
在全球科技界聚焦馬斯克Grok-3巨型GPU集群之際,中國的大模型技術公司正悄然加速技術創新步伐。
近期,一項名為Native Sparse Attention(NSA)的研究成果吸引了業界目光。這項技術由梁文鋒等專家親自參與研發,融合了算法與硬件的雙重優化,旨在突破長上下文建模中的計算瓶頸。NSA技術不僅成功將大語言模型處理64k長文本的速度提升了最高11.6倍,還在通用基準測試中超越了傳統全注意力模型的性能。這一突破證明,通過算法與硬件的協同創新,可以在保持模型性能的同時,極大提升長文本處理效率。
緊接著,Kimi公司也推出了自家的稀疏注意力技術——MoBA(Mixture of Block Attention)。該技術由月之暗面、清華大學及浙江大學的研究團隊共同研發,旨在將全上下文劃分為多個塊,每個查詢令牌學習關注最相關的鍵值塊,以實現高效的長序列處理。
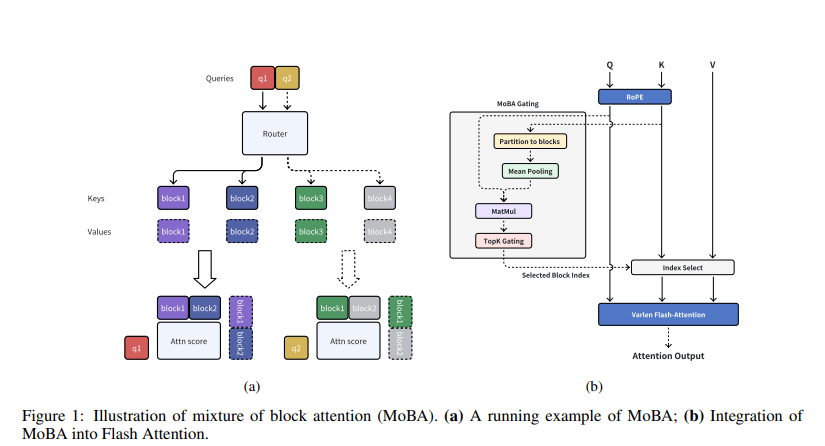
據相關論文介紹,MoBA技術在各種長文本處理任務中,能夠保持相近性能的同時,顯著降低注意力計算的時間和內存消耗。在1M token的測試中,MoBA的速度比全注意力快了6.5倍;在處理超長文本(如1000萬token)時,MoBA的優勢更加明顯,實現了16倍以上的加速。
MoBA的核心創新在于可訓練的塊稀疏注意力機制,它通過將輸入序列劃分為多個塊,每個查詢令牌動態選擇最相關的幾個塊進行注意力計算,而非傳統方法中的全局計算。MoBA還引入了無參數top-k門控機制,確保模型只關注信息量最大的部分,同時支持在全注意力和稀疏注意力模式之間無縫切換。
