
在人工智能領域的一次重大動作中,OpenAI終于打破了長達六年的沉默,宣布開源兩款全新的語言模型——gpt-oss-120b與gpt-oss-20b。這一消息迅速引起了業界的廣泛關注與討論。
這兩款新模型均采用了MoE(混合專家)架構,與DeepSeek的多款模型有著異曲同工之妙。OpenAI此番開源的舉措,無疑為開發者們提供了更為豐富的選擇。而這兩款模型的最大亮點,莫過于其在部署上的高效性。gpt-oss-120b能夠在單個80GB的GPU上流暢運行,而gpt-oss-20b更是僅需16GB內存,便可在邊緣設備上大展身手,為端側AI應用提供了強有力的本地模型支持。
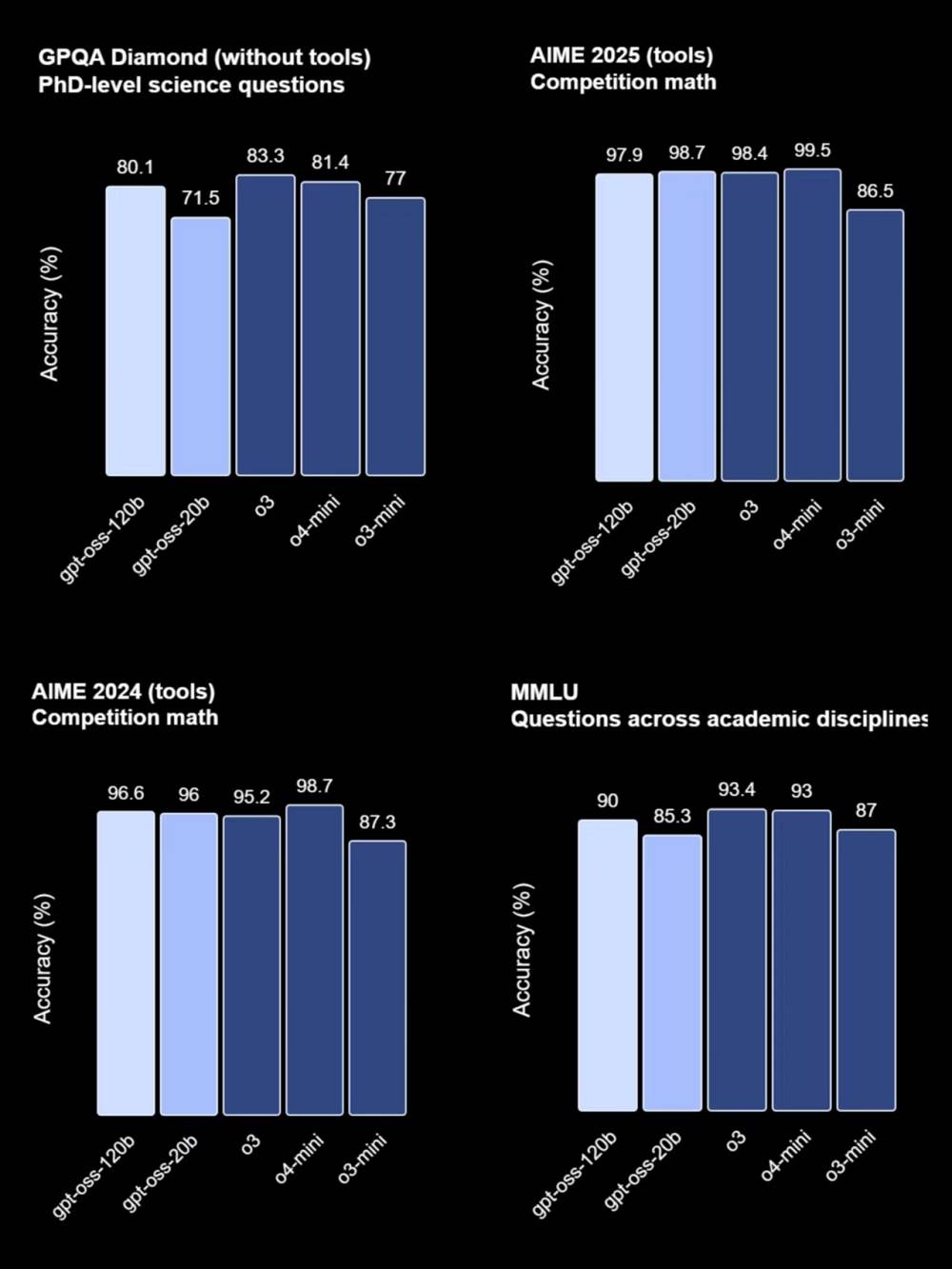
在性能表現上,gpt-oss-120b與OpenAI的o4-mini模型幾乎不相上下,而gpt-oss-20b則與o3-mini模型有著相似的表現。特別是在工具使用與小樣本函數調用方面,這兩款新模型更是展現出了強大的實力。它們還支持調整模型推理長度,進一步提升了應用的靈活性。
值得注意的是,這兩款模型還采用了MXFP4原生量化技術,使得它們在保持高性能的同時,也能夠更加節能高效。其中,gpt-oss-120b在H100 GPU上歷經210萬卡時的艱苦訓練,才得以問世;而20b版本的訓練量則僅為前者的十分之一。
面向Agent場景時,這兩款模型與OpenAI的Responses API完美兼容,可用于Agent工作流。它們不僅具備出色的指令遵循能力與工具使用能力,還支持網頁搜索與Python代碼執行等功能,推理能力同樣不容小覷。這一特性無疑將使得它們在更多應用場景中發揮出巨大的潛力。
盡管如此,gpt-oss系列模型的推出仍然得到了眾多平臺與企業的支持。目前,已有至少14家部署平臺宣布了對這兩款模型的支持,包括Azure、Hugging Face、vLLM、Ollama等知名平臺。在硬件方面,英偉達、AMD、Cerebras和Groq等至少4家企業也宣布了對gpt-oss系列的支持。其中,Cerebras更是將gpt-oss-120b的推理速度提升到了每秒超過3000 tokens,創下了OpenAI模型的最快紀錄。
如今,gpt-oss-120b與gpt-oss-20b已正式上線開源托管平臺Hugging Face,普通用戶也可以在OpenAI打造的體驗網站中直接免費試用。這一舉措無疑將進一步推動人工智能技術的發展與應用,為更多開發者與研究者提供強有力的支持。





