
在機器人技術領域的最新突破中,智元機器人公司于近日震撼發布了其首個通用具身基座模型——智元啟元大模型Genie Operator-1(簡稱GO-1)。這一創新成果不僅標志著機器人智能化進程的一大步,還預示著具身智能正加速向通用化、開放化與智能化邁進。
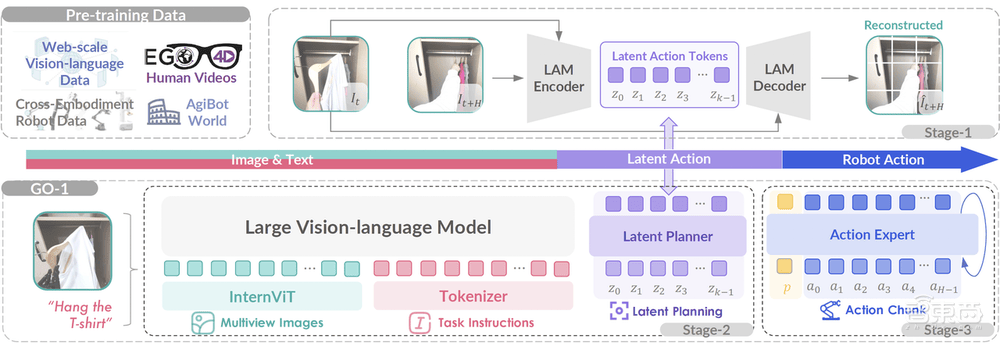
GO-1的核心在于其提出的Vision-Language-Latent-Action(ViLLA)框架,該框架巧妙融合了VLM(多模態大模型)與MoE(混合專家)技術,實現了從數據采集、模型訓練到模型推理的無縫銜接。這一設計賦予了GO-1諸多顯著優勢,如小樣本快速泛化能力、跨本體應用的“一腦多形”特性、持續進化的學習機制以及基于人類視頻的學習能力。

VLM作為GO-1的主干網絡,通過繼承開源多模態大模型的權重,并利用互聯網上的大規模純文本和圖文數據,使得GO-1擁有了強大的場景感知和理解能力。而MoE中的隱動作專家模型和動作專家模型,則分別通過學習互聯網上的大規模人類操作和跨本體操作視頻,以及高質量的仿真數據和真機數據,讓GO-1具備了動作的理解和精細執行能力。
GO-1的五大特點尤為引人注目:采訓推一體的軟硬件一體化框架,確保了從數據采集到模型推理的高效銜接;小樣本快速泛化能力,使得GO-1能夠在極少數據甚至零樣本下快速適應新場景和新任務;一腦多形的特性,讓GO-1能夠在不同機器人形態之間靈活遷移,快速適配到各種本體;持續進化的學習機制,借助智元的數據回流系統,讓GO-1能夠從實際執行中遇到的問題數據中不斷學習和進化;人類視頻學習能力,則進一步增強了GO-1對人類行為的理解。
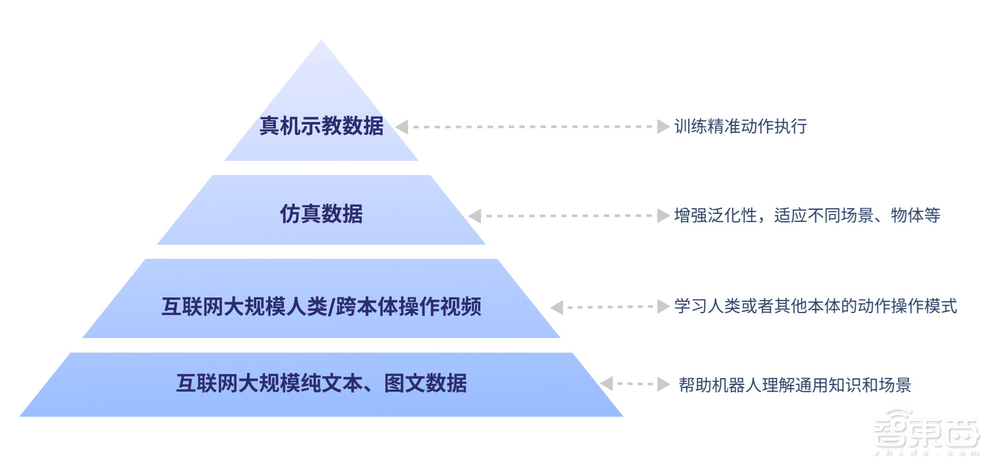
GO-1的構建基于具身領域的數字金字塔模型,從底層的互聯網大規模純文本與圖文數據,到上層的互聯網大規模人類操作/跨本體視頻,再到仿真數據和高質量的真機示教數據,每一層都為GO-1提供了全面而豐富的知識和能力培訓。這使得GO-1能夠輕松面對多種多樣的環境和物體,快速學習新的操作,并天然適應新的場景。
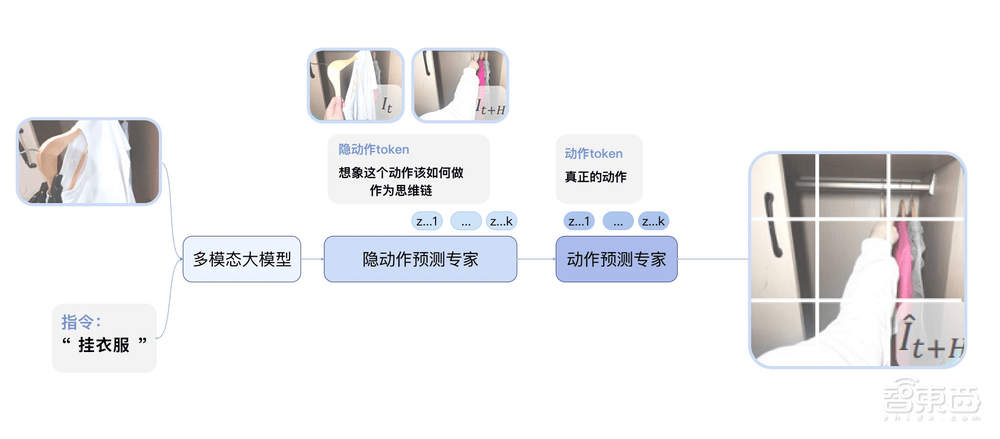
在實際應用中,GO-1的表現同樣令人矚目。用戶只需用平常講話的方式告訴機器人要做的事情,比如“掛衣服”,GO-1就能根據看到的畫面和所學習的知識,理解任務要求,并拆解成一系列步驟來執行。從家庭場景中的準備餐食、收拾桌面,到辦公和商業場景中的接待訪客、發放物品,再到工業等更多場景的其他操作任務,GO-1都能快速而準確地完成。
GO-1的持續進化能力也值得稱道。比如,在機器人做咖啡時,如果不小心把杯子放歪了,GO-1就能從這個問題數據中持續學習和進化,直到成功完成任務。這種不斷學習和進步的能力,讓GO-1在面對多變的真實世界時更加游刃有余。

智元機器人的這一創新成果,無疑為機器人技術的發展注入了新的活力。GO-1的出現,不僅解決了具身智能在場景和物體泛化能力不足、語言理解能力缺失、新技能學習緩慢以及跨本體部署困難等方面的問題,更為機器人代替人類完成工作生活中的各種事情提供了強大的腦力支持。未來,隨著GO-1的不斷優化和升級,我們有理由相信,機器人將走向更多不同場景,適應多變的真實世界,為人類的生活和工作帶來更多便利和驚喜。





