擊這里在線咨詢客服")
近期,一款由中國新興AI企業(yè)DeepSeek研發(fā)的開源大模型DeepSeek-V3,在全球范圍內(nèi)引起了廣泛關(guān)注。這款模型不僅性能卓越,而且訓(xùn)練成本相對(duì)較低,給業(yè)界帶來了不小的震動(dòng)。
據(jù)悉,DeepSeek-V3的技術(shù)論文詳細(xì)披露了該模型的研發(fā)歷程。與上一代相比,其參數(shù)規(guī)模從2360億大幅提升至6710億,并在14.8T tokens的數(shù)據(jù)集上進(jìn)行了預(yù)訓(xùn)練,上下文長度更是達(dá)到了128K。這一系列的升級(jí),使得DeepSeek-V3在多個(gè)主流評(píng)測(cè)基準(zhǔn)上表現(xiàn)出色,性能媲美甚至超越了GPT-4o和Claude-3.5-Sonnet等領(lǐng)先的閉源模型。
DeepSeek-V3的出色表現(xiàn),也吸引了眾多AI領(lǐng)域的大咖關(guān)注。其中包括阿里前副總裁賈揚(yáng)清、metaAI科學(xué)家田淵棟、英偉達(dá)高級(jí)研究科學(xué)家Jim Fan等。這些專家對(duì)DeepSeek-V3給予了高度評(píng)價(jià),甚至有網(wǎng)友將其譽(yù)為“全球最佳開源大模型”,并預(yù)測(cè)它將加速AGI(通用人工智能)的實(shí)現(xiàn)。
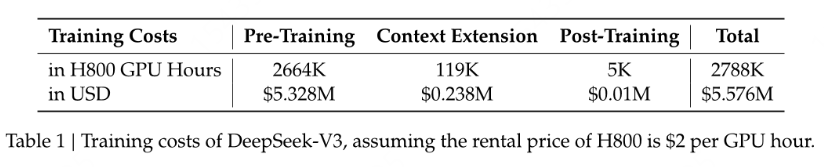
值得注意的是,DeepSeek-V3的訓(xùn)練成本相對(duì)較低,是其受到廣泛關(guān)注的重要原因之一。據(jù)透露,該模型僅使用了2000多張GPU,訓(xùn)練成本不到600萬美元,遠(yuǎn)低于OpenAI、meta等在萬卡規(guī)模上訓(xùn)練的模型成本。這種成本效益比,讓DeepSeek-V3在業(yè)界獨(dú)樹一幟。
