
在人工智能領(lǐng)域,盡管現(xiàn)有的頂尖大語言模型(SOTA)展現(xiàn)了卓越智能,部分任務(wù)表現(xiàn)甚至超越人類,但其龐大的參數(shù)規(guī)模——動輒數(shù)千億乃至萬億級別,導(dǎo)致了高昂的訓(xùn)練、部署及推理成本。對于企業(yè)及開發(fā)者而言,在處理相對簡單卻需大規(guī)模、高并發(fā)處理的任務(wù)時,這些頂尖模型并非性價比最優(yōu)的選擇。
針對這一痛點,新興初創(chuàng)公司Fastino應(yīng)運而生。該公司利用低端游戲GPU,以平均不足10萬美元的成本,成功訓(xùn)練出一系列名為“任務(wù)特定語言模型”(TLMs)的小型模型。這些模型在特定任務(wù)上的性能可媲美大型語言模型,且推理速度快了99倍。
近期,F(xiàn)astino宣布獲得由Khosla Ventures領(lǐng)投的1750萬美元種子輪融資,Insight Partners、Valor Equity Partners及知名天使投資人Scott Johnston(前Docker首席執(zhí)行官)和Lukas Biewald(Weights & Biases首席執(zhí)行官)參與跟投。加上2024年11月由M12(微軟旗下)和Insight Partners領(lǐng)投的700萬美元前種子輪融資,F(xiàn)astino累計融資額已近2500萬美元。
Fastino由連續(xù)創(chuàng)業(yè)者Ash Lewis(首席執(zhí)行官)和George Hurn-Maloney(首席運營官)共同創(chuàng)立。Ash Lewis此前還參與創(chuàng)立了DevGPT、Ashtv AI等多家AI原生公司。他們組建了一支技術(shù)團隊,成員來自谷歌DeepMind、斯坦福大學(xué)、卡內(nèi)基梅隆大學(xué)及蘋果等頂尖機構(gòu),能夠從底層技術(shù)革新,訓(xùn)練出“任務(wù)特定語言模型”。

Fastino的TLM模型在成本效益和性能上表現(xiàn)突出。隨著AI模型規(guī)模的不斷擴大,雖然數(shù)千億至上萬億參數(shù)的SOTA模型在智能上持續(xù)提升,甚至在某些初級任務(wù)上替代人力,但高昂的訓(xùn)練、部署及推理成本使得它們在經(jīng)濟性上并不總是最優(yōu)選擇。即便是擁有近10億周活用戶的OpenAI,也面臨著用戶增長帶來的成本飆升壓力。
Ash Lewis談及創(chuàng)業(yè)初衷時表示:“我們上一家創(chuàng)業(yè)公司在走紅后,基礎(chǔ)設(shè)施成本急劇上升。有一段時間,語言模型的開支甚至超過了整個團隊的費用,這促使我們創(chuàng)立了這家公司。”
除了高昂的運行成本,大尺寸模型的通用性與專用性之間的矛盾也是一大問題。雖然大尺寸模型帶來了強大的智力和通用性,但在特定專用任務(wù)上性能可能并不突出,且需為通用性支付額外成本。大尺寸模型運行速度慢,影響了用戶體驗。當(dāng)前的AI工作負載更看重精準(zhǔn)度、速度和可擴展性,而非泛化的推理能力。
