在人工智能領(lǐng)域,一場圍繞大模型技術(shù)的開源競賽正愈演愈烈。就在DeepSeek發(fā)布其最新的稀疏注意力框架NSA論文后不久,另一支備受矚目的大模型團隊“月之暗面Kimi”也迅速跟進,公布了名為MoBA的論文,同樣聚焦于提升大模型在處理超長序列任務(wù)時的效率和性能。
據(jù)悉,MoBA框架旨在通過實現(xiàn)高效、動態(tài)的注意力選擇,來解決長文本處理中的效率難題。與NSA類似,MoBA也是一個稀疏注意力框架,但其最大上下文長度可擴展至驚人的10M,遠超NSA的64k限制。這一突破性的進展,無疑為長文本處理任務(wù)提供了更為強大的工具。
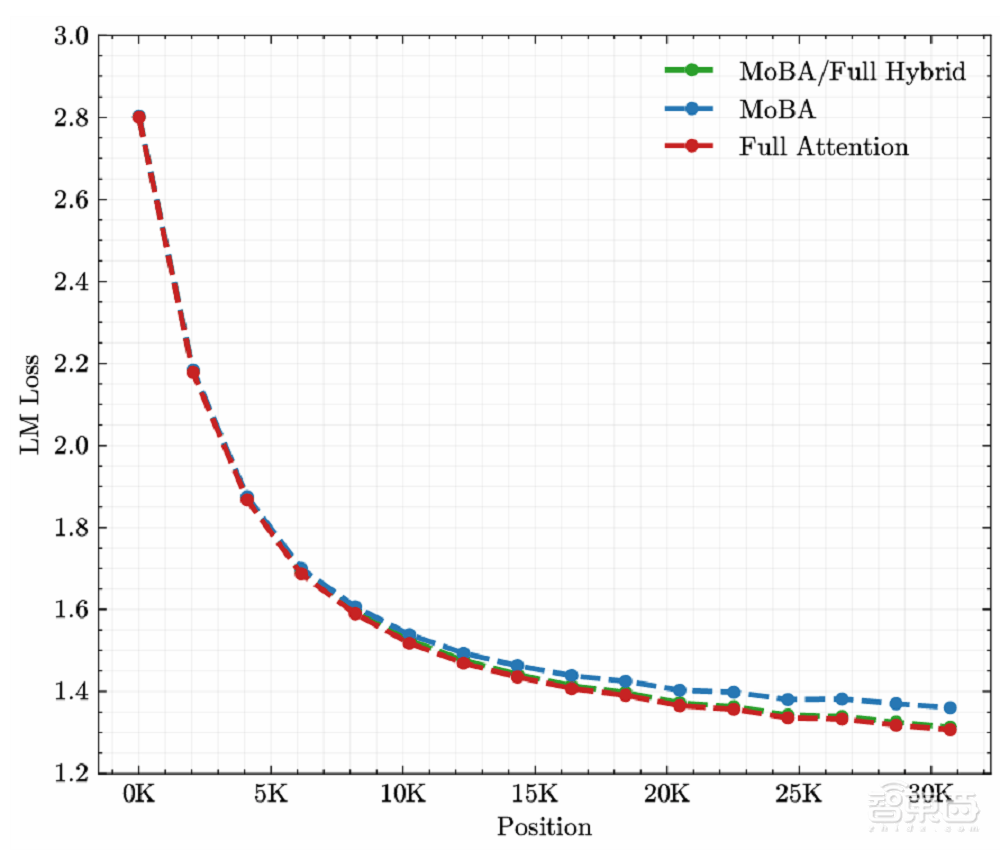
MoBA還借鑒了MoE中細粒度劃分的思想,通過增加塊的數(shù)量和減小塊的大小,模型能夠更精準(zhǔn)地捕捉局部信息,同時減少不必要的計算。這一設(shè)計使得MoBA能夠在保持與全注意力機制相當(dāng)效果的同時,顯著提升計算效率。
實驗結(jié)果表明,MoBA在處理長達100萬tokens的序列時,其速度比全注意力架構(gòu)快6.5倍;在擴展到1000萬tokens時,與標(biāo)準(zhǔn)Flash Attention相比,MoBA的計算時間實現(xiàn)了16倍的加速比。這一顯著的優(yōu)勢,使得MoBA在處理極長序列任務(wù)時具有極高的性價比。
MoBA框架還具備高度的靈活性和兼容性。它能夠在全注意力和稀疏注意力模式之間無縫切換,從而最大化與現(xiàn)有預(yù)訓(xùn)練模型的兼容性。這一特性使得MoBA能夠輕松融入現(xiàn)有的AI系統(tǒng)中,為開發(fā)者提供更為便捷和高效的解決方案。
除了MoBA框架的發(fā)布外,月之暗面團隊還面向開發(fā)者推出了一款最新的模型——Kimi Latest。這款模型旨在彌合Kimi智能助手和開放平臺之間模型的差異,為開發(fā)者提供更為穩(wěn)定和高效的AI解決方案。Kimi Latest模型支持自動上下文緩存,緩存命中的Tokens費用僅為1元/百萬tokens,大大降低了開發(fā)者的使用成本。
隨著DeepSeek、月之暗面等國內(nèi)大模型團隊的紛紛開源和技術(shù)分享,一場圍繞大模型技術(shù)的開源軍備競賽正愈演愈烈。這不僅有助于推動AI技術(shù)的快速發(fā)展和應(yīng)用落地,也為開發(fā)者提供了更為豐富和多樣的選擇。在這場競賽中,月之暗面團隊?wèi){借其創(chuàng)新的MoBA框架和Kimi Latest模型,無疑成為了備受矚目的焦點之一。