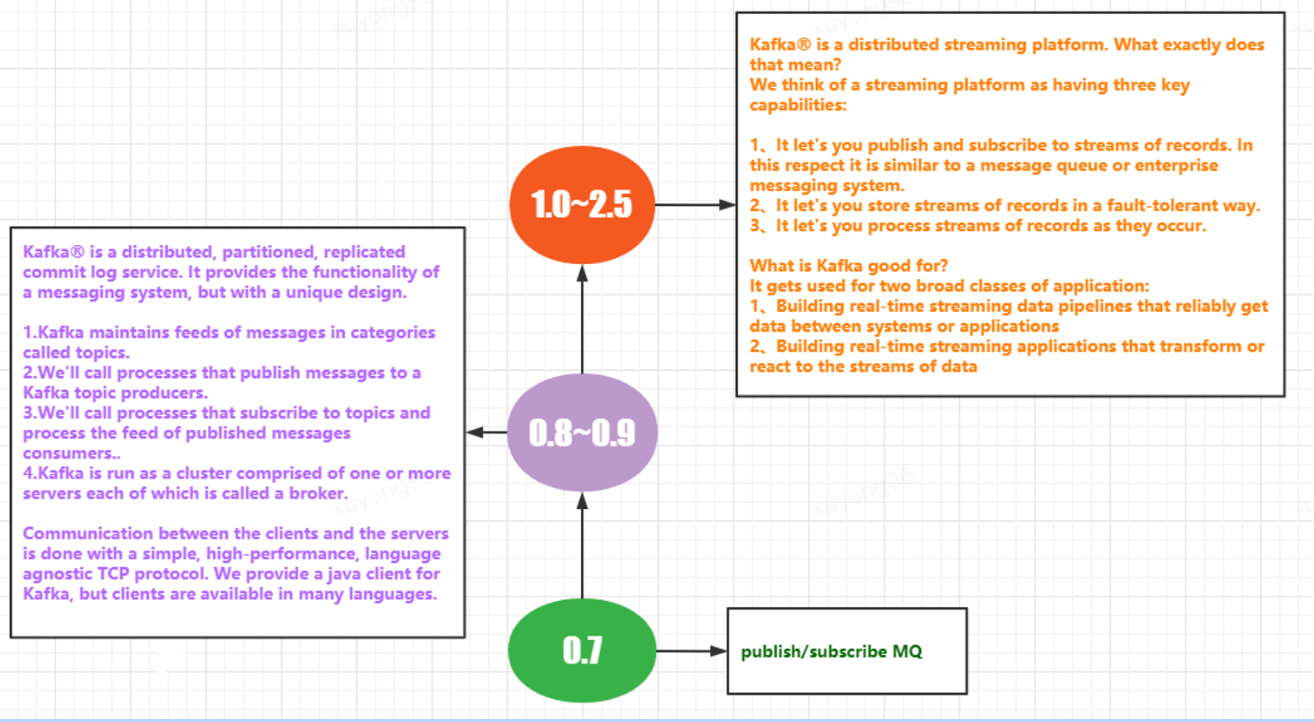
Apache Kafka 是消息引擎系統(tǒng),也是一個(gè)分布式流處理平臺(Distributed Streaming Platform)
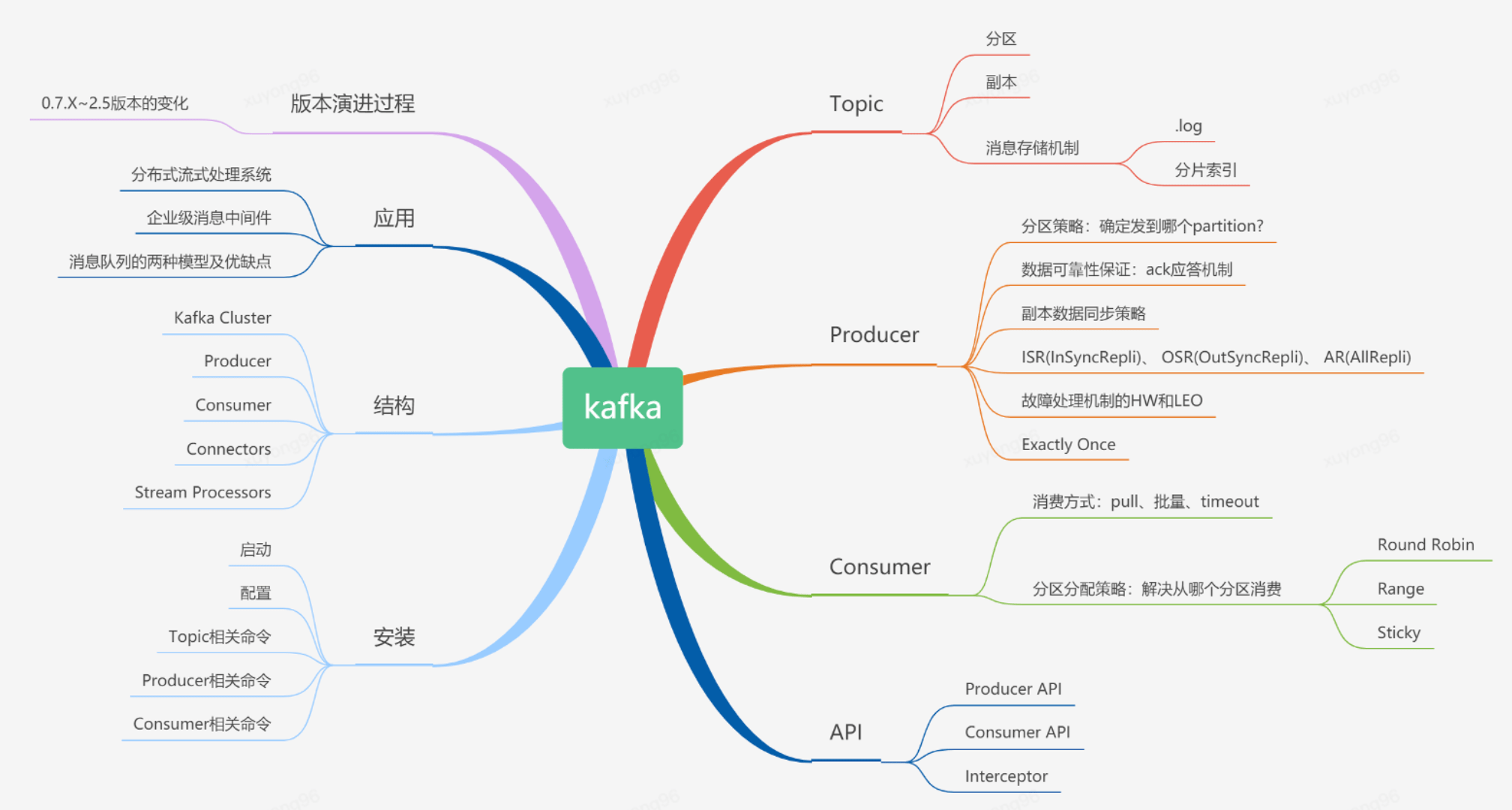
2、kafka全景圖:
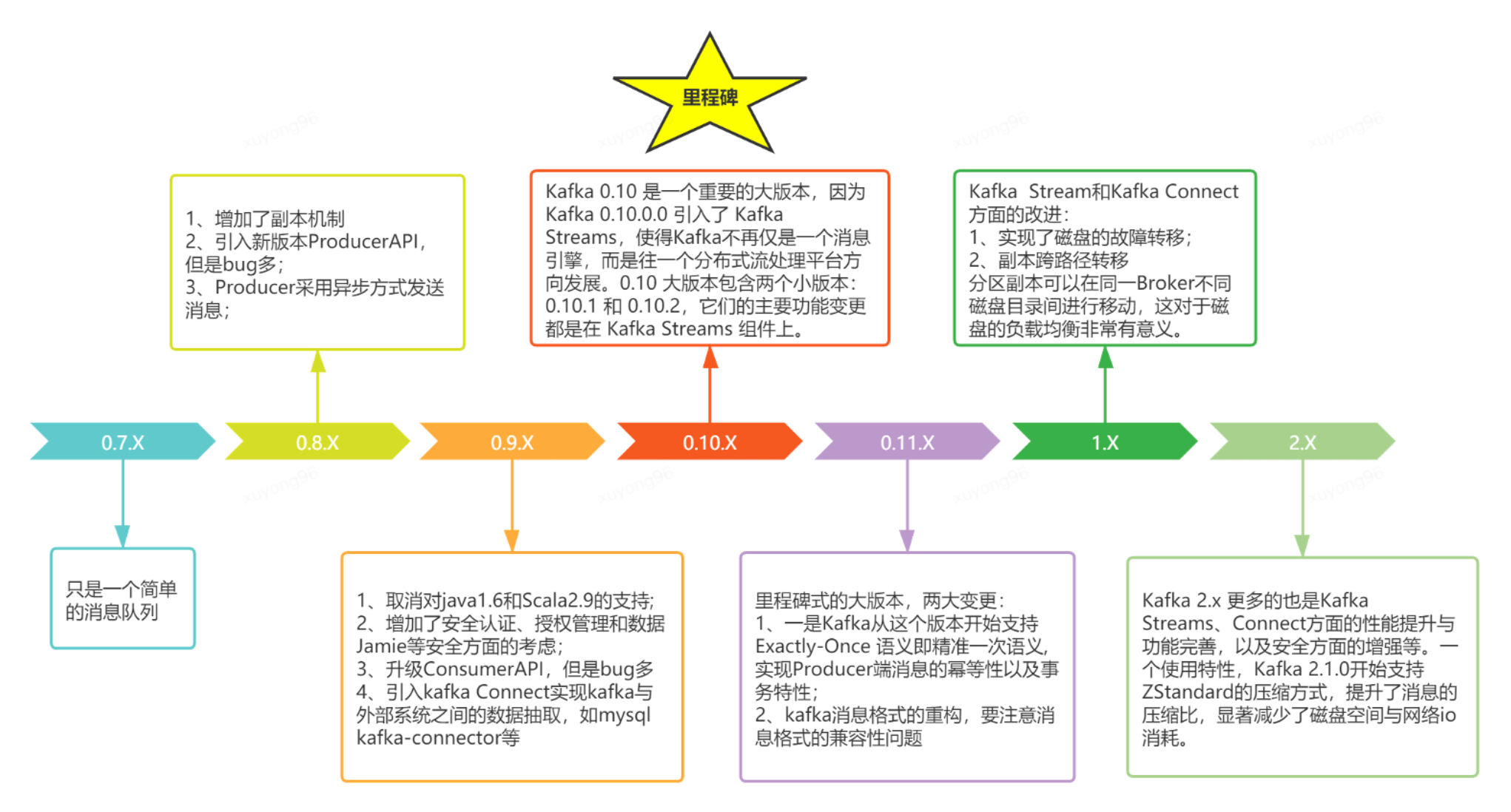
3、Kafka的版本演進(jìn):

4、kafka選型:
Apache Kafka:也稱社區(qū)版 Kafka。優(yōu)勢在于迭代速度快,社區(qū)響應(yīng)度高,使用它可以讓你有更高的把控度;缺陷在于僅提供基礎(chǔ)核心組件,缺失一些高級的特性。(如果你僅僅需要一個(gè)消息引擎系統(tǒng)亦或是簡單的流處理應(yīng)用場景,同時(shí)需要對系統(tǒng)有較大把控度,那么我推薦你使用 Apache Kafka)
Confluent Kafka :Confluent 公司提供的 Kafka。優(yōu)勢在于集成了很多高級特性且由 Kafka 原班人馬打造,質(zhì)量上有保證;缺陷在于相關(guān)文檔資料不全,普及率較低,沒有太多可供參考的范例。(如果你需要用到 Kafka 的一些高級特性,那么推薦你使用 Confluent Kafka。)
CDH/HDP Kafka:大數(shù)據(jù)云公司提供的 Kafka,內(nèi)嵌 Apache Kafka。優(yōu)勢在于操作簡單,節(jié)省運(yùn)維成本;缺陷在于把控度低,演進(jìn)速度較慢。(如果你需要快速地搭建消息引擎系統(tǒng),或者你需要搭建的是多框架構(gòu)成的數(shù)據(jù)平臺且 Kafka 只是其中一個(gè)組件,那么我推薦你使用這些大數(shù)據(jù)云公司提供的 Kafka)
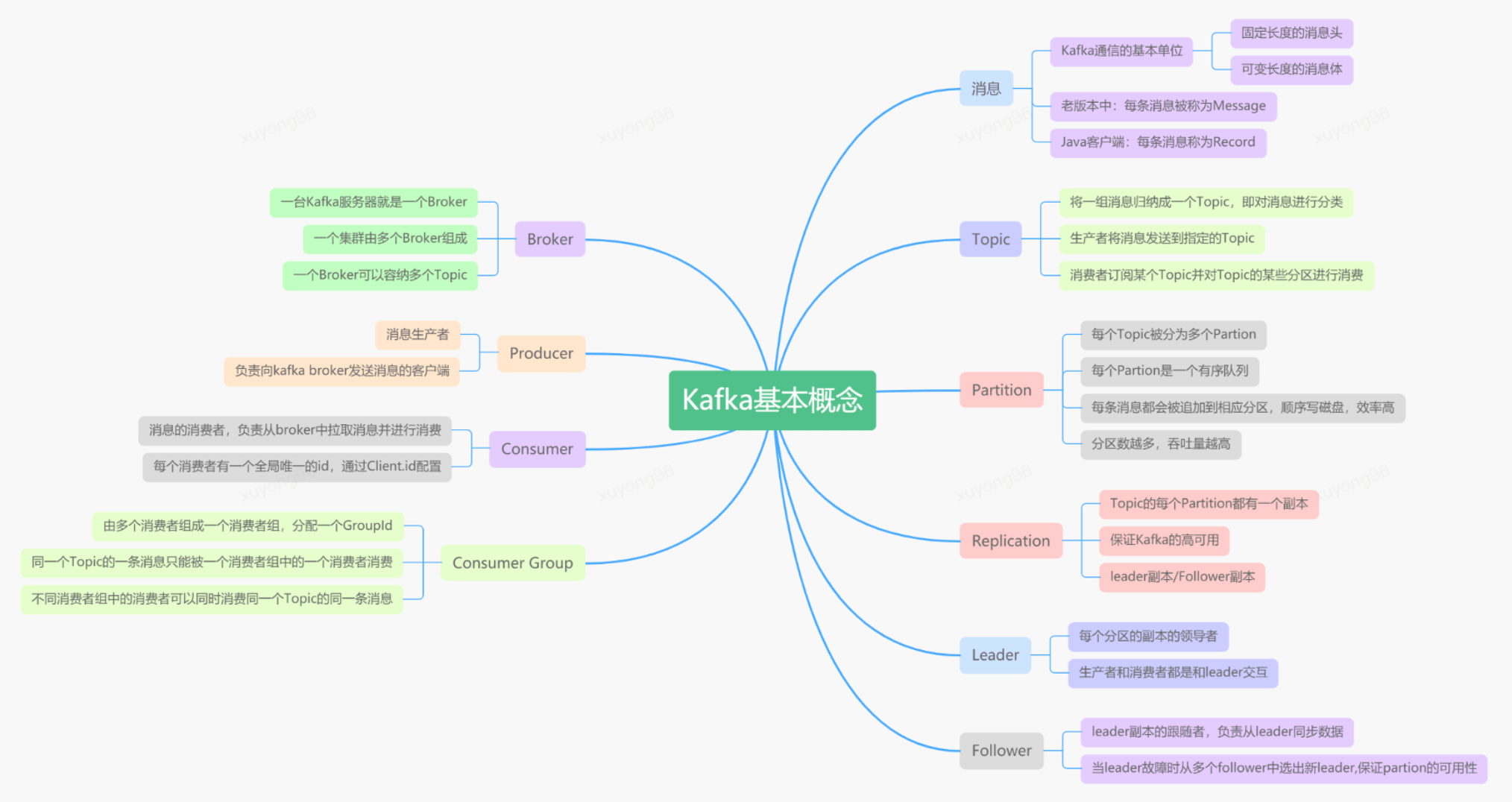
5、Kafka的基本概念:
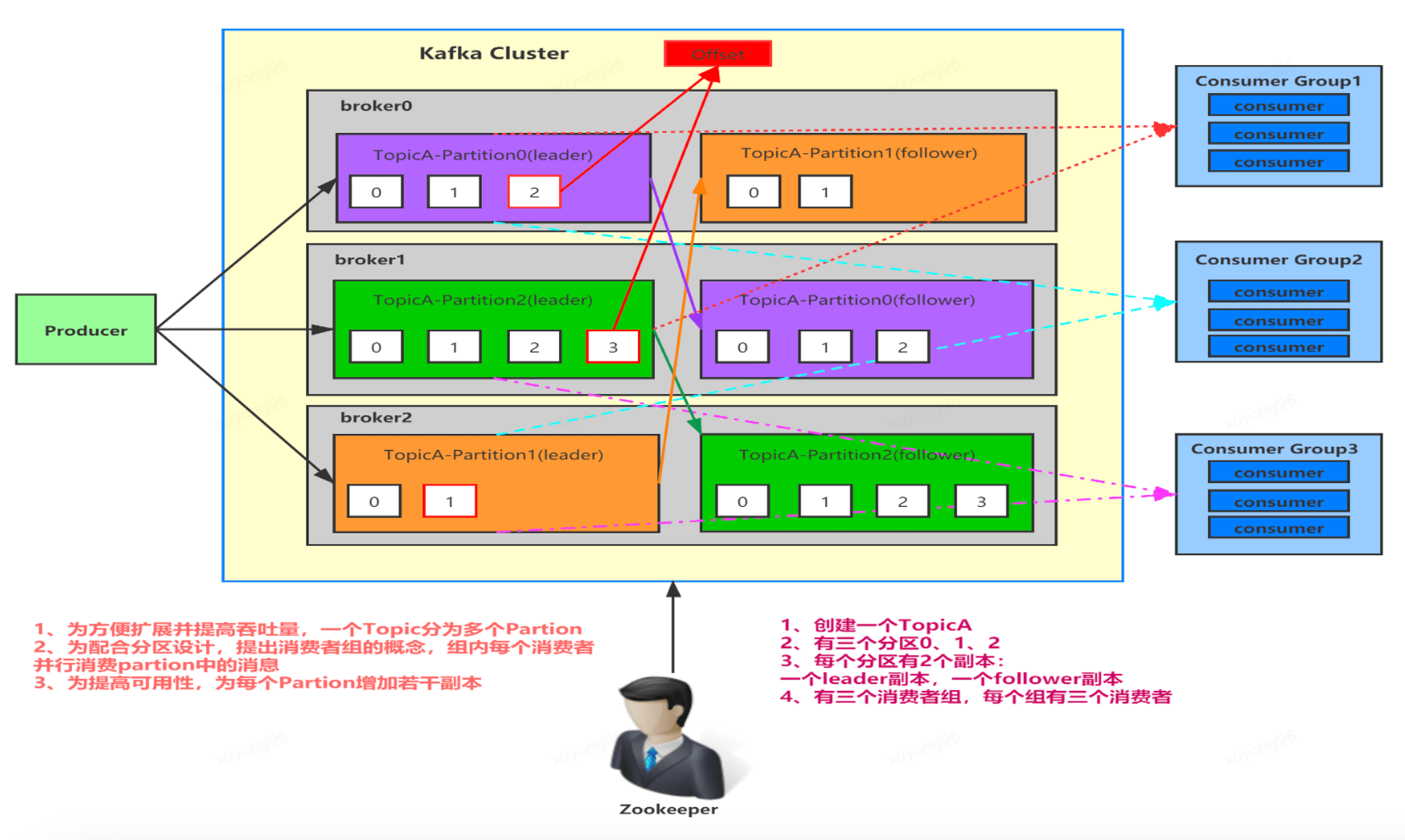
6、Kafka的基本結(jié)構(gòu):
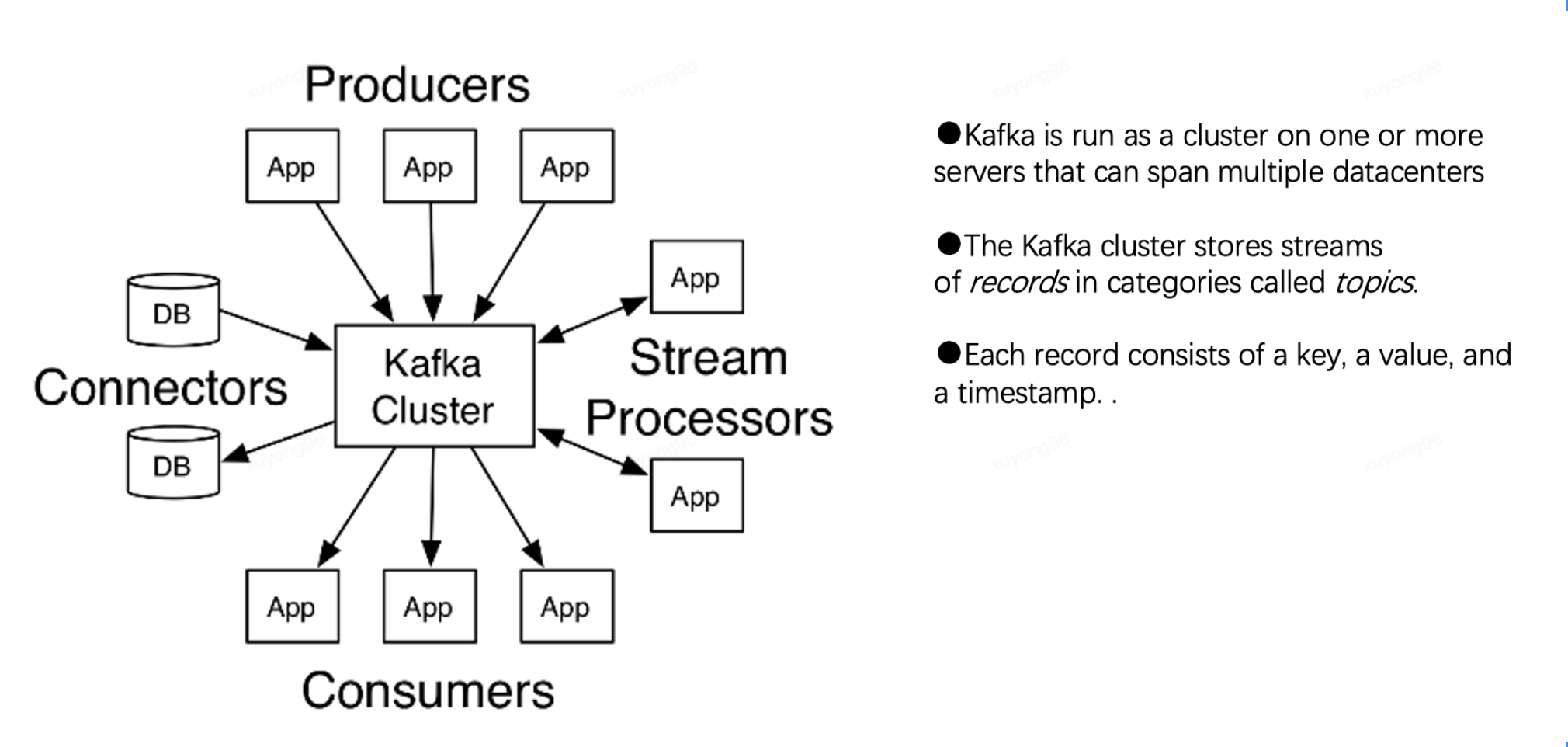
7、Kafka的集群結(jié)構(gòu):
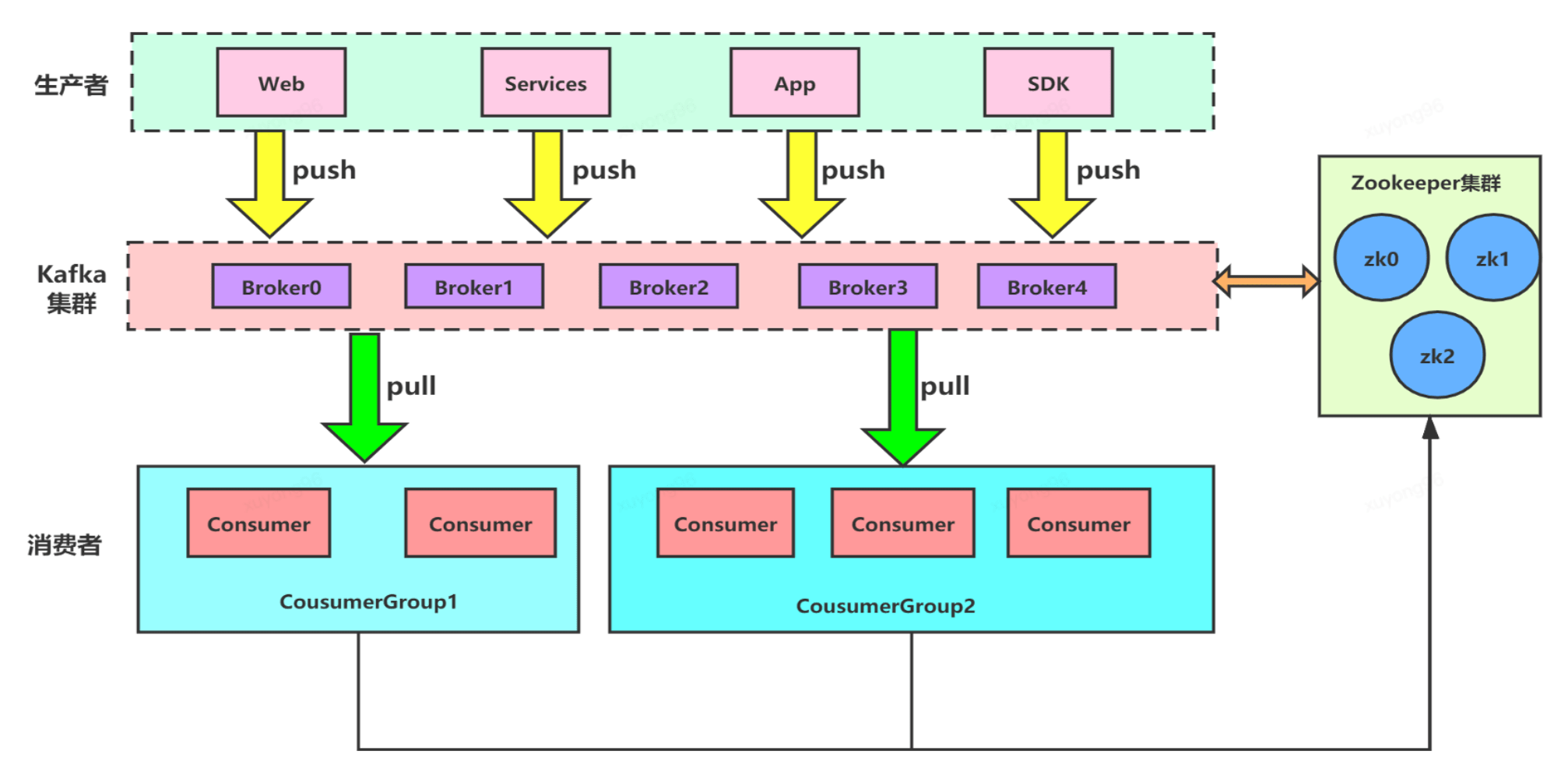
8、kafka的應(yīng)用場景(用戶注冊/異步):
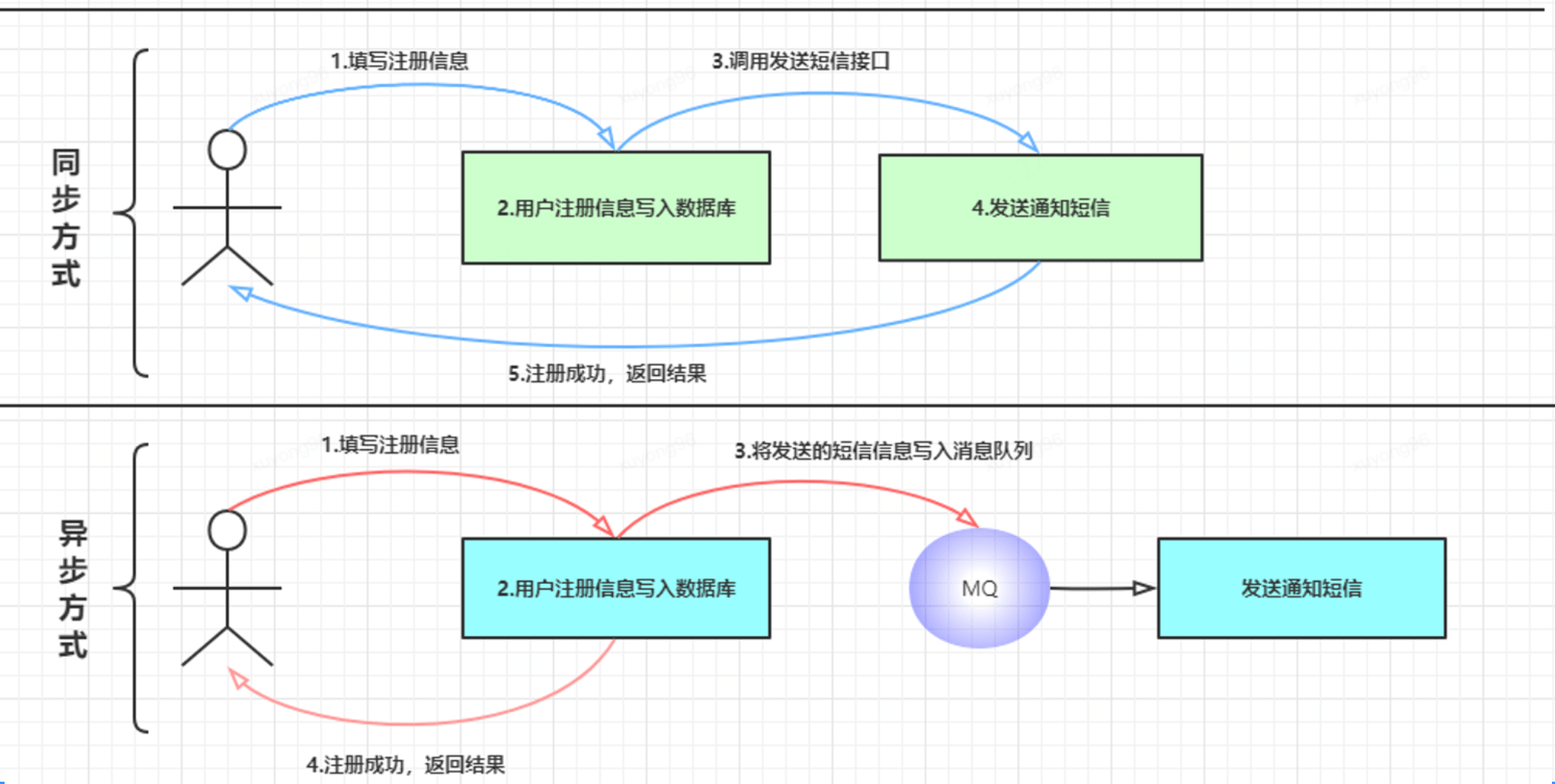
