
在人工智能(AI)技術迅猛發(fā)展的當下,企業(yè)正面臨一場數據治理的革命。業(yè)務部門渴望通過數據驅動決策,卻常常因為指標口徑的不統一和數據血緣的不透明而陷入困境。同時,技術團隊在投入大量資金訓練AI模型時,也往往因基礎數據質量的問題而導致事倍功半。這一現狀迫使企業(yè)不得不重新審視數據治理的價值。
在近期于上海舉辦的「數據薈」Meet Up活動中,阿里云智能集團瓴羊的高級技術專家周鑫指出,數據治理實施的最大難題在于治理過程涉及的點過多,導致企業(yè)在多個治理模塊中疲于奔命,難以形成持續(xù)的價值。他提出,以數據標準為中心,貫穿數據全生命周期,是破解這一困局的關鍵。
數據治理之所以困難重重,是因為實施鏈路復雜且繁瑣。企業(yè)在進行數據治理時,通常需要經歷現狀評估、目標制定、計劃執(zhí)行和持續(xù)監(jiān)控等多個步驟。在這個過程中,企業(yè)不僅要考慮數據質量、數據安全和生命周期管理,還要在控制成本的同時,兼顧整個組織架構的需求。周鑫表示,傳統的治理步驟面臨實施方法復雜、治理鏈路繁瑣、工具支撐不足和難以持續(xù)治理等四大問題。

這一困境導致企業(yè)在實施數據治理時容易偏離中心,缺乏一個核心抓手。即使艱難完成治理,后續(xù)的迭代也非常困難,因為任何一個目標的改動都可能牽一發(fā)而動全身,導致數據安全與質量規(guī)則的反復調整,大大拖慢了治理進度。因此,找到數據治理的核心——數據標準,成為了解決問題的關鍵。
近年來,國家頻頻出臺數據標準相關政策規(guī)范,從《“數據要素x”三年行動計劃》到國家數據標準體系,再到全國數據標準化技術委員會,都彰顯了數據標準的重要地位。周鑫表示,當企業(yè)確定了數據標準,治理工作就已經完成了很大一部分。以瓴羊Dataphin為例,企業(yè)完成業(yè)務與數據盤點后,將數據納入數據元中心,便可以在Dataphin中梳理數據標準。數據標準的建立不僅貫穿數據建模、研發(fā)等事前環(huán)節(jié),還能通過生成質量規(guī)則和安全識別、分類分級等功能,實現對數據事中及事后的全面管控。
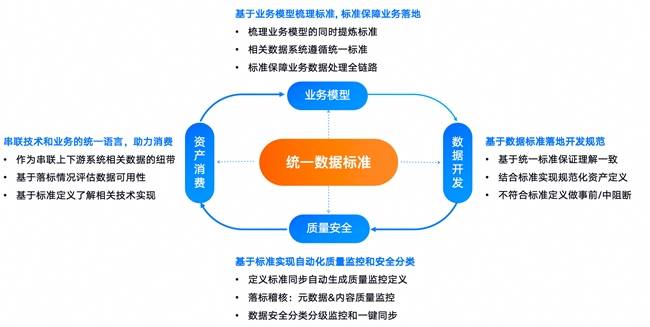
在數據標準的基礎上,企業(yè)可以更加高效地管理數據質量。例如,在手機號的標準設置中,系統會自動根據用戶設定的屬性要求生成一系列質量校驗規(guī)則,確保相關字段數據符合標準。在訪問權限上,系統也會自動匹配審批流程,幫助快速識別和處理不合規(guī)的數據。這使得數據標準的滿足度成為衡量數據質量優(yōu)劣的重要指標。
AI技術的爆發(fā)為數據治理帶來了新的機遇。周鑫認為,通過AI與數據治理的結合,可以實現完整的主動數據治理。在數據標準階段,AI可以逆向生成碼表、數據標準和數據模型,大大降低從業(yè)務到標準、到模型的實施成本。同時,AI還能自動識別治理效果,提供治理策略指引,形成數據治理的良性內循環(huán)。

瓴羊Dataphin的實踐展示了AI在數據治理中的巨大潛力。通過智能小D平臺,用戶可以直接通過對話的方式詢問具體的業(yè)務需求,系統會根據用戶需求快速提供對應的數據資產表。Dataphin還引入了AI能力來豐富數據屬性、簡化數據上架流程以及加快特征識別速度。這使得企業(yè)能夠更加高效地管理和使用數據資產。
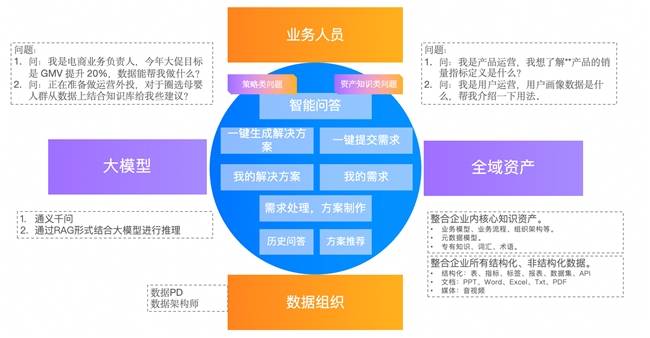
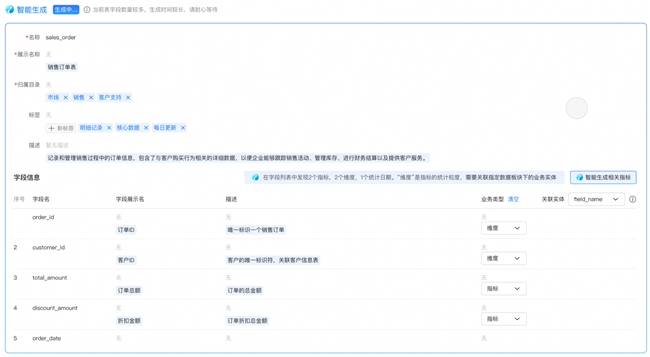
周鑫還介紹了Dataphin在數據治理與AI融合方面的遠期規(guī)劃。他提出,邁向智能化的最大標志是自助治理,即通過AI能力基于業(yè)務變化自動調整治理目標、策略和業(yè)務動作。面對海量數據質量參差、治理鏈路冗長的挑戰(zhàn),他建議從小的業(yè)務和領域切入,通過縮小問題求解集合來加快提升數據質量。隨著AI技術的不斷發(fā)展,Dataphin將實現對業(yè)務流程的深度理解,系統自動生成數據標準,全面提升數據治理的智能化水平。





