機器之心編輯部
飛槳自動混合精度技術,讓你的訓練速度飛起來。
隨著生活節(jié)奏的加快,「等待」已經越來越成為人們希望遠離的事情。但是在深度學習領域,模型的參數、數據集的規(guī)模等等動輒就是以億為單位,甚至更大,因此當模型訓練成功之時,放一首張靚穎的「終于等到你」作為背景音樂實在是太應景了。
那如果現在向你推薦一款神器,可以實現訓練速度翻倍,訪存效率翻倍,你心動嗎?心動不如行動(這可不是電視直銷,別著急換頻道),來和我一起看看這款神器——基于飛槳核心框架的自動混合精度(Automatic Mixed Precision) 技術,簡稱飛槳 AMP 技術。
飛槳 AMP 技術僅僅通過一行代碼即可幫助用戶簡便快速的將單精度訓練的模型修改為自動混合精度訓練。同時通過黑白名單和動態(tài) Loss Scaling 來保證訓練的穩(wěn)定性,避免出現 INF 或者 NAN 問題。飛槳 AMP 可以充分發(fā)揮新一代 NVIDIA GPU 中 Tensor Core 的計算性能優(yōu)勢,ResNet50、Transformer 等模型的訓練速度與單精度訓練相比可以提升到 1.5~2.9 倍。
那么它是怎么實現的呢?我們先從什么是自動混合精度技術講起。
什么是自動混合精度技術
顧名思義,自動混合精度是一種自動將半精度和單精度混合使用,從而加速模型訓練的技術。其中單精度(Float Precision32,FP32)好理解,是計算機常用的一種數據類型。那么半精度是什么呢?如圖 1 所示,半精度(Float Precision16,FP16)是一種相對較新的浮點類型,在計算機中使用 2 字節(jié)(16 位)存儲,在 IEEE 754-2008 中,它被稱作 binary16。與計算中常用的單精度和雙精度類型相比,Float16 更適于在精度要求不高的場景中使用。

圖 1 半精度和單精度數據示意圖
不言而喻,在深度學習領域,如果使用 Float16 代替 Float32 來存儲數據,那么開發(fā)者就可以訓練更大更復雜的模型,使用更大的 batch size。因此對于那些恨不得挖掘出 GPU 里每一個晶體管全部潛力的科學家們怎么能放過它呢?同時由于 NVIDIA 推出了具備 Tensor Core 技術的 Volta 及 Turing 架構 GPU,使半精度計算趨向成熟。在相同的 GPU 硬件上,Tensor Core 的半精度計算吞吐量是單精度的 8 倍。
但顯而易見,使用 Float16 肯定會同時帶來計算精度上的損失。但對深度學習訓練而言,并不是所有計算都要求很高的精度,一些局部的精度損失對最終訓練效果影響很微弱,僅需要某些特殊步驟保留 Float32 的計算精度即可。因此混合精度計算的需求應運而生。我們可以將訓練過程中一些對精度損失不敏感且能使用 Tensor Core 進行加速的運算使用半精度處理,最大限度的提升訪存和計算效率。
但是對每個具體模型,人工去設計和嘗試精度混合的方法,是非常繁瑣的,我們迫切需要一種更簡潔的方式,高效地實現混合精度的訓練。AMP,顧名思義,就是讓混合精度訓練自動化,因此使用簡單是它的重要特色。具體咋用,咱們往下看!
AMP 的使用方法
下面以 MNIST 為例介紹如何使用飛槳 AMP 技術。MNIST 網絡定義的代碼如下所示。其中 conv2d、batch_norm(bn)和 pool2d 的數據布局需要提前設置為'NHWC',這樣有利于加速混合精度訓練,并且 conv2d 的輸出通道數需要設置為 4 的倍數,以便使用 Tensor Core 技術加速。
import paddle.fluid as fluiddef MNIST(data, class_dim): conv1 = fluid.layers.conv2d(data, 16, 5, 1, act=None, data_format='NHWC') bn1 = fluid.layers.batch_norm(conv1, act='relu', data_layout='NHWC') pool1 = fluid.layers.pool2d(bn1, 2, 'max', 2, data_format='NHWC') conv2 = fluid.layers.conv2d(pool1, 64, 5, 1, act=None, data_format='NHWC') bn2 = fluid.layers.batch_norm(conv2, act='relu', data_layout='NHWC') pool2 = fluid.layers.pool2d(bn2, 2, 'max', 2, data_format='NHWC') fc1 = fluid.layers.fc(pool2, size=50, act='relu') fc2 = fluid.layers.fc(fc1, size=class_dim, act='softmax') return fc2
為了訓練 MNIST 網絡,還需要定義損失函數來更新權重參數,此處使用的優(yōu)化損失函數是 SGDOptimizer。為了簡化說明,這里省略了迭代訓練的相關代碼,僅體現損失函數及優(yōu)化器定義相關的內容。
import paddle.fluid as fluidimport numpy as npdata = fluid.layers.data( name='image', shape=[None, 28, 28, 1], dtype='float32')label = fluid.layers.data(name='label', shape=[None, 1], dtype='int64')out = MNIST(data, class_dim=10)loss = fluid.layers.cross_entropy(input=out, label=label)avg_loss = fluid.layers.mean(loss)sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)sgd.minimize(avg_loss)
那么如何將上面的示例改造成使用 AMP 訓練的方式呢?用戶僅需要使用飛槳提供的 AMP 函數 fluid.contrib.mixed_precision.decorate 將原來的優(yōu)化器 SGDOptimizer 進行封裝,然后使用封裝后的優(yōu)化器(mp_sgd)更新參數梯度,代碼如下所示:
sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd)mp_sgd.minimize(avg_loss)
如上即為最簡單的飛槳 AMP 功能使用方法。
但是大家可能有些疑問,模型是如何感知哪些算子(Op)需要被轉換呢?是不是還需要手工指定呢?算子那么多,我怎么知道哪個算子可以被轉換呢?別著急,飛槳已經幫你定制好了,這也是這門技術被稱為「自動」的原因之一,且請往下看!
黑白名單功能
為了讓開發(fā)者可以方便快捷的使用混合精度計算,飛槳的工程師們使用了大量模型在不同應用場景中反復驗證,然后根據半精度數據類型計算的穩(wěn)定性和加速效果,梳理出一系列適合轉換為半精度計算的算子,并將這些算子定義到了一份白名單文件中。同時對于一些經過驗證發(fā)現不適合轉換的算子,也就是使用半精度計算會導致數值不精確的算子將被記錄到黑名單文件中。此外一些對半精度計算沒有多少影響的算子歸類于灰名單。在使用 AMP 訓練過程中,系統(tǒng)會自動讀取黑白名單,從而感知到哪些算子需要被轉換為半精度計算。
對于某些特殊場景,如果開發(fā)者希望使用自定義的黑白名單,則可以使用 AutoMixedPrecisionLists 類設置,代碼示例如下所示。
sgd = SGDOptimizer(learning_rate=1e-3)# 指定自定義的黑白名單,其中 list1 和 list2 為包含有算子名稱的列表amp_list = AutoMixedPrecisionLists(custom_white_list=list1,custom_black_list=list2)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd, amp_list)mp_sgd.minimize(avg_loss)
那么自動混合精度技術被稱為「自動」的原因之二呢?那就是下面的自動調整 Loss Scaling 功能。
自動調整 Loss Scaling
AMP 技術在提升訪存和計算效率的同時,伴隨的副作用也是很明顯的。那就是由于半精度數據類型的精度范圍與轉換前的單精度相比過窄,導致容易產生 INF 和 NAN 問題。為了避免此類問題,AMP 技術實現了自動調整 Loss Scaling 功能,即在 AMP 訓練過程中,為了避免精度下溢,每訓練一定數量批次的數據,就將 Loss 放大指定倍數。如果 Loss 在放大過程中發(fā)生上溢,則可以再縮小一定倍數,確保整個訓練過程中,梯度可以正常收斂。
fluid.contrib.mixed_precision.decorate 函數攜帶了自動調整 Loss Scaling 功能相關的參數,這些參數都帶有默認值,如下面代碼所示。這些默認值都是經過飛槳工程師多次驗證后定義的。通常情況下,用戶可以直接使用,無需重新設置。
sgd = SGDOptimizer(learning_rate=1e-3)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd, init_loss_scaling=2**15, incr_every_n_steps=2000, use_dynamic_loss_scaling=True)mp_sgd.minimize(avg_loss)
多卡 GPU 訓練的優(yōu)化
在新發(fā)布的飛槳核心框架 1.7 版本上,AMP 技術深度優(yōu)化了多卡 GPU 訓練。如圖 2 所示,在優(yōu)化之前的參數梯度更新過程中,梯度計算時雖然使用的是半精度數據類型,但是不同 GPU 卡之間的梯度傳輸數據類型仍為單精度。

圖 2 1.7 版本之前的參數梯度更新過程示意圖
為了降低 GPU 多卡之間的梯度傳輸帶寬,我們將梯度傳輸這個過程提到 Cast 操作之前,而每個 GPU 卡在得到對應的半精度梯度后再執(zhí)行 Cast 操作,將其轉變?yōu)閱尉阮愋停鐖D 3 所示。這一優(yōu)化在訓練網絡復雜度較大的模型時,對減少帶寬占用方面非常有效,如多卡訓練 BERT-Large 模型。

圖 3 1.7 版本的參數梯度更新過程示意圖
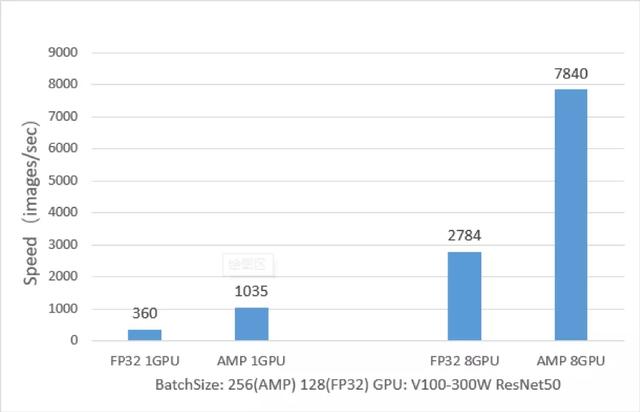
訓練性能對比(AMP VS FP32)
飛槳 AMP 技術在 ResNet50、Transformer 等模型上訓練速度相對于 FP32 訓練來說有非常大的優(yōu)勢,下面以 ResNet50 模型為例,從下圖中可以看出,ResNet50 的 AMP 訓練相對與 FP32 訓練,單卡加速比可達 2.9 倍,八卡加速比可達 2.8 倍。