9、kafka隊(duì)列模式---點(diǎn)對點(diǎn):
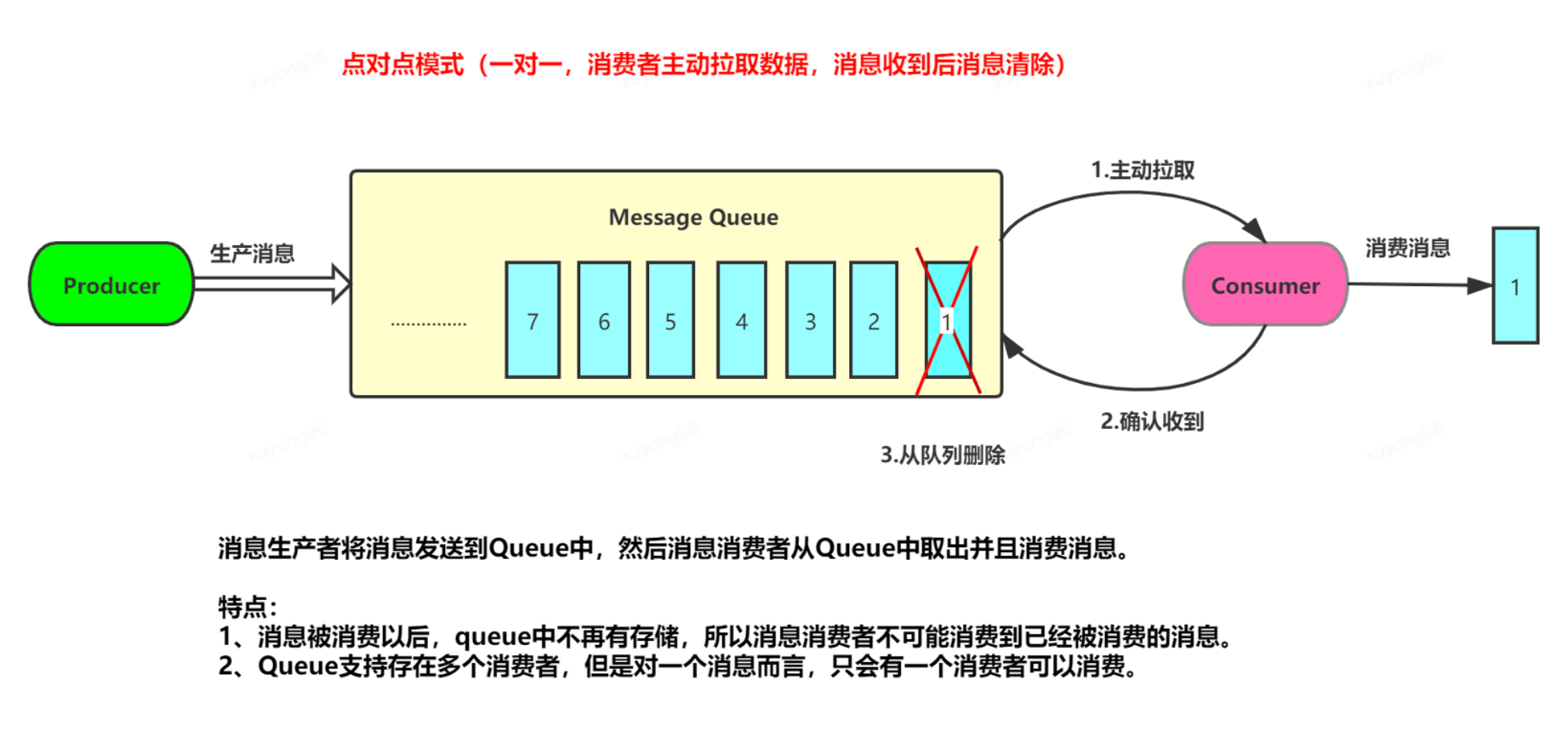
10、kafka隊(duì)列模式---發(fā)布/訂閱:
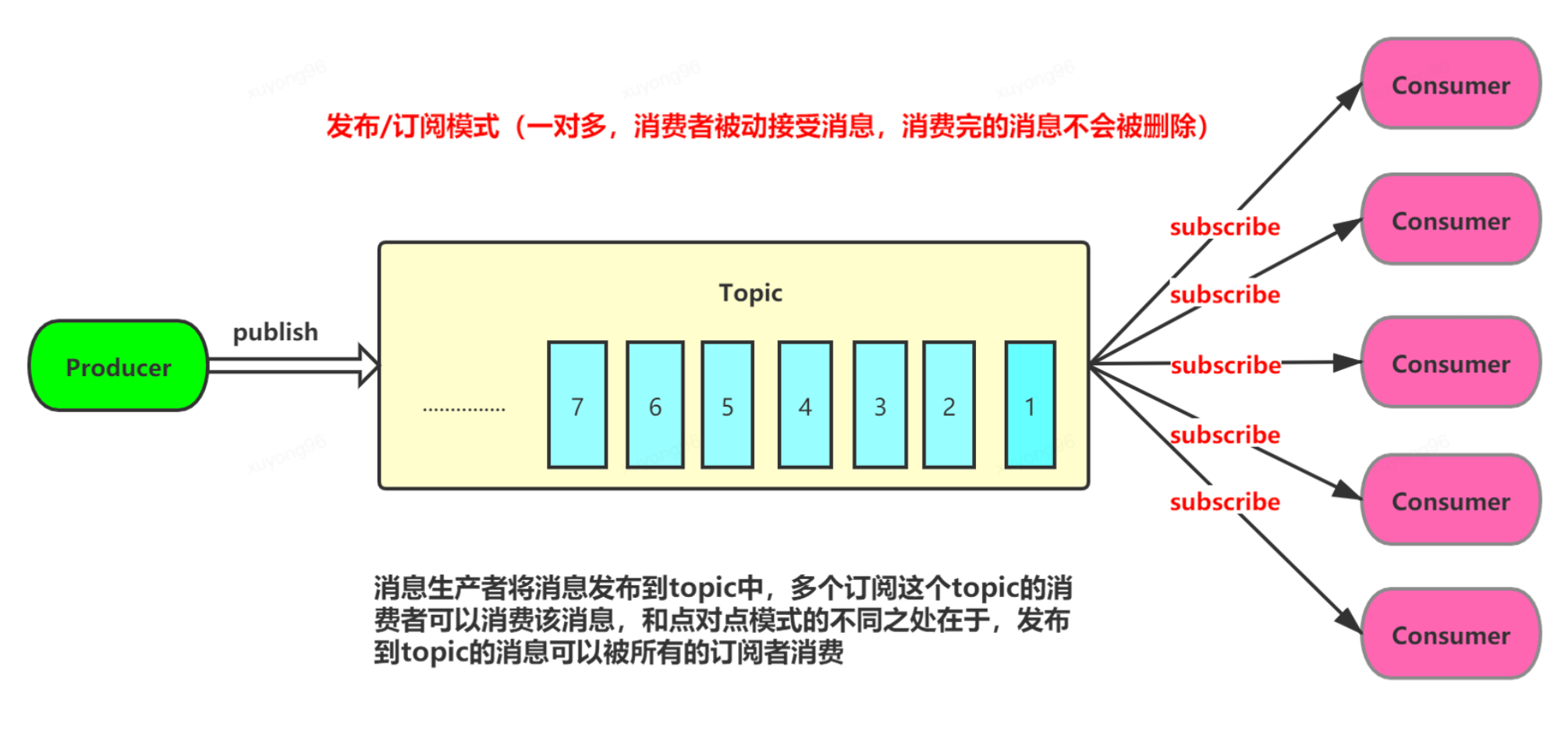
11、kafka構(gòu)成角色:
1、broker:
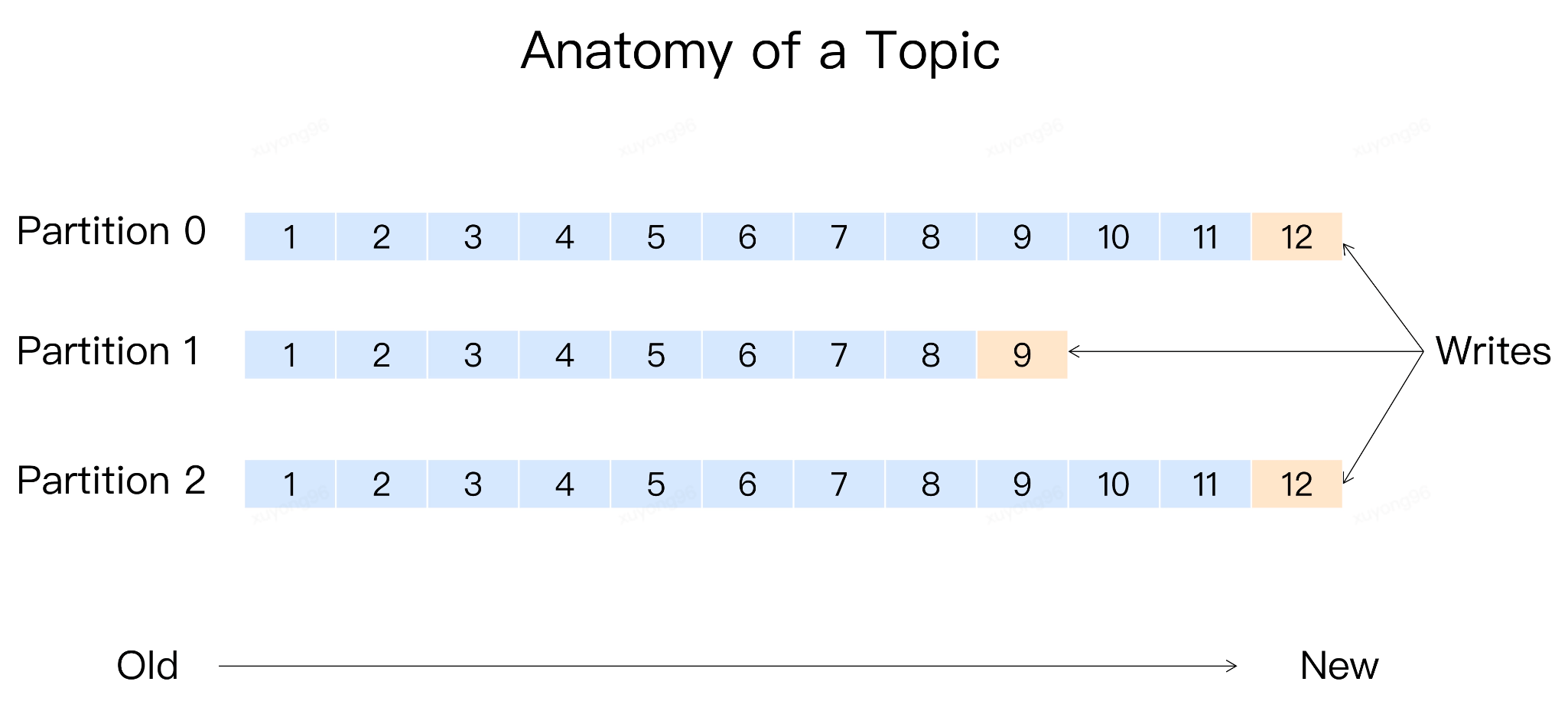
消息格式: 主題 - 分區(qū) - 消息 、主題下的每條消息只會保存在某一個(gè)分區(qū)中,而不會在多個(gè)分區(qū)中被保存多份
這樣設(shè)計(jì)的原因是:不使用多topic做負(fù)載均衡,意義在于對業(yè)務(wù)屏蔽該邏輯。業(yè)務(wù)只需要對topic進(jìn)行發(fā)送,指定負(fù)載均衡策略即可 同時(shí) topic分區(qū)是實(shí)現(xiàn)負(fù)載均衡以及高吞吐量的關(guān)鍵
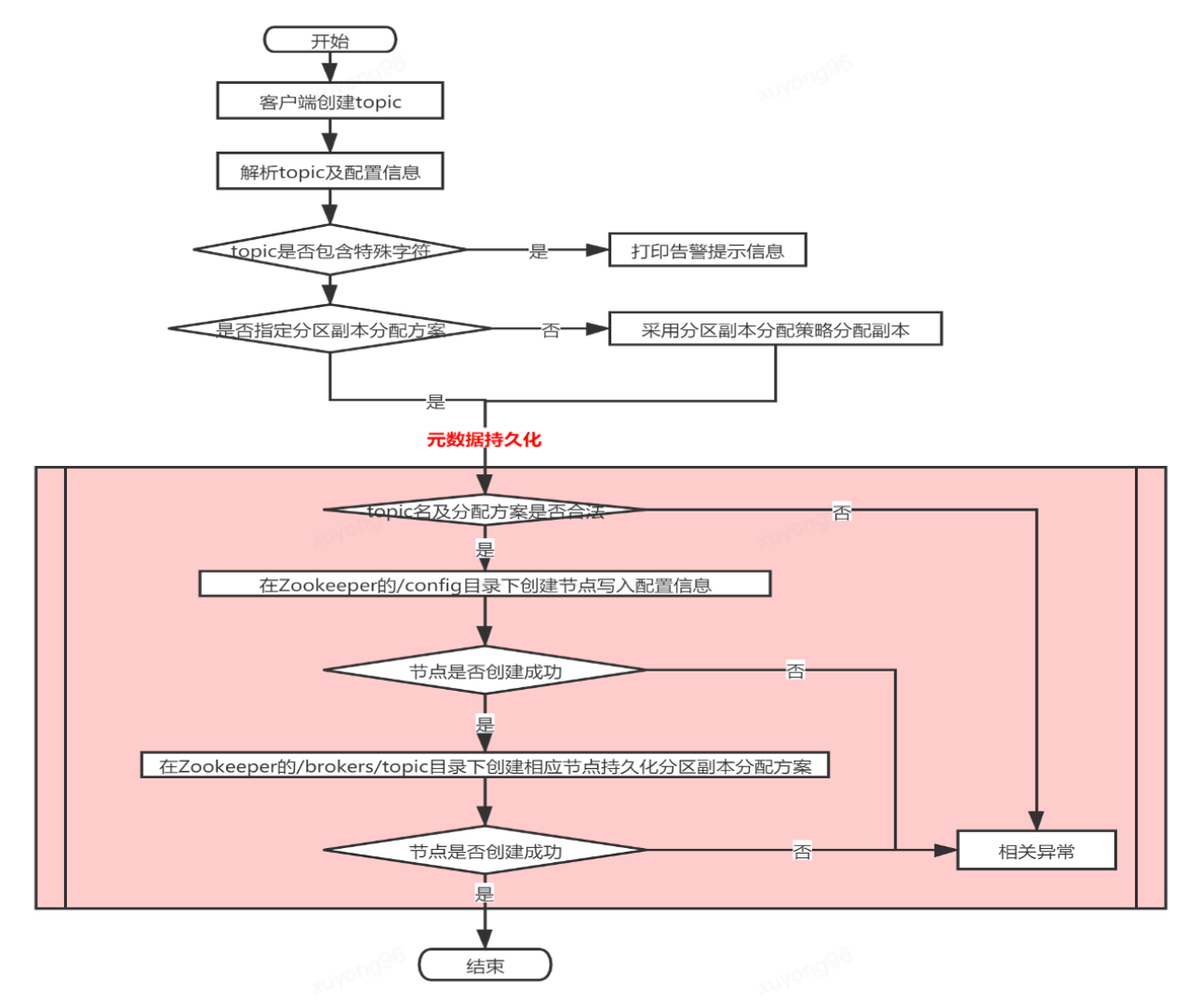
Topic的創(chuàng)建流程
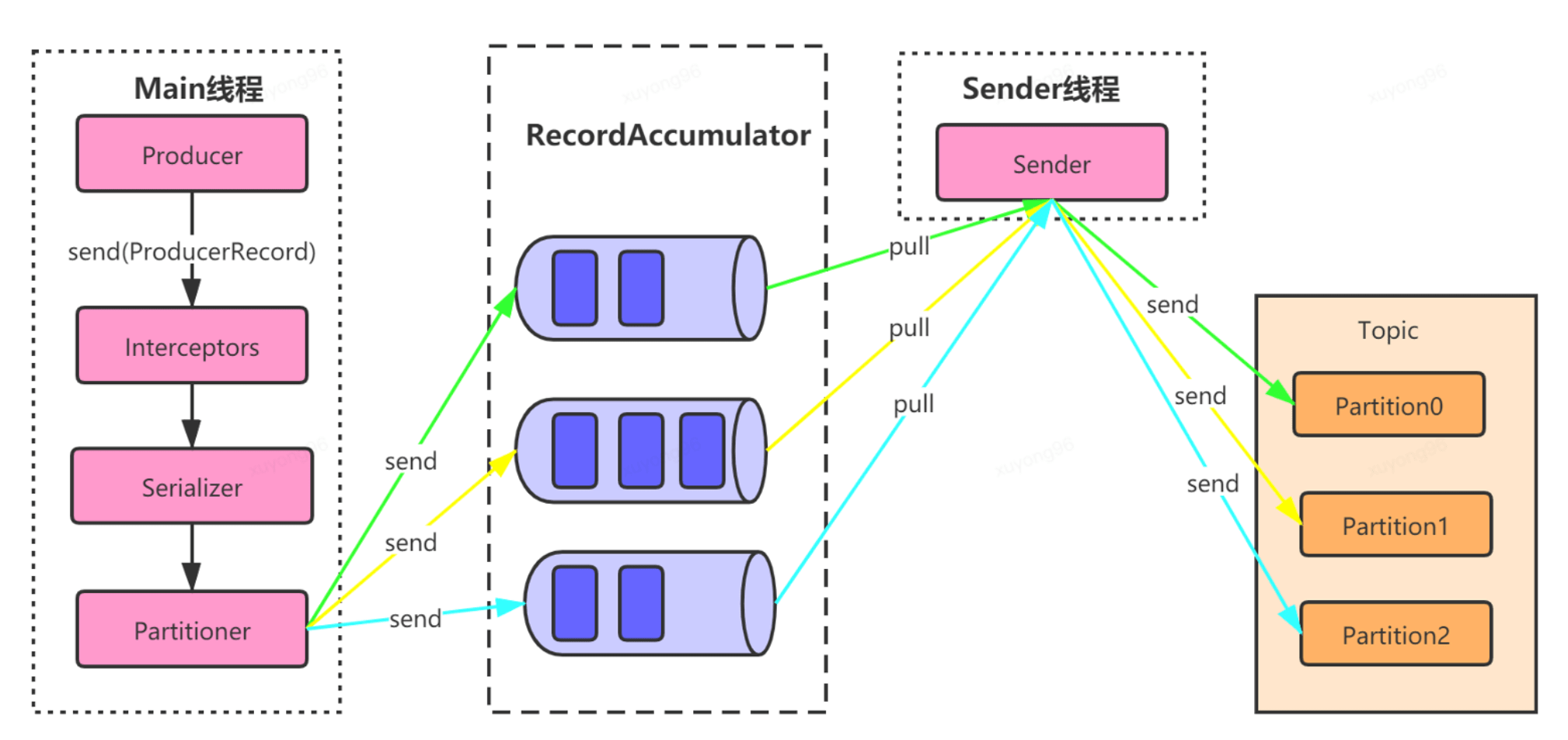
2、Producer:
發(fā)送消息流程
3、Consumer:
Kafka消費(fèi)者對象訂閱主題并接收Kafka的消息,然后驗(yàn)證消息并保存結(jié)果。Kafka消費(fèi)者是消費(fèi)者組的一部分。一個(gè)消費(fèi)者組里的消費(fèi)者訂閱的是同一個(gè)主題,每個(gè)消費(fèi)者接收主題一部分分區(qū)的消息。消費(fèi)者組的設(shè)計(jì)是對消費(fèi)者進(jìn)行的一個(gè)橫向伸縮,用于解決消費(fèi)者消費(fèi)數(shù)據(jù)的速度跟不上生產(chǎn)者生產(chǎn)數(shù)據(jù)的速度的問題,通過增加消費(fèi)者,讓它們分擔(dān)負(fù)載,分別處理部分分區(qū)的消息
4、Consumer Group:
它是kafka提供的具有可擴(kuò)展且可容錯(cuò)的消費(fèi)者機(jī)制
特性:
1、 Consumer Group下可以有一個(gè)或多個(gè) Consumer實(shí)例;
2、在一個(gè)Katka集群中,Group ID標(biāo)識唯一的一個(gè)Consumer Group;
