
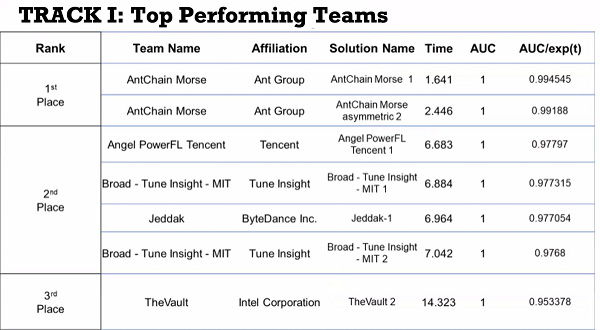
近日,2023 iDASH 國際隱私計算競賽落下帷幕,字節跳動安全研究-Jeddak可信隱私計算團隊聯合南京大學、南方科技大學、香港城市大學組建的 Jeddak Team 聯合戰隊,獲得機密計算賽道第一名、同態加密賽道第二名的優異成績。在iDASH 2022大賽上,Jeddak team首次參加大賽,即入圍可信計算和區塊鏈賽道前三。
iDASH是數據隱私與安全計算領域的國際最高規格競賽,由美國國立衛生研究院(NIH)主辦,歷年來吸引了全球頂尖高校和科技公司的積極參與。今年的大賽共吸引了來自12個國家的62支隊伍參賽,包括哈佛大學、耶魯大學、麻省理工學院、加州大學圣迭戈分校以及英特爾、騰訊、螞蟻集團、阿里巴巴等隊伍。
此次比賽設置了機密計算、同態加密、區塊鏈共3個賽道,組委會根據各賽題場景篩選出滿足要求的方案設計和代碼實現,然后從性能、精度等指標維度對各參賽隊進行排名。作為 Best-Performing Team,Jeddak team團隊成員受邀在耶魯大學舉行的 iDASH Workshop 2023 上展示了參賽方案。

賽題總覽
隱私計算是一種能夠保護數據隱私的計算解決方案,通過前沿密碼學、可信硬件等先進技術手段,為用戶提供安全合規的數據流通交易與融合共享,以此發揮更大價值;同時也滿足了數據的“可用不可見”。隱私計算通常可由“軟/硬”兩類技術實現:前者本質是圍繞數據自身做隱私保護,例如此次賽道之一的同態加密;而后者是對數據所處的計算環境做安全防護,例如另一賽道的機密計算。一般情況下的常規計算都是在數據明文基礎上進行的,而同態加密計算是指:在其對應的密文基礎上執行運算。兩者分別針對明、密文數據的基本操作,如加法和乘法也都是一一對應的、并且最終計算結果相同;區別只是其中之一被加密,所以只有該數據的所有者因掌握了密鑰才能解密獲得結果。形象地講,兩者是計算等效的“平行世界”關系,其中同態加密額外提供了隱私保護能力,因為在整個過程中數據始終處于密態。另外一類以硬件機制為代表的機密計算,可簡單理解為:構建了一個與外界隔離的沙箱環境,于是敏感數據在里面的計算使用不受干擾,實現了機密性和完整性保護。
在生物信息領域,一方面對個人數據的隱私保護至關重要,另一方面醫療單位和研究機構又迫切需要打通各方數據。因此,隱私計算已逐漸成為該領域的關鍵技術,促進多方共同參與、合規挖掘利用數據的寶貴價值:來自不同數據源的生信數據經過加密處理后,存儲在具備隱私計算能力的云平臺上,進而為泛在數據使用提供所需服務。例如,隱私計算能夠幫助醫療、保險機構利用個體基因數據有效地預測潛在疾病風險,從而作出綜合評判。研究人員也可以通過隱私計算挖掘數據多維度價值,建立精準模型輔助診療、加速新藥物研發等,推動生物信息領域的研究和應用創新。
在本屆iDASH競賽中,機密計算賽道要求在確保全過程基因數據的安全隱私前提下,實現高效的基因組推斷。Jeddak團隊提出了基于可信執行環境(TEE)的解決方案,該方案可以有效應對各類高負載的計算任務(如數據清洗、結構預測、差異表達分析、突變檢測等),不但能夠準確完成、同時也提供了能效更高的安全隱私保障。
同態加密賽道要求根據基因數據的密文、來識別基因樣本和基因數據庫之間的親屬關系。Jeddak團隊通過分析基因數據的特征,提出了親屬關系判別算法,以及相應的基因數據編碼方式和高性能密文計算方案。不僅能夠高效處理基因組數據,還適用于各種高維度的隱私數據密態分析。

機密計算賽道揭秘
機密計算賽題是加固并優化現有的基因組推斷算法PanGenie,以提高其在處理人類基因數據過程中的計算性能與數據安全。目前,變異感知的泛基因組圖(Variation-aware Pangenome Graph)已成為一種更為有效的人類參考基因組表示形式,而短序列片段測序(Short-reads Sequencing)由于其高效性和低成本仍然是最實用的測序方式。PanGenie則是基于這兩類信息設計的一類高效基因組推斷算法。今年的iDASH競賽首次引入了基于AMD SEV技術的可信執行環境,以確保在數據處理過程中的安全隱私性。此外,比賽還對資源使用進行了嚴格限制,規定參賽隊伍最多使用2臺虛擬機,每臺虛擬機只能使用4個計算核心,并要求可信計算基(TCB)不超過1MB。本次比賽主要考察機密計算系統的設計與優化水平。
針對本次賽題的考核要求,Jeddak Team對指定算法PanGenie與其實現進行了細致全面的分析,從并行化、內存優化、執行流程優化、編譯期優化等多個角度對原有實現進行了重構創新,在保證方案的安全性前提下,高效發揮利用給定的計算資源、突破能效瓶頸。下面介紹Jeddak Team方案的主要優化點:
