
在人工智能領域,一場關于具身智能的革命正在悄然進行。近日,兩大創新成果相繼亮相,引發了業界的廣泛關注。Figure公司推出的Helix模型,以其分層架構實現了高頻控制與高泛化能力的雙重突破。幾乎同時,中國的靈初智能團隊也不甘落后,發布了基于強化學習的Psi R0.5模型,距離其前作Psi R0的問世僅僅相隔兩個月。
Psi R0.5不僅在復雜場景的泛化性、靈巧性、思維鏈(CoT)以及長程任務能力上實現了顯著提升,更在數據利用效率上展現了驚人的實力。據透露,完成泛化抓取訓練所需的數據量僅為Helix的0.4%,這一數據無疑在全球范圍內樹立了泛化靈巧操作與訓練效率的新標桿。
靈初智能團隊還連續發布了四篇高質量論文,詳細闡述了團隊在高效泛化抓取、堆疊場景物品檢索、利用外部環境配合抓取以及VLA安全對齊方面的最新研究成果。這些論文不僅展示了中國團隊在具身智能領域的強大實力,更為全球研究者提供了寶貴的參考。
Psi R0.5的路徑演進圖清晰地展示了其從初步構想到最終實現的整個歷程。其中,DexGraspVLA作為首個用于靈巧手通用抓取的VLA框架,通過少量的訓練即可在多變環境下智能涌現出靈巧操作能力,其表現令人矚目。
DexGraspVLA框架融合了視覺、語言和動作三個層次,高層規劃由預訓練的大型視覺語言模型實現,可理解多樣化指令并自主決定抓取策略;低層控制器則通過實時視覺反饋閉環掌握目標物體,智能涌現出靈巧操作能力。整個框架的核心在于將多樣化的圖像輸入數據通過現有的Foundation Model轉換成Domain-invariance的表征,并端到端地訓練下層控制模型。
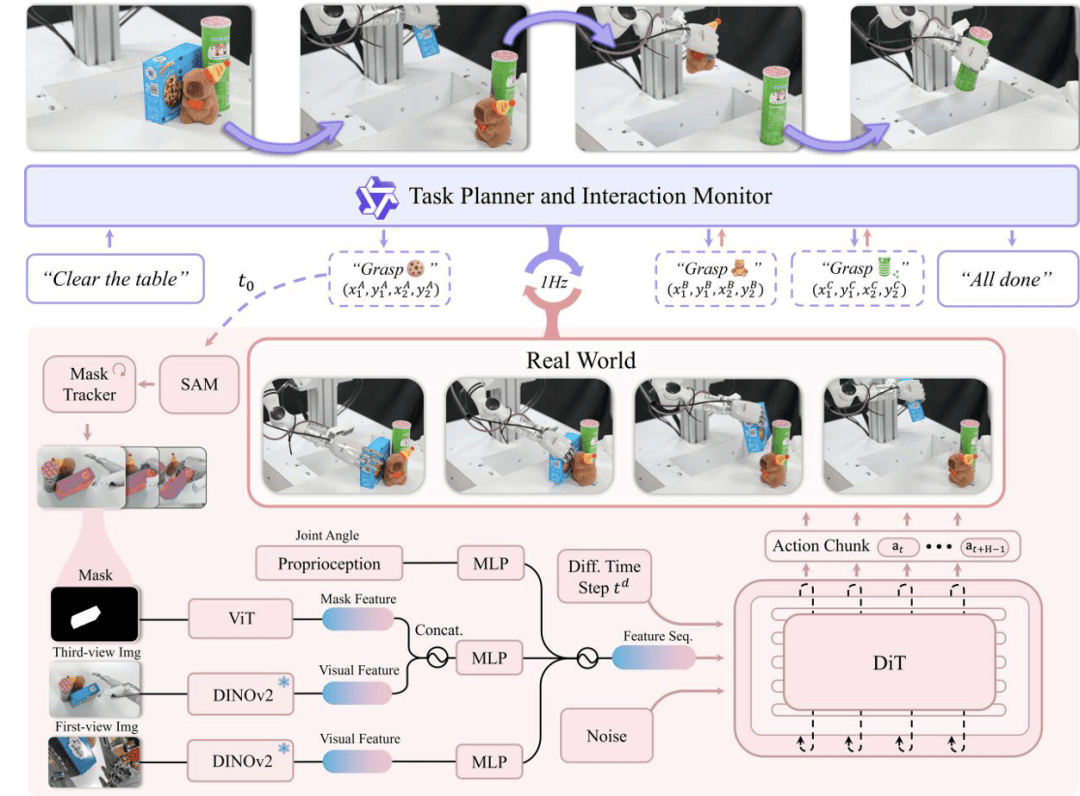
實驗結果顯示,靈初智能僅使用了約2小時的靈巧手抓取數據,便成功泛化到上千種不同物體、位置、堆疊、燈光和背景下進行抓取。這一數據量僅為Figure的0.4%,數據利用效率提高了250倍。DexGraspVLA不僅能夠根據語言指令分辨出目標物體并處理堆疊場景下的目標物體檢索與抓取,還擁有快速的抓取速度、閉環姿態矯正與重抓取能力以及長程推理能力。
靈初智能還開發了一套基于強化學習的物體檢索策略——Retrieval Dexterity,解決了堆疊場景中物體檢索識別效率低的問題。該策略在仿真環境中進行大規模訓練,隨后將訓練結果零樣本遷移至現實機器人和復雜環境中,實現了從雜亂堆疊物體中快速取出目標物體的目標。
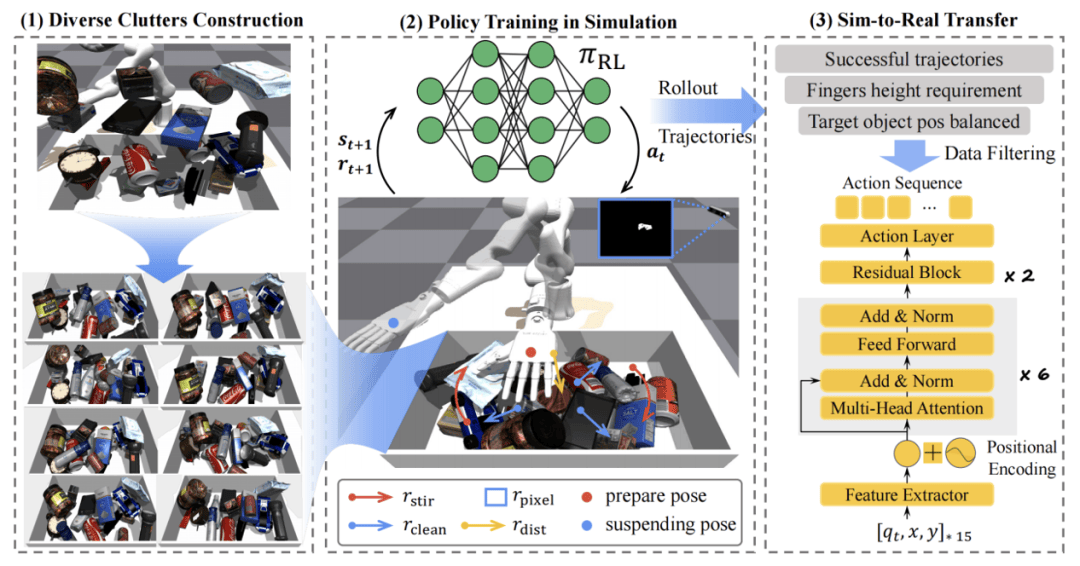
Retrieval Dexterity不僅在訓練過的物體上表現出色,還能將檢索能力泛化到未見過的新物體上。與人為設定的動作相比,該方法在所有場景中平均減少了38%的操作步驟。同時,靈初智能還推出了ExDex方案,利用外部靈巧性抓取那些無法直接抓取的物體。通過強化學習,ExDex能夠自主制定策略,借助周圍環境完成抓取任務。
最后,靈初智能與北京大學PAIR-Lab團隊攜手推出了具身安全模型SafeVLA。該模型通過安全對齊技術,讓機器人在復雜場景中安全高效地執行任務。SafeVLA不僅關注任務的完成,更將人類安全放在首位。在引入約束馬爾可夫決策過程(CMDP)范式后,SafeVLA在安全性和任務執行方面均取得了突破性進展。
SafeVLA在12個分布外(OOD)實驗中表現出色,面對光照、材質變化和復雜環境擾動時始終穩定發揮。這一成果不僅證明了SafeVLA在平衡安全與效率方面的卓越能力,更為人機交互的未來提供了更加安全可靠的解決方案。