3、 Consumer Group 下所有實(shí)例訂閱的主題的單個(gè)分區(qū),只能分配給組內(nèi)的 某個(gè)Consumer實(shí)例消費(fèi)。
Consumer Group 兩大模型:
1、如果所有實(shí)例都屬于同一個(gè)Group,那么它實(shí)現(xiàn)的是消息隊(duì)列模型;
2、如果所有實(shí)例分別屬于不同的GrouD,那么它實(shí)現(xiàn)的就是發(fā)布/訂閱模型。
12、Kafka的工作流程:
13、Kafka常用命令:

進(jìn)階
14、Kafka的文件存儲機(jī)制—log:
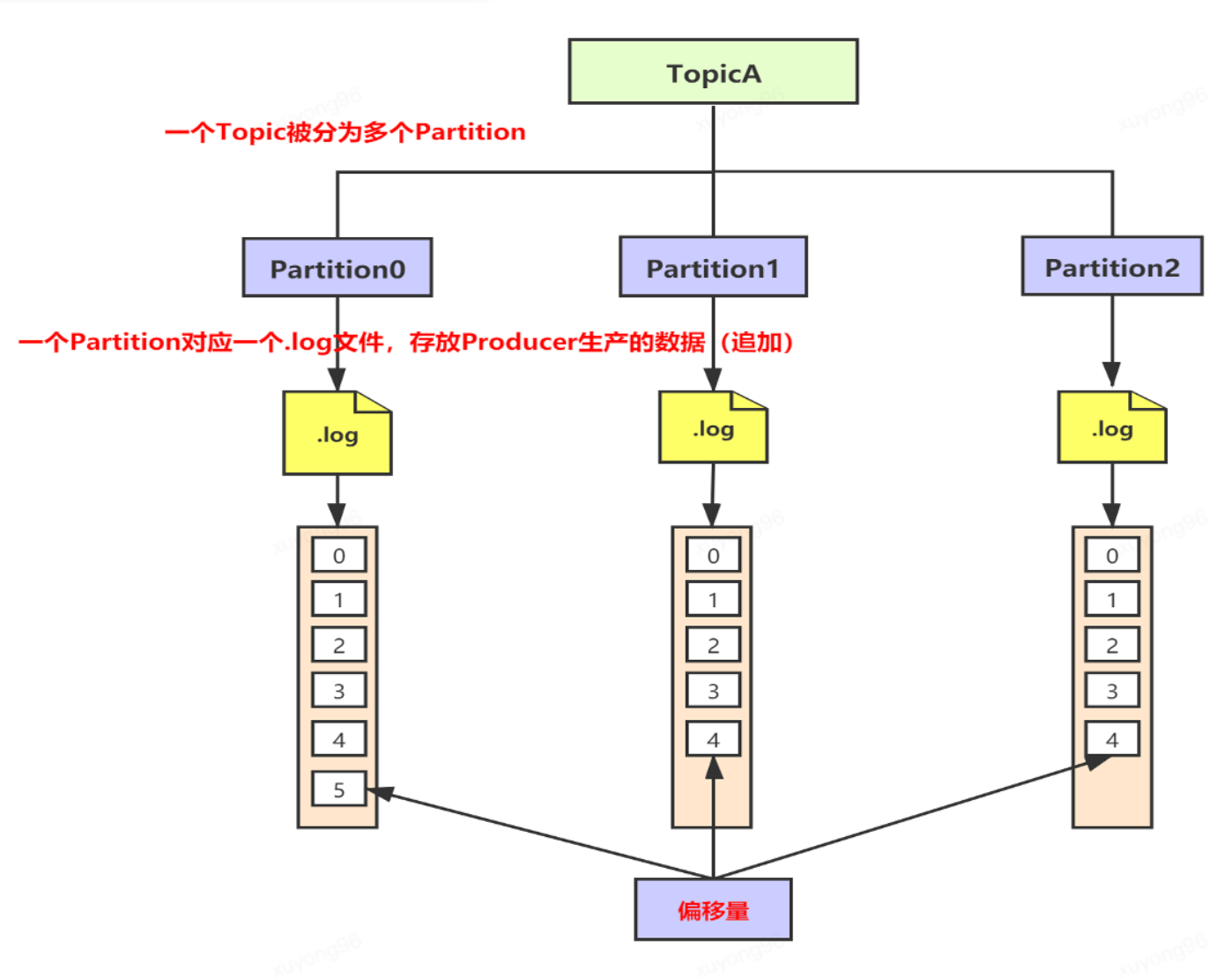
15、Kafka的文件存儲機(jī)制—分片/索引:
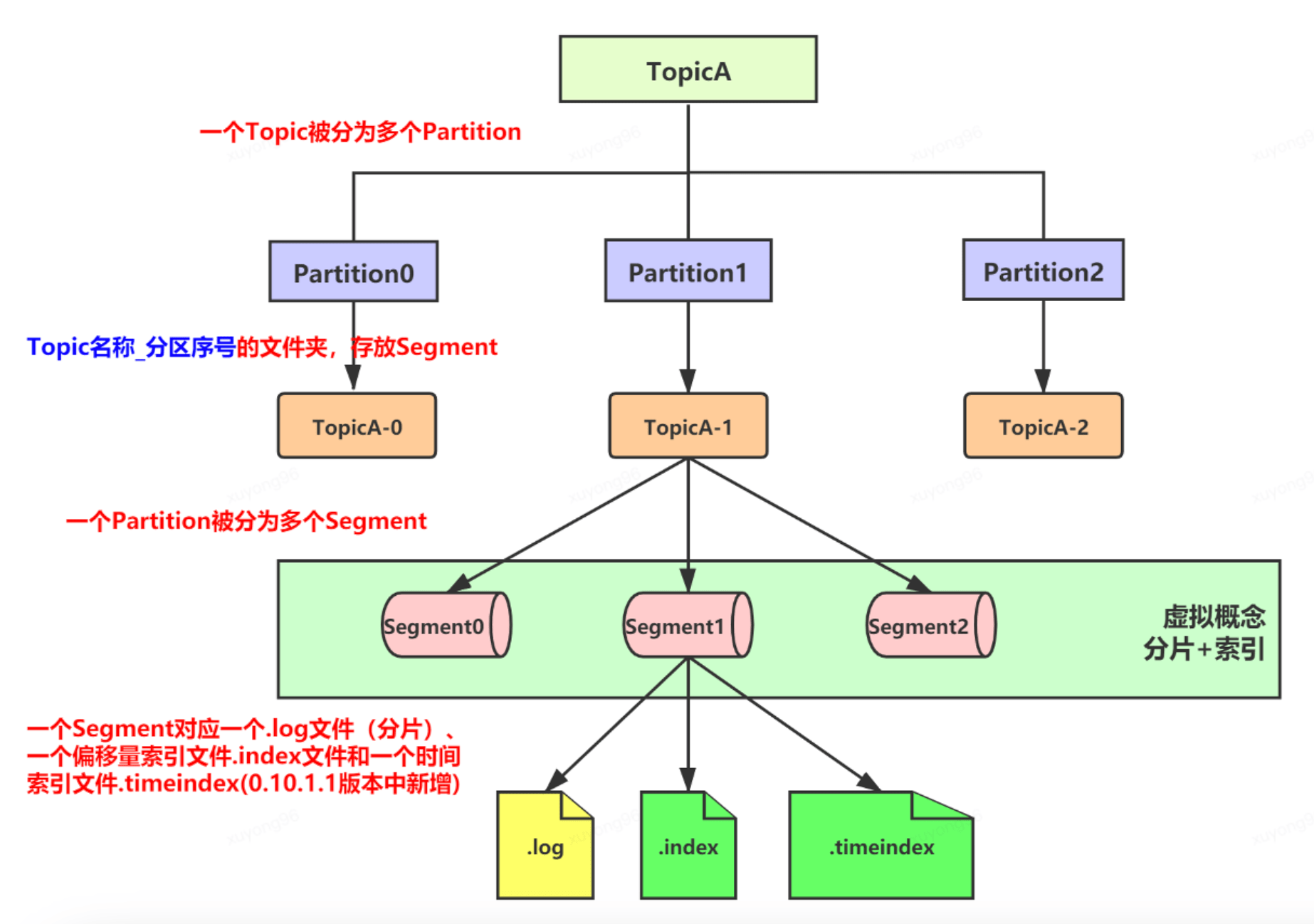
16、Kafka的文件存儲機(jī)制—index/log:
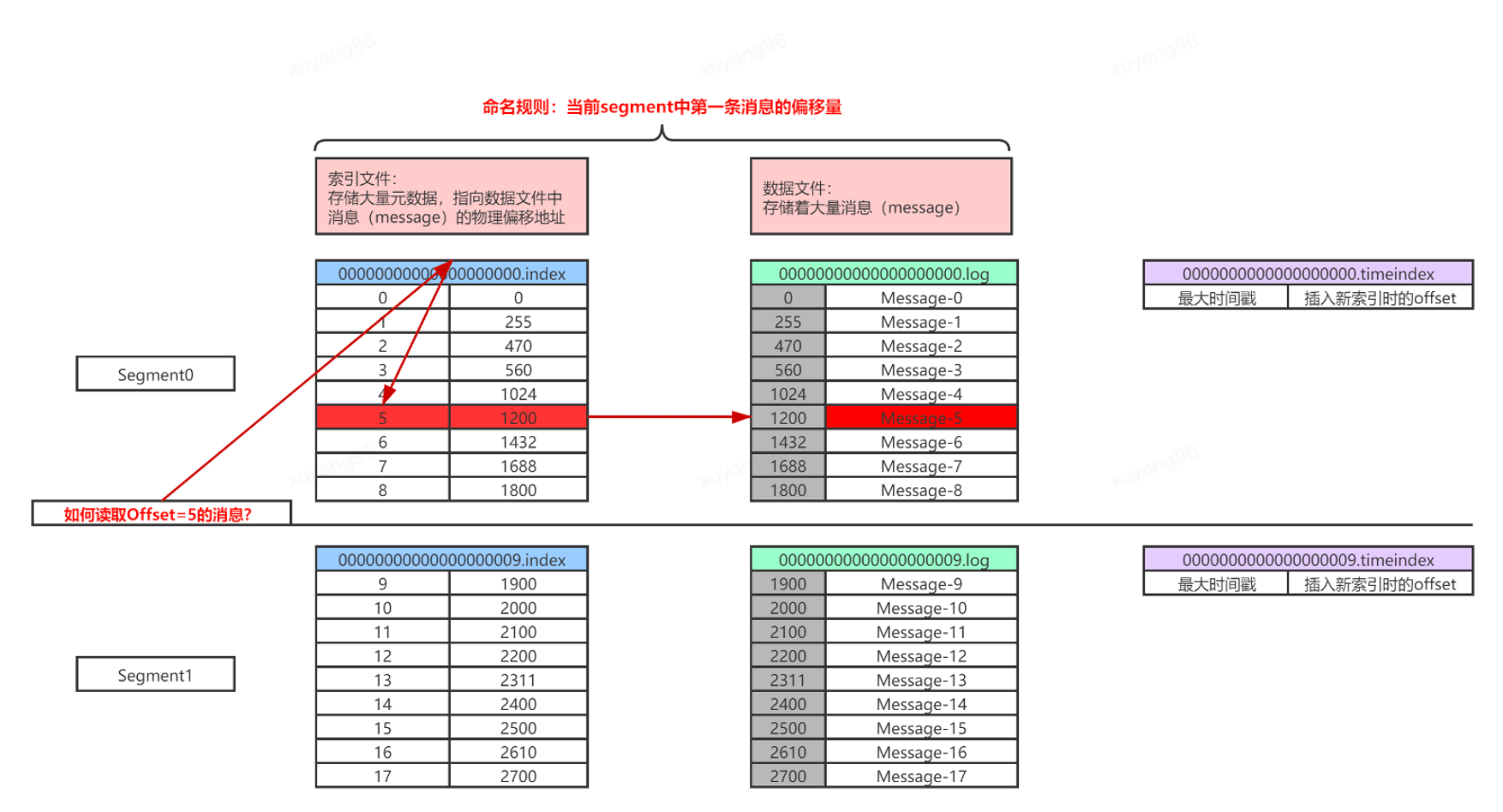
17、kafka 如何支持百萬QPS?
順序讀寫 :
生產(chǎn)者寫入數(shù)據(jù)和消費(fèi)者讀取數(shù)據(jù)都是順序讀寫的
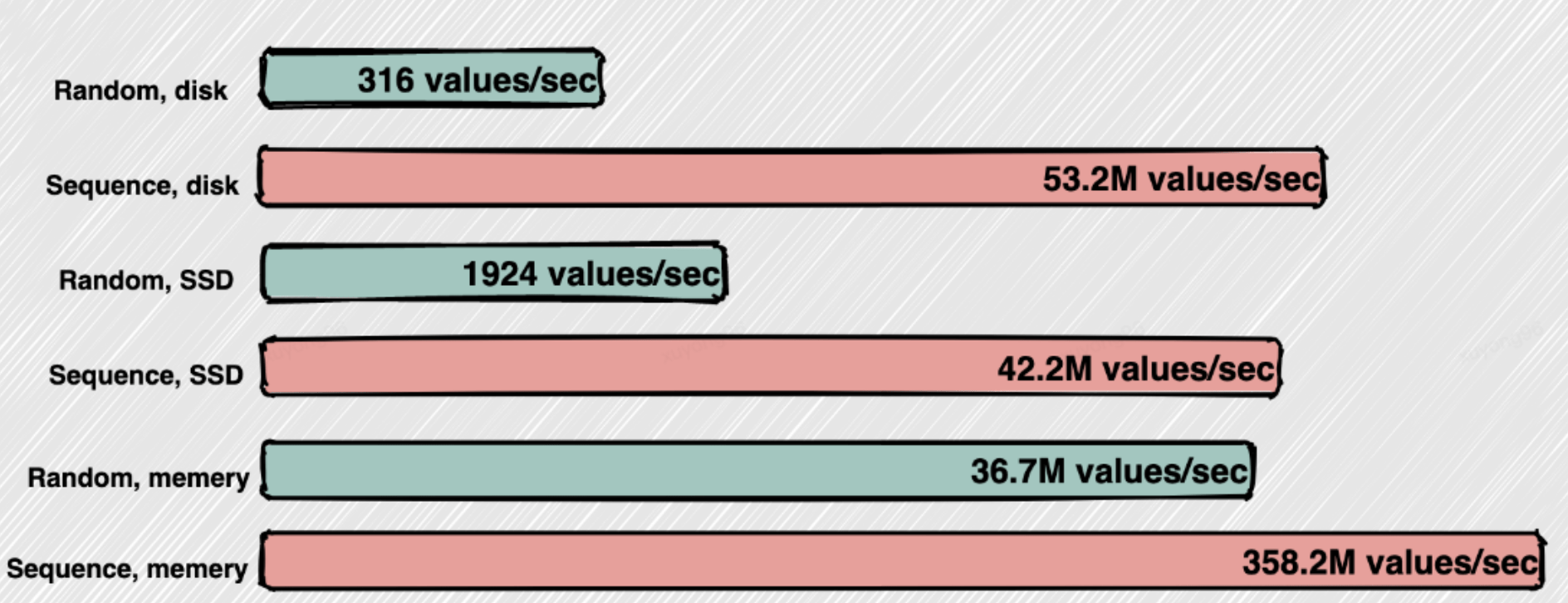
Batch Data(數(shù)據(jù)批量處理):
當(dāng)消費(fèi)者(consumer)需要消費(fèi)數(shù)據(jù)時(shí),首先想到的是消費(fèi)者需要一條,kafka發(fā)送一條,消費(fèi)者再要一條kafka再發(fā)送一條。但實(shí)際上 Kafka 不是這樣做的,Kafka 耍小聰明了。Kafka 把所有的消息都存放在一個(gè)一個(gè)的文件中,當(dāng)消費(fèi)者需要數(shù)據(jù)的時(shí)候 Kafka 直接把文件發(fā)送給消費(fèi)者。比如說100萬條消息放在一個(gè)文件中可能是10M的數(shù)據(jù)量,如果消費(fèi)者和Kafka之間網(wǎng)絡(luò)良好,10MB大概1秒就能發(fā)送完,既100萬TPS,Kafka每秒處理了10萬條消息。
MMAP(內(nèi)存映射文件):
MMAP也就是內(nèi)存映射文件,在64位操作系統(tǒng)中一般可以表示 20G 的數(shù)據(jù)文件,它的工作原理是直接利用操作系統(tǒng)的 Page 來實(shí)現(xiàn)文件到物理內(nèi)存的直接映射,完成映射之后對物理內(nèi)存的操作會被同步到硬盤上。
