
在信息安全領域,惡意軟件為了規避安全分析人員的追蹤,常常采用混淆技術來掩蓋其真實目的和運行邏輯。這一做法給安全分析帶來了巨大挑戰,傳統工具和分析方法往往力不從心,效率低下且缺乏普適性。然而,隨著人工智能技術的飛速發展,特別是Transformer模型的興起,為這一難題提供了新的解決方案。
Transformer模型最初應用于機器翻譯領域,其后發展出的大型語言模型(LLM)已經能夠勝任對話、推理等復雜任務。混淆技術的核心在于通過復雜化代碼邏輯來阻礙人類分析者的理解過程,而LLM所具備的歸納和推理能力恰好能夠應對這一挑戰,為反混淆提供了新的思路。
傳統去混淆方法主要分為靜態分析和動態分析兩類。以OLLVM為例,安全研究人員需要識別諸如控制流平坦化、指令替換、虛假控制流等混淆特征,并通過模擬執行或符號執行來還原原始代碼邏輯。這種方法不僅工程量大,而且耗時費力,每種混淆工具都需要單獨分析其特征。
相比之下,基于LLM的反混淆方法則顯得更為高效和通用。通過將多種編程語言及其去混淆方法整合到一個統一的模型中,LLM能夠自動識別和還原混淆代碼。這一方法的基本流程包括兩個步驟:首先,LLM通過大量數據訓練學習混淆特征;其次,利用LLM的推理能力提取原始代碼邏輯。這一過程不僅大大減輕了人工分析的負擔,還提高了去混淆的準確性和效率。
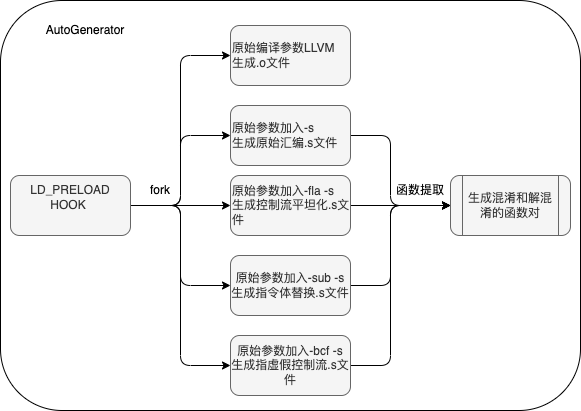
為了訓練這一模型,研究人員開發了一個名為AutoGenerator的工具。該工具通過LD_PRELOAD技術注入到編譯器中,提取編譯參數并生成未混淆的代碼以及多種混淆變體。這些代碼被用作訓練數據,用于微調LLM模型。經過大量數據的訓練,模型在去混淆任務上取得了顯著成效。
在實際應用中,研究人員對微調后的模型進行了初步測試。結果顯示,模型在14組未訓練的代碼上去混淆的準確率高達90%以上,明顯優于傳統GPT模型的表現。這一成果不僅證明了LLM在去混淆領域的潛力,也為二進制安全研究提供了新的工具和方法。


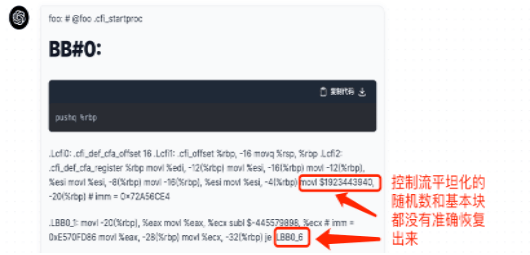

LLM在逆向工程領域也展現出巨大潛力。逆向工程需要從低級語言(如匯編)轉換到高級語言(如C語言),這一過程中往往存在信息缺失的問題。而LLM在預訓練階段已經學習了大量知識,能夠彌補這一信息缺失,提高逆向工程的準確性和效率。
隨著大型語言模型技術的不斷發展,其在信息安全領域的應用前景愈發廣闊。未來,我們有望看到更多基于LLM的安全工具和方法涌現,為二進制安全研究和實踐注入新的活力。