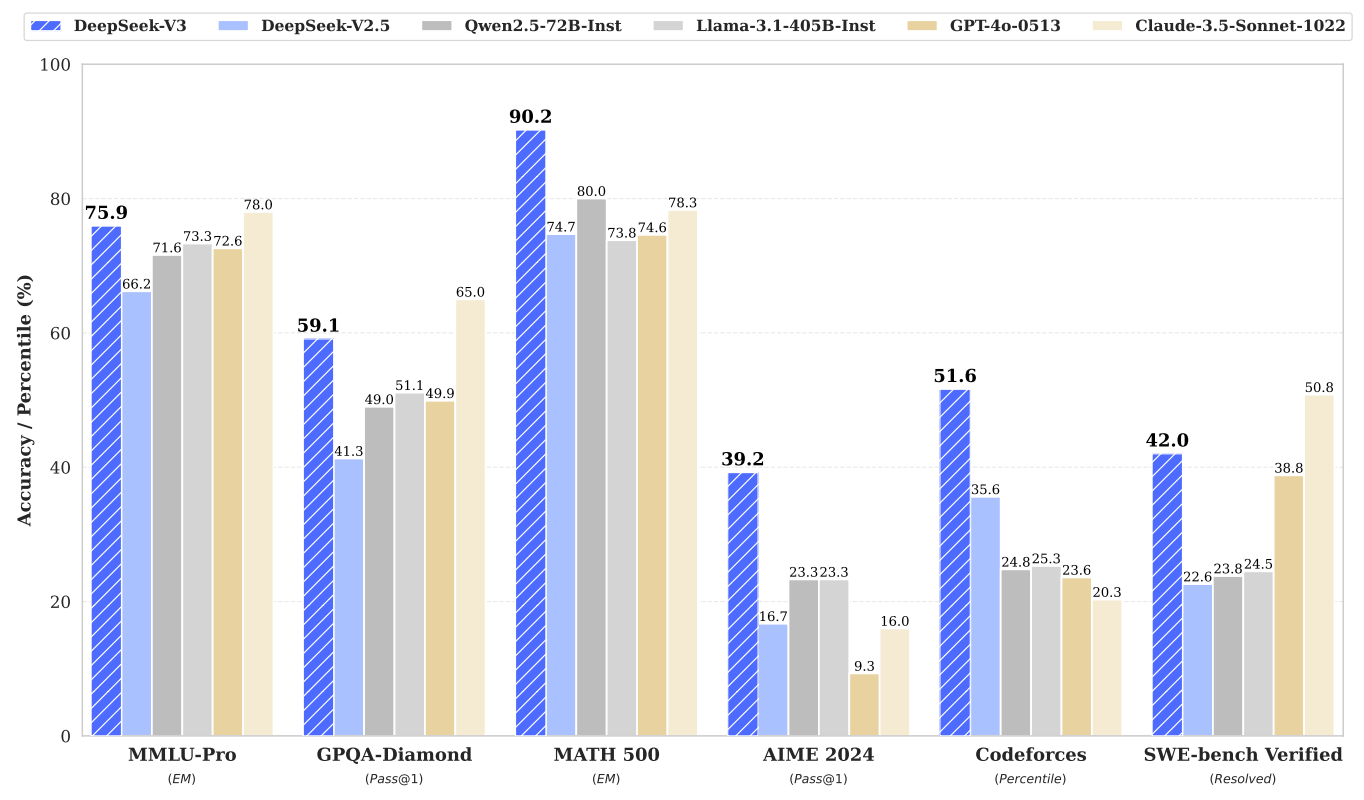
在知識(shí)能力方面,DeepSeek-V3同樣表現(xiàn)出色。在MMLU-Pro和GPQA-Diamond等基準(zhǔn)測(cè)試中,它超越了阿里、meta等所有開源模型,并接近GPT-4o的水平,盡管略遜于Claude-3.5-Sonnet。而在數(shù)學(xué)、代碼和推理能力方面,DeepSeek-V3更是展現(xiàn)出了強(qiáng)大的實(shí)力。在MATH500、AIME2024及Codeforces等多個(gè)主流基準(zhǔn)測(cè)試中,它不僅碾壓了阿里和meta的最新開源模型,還超越了GPT-4o和Claude-3.5-Sonnet,成為業(yè)界的新標(biāo)桿。
然而,DeepSeek-V3也并非完美無缺。它在某些方面還存在局限性。例如,在英文能力方面,它還落后于GPT-4o和Claude-Sonnet-3.5。同時(shí),該模型的部署要求較高,對(duì)小型團(tuán)隊(duì)不太友好。其生成速度也有待進(jìn)一步提升。不過,DeepSeek在論文中表示,隨著更先進(jìn)硬件的開發(fā),這些局限性有望在未來得到解決。
盡管存在這些局限性,但DeepSeek-V3的出現(xiàn)無疑為AI領(lǐng)域帶來了新的活力和希望。它展示了中國在AI技術(shù)研發(fā)方面的實(shí)力和潛力,也為其他國家和地區(qū)提供了寶貴的借鑒和啟示。未來,我們期待DeepSeek-V3能夠不斷完善和提升自己,為AI領(lǐng)域的發(fā)展做出更大的貢獻(xiàn)。