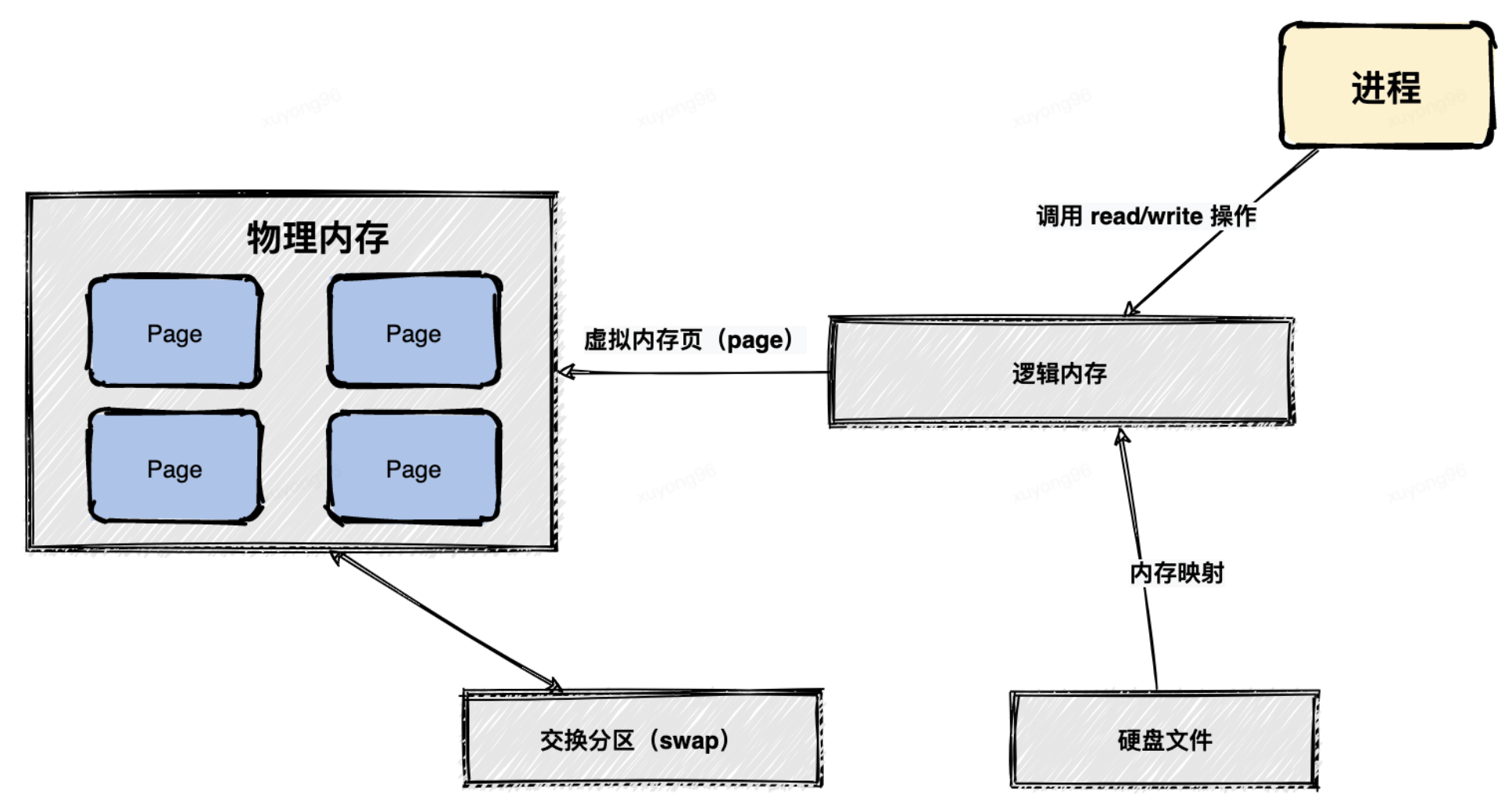
通過MMAP技術(shù)進(jìn)程可以像讀寫硬盤一樣讀寫內(nèi)存(邏輯內(nèi)存),不必關(guān)心內(nèi)存的大小,因?yàn)橛刑摂M內(nèi)存兜底。這種方式可以獲取很大的I/O提升,省去了用戶空間到內(nèi)核空間復(fù)制的開銷。也有一個(gè)很明顯的缺陷,寫到MMAP中的數(shù)據(jù)并沒有被真正的寫到硬盤,操作系統(tǒng)會在程序主動調(diào)用 flush 的時(shí)候才把數(shù)據(jù)真正的寫到硬盤。
Zero Copy(零拷貝):
如果不使用零拷貝技術(shù),消費(fèi)者(consumer)從Kafka消費(fèi)數(shù)據(jù),Kafka從磁盤讀數(shù)據(jù)然后發(fā)送到網(wǎng)絡(luò)上去,數(shù)據(jù)一共發(fā)生了四次傳輸?shù)倪^程。其中兩次是 DMA 的傳輸,另外兩次,則是通過 CPU 控制的傳輸。
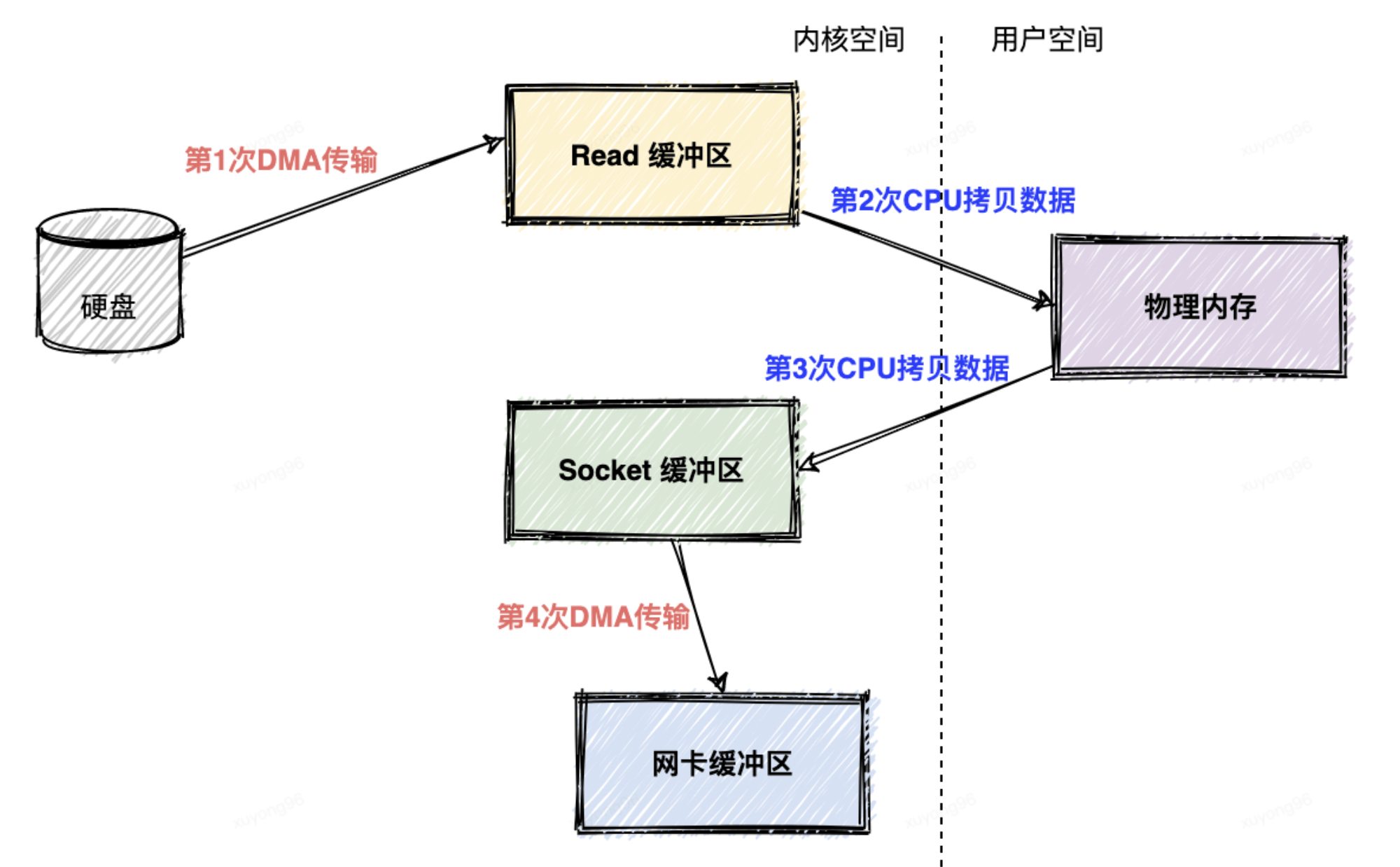
第一次傳輸:從硬盤上將數(shù)據(jù)讀到操作系統(tǒng)內(nèi)核的緩沖區(qū)里,這個(gè)傳輸是通過 DMA 搬運(yùn)的。
第二次傳輸:從內(nèi)核緩沖區(qū)里面的數(shù)據(jù)復(fù)制到分配的內(nèi)存里面,這個(gè)傳輸是通過 CPU 搬運(yùn)的。
第三次傳輸:從分配的內(nèi)存里面再寫到操作系統(tǒng)的 Socket 的緩沖區(qū)里面去,這個(gè)傳輸是由 CPU 搬運(yùn)的。
第四次傳輸:從 Socket 的緩沖區(qū)里面寫到網(wǎng)卡的緩沖區(qū)里面去,這個(gè)傳輸是通過 DMA 搬運(yùn)的。
實(shí)際上在kafka中只進(jìn)行了兩次數(shù)據(jù)傳輸,如下圖:
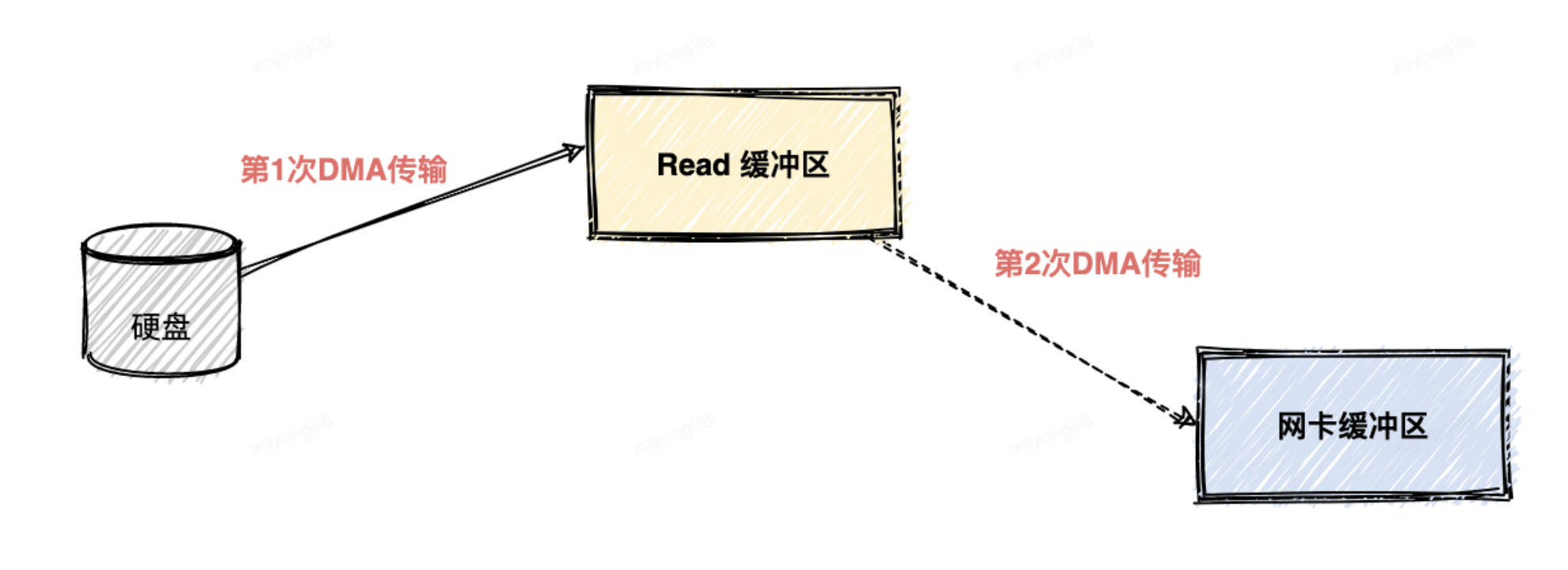
第一次傳輸:通過 DMA從硬盤直接讀到操作系統(tǒng)內(nèi)核的讀緩沖區(qū)里面。
第二次傳輸:根據(jù) Socket 的描述符信息直接從讀緩沖區(qū)里面寫入到網(wǎng)卡的緩沖區(qū)里面。
我們可以看到同一份數(shù)據(jù)的傳輸次數(shù)從四次變成了兩次,并且沒有通過 CPU 來進(jìn)行數(shù)據(jù)搬運(yùn),所有的數(shù)據(jù)都是通過 DMA 來進(jìn)行傳輸?shù)摹]有在內(nèi)存層面去復(fù)制(Copy)數(shù)據(jù),這個(gè)方法稱之為零拷貝(Zero-Copy)。
