擊這里在線咨詢客服")
阿里巴巴旗下的通義團(tuán)隊(duì)近日宣布了一項(xiàng)重大進(jìn)展,正式推出了基于千問3大模型的全新向量模型系列——Qwen3-Embedding。這一系列的發(fā)布,標(biāo)志著千問3在文本表征、檢索及排序等核心任務(wù)上的又一次飛躍,性能相較于其前代模型有了顯著提升,最高可達(dá)40%。
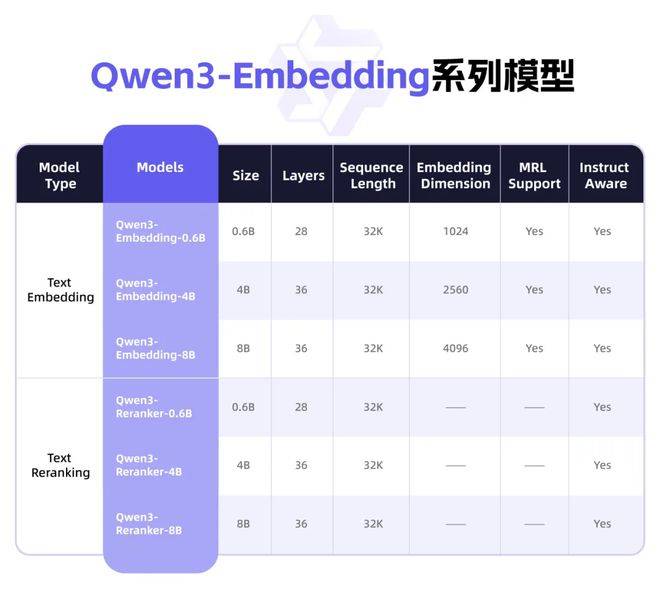
Qwen3-Embedding系列模型,作為千問3的衍生產(chǎn)品,其設(shè)計(jì)初衷便是為了優(yōu)化和提升AI在文本處理方面的能力。通過先進(jìn)的對(duì)比訓(xùn)練、SFT技術(shù)以及模型融合策略,通義團(tuán)隊(duì)成功地打造出了這一系列的文本嵌入模型Qwen3-Embedding和文本排序模型Qwen3-Reranker。
向量模型,被譽(yù)為AI的“翻譯官”,它們能夠?qū)⑷祟愃芾斫獾姆墙Y(jié)構(gòu)化信息,如文本和圖片,轉(zhuǎn)化為機(jī)器更易處理的向量形式。這一轉(zhuǎn)化過程為AI在信息分類、檢索及排序等方面提供了強(qiáng)有力的支持,極大地提升了AI的語義理解和信息處理能力。Qwen3-Embedding系列模型的推出,正是基于這一理念,旨在進(jìn)一步提升AI在這些方面的性能。
在權(quán)威的多語言向量評(píng)估榜單MTEB上,Qwen3-Embedding-8B模型憑借其卓越的性能,成功超越了谷歌的Gemini Embedding、OpenAI的text-embedding-3-large以及微軟的multilingual-e5-large-instruct等頂尖模型,奪得了同類模型的最佳性能SOTA。這一成就不僅彰顯了Qwen3-Embedding系列模型的強(qiáng)大實(shí)力,也體現(xiàn)了阿里巴巴在AI技術(shù)領(lǐng)域的深厚底蘊(yùn)。
Qwen3向量模型系列還具備出色的多語言能力。得益于千問3大模型的多語言特性,Qwen3-Embedding系列模型支持超過100種語言,并涵蓋了多種編程語言。這一特性使得Qwen3向量模型系列在跨語言檢索、代碼檢索等方面展現(xiàn)出了強(qiáng)大的能力。
為了方便開發(fā)者更好地利用Qwen3向量模型系列,阿里巴巴此次開源了9款不同尺寸和版本的模型,包括0.6B、4B、8B等。開發(fā)者可以根據(jù)自己的需求選擇合適的模型,自由組合模塊,并自定義向量或指令,以實(shí)現(xiàn)特定任務(wù)、語言和場(chǎng)景的深度優(yōu)化。例如,在智能搜索和推薦系統(tǒng)中,開發(fā)者可以采用Qwen3-Embedding模型進(jìn)行文本向量化;在RAG實(shí)踐中,可以利用Qwen3-Reranker模型提升最終結(jié)果的相關(guān)性和準(zhǔn)確性;甚至還可以與視覺理解模型結(jié)合,探索前沿的跨模態(tài)語義理解。
目前,Qwen3 Embedding和Reranker模型已經(jīng)在魔搭社區(qū)、Hugging Face和GitHub等平臺(tái)上開源,開發(fā)者可以直接通過阿里云百煉使用API服務(wù)。這一舉措無疑將為AI技術(shù)的普及和發(fā)展提供有力的支持。
自4月29日千問3大模型開源以來,它已經(jīng)在國內(nèi)外的多個(gè)權(quán)威榜單上取得了優(yōu)異的成績,包括Artificial Analysis、LiveBench、LiveCodeBench和SuperClue等。這些成績的取得,不僅證明了千問3大模型的強(qiáng)大實(shí)力,也展示了阿里巴巴在AI技術(shù)領(lǐng)域的持續(xù)創(chuàng)新和突破。





