擊這里在線咨詢客服")
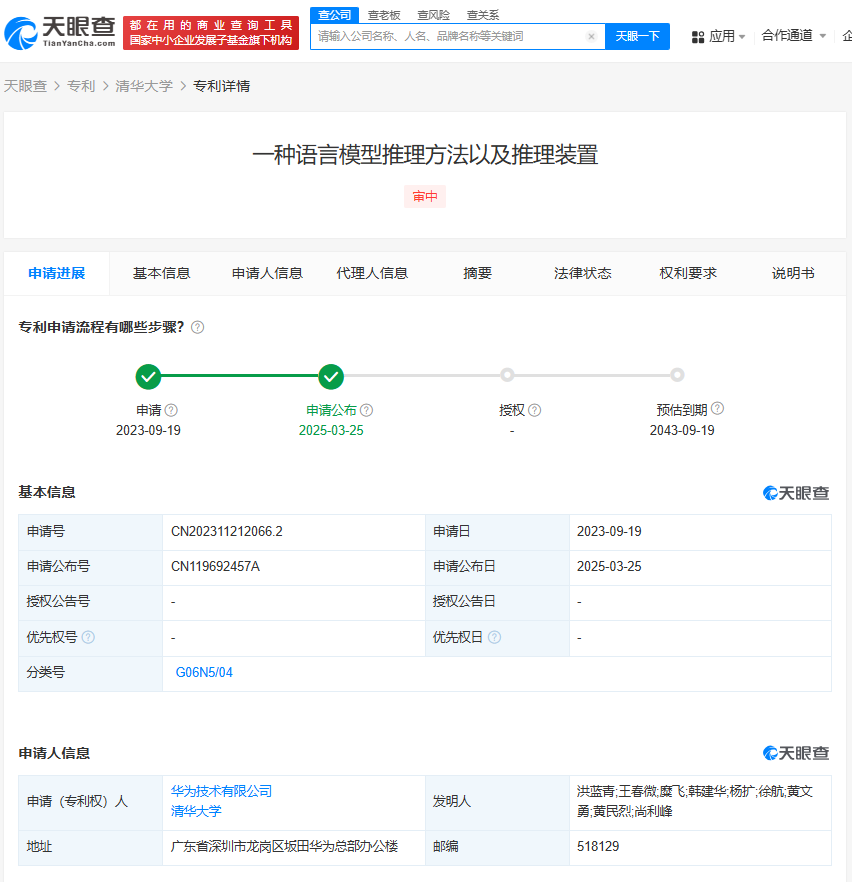
近期,一項(xiàng)由華為技術(shù)有限公司與清華大學(xué)聯(lián)手申請(qǐng)的專利引起了廣泛關(guān)注。據(jù)天眼查信息顯示,這項(xiàng)名為“一種語言模型推理方法及其推理裝置”的專利于3月25日正式公布。
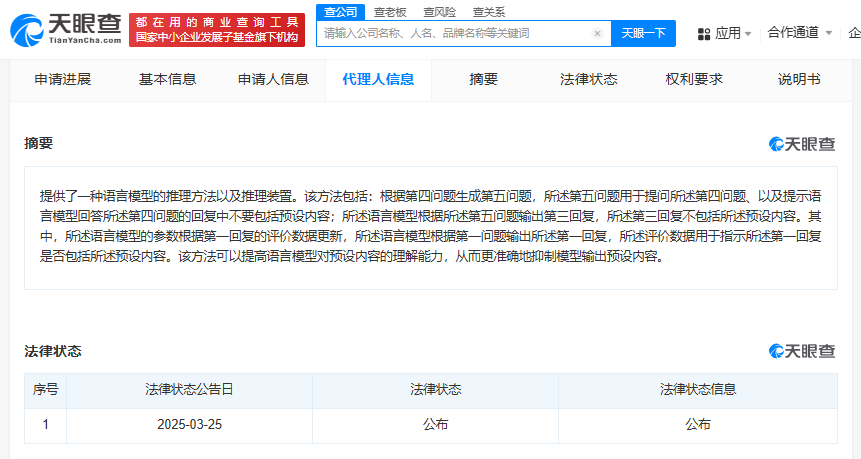
該專利的核心在于一種創(chuàng)新的語言模型推理方法,其具體操作流程頗具匠心。首先,系統(tǒng)會(huì)基于一個(gè)初始問題(第四問題)生成一個(gè)變形問題(第五問題)。這個(gè)第五問題不僅包含了原始問題的全部信息,還特別指示語言模型在回答時(shí)避免包含某些預(yù)設(shè)內(nèi)容。隨后,語言模型會(huì)根據(jù)這個(gè)經(jīng)過精心設(shè)計(jì)的第五問題輸出回答(第三回復(fù)),而這個(gè)回答會(huì)嚴(yán)格遵循指示,不包含任何預(yù)設(shè)內(nèi)容。
更為先進(jìn)的是,這個(gè)語言模型的參數(shù)并非一成不變,而是會(huì)根據(jù)過往回答的評(píng)價(jià)數(shù)據(jù)進(jìn)行動(dòng)態(tài)調(diào)整。具體來說,模型會(huì)先根據(jù)一個(gè)問題(第一問題)輸出一個(gè)回答(第一回復(fù)),然后這些回答會(huì)根據(jù)是否包含預(yù)設(shè)內(nèi)容等標(biāo)準(zhǔn)進(jìn)行評(píng)價(jià)。這些評(píng)價(jià)數(shù)據(jù)將作為反饋,用于優(yōu)化模型的參數(shù),從而提升其理解和抑制預(yù)設(shè)內(nèi)容的能力。
這項(xiàng)專利的公布,標(biāo)志著華為與清華大學(xué)在人工智能領(lǐng)域的又一次深度合作取得了重要成果。通過這種方法,語言模型能夠更加精準(zhǔn)地理解和處理信息,避免在回答中包含不必要或敏感的內(nèi)容,從而極大地提升了模型的實(shí)用性和準(zhǔn)確性。
這項(xiàng)專利的推出也反映了當(dāng)前人工智能領(lǐng)域?qū)τ谡Z言模型推理能力的重視。隨著技術(shù)的不斷進(jìn)步和應(yīng)用場(chǎng)景的日益豐富,對(duì)于語言模型的理解能力、推理能力和控制能力都提出了更高的要求。而華為與清華大學(xué)的這項(xiàng)創(chuàng)新成果,無疑為這一領(lǐng)域的發(fā)展注入了新的活力和動(dòng)力。
未來,隨著這項(xiàng)專利的進(jìn)一步應(yīng)用和推廣,我們有理由相信,語言模型將在更多領(lǐng)域發(fā)揮更大的作用,為人類社會(huì)的智能化進(jìn)程貢獻(xiàn)更多的智慧和力量。