無論傳輸數(shù)據(jù)量的大小,傳輸同樣的數(shù)據(jù)使用了零拷貝能夠縮短 65%的時(shí)間,大幅度提升了機(jī)器傳輸數(shù)據(jù)的吞吐量,這也是Kafka能夠支持百萬TPS的一個(gè)重要原因
18、壓縮:
特性:
節(jié)省網(wǎng)絡(luò)傳輸帶寬以及 Kafka Broker 端的磁盤占用。
生產(chǎn)者配置 :
compression.type
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 開啟GZIP壓縮
props.put("compression.type", "gzip");
Producerproducer = new KafkaProducer<>(props)
broker開啟壓縮:
Broker 端也有一個(gè)參數(shù)叫 compression.type 默認(rèn)值為none,這意味著發(fā)送的消息是未壓縮的。否則,您指定支持的類型:gzip、snAppy、lz4或zstd。 Producer 端壓縮、Broker 端保持、Consumer 端解壓縮。
broker何時(shí)壓縮:
情況一:Broker 端指定了和 Producer 端不同的壓縮算法。(風(fēng)險(xiǎn):可能會發(fā)生預(yù)料之外的壓縮 / 解壓縮操作,表現(xiàn)為 Broker 端 CPU 使用率飆升)
想象一個(gè)對話:
Producer 說:“我要使用 GZIP 進(jìn)行壓縮。
Broker 說:“不要,我這邊接收的消息必須使用配置的 lz4 進(jìn)行壓縮
情況二: Broker 端發(fā)生了消息格式轉(zhuǎn)換 (風(fēng)險(xiǎn):涉及額外壓縮/解壓縮,且 Kafka 喪失 Zero Copy 特性)
Kafka 共有兩大類消息格式,社區(qū)分別稱之為 V1 版本和 V2 版本
為了兼容老版本的格式,Broker 端會對新版本消息執(zhí)行向老版本格式的轉(zhuǎn)換。這個(gè)過程中會涉及消息的解壓縮和重新壓縮
消息何時(shí)解壓縮:
Consumer:收到到壓縮過的消息會解壓縮還原成之前的消息。
broker:收到producer的消息 壓縮算法和自己的不一致/兼容新老版本的消息格式
壓縮算法對比:
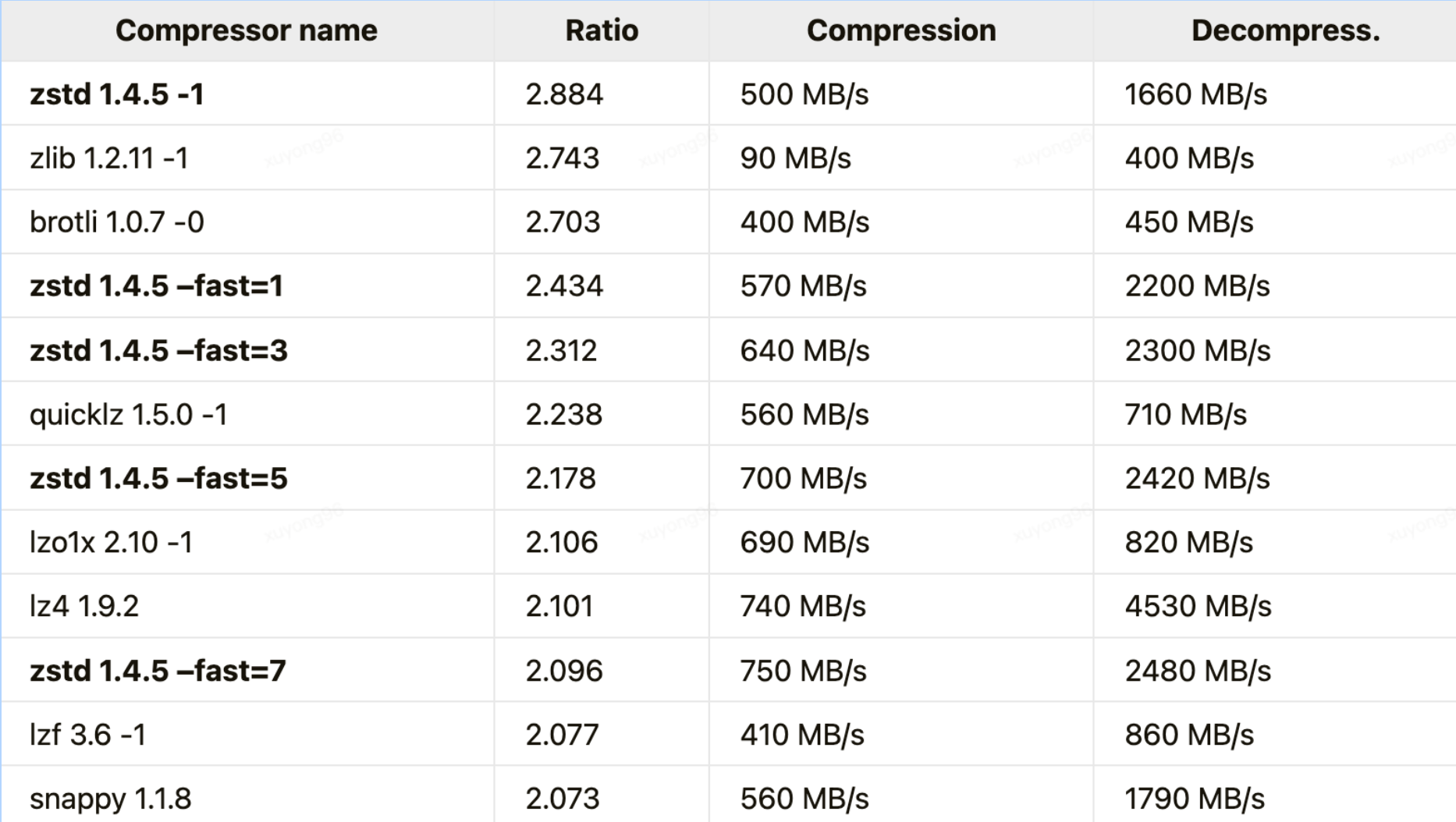
以 Kafka 為例,吞吐量方面:LZ4 > Snappy > zstd 和 GZIP;壓縮比方面,zstd > LZ4 > GZIP > Snappy;
具體到物理資源,使用 Snappy 算法占用的網(wǎng)絡(luò)帶寬最多,zstd 最少,這是合理的,畢竟 zstd 就是要提供超高的壓縮比;
在 CPU 使用率方面,各個(gè)算法表現(xiàn)得差不多,只是在壓縮時(shí) Snappy 算法使用的 CPU 較多一些,而在解壓縮時(shí) GZIP 算法則可能使用更多的 CPU;
19、Exactly-Once(ACK應(yīng)答機(jī)制):
1、At Least Once
最少發(fā)送一次,Ack級別為-1,保證數(shù)據(jù)不丟失
2、At Most Once
最多發(fā)送一次,Ack級別為1,保證數(shù)據(jù)不重復(fù)
3、冪等性
保證producer發(fā)送的數(shù)據(jù)在broker只持久化一條
4、Exactly Once(0.11版本)
At Least Once + 冪等性 = Exactly Once
要啟用冪等性,只需要將Producer的參數(shù)中 enable.idompotence設(shè)置為 true即可。 Kafka的冪等性實(shí)現(xiàn)其實(shí)就是將原來下游需要做的去重放在了數(shù)據(jù)上游。
20、producer如何獲取metadata:
1:在創(chuàng)建KafkaProducer實(shí)例時(shí) 第一步:生產(chǎn)者應(yīng)用會在后臺創(chuàng)建并啟動一個(gè)名為Sender的線程,
2:該Sender線程開始運(yùn)行時(shí),首先會創(chuàng)建與Broker的連接。 第二步:此時(shí)不知道要連接哪個(gè)Broker,kafka會通過METADATA請求獲取集群的元數(shù)據(jù),連接所有的Broker。
3:Producer 通過 metadata.max.age.ms定期更新元數(shù)據(jù),在連接多個(gè)broker的情況下,producer的InFlightsRequests中維護(hù)著每個(gè)broker的等待回復(fù)消息的隊(duì)列,等待數(shù)量越少說明broker處理速度越快,負(fù)載越小,就會發(fā)到哪個(gè)broker上
21、kafka真的會丟消息嗎?
