
小紅書在AI領域再次發力,近兩個月內連續開源了三款自研模型,其中最新推出的dots.vlm1是首個多模態大模型。這款模型基于小紅書人文智能實驗室(Humane Intelligence Lab,簡稱hi lab)自研的視覺編碼器構建,不僅在視覺理解和推理任務上表現卓越,還能應對數獨解題、高考數學題解答等復雜任務,甚至能模仿李白詩風創作詩句。
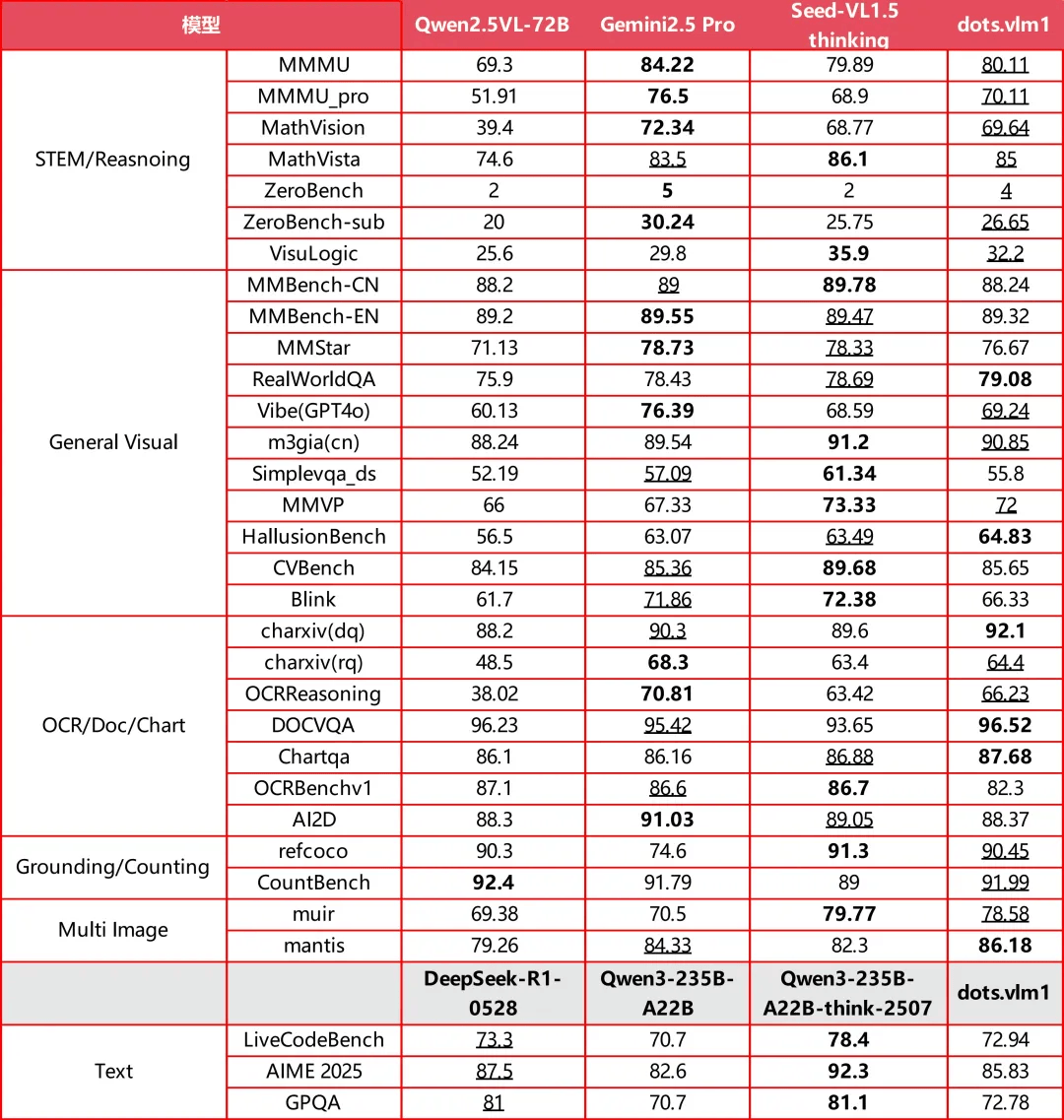
在AI技術日新月異的當下,小紅書的這次開源行動無疑為行業帶來了新的活力。OpenAI、谷歌等國際巨頭也在近期發布了新的開源模型,但相比之下,dots.vlm1的多模態能力顯得尤為突出。據官方介紹,dots.vlm1在視覺評測集如MMMU、MathVision、OCR Reasoning上的表現已接近當前領先的Gemini 2.5 Pro與Seed-VL1.5 Thinking模型,顯示出強大的圖文理解與推理能力。
在文本推理任務上,dots.vlm1的表現也相當出色,能夠處理AIME、GPQA、LiveCodeBench等復雜任務。盡管在數學和代碼能力上已具備一定的通用性,但在GPQA等更多樣化的推理任務上仍有一定提升空間。不過,整體而言,dots.vlm1在視覺多模態能力方面已接近業界最高水平。
小紅書hi lab在上周開源的dots.ocr文檔解析模型也引起了廣泛關注,該模型以17億參數的“小模型”實現了業界領先的性能,成功登上Huggingface熱榜第七。這一系列動作表明,hi lab在AI技術自研方面正不斷加大投入,致力于拓展人機交互的可能性。
dots.vlm1的成功不僅在于其卓越的性能,更在于其背后的技術架構和訓練策略。該模型由全自研的12億參數NaViT視覺編碼器、輕量級MLP適配器和DeepSeek V3 MoE大語言模型構成,通過三階段流程進行訓練。其中,NaViT視覺編碼器從零開始訓練,原生支持動態分辨率,為模型的高分辨率輸入提供了充足的表示容量。
在預訓練階段,dots.vlm1使用了大量跨模態互譯數據和跨模態融合數據,旨在增強模型的多模態能力。這些數據涵蓋了普通圖像、復雜圖表、OCR場景、視頻幀等多種類型,為模型提供了豐富的訓練素材。通過這些數據的訓練,dots.vlm1能夠在圖文混合上下文中執行下一token預測,避免過度依賴單一模態。
對于小紅書而言,自研多模態大模型不僅是技術實力的體現,更是為了更好地理解用戶和內容,提升個性化推薦的精準度。隨著月活用戶超過3.5億,小紅書每天都會產生海量的圖文內容。如何更好地處理這些內容,讓AI更懂用戶,成為小紅書面臨的重要課題。而dots.vlm1的推出,無疑為這一課題的解決提供了有力支持。
小紅書hi lab還在不斷壯大dots模型家族,未來或將推出更多基于dots的多模態模型。這些模型有望與小紅書的應用產品緊密結合,進一步提升用戶體驗。同時,小紅書也在積極招募“AI人文訓練師”團隊,幫助AI更好地進行后訓練,以應對更加復雜和多樣化的任務。
隨著AI技術的不斷發展,多模態能力已成為通向AGI(通用人工智能)的必經之路。小紅書通過自研多模態大模型,不僅提升了自身的技術實力,也為行業樹立了新的標桿。未來,我們期待看到更多像dots.vlm1這樣的優秀模型涌現,共同推動AI技術的進步和發展。





