
桔妹導讀:線上性能問題的定位和優化是程序員進階的必經之路,定位問題的方式有多種多樣,常見的有觀察線程棧、排查日志和做性能分析。性能分析(profile)作為定位性能問題的大殺器,它可以收集程序執行過程中的具體事件,并且對程序進行抽樣統計,從而能更精準的定位問題。本文會以 go 語言的 pprof 工具為例,分享兩個線上性能故障排查過程,希望能通過本文使大家對性能分析有更深入的理解。
在遇到線上的性能問題時,面對幾百個接口、成噸的日志,如何定位具體是哪里的代碼導致的問題呢?這篇文章會分享一下 profiling 這個定位性能問題的利器,內容主要有:
- 如何通過做 profiling 來精準定位故障源頭
- 兩個工作中通過 profiling 解決性能問題的實際例子
- 總結在做 profiling 時如何通過一些簡單的現象來快速定位問題的排查方向
- 日常 golang 編碼時要避開的一些坑
- 部分 golang 源碼解析
文章篇幅略長,也可直接翻到下面看經驗總結。
1.profiling是什么
profile 一般被稱為 性能分析,詞典上的翻譯是 概況(名詞)或者 描述…的概況(動詞)。對于計算機程序來說,它的 profile,就是一個程序在運行時的各種概況信息,包括 cpu 占用情況,內存情況,線程情況,線程阻塞情況等等。知道了程序的這些信息,也就能容易的定位程序中的問題和故障原因。
golang 對于 profiling 支持的比較好,標準庫就提供了profile庫 "runtime/pprof" 和 "net/http/pprof",而且也提供了很多好用的可視化工具來輔助開發者做 profiling。
2.兩次 profiling 線上實戰
紙上得來終覺淺,下面分享兩個在工作中實際遇到的線上問題,以及我是如何通過 profiling 一步一步定位到問題的。
▍cpu 占用 99%
某天早上一到公司就收到了線上 cpu 占用率過高的報警。立即去看監控,發現這個故障主要有下面四個特征:
- cpu idle 基本掉到了 0% ,內存使用量有小幅度增長但不嚴重;
- 故障是偶發的,不是持續存在的;
- 故障發生時3臺機器的 cpu 幾乎是同時掉底;
- 故障發生后,兩個小時左右能恢復正常。
現象如圖,上為內存,下為cpu idle:

檢查完監控之后,立即又去檢查了一下有沒有影響線上業務。看了一下線上接口返回值和延遲,基本上還都能保持正常使用,就算cpu占用 99% 時接口延時也只比平常多了幾十ms。由于不影響線上業務,所以沒有選擇立即回滾,而是決定在線上定位問題(而且前一天后端也確實沒有上線新東西)。
所以給線上環境加上了 pprof,等著這個故障自己復現。代碼如下:
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("0.0.0.0:8005", nil))
}()
// ..... 下面業務代碼不用動
}
golang 對于 profiling 的支持比較完善,如代碼所示,只需要簡單的引入 "net/http/pprof" 這個包,然后在 main 函數里啟動一個 http server 就相當于給線上服務加上 profiling 了,通過訪問 8005 這個 http 端口就可以對程序做采樣分析。
服務上開啟pprof之后,在本地電腦上使用 go tool pprof 命令,可以對線上程序發起采樣請求,golang pprof 工具會把采樣結果繪制成一個漂亮的前端頁面供人們排查問題。
等到故障再次復現時,我們首先對 cpu 性能進行采樣分析:
brew install graphviz # 安裝graphviz,只需要安裝一次就行了
go tool pprof -http=:1234 http://your-prd-addr:8005/debug/pprof/profile?seconds=30
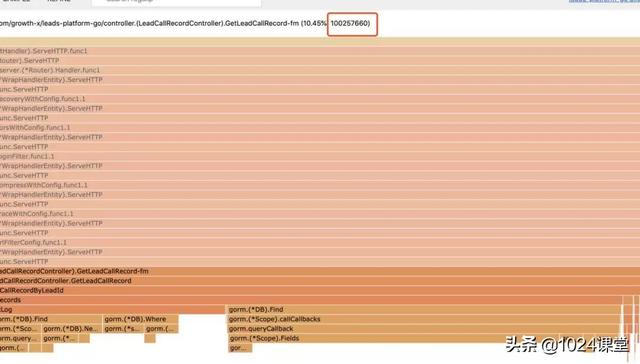
打開 terminal,輸入上面命令,把命令中的 your-prd-addr 改成線上某臺機器的地址,然后回車等待30秒后,會自動在瀏覽器中打開一個頁面,這個頁面包含了剛剛30秒內對線上cpu占用情況的一個概要分析。點擊左上角的 View 選擇 Flame graph,會用火焰圖(Flame graph)來顯示cpu的占用情況:

分析此圖可以發現,cpu 資源的半壁江山都被 GetLeadCallRecordByLeadId 這個函數占用了,這個函數里占用 cpu 最多的又大多是數據庫訪問相關的函數調用。由于 GetLeadCallRecordByLeadId 此函數業務邏輯較為復雜,數據庫訪問較多,不太好具體排查是哪里出的問題,所以我把這個方向的排查先暫時擱置,把注意力放到了右邊那另外半壁江山。
在火焰圖的右邊,有個讓我比較在意的點是 runtime.gcBgMarkWorker 函數,這個函數是 golang 垃圾回收相關的函數,用于標記(mark)出所有是垃圾的對象。一般情況下此函數不會占用這么多的 cpu,出現這種情況一般都是內存 gc 問題,但是剛剛的監控上看內存占用只比平常多了幾百M,并沒有特別高又是為什么呢?原因是影響GC性能的一般都不是內存的占用量,而是對象的數量。舉例說明,10個100m的對象和一億個10字節的對象占用內存幾乎一樣大,但是回收起來一億個小對象肯定會被10個大對象要慢很多。
插一段 golang 垃圾回收的知識,golang 使用“三色標記法”作為垃圾回收算法,是“標記-清除法”的一個改進,相比“標記-清除法”優點在于它的標記(mark)的過程是并發的,不會Stop The World。但缺點是對于巨量的小對象處理起來比較不擅長,有可能出現垃圾的產生速度比收集的速度還快的情況。gcMark線程占用高很大幾率就是對象產生速度大于垃圾回收速度了。
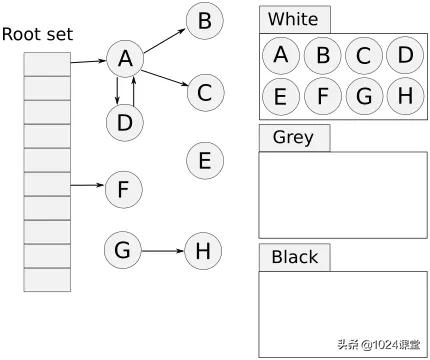
三色標記法
所以轉換方向,又對內存做了一下 profiling:
[net/http.HandlerFunc.ServeHTTP/server.go:1947] _com_request_in||traceid=091d682895eda2fsdffsd0cbe3f9a95||spanid=297b2a9sdfsdfsdfb8bf739||hintCode=||hintContent=||method=GET||host=10.88.128.40:8000||uri=/lp-api/v2/leadCallRecord/getLeadCallRecord||params=leadId={"id":123123}||from=10.0.0.0||proto=HTTP/1.0
然后在瀏覽器里點擊左上角 VIEW-》flame graph,然后點擊 SAMPLE-》inuse_objects。
這樣顯示的是當前的對象數量:
可以看到,還是 GetLeadCallRecordByLeadId 這個函數的問題,它自己就產生了1億個對象,遠超其他函數。所以下一步排查問題的方向確定了是:定位為何此函數產生了如此多的對象。
之后我開始在日志中 grep '/getLeadCallRecord' lead-platform. 來一點一點翻,重點看 cpu 掉底那個時刻附近的日志有沒有什么異常。果然發現了一條比較異常的日志:
[net/http.HandlerFunc.ServeHTTP/server.go:1947] _com_request_in||traceid=091d682895eda2fsdffsd0cbe3f9a95||spanid=297b2a9sdfsdfsdfb8bf739||hintCode=||hintContent=||method=GET||host=10.88.128.40:8000||uri=/lp-api/v2/leadCallRecord/getLeadCallRecord||params=leadId={"id":123123}||from=10.0.0.0||proto=HTTP/1.0
注意看 params 那里,leadId 本應該是一個 int,但是前端給傳來一個JSON,推測應該是前一天上線帶上去的bug。但是還有問題解釋不清楚,類型傳錯應該報錯,但是為何會產生這么多對象呢?于是我進代碼(已簡化)里看了看:
func GetLeadCallRecord(leadId string, bizType int) ([]model.LeadCallRecords, error) {
sql := "SELECT record.* FROM lead_call_record AS record " +
"where record.lead_id = {{leadId}} and record.biz_type = {{bizType}}"
conditions := make(map[string]interface{}, 2)
conditions["leadId"] = leadId
conditions["bizType"] = bizType
cond, val, err := builder.NamedQuery(sql, conditions)
發現很尷尬的是,這段遠古代碼里對于 leadId 根本沒有判斷類型,直接用 string 了,前端傳什么過來都直接當作 sql 參數了。也不知道為什么 MySQL 很抽風的是,雖然 lead_id 字段類型是bigint,在 sql 里條件用 string 類型傳參數 WHERE leadId = 'someString' 也能查到數據,而且返回的數據量很大。本身 lead_call_record 就是千萬級別的大表,這個查詢一下子返回了幾十萬條數據。又因為此接口后續的查詢都是根據這個這個查詢返回的數據進行查詢的,所以整個請求一下子就產生了上億個對象。
由于之前傳參都是正確的,所以一直沒有觸發這個問題,正好前一天前端小姐姐上線需求帶上了這個bug,一波前后端混合雙打造成了這次故障。
到此為止就終于定位到了問題所在,而且最一開始的四個現象也能解釋的通了:
- cpu idle 基本掉到了 0% ,內存使用量有小幅度增長但不嚴重;
- 故障是偶發的,不是持續存在的;
- 故障發生時3臺機器的 cpu 幾乎是同時掉底;
- 故障發生后,兩個小時左右能恢復正常。
逐條解釋一下:
- GetLeadCallRecordByLeadId 函數每次在執行時從數據庫取回的數據量過大,大量cpu時間浪費在反序列化構造對象 和 gc 回收對象上。
- 和前端確認 /lp-api/v2/leadCallRecord/getLeadCallRecord 接口并不是所有請求都會傳入json,只在某個頁面里才會有這種情況,所以故障是偶發的。
- 因為接口并沒有直接掛掉報錯,而是執行的很慢,所以應用前面的負載均衡會超時,負載均衡器會把請求打到另一臺機器上,結果每次都會導致三臺機器同時爆表。
- 雖然申請了上億個對象,但 golang 的垃圾回收器是真滴靠譜,兢兢業業的回收了兩個多小時之后,就把幾億個對象全回收回去了,而且奇跡般的沒有影響線上業務。幾億個對象都扛得住,只能說厲害了我的go。
最后捋一下整個過程:
cpu占用99% -> 發現GC線程占用率持續異常 -> 懷疑是內存問題 -> 排查對象數量 -> 定位產生對象異常多的接口 -> 定位到某接口 -> 在日志中找到此接口的異常請求 -> 根據異常參數排查代碼中的問題 -> 定位到問題
可以發現,有 pprof 工具在手的話,整個排查問題的過程都不會懵逼,基本上一直都照著正確的方向一步一步定位到問題根源。這就是用 profiling 的優點所在。
▍內存占用 90%
第二個例子是某天周會上有同學反饋說項目內存占用達到了15個G之多,看了一下監控現象如下:
- cpu占用并不高,最低idle也有85%
- 內存占用呈鋸齒形持續上升,且速度很快,半個月就從2G達到了15G
如果所示:
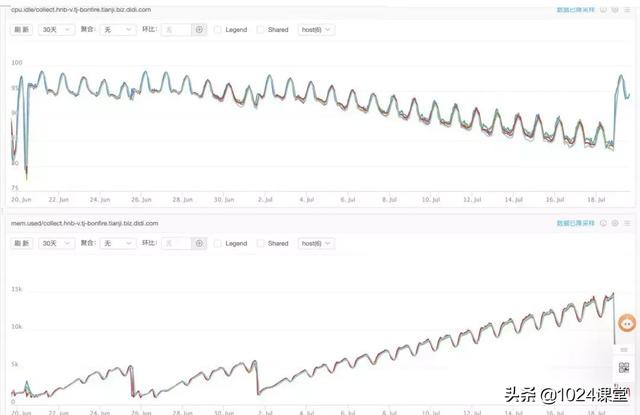
鋸齒是因為晝夜高峰平峰導致的暫時不用管,但持續上漲很明顯的是內存泄漏的問題,有對象在持續產生,并且被持續引用著導致釋放不掉。于是上了 pprof 然后準備等一晚上再排查,讓它先泄露一下再看現象會比較明顯。
這次重點看內存的 inuse_space 圖,和 inuse_objects 圖不同的是,這個圖表示的是具體的內存占用而不是對象數,然后VIEW類型也選graph,比火焰圖更清晰。
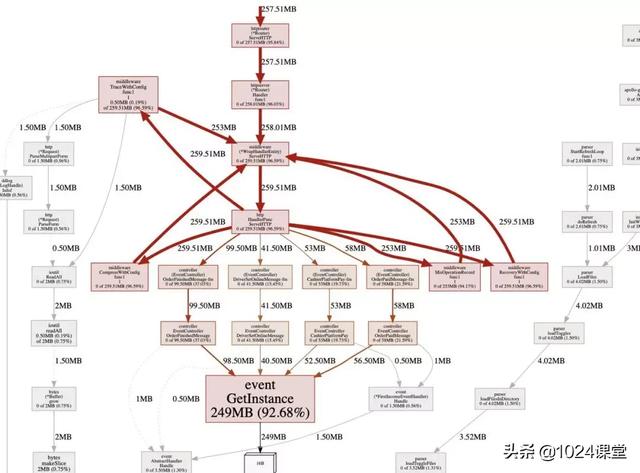
這個圖可以明顯的看出來程序中92%的對象都是由于 event.GetInstance 產生的。然后令人在意的點是這個函數產生的對象都是一個只有 16 個字節的對象(看圖上那個16B)這個是什么原因導致的后面會解釋。
先來看這個函數的代碼吧:
var (
firstActivationEventHandler FirstActivationEventHandler
firstOnlineEventHandler FirstOnlineEventHandler
)
func GetInstance(eventType string) Handler {
if eventType == FirstActivation {
firstActivationEventHandler.ChildHandler = firstActivationEventHandler
return firstActivationEventHandler
} else if eventType == FirstOnline {
firstOnlineEventHandler.ChildHandler = firstOnlineEventHandler
return firstOnlineEventHandler
}
// ... 各種類似的判斷,略過
return nil
}
這個是做一個類似單例模式的功能,根據事件類型返回不同的 Handler。但是這個函數有問題的點有兩個:
- firstActivationEventHandler.ChildHandler 是一個 interface,在給一個 interface 賦值的時候,如果等號右邊是一個 struct,會進行值傳遞,也就意味著每次賦值都會在堆上復制一個此 struct 的副本。(golang默認都是值傳遞)
- firstActivationEventHandler.ChildHandler = firstActivationEventHandler 是一個自己引用自己循環引用。
兩個問題導致了每次 GetInstance 函數在被調用的時候,都會復制一份之前的 firstActivationEventHandler 在堆上,并且讓 firstActivationEventHandler.ChildHandler 引用指向到這個副本上。
這就導致人為在內存里創造了一個巨型的鏈表:

并且這個鏈表中所有節點都被之后的副本引用著,永遠無法被GC當作垃圾釋放掉。
所以解決這個問題方案也很簡單,單例模式只需要在 init 函數里初始化一次就夠了,沒必要在每次 GetInstance 的時候做初始化操作:
func init() {
firstActivationEventHandler.ChildHandler = &firstActivationEventHandler
firstOnlineEventHandler.ChildHandler = &firstOnlineEventHandler
// ... 略過
}
另外,可以深究一下為什么都是一個 16B 的對象呢?為什么 interface 會復制呢?這里貼一下 golang runtime 關于 interface 部分的源碼:
下面分析 golang 源碼,不感興趣可直接略過。
// interface 底層定義
type iface struct {
tab *itab
data unsafe.Pointer
}
// 空 interface 底層定義
type eface struct {
_type *_type
data unsafe.Pointer
}
// 將某變量轉換為interface
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
iface 這個 struct 是 interface 在內存中實際的布局。可以看到,在golang中定義一個interface,實際上在內存中是一個 tab 指針和一個 data 指針,目前的機器都是64位的,一個指針占用8個字節,兩個就是16B。
我們的 firstActivationEventHandler 里面只有一個 ChildHandler interface,所以整個 firstActivationEventHandler 占用 16 個字節也就不奇怪了。
另外看代碼第 20 行那里,可以看到每次把變量轉為 interface 時是會做一次 mallocgc(t.size, t, true) 操作的,這個操作就會在堆上分配一個副本,第 21 行 typedmemmove(t, x, elem) 會進行復制,會復制變量到堆上的副本上。這就解釋了開頭的問題。
3.經驗總結
在做內存問題相關的 profiling 時:
- 若 gc 相關函數占用異常,可重點排查對象數量
- 解決速度問題(CPU占用)時,關注對象數量( --inuse/alloc_objects )指標
- 解決內存占用問題時,關注分配空間( --inuse/alloc_space )指標
- inuse 代表當前時刻的內存情況,alloc 代表從從程序啟動到當前時刻累計的內存情況,一般情況下看 inuse 指標更重要一些,但某些時候兩張圖對比著看也能有些意外發現。
在日常 golang 編碼時:
- 參數類型要檢查,尤其是 sql 參數要檢查(低級錯誤)
- 傳遞struct盡量使用指針,減少復制和內存占用消耗(尤其對于賦值給interface,會分配到堆上,額外增加gc消耗)
- 盡量不使用循環引用,除非邏輯真的需要
- 能在初始化中做的事就不要放到每次調用的時候做