kafka最優(yōu)配置:
Producer:
如果是JAVA客戶端 建議使用 producer.send(msg, callback) ,callback(回調(diào))它能準(zhǔn)確地告訴你消息是否真的提交成功了。
設(shè)置 acks = all。acks 是 Producer 的參數(shù),如果設(shè)置成 all,需要所有副本 Broker 都要接收到消息,該消息才算是“已提交”。這是最高等級的“已提交”定義。
設(shè)置 retries 為一個(gè)較大的值。當(dāng)出現(xiàn)網(wǎng)絡(luò)的瞬時(shí)抖動時(shí),消息發(fā)送可能會失敗,此時(shí)配置了 retries > 0 的 Producer 能夠自動重試消息發(fā)送,避免消息丟失。
Consumer:
消息消費(fèi)完成再提交。Consumer 端有個(gè)參數(shù) enable.auto.commit,最好把它設(shè)置成 false,并采用手動提交位移的方式。
broker :
設(shè)置 unclean.leader.election.enable = false。它控制的是哪些 Broker 有資格競選分區(qū)的 Leader。如果一個(gè) Broker 落后原先的 Leader 太多,那么它一旦成為新的 Leader,必然會造成消息的丟失。故一般都要將該參數(shù)設(shè)置成 false,即不允許這種情況的發(fā)生。
設(shè)置 replication.factor >= 3,目前防止消息丟失的主要機(jī)制就是冗余。
設(shè)置 min.insync.replicas > 1,控制的是消息至少要被寫入到多少個(gè)副本才算是“已提交”。設(shè)置成大于 1 可以提升消息持久性。在實(shí)際環(huán)境中千萬不要使用默認(rèn)值 1。 確保 replication.factor > min.insync.replicas。如果兩者相等,那么只要有一個(gè)副本掛機(jī),整個(gè)分區(qū)就無法正常工作了。我們不僅要改善消息的持久性,防止數(shù)據(jù)丟失,還要在不降低可用性的基礎(chǔ)上完成。推薦設(shè)置成 replication.factor = min.insync.replicas + 1。
22、kafka Replica:
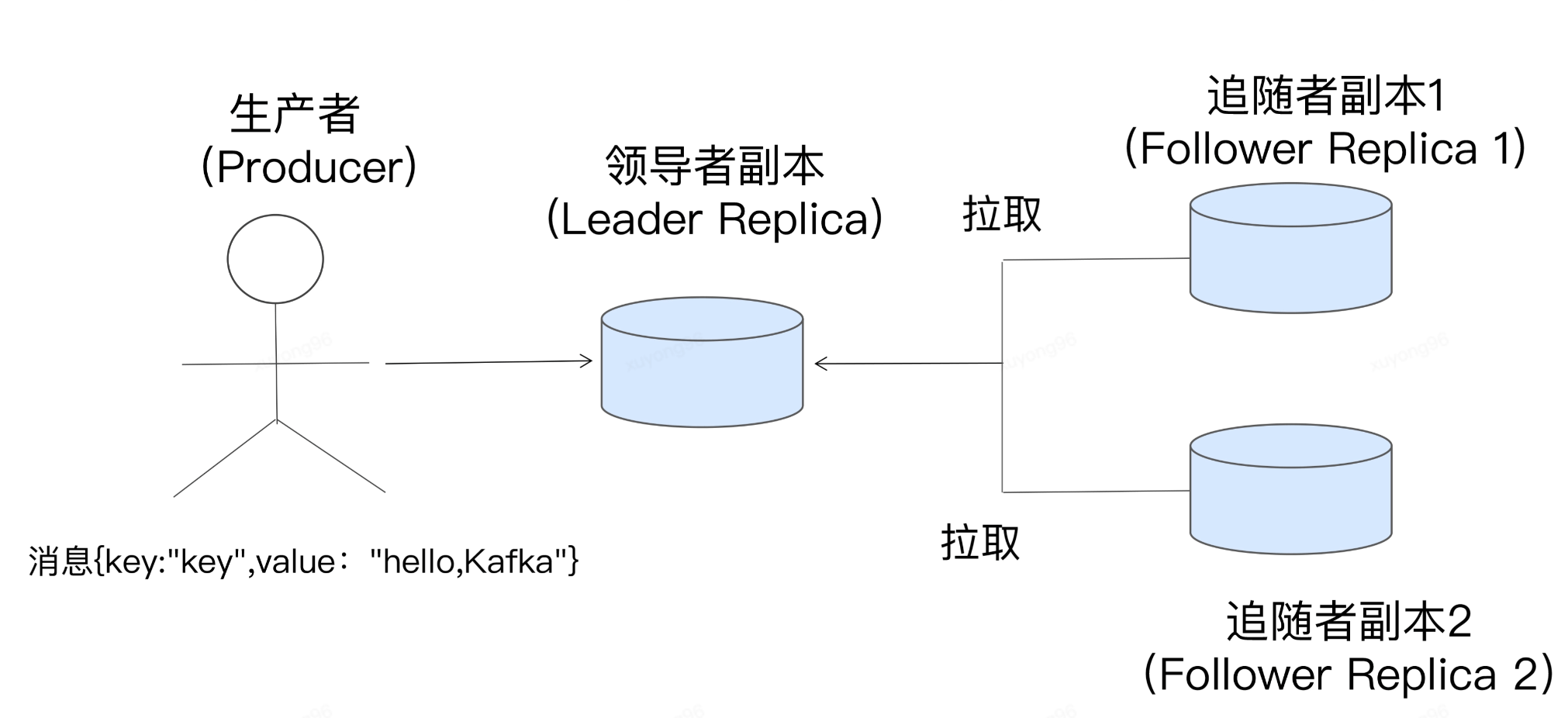
本質(zhì)就是一個(gè)只能追加寫消息的提交日志。根據(jù) Kafka 副本機(jī)制的定義,同一個(gè)分區(qū)下的所有副本保存有相同的消息序列,這些副本分散保存在不同的 Broker 上,從而能夠?qū)共糠?Broker 宕機(jī)帶來的數(shù)據(jù)不可用
3個(gè)特性:
第一,在 Kafka 中,副本分成兩類:領(lǐng)導(dǎo)者副本(Leader Replica)和追隨者副本(Follower Replica)。每個(gè)分區(qū)在創(chuàng)建時(shí)都要選舉一個(gè)副本,稱為領(lǐng)導(dǎo)者副本,其余的副本自動稱為追隨者副本。
第二,Kafka 的副本機(jī)制比其他分布式系統(tǒng)要更嚴(yán)格一些。在 Kafka 中,追隨者副本是不對外提供服務(wù)的。這就是說,任何一個(gè)追隨者副本都不能響應(yīng)消費(fèi)者和生產(chǎn)者的讀寫請求。所有的請求都必須由領(lǐng)導(dǎo)者副本來處理,或者說,所有的讀寫請求都必須發(fā)往領(lǐng)導(dǎo)者副本所在的 Broker,由該 Broker 負(fù)責(zé)處理。追隨者副本不處理客戶端請求,它唯一的任務(wù)就是從領(lǐng)導(dǎo)者副本異步拉取消息,并寫入到自己的提交日志中,從而實(shí)現(xiàn)與領(lǐng)導(dǎo)者副本的同步。
第三,當(dāng)領(lǐng)導(dǎo)者副本掛掉了,或者說領(lǐng)導(dǎo)者副本所在的 Broker 宕機(jī)時(shí),Kafka 依托于監(jiān)控功能能夠?qū)崟r(shí)感知到,并立即開啟新一輪的領(lǐng)導(dǎo)者選舉,從追隨者副本中選一個(gè)作為新的領(lǐng)導(dǎo)者。老 Leader 副本重啟回來后,只能作為追隨者副本加入到集群中。
意義: 方便實(shí)現(xiàn)“Read-your-writes”
(1)含義:當(dāng)使用生產(chǎn)者API向Kafka成功寫入消息后,馬上使用消息者API去讀取剛才生產(chǎn)的消息。 (2)如果允許追隨者副本對外提供服務(wù),由于副本同步是異步的,就可能因?yàn)閿?shù)據(jù)同步時(shí)間差,從而使客戶端看不到最新寫入的消息。 B :方便實(shí)現(xiàn)單調(diào)讀(Monotonic Reads) (1)單調(diào)讀:對于一個(gè)消費(fèi)者用戶而言,在多處消息消息時(shí),他不會看到某條消息一會存在,一會不存在。 (2)如果允許追隨者副本提供讀服務(wù),由于消息是異步的,則多個(gè)追隨者副本的狀態(tài)可能不一致。若客戶端每次命中的副本不同,就可能出現(xiàn)一條消息一會看到,一會看不到
23、ISR(In-Sync Replica Set)LEO&HW 機(jī)制:
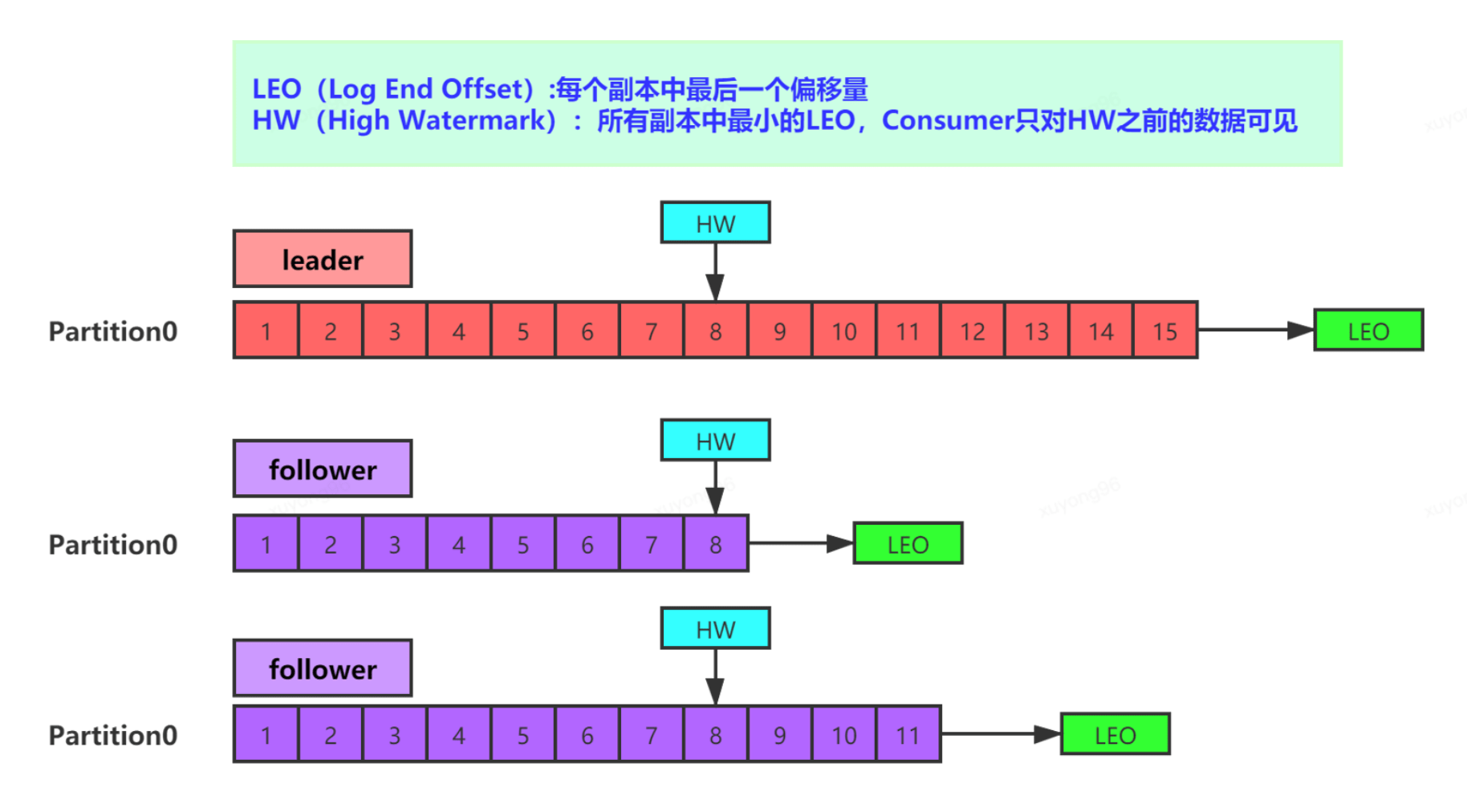
HW(High Watermark)是所有副本中最小的LEO。
比如: 一個(gè)分區(qū)有3個(gè)副本,一個(gè)leader,2個(gè)follower。producer向leader寫了10條消息,follower1從leader處拷貝了5條消息,follower2從leader處拷貝了3條消息,那么leader副本的LEO就是10,HW=3;follower1副本的LEO就是5
HW作用:保證消費(fèi)數(shù)據(jù)的一致性和副本數(shù)據(jù)的一致性 通過HW機(jī)制。leader處的HW要等所有follower LEO都越過了才會前移
ISR: 所有與leader副本保持一定程度同步的副本(包括leader副本在內(nèi))組成ISR(In-Sync Replicas)
1、Follower故障:
當(dāng)follower掛掉之后,會被踢出ISR;
當(dāng)follower恢復(fù)后,會讀取本地磁盤記錄的HW,然后截掉HW之后的部分,從HW開始從leader繼續(xù)同步數(shù)據(jù),當(dāng)該follower的LEO大于等于該partition的HW的時(shí)候,就是它追上leader的時(shí)候,會被重新加入到ISR中
