
近日,豆包大模型團隊攜手北京交通大學與中國科學技術大學,共同研發的視頻生成實驗模型“VideoWorld”正式宣布開源。這一創新成果在業界樹立了新的里程碑,它首次實現了無需語言模型輔助,即可實現對世界的認知。
傳統的多模態模型,如Sora、DALL-E和Midjourney等,大多依賴于語言或標簽數據來獲取知識。然而,語言作為一種表達工具,其局限性在于無法全面捕捉真實世界中的所有復雜信息。例如,折紙藝術或打領結等細致入微的技巧,往往難以通過語言進行精確描述。而VideoWorld則打破了這一限制,它摒棄了語言模型,通過純視覺信號進行統一的理解、執行和推理。
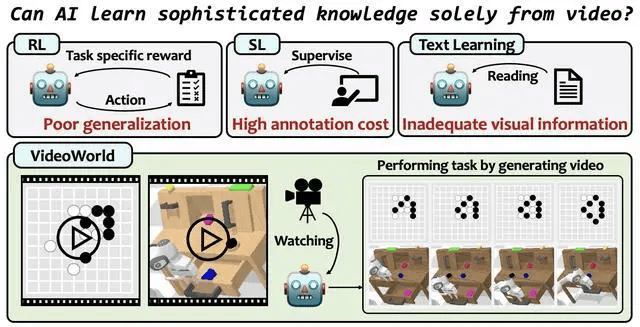
VideoWorld的核心優勢在于其獨特的潛在動態模型。這一模型能夠高效地壓縮視頻幀間的變化信息,從而顯著提升知識學習的效率和效果。這一突破性的技術使得VideoWorld在無需依賴強化學習搜索或獎勵函數機制的情況下,依然能夠達到專業級的圍棋水平——在5段9x9圍棋比賽中表現出色。它還能在多種復雜環境中執行機器人任務,展現出強大的應用潛力。
這一成果的發布,標志著視頻生成技術邁向了一個新的發展階段。VideoWorld不僅為學術界提供了新的研究方向和思路,同時也為工業界帶來了廣闊的應用前景。隨著技術的不斷成熟和完善,相信VideoWorld將在更多領域發揮重要作用,推動人工智能技術的進一步發展。





