
在人工智能領域,一項新的突破正引發廣泛關注。meta公司近期宣布,他們利用17億張未標注圖片,通過自監督學習技術,成功訓練出了一個名為DINOv3的視覺模型。這個模型擁有70億參數,不僅在多個計算機視覺任務中刷新了性能記錄,還實現了前所未有的通用性和高效性。
DINOv3的問世,標志著自監督學習在計算機視覺領域取得了重大進展。傳統上,這類模型在訓練時嚴重依賴人工標注的數據,但DINOv3卻能夠在沒有標簽的情況下,從海量圖像中學習到豐富的特征表示。這一特性使得DINOv3特別適用于那些標注資源稀缺或成本高昂的場景,如衛星圖像處理。
meta公司不僅公開了DINOv3的預訓練模型,還慷慨地分享了完整的訓練代碼、適配器和評估工具,實現了真正的開源。這意味著研究者和開發者可以無需從頭開始,直接利用這些資源來推動自己的研究或產品開發。
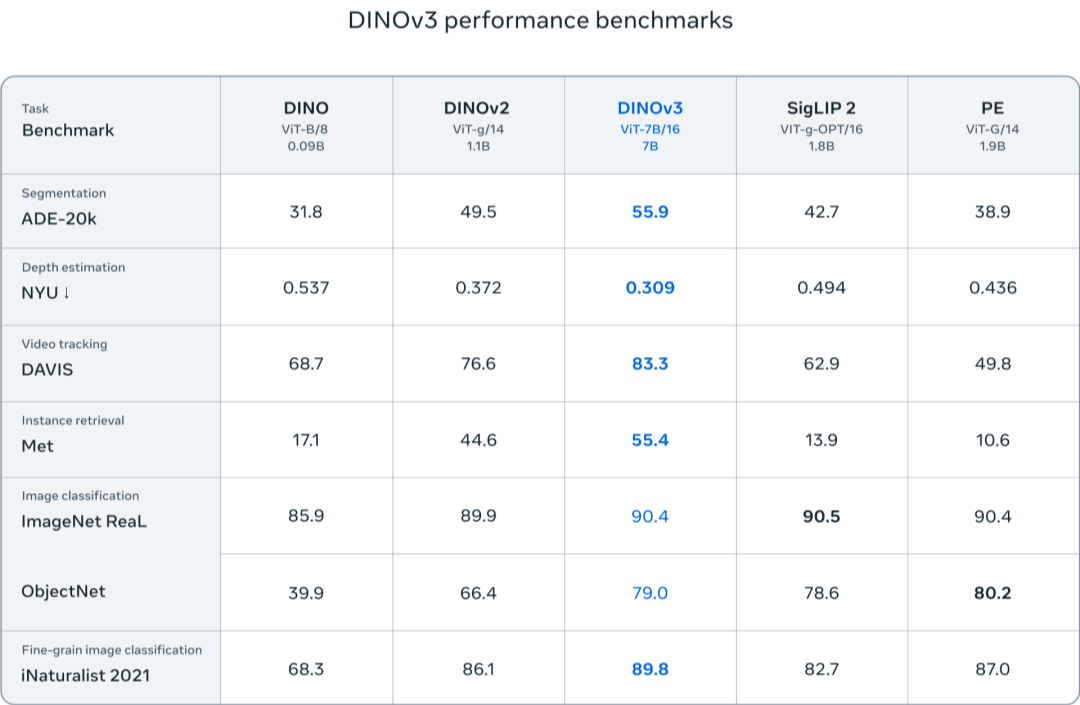
DINOv3的亮點之一是其強大的高分辨率特征生成能力。在多個密集預測任務中,如目標檢測、語義分割等,DINOv3都展現出了卓越的性能。更令人驚訝的是,它能夠在不經過微調的情況下,直接應用于這些任務,從而大大提高了處理效率和靈活性。
NASA的噴氣推進實驗室(JPL)已經率先將DINOv3應用于火星探索任務中。這一舉措不僅證明了DINOv3在極端環境下的可靠性和實用性,也為其在其他領域的應用開辟了廣闊的前景。從醫療保健到環境監測,從自動駕駛到零售制造,DINOv3都有可能成為推動這些行業進步的關鍵技術。
meta還構建了一個包含多個版本的DINOv3模型家族,以滿足不同計算需求下的應用場景。通過蒸餾技術,他們將大型模型壓縮成了更小但性能依然出色的版本,使得DINOv3能夠在各種資源限制下實現高效部署。

DINOv3的成功,是自監督學習領域的一次重大勝利。它不僅刷新了多個基準測試的成績,更重要的是,它展示了自監督學習在推動人工智能進步方面的巨大潛力。隨著技術的不斷發展,我們有理由相信,DINOv3將在未來繼續引領計算機視覺領域的新潮流。





