
金山云近期宣布,已經(jīng)成功適配了階躍星辰最新推出的兩款多模態(tài)大模型,為用戶帶來了前所未有的體驗。這兩款模型分別是全球參數(shù)量最大的開源視頻生成模型Step-Video-T2V,以及業(yè)界首款產(chǎn)品級開源語音交互模型Step-Audio。現(xiàn)在,用戶只需登錄金山云官方網(wǎng)站,即可輕松體驗。
在Step-Video-T2V模型的適配上,金山云憑借強大的算力支持和穩(wěn)定的運行環(huán)境,充分釋放了模型的性能,為用戶帶來了流暢的視頻生成體驗。據(jù)了解,Step-Video-T2V模型擁有高達(dá)300億的參數(shù),能夠直接生成204幀、540P分辨率的高質(zhì)量視頻。在各項評測中,該模型在指令遵循、運動平滑性、物理合理性以及美感度等方面,均顯著超越了目前市面上效果最佳的開源視頻生成模型。
為了支持Step-Video-T2V模型的多卡并行部署,階躍星辰官方提供了全面的支持。其中,文本編碼器和VAE部分由獨立的進(jìn)程維護(hù),而DiT部分則可以選擇4卡并行或8卡并行,每張卡至少需要80G的顯存。對于單臺機器的運行,推薦使用5個80G顯存的GPU。在部署方面,金山云已經(jīng)為用戶預(yù)裝好了ubuntu22.04系統(tǒng),并內(nèi)置了Step-Video-T2V模型和依賴環(huán)境的鏡像。通過金山云的云計算環(huán)境,可以精準(zhǔn)協(xié)調(diào)各卡資源,確保文本編碼器、VAE和DiT等部分協(xié)同工作,大幅提升視頻生成效率。
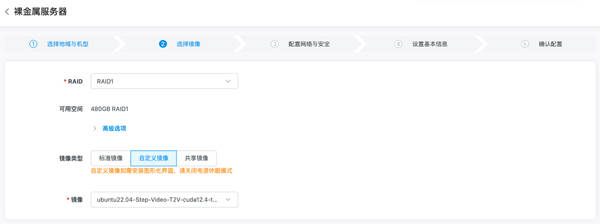
用戶只需在金山云裸金屬服務(wù)器控制臺選擇內(nèi)置Step-Video-T2V的自定義鏡像進(jìn)行創(chuàng)建,創(chuàng)建完成后即可啟動模型并使用。啟動服務(wù)也非常簡單,用戶只需登錄服務(wù)器進(jìn)入Step-Video-T2V-main目錄,運行相應(yīng)的Python腳本即可。當(dāng)看到“Running on all addresses (0.0.0.0)”的提示時,即表示服務(wù)已成功啟動。
除了Step-Video-T2V模型外,金山云還完成了實時語音對話系統(tǒng)Step-Audio模型的適配工作。通過先進(jìn)的云計算技術(shù),金山云降低了模型的響應(yīng)延遲,讓用戶與模型的對話更加自然流暢。無論是實時語音聊天還是語音指令控制,Step-Audio模型都能快速準(zhǔn)確地響應(yīng),為用戶提供優(yōu)質(zhì)的語音交互服務(wù)。Step-Audio作為業(yè)內(nèi)創(chuàng)新性的開源語音模型,能夠根據(jù)不同的場景需求生成情緒、方言、語種、歌聲和個性化風(fēng)格的表達(dá),并與用戶進(jìn)行高質(zhì)量對話。
在各項主流公開評測中,Step-Audio模型均表現(xiàn)出色,位列第一。特別是在HSK-6(漢語水平考試六級)評測中,Step-Audio模型更是展現(xiàn)出了卓越的性能,成為最懂中國話的開源語音交互大模型。
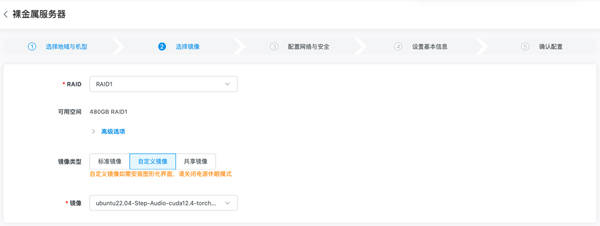
在部署方面,金山云同樣為用戶預(yù)裝好了ubuntu22.04系統(tǒng),并內(nèi)置了Step-Audio模型和依賴環(huán)境的鏡像。用戶只需在金山云裸金屬服務(wù)器控制臺選擇內(nèi)置Step-Audio的自定義鏡像進(jìn)行創(chuàng)建,創(chuàng)建完成后即可啟動模型并使用。啟動服務(wù)同樣簡單,用戶只需登錄服務(wù)器進(jìn)入Step-Audio-main目錄,運行相應(yīng)的Python腳本即可。
隨著人工智能技術(shù)的快速發(fā)展,金山云始終與前沿技術(shù)保持同步,不斷攜手生態(tài)合作伙伴,為前沿技術(shù)的落地轉(zhuǎn)化提供有力支持。通過此次對階躍星辰兩款多模態(tài)大模型的適配,金山云再次展現(xiàn)了其在云計算領(lǐng)域的強大實力和技術(shù)創(chuàng)新能力。