2、Leader故障:
當(dāng)leader故障之后,會從follower中選出新的leader,為保證多個(gè)副本之間的數(shù)據(jù)一致性,其余的follower會將各自HW之后的部分截掉(新leader如果沒有那部分?jǐn)?shù)據(jù) follower就會截掉造成數(shù)據(jù)丟失),重新從leader開始同步數(shù)據(jù),但是只能保證副本之間的數(shù)據(jù)一致性,并不能保證數(shù)據(jù)不重復(fù)或丟失。
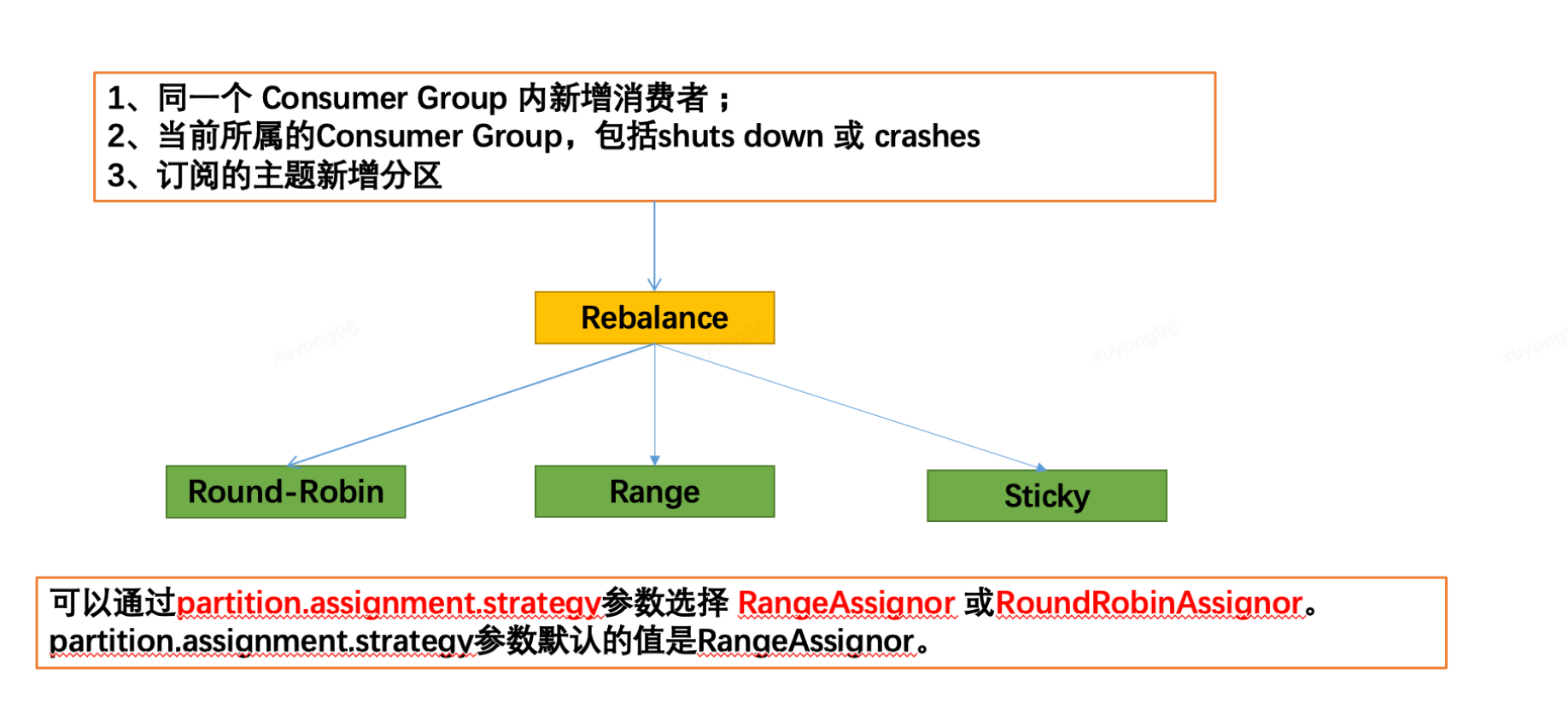
24、Consumer分區(qū)分配策略:
自定義分區(qū)策略:
你需要顯式地配置生產(chǎn)者端的參數(shù)partitioner.class。這個(gè)參數(shù)該怎么設(shè)定呢?方法很簡單,在編寫生產(chǎn)者程序時(shí),你可以編寫一個(gè)具體的類實(shí)現(xiàn)org.apache.kafka.clients.producer.Partitioner接口。這個(gè)接口也很簡單,只定義了兩個(gè)方法:partition()和close(),通常你只需要實(shí)現(xiàn)最重要的 partition 方法
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
//隨機(jī)
//return ThreadLocalRandom.current().nextInt(partitions.size());
//按消息鍵保序策略
//return Math.abs(key.hashCode()) % partitions.size();
//指定條件
return partitions.stream().filter(Predicate(指定條件))).map(PartitionInfo::partition).findAny().get();
}
25、kafka中一個(gè)不為人知的topic:
consumer_offsets:
老版本的Kafka會把位移信息保存在Zk中 ,但zk不適用于高頻的寫操作,這令zk集群性能嚴(yán)重下降,在新版本中將位移數(shù)據(jù)作為一條條普通的Kafka消息,提交至內(nèi)部主題(_consumer_offsets)中保存,實(shí)現(xiàn)高持久性和高頻寫操作。
位移主題每條消息內(nèi)容格式:Group ID,主題名,分區(qū)號
當(dāng)Kafka集群中的第一個(gè)Consumer程序啟動時(shí),Kafka會自動創(chuàng)建位移主題。也可以手動創(chuàng)建 分區(qū)數(shù)依賴于Broker端的offsets.topic.num.partitions的取值,默認(rèn)為50 副本數(shù)依賴于Broker端的offsets.topic.replication.factor的取值,默認(rèn)為3
思考:
只要 Consumer 一直啟動著,它就會無限期地向位移主題寫入消息,就算沒有新消息進(jìn)來 也會通過定時(shí)任務(wù)重復(fù)寫相同位移 最終撐爆磁盤?
Kafka 提供了專門的后臺線程定期地巡檢待 Compact 的主題,看看是否存在滿足條件的可刪除數(shù)據(jù),這個(gè)后臺線程叫 Log Cleaner,對相同的key只保留最新的一條消息。
26、Consumer Group Rebalance:
術(shù)語簡介:
Rebalance :就是讓一個(gè) Consumer Group 下所有的 Consumer 實(shí)例就如何消費(fèi)訂閱主題的所有分區(qū)達(dá)成共識的過程。
Coordinator:它專門為 Consumer Group 服務(wù),負(fù)責(zé)為 Group 執(zhí)行 Rebalance 以及提供位移管理和組成員管理等。
Consumer 端應(yīng)用程序在提交位移時(shí),其實(shí)是向 Coordinator 所在的 Broker 提交位移。同樣地,當(dāng) Consumer 應(yīng)用啟動時(shí),也是向 Coordinator 所在的 Broker 發(fā)送各種請求,然后由 Coordinator 負(fù)責(zé)執(zhí)行消費(fèi)者組的注冊、成員管理記錄等元數(shù)據(jù)管理操作。
如何確定Coordinator位置 :partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount) 比如(abs(627841412 % 50)=12 Coordinator就在 partitionId=12的Leader 副本所在的 Broker)。
Rebalance的危害:
Rebalance 影響 Consumer 端 TPS 這期間不會工作
Rebalance 很慢 Consumer越多 Rebalance時(shí)間越長
Rebalance 效率不高 需要所有成員參與
觸發(fā) Rebalance場景:
組成員數(shù)量發(fā)生變化
訂閱主題數(shù)量發(fā)生變化
訂閱主題的分區(qū)數(shù)發(fā)生變化
如何避免 Rebalance:
設(shè)置 session.timeout.ms = 15s (session連接時(shí)間 默認(rèn)10)
設(shè)置 heartbeat.interval.ms = 2s(心跳時(shí)間)
max.poll.interval.ms (取決你一批消息處理時(shí)長 默認(rèn)5分鐘)
要保證 Consumer 實(shí)例在被判定為“dead”之前,能夠發(fā)送至少 3 輪的心跳請求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
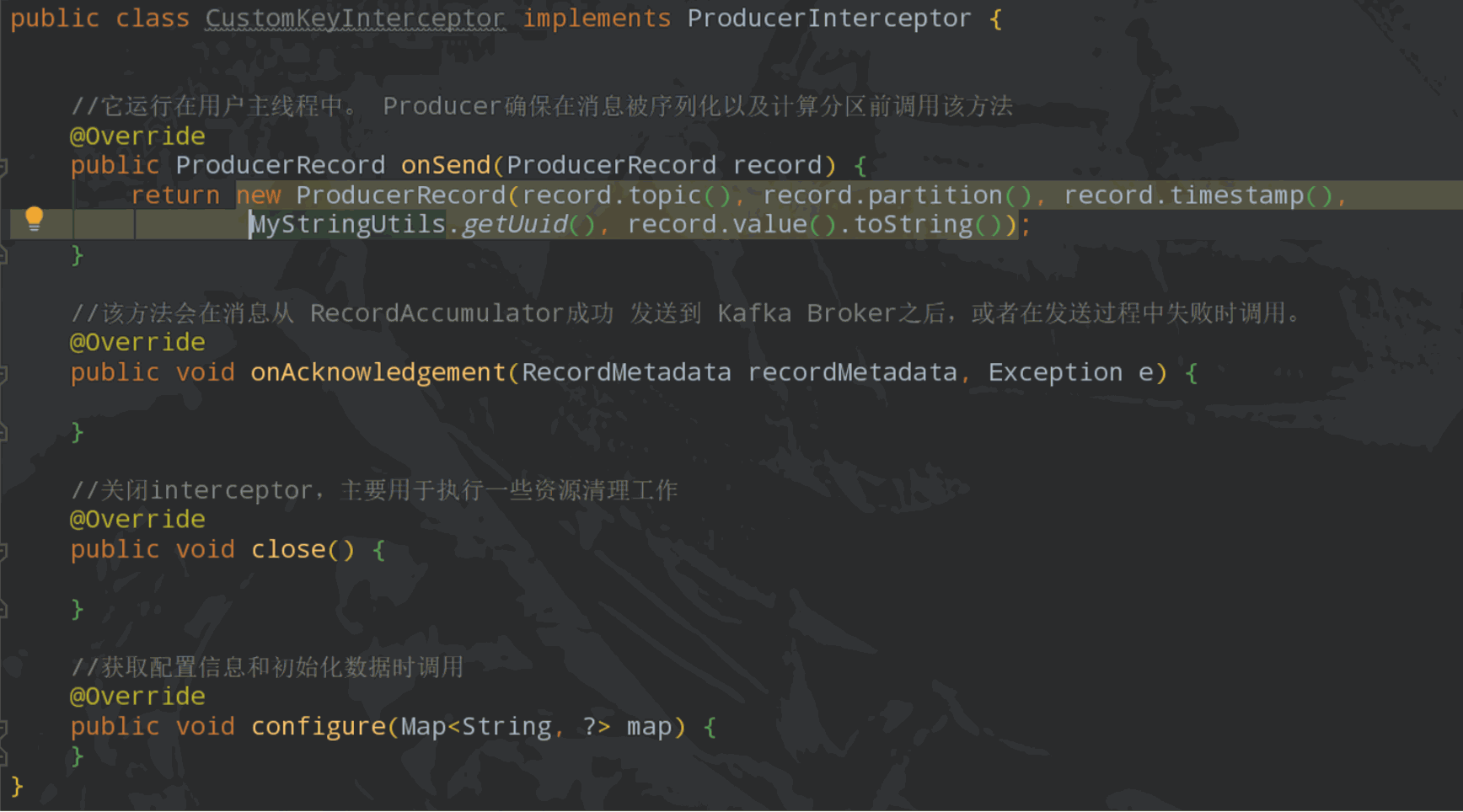
27、Kafka 攔截器:
Kafka 攔截器分為生產(chǎn)者攔截器和消費(fèi)者攔截器,可以應(yīng)用于包括客戶端監(jiān)控、端到端系統(tǒng)性能檢測、消息審計(jì)等多種功能在內(nèi)的場景。
例:生產(chǎn)者Interceptor
部分圖文資料地址
-- 極客時(shí)間 Kafka 核心技術(shù)與實(shí)戰(zhàn)