George Hurn-Maloney指出:“AI開發(fā)者不需要在無數(shù)無關(guān)數(shù)據(jù)點上訓(xùn)練的大語言模型,他們需要適合其任務(wù)的正確模型。因此,我們推出了高精度、輕量化的模型,讓開發(fā)者能夠無縫集成。”
Fastino的TLMs專為需要低延遲、高精度AI的開發(fā)者和企業(yè)設(shè)計,不針對消費級用戶,無需通用性。這些模型結(jié)合了基于Transformer的注意力機制,并在架構(gòu)、預(yù)訓(xùn)練和后訓(xùn)練階段引入任務(wù)專精。它們優(yōu)先考慮緊湊性和硬件適應(yīng)性,同時不犧牲任務(wù)準(zhǔn)確性。這種架構(gòu)和技術(shù)創(chuàng)新使得TLM模型能夠在低端硬件上高效運行,同時提升任務(wù)準(zhǔn)確性。
相比OpenAI GPT-4o的4000ms延遲,F(xiàn)astino的TLM模型延遲低至100ms,快了99倍。在性能方面,F(xiàn)astino對比了TLM模型在意圖檢測、垃圾信息過濾、情感傾向分析、有害言論過濾、主題分類和大型語言模型防護等基準(zhǔn)上的表現(xiàn),結(jié)果顯示其F1分數(shù)比GPT-4o高出17%。

Fastino的TLM模型并非單一模型,而是針對每個特定用例訓(xùn)練的一組模型。首批模型能夠應(yīng)對一些需求最明確且廣泛的企業(yè)和開發(fā)者核心任務(wù),如文本摘要、函數(shù)調(diào)用、文本轉(zhuǎn)JSON、個人身份信息屏蔽、文本分類、臟話過濾和信息提取等。
在收費模式上,F(xiàn)astino采用了訂閱制,對初級開發(fā)者和中小企業(yè)較為友好。個人開發(fā)者每月有1萬次免費請求,Pro用戶每月10萬次請求僅需45美元,團隊用戶300萬次請求每月1275美元。Pro用戶和團隊用戶還享有更快模型速度、更安全模型訪問及更大上下文窗口等額外優(yōu)勢。
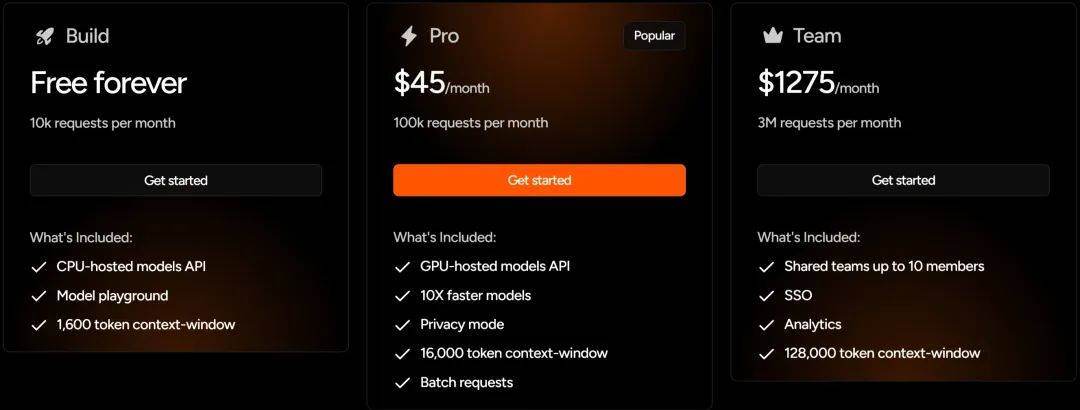
Fastino的TLM模型能夠針對開發(fā)者和小企業(yè)用戶提供服務(wù),得益于其極低的模型運行成本。對于企業(yè)客戶,TLM可部署在客戶的虛擬私有云、本地數(shù)據(jù)中心或邊緣設(shè)備上,使企業(yè)能夠在保留敏感信息控制權(quán)的同時,利用先進的人工智能能力。
目前,F(xiàn)astino的TLM已在多個行業(yè)產(chǎn)生影響,從金融和醫(yī)療領(lǐng)域的文檔解析到電子商務(wù)中的實時搜索查詢智能,財富500強企業(yè)正利用這些模型優(yōu)化運營、提升效率。
在模型規(guī)模不斷擴大的趨勢下,小模型在企業(yè)應(yīng)用中展現(xiàn)出獨特優(yōu)勢。低成本、低延遲以及在特定任務(wù)上不弱于大尺寸通用模型的優(yōu)點,使得小模型受到企業(yè)和開發(fā)者的青睞。這一趨勢不僅適用于Fastino,其他模型廠商如Cohere和Mistral也提供強大的小尺寸模型。國內(nèi)大廠如阿里云的Qwen3也推出了4B、1.7B甚至0.6B的模型。小尺寸模型在成本效益、推理時延和能力匹配上的優(yōu)勢,為它們在AI領(lǐng)域贏得了生存空間。