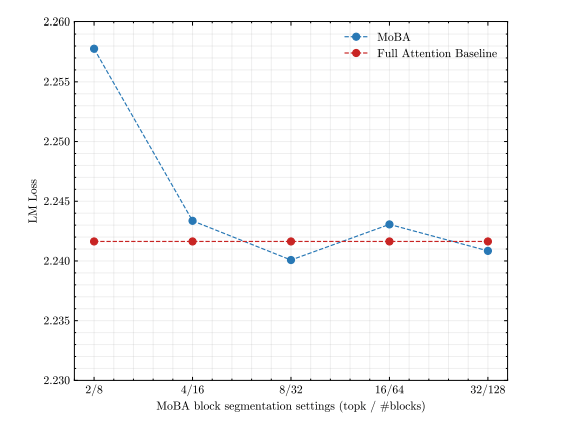
Kimi團隊對MoBA進行了全面的實驗驗證,結果顯示,盡管MoBA的注意力模式稀疏度高達81.25%,但其語言模型損失表現與全注意力相當。在長文本縮放能力實驗中,通過增加序列長度到32K,MoBA的稀疏度進一步提高到95.31%,且性能與全注意力之間的差距逐漸縮小。更細粒度的塊分割可以進一步提高MoBA的性能。
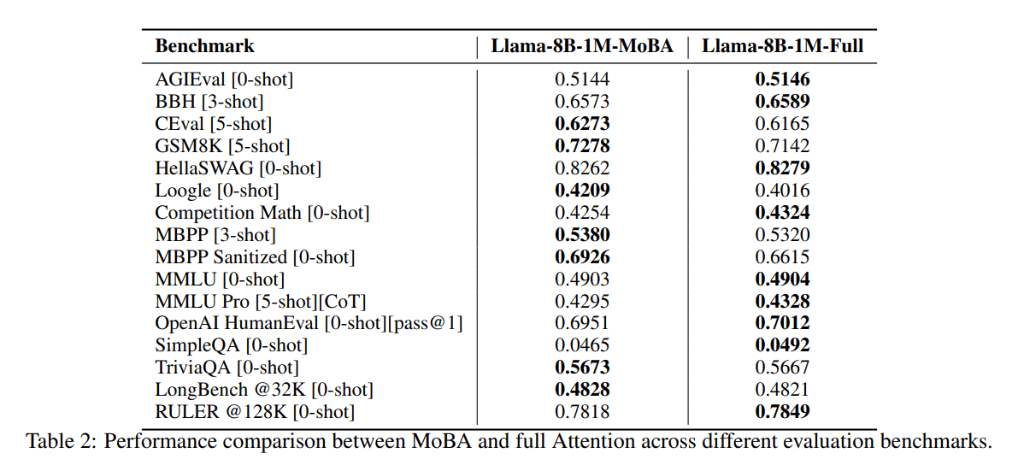
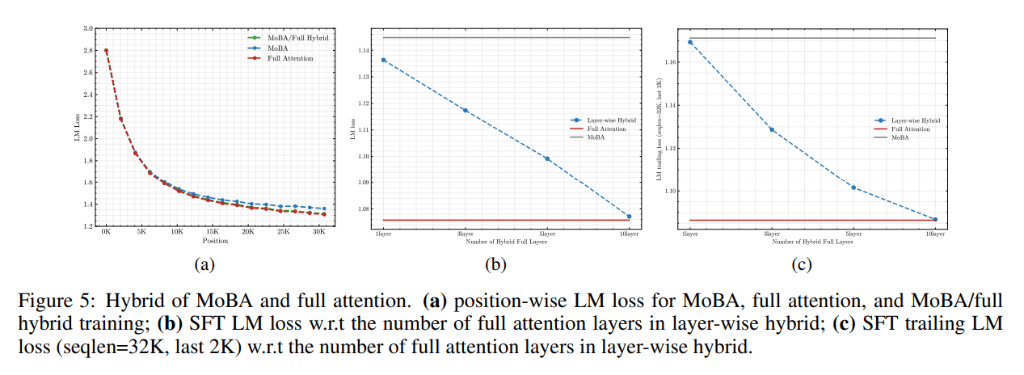
在混合訓練實驗中,Kimi團隊發現,通過結合使用MoBA和全注意力進行訓練,可以在訓練效率和模型性能之間取得平衡。在多個真實世界的下游任務中,MoBA的表現與全注意力模型相當,甚至在某些任務上略有優勢。
在處理效率和可擴展性方面,MoBA展現出了顯著優勢。實驗表明,在處理長序列時,MoBA的計算復雜度為亞平方級,比全注意力更高效。特別是在處理1000萬token的序列時,MoBA的注意力計算時間減少了16倍。
MoBA技術的推出,不僅標志著中國在稀疏注意力技術領域的重大突破,也為實現人工通用智能(AGI)提供了有力支持。隨著技術的不斷成熟和應用的不斷拓展,MoBA有望在未來的人工智能領域發揮更加重要的作用。





