
在機器人技術的前沿探索中,智元機器人于3月10日震撼發布其首個通用具身基座模型——智元啟元大模型Genie Operator-1(簡稱GO-1)。這一創新成果不僅標志著機器人在智能化道路上邁出了重要一步,更預示著具身智能向通用化、開放化邁進的新紀元。
GO-1的核心在于其提出的Vision-Language-Latent-Action(ViLLA)框架,該框架巧妙融合了VLM(多模態大模型)與MoE(混合專家)技術,實現了從數據采集、模型訓練到模型推理的無縫銜接。這一獨特設計賦予了GO-1小樣本快速泛化的能力,使其能在極少數據甚至零樣本的情況下迅速適應新場景和新任務。
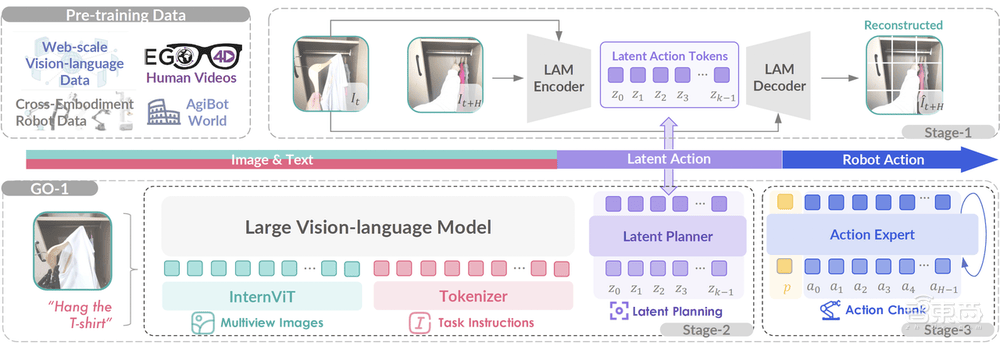
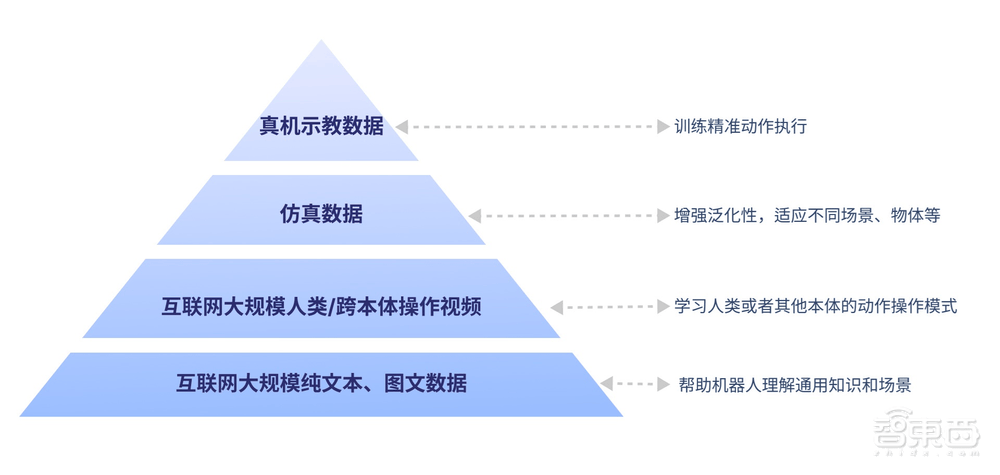
GO-1的ViLLA框架通過VLM主干網絡,利用互聯網上的大規模純文本和圖文數據,為機器人提供了廣泛的場景感知和理解能力。而MoE中的隱動作專家模型和動作專家模型,則分別通過大規模人類操作和跨本體操作視頻,以及高質量的仿真數據和真機數據,使機器人具備了動作理解和精細執行能力。這種設計使得GO-1能夠輕松應對多樣化的環境和物體,快速學習并執行新的操作。
尤為GO-1的“一腦多形”特性使其成為一個真正的通用機器人策略模型。這意味著GO-1可以在不同機器人形態之間自由遷移,快速適配到各種本體上,從而大大拓展了其應用場景。無論是家庭場景中的餐食準備、桌面收拾,還是辦公和商業場景中的接待訪客、發放物品,GO-1都能游刃有余。
GO-1還具備持續進化的能力。通過智元提供的一整套數據回流系統,GO-1可以從實際執行中遇到的問題數據中不斷學習和進化,從而不斷提升其性能和表現。例如,當機器人在做咖啡時不小心將杯子放歪時,它可以通過數據回流系統學習到這一錯誤,并在后續任務中避免重復發生。
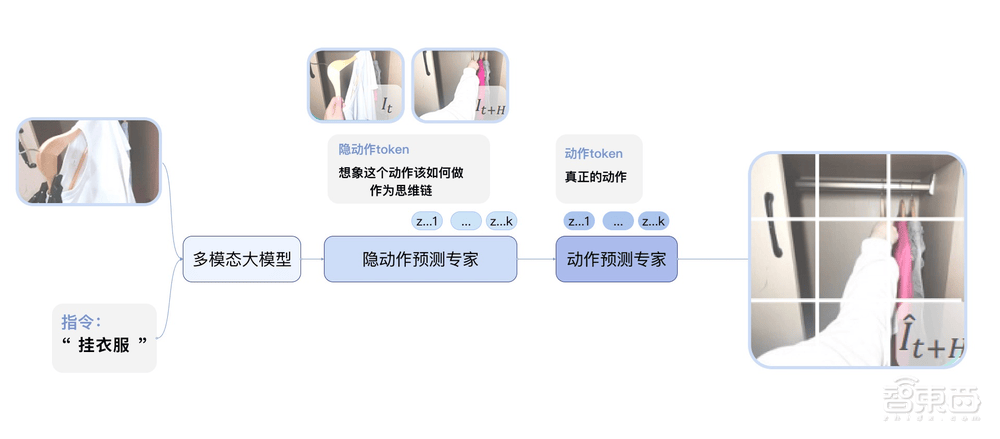
在實際應用中,GO-1的表現同樣令人矚目。用戶只需通過簡單的語言指令,如“掛衣服”,GO-1就能根據所看到的畫面和所學習的知識,理解指令的含義和要求,并快速執行相應的動作。這種結合互聯網視頻和真實人類示范的學習方式,極大地增強了GO-1對人類行為的理解和執行能力。
在商務會議等場景中,GO-1同樣展現出了其強大的應用潛力。面對人類發出的各種語音指令,如“幫我拿一瓶飲料”或“幫我拿一個蘋果”,GO-1都能迅速響應并執行相應的動作,為會議提供便捷的服務。


智元機器人的這一創新成果,無疑為具身智能的發展注入了新的活力。GO-1的出現,不僅解決了具身智能在場景和物體泛化能力不足、語言理解能力欠缺、新技能學習緩慢以及跨本體部署困難等方面的問題,更為機器人走向更多不同場景、適應多變的真實世界提供了強大的技術支持。隨著技術的不斷進步和應用場景的不斷拓展,我們有理由相信,未來的機器人將更加智能化、通用化和開放化。





