

語言技術平臺(Language Technology Platform,LTP)是哈工大社會計算與信息檢索研究中心(HIT-SCIR)歷時多年研發的一整套高效、高精度的中文自然語言處理開源基礎技術平臺。該平臺集詞法分析(分詞、詞性標注、命名實體識別)、句法分析(依存句法分析)和語義分析(語義角色標注、語義依存分析)等多項自然語言處理技術于一體。
其中句法分析、語義分析等多項關鍵技術多次在CoNLL國際評測中獲得了第1名。此外,平臺還榮獲了2010年中國中文信息學會科學技術一等獎、2016年黑龍江省科技進步一等獎。國內外眾多研究單位和知名企業通過簽署協議以及收費授權的方式使用該平臺。
哈工大SCIR本科生馮云龍等同學在車萬翔教授指導下,于近日對LTP進行了新一輪的全面升級,并推出了LTP 4.0版本。此次升級的主要改進為:
-
基于多任務學習框架進行統一學習,使得全部六項任務可以共享語義信息,達到了知識遷移的效果。既有效提升了系統的運行效率,又極大縮小了模型的占用空間
-
基于預訓練模型進行統一的表示 ,有效提升了各項任務的準確率
-
基于教師退火模型蒸餾出單一的多任務模型,進一步提高了系統的準確率
-
基于PyTorch框架開發,提供了原生的Python調用接口,通過pip包管理系統一鍵安裝,極大提高了系統的易用性
下表列出了新舊版LTP在精度、效率和模型大小方面的對比:
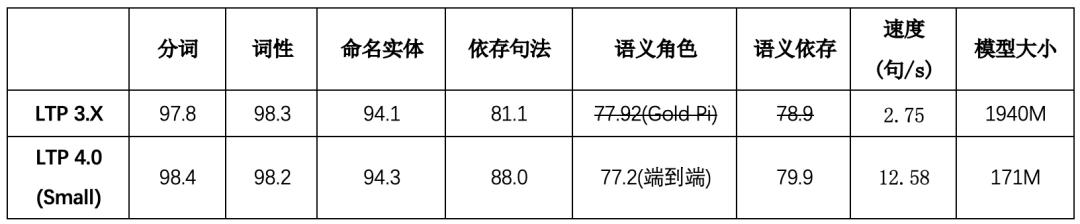
為了模型的小巧易用,本次發布的版本基于哈工大訊飛聯合實驗室發布的中文ELECTRA Small預訓練模型。后續將陸續發布基于不同預訓練模型的版本,從而為用戶提供更多準確率和效率平衡點的選擇。
測試環境如下:
-
Python 3.7
-
LTP 4.0 Batch Size = 1
-
centos 3.10.0-1062.9.1.el7.x86_64
-
Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz
備注:速度數據在人民日報命名實體測試數據上獲得,速度計算方式均為所有任務順序執行的結果。另外,語義角色標注與語義依存新舊版采用的語料不相同,因此無法直接比較(新版語義依存使用SemEval 2016語料,語義角色標注使用CTB語料)。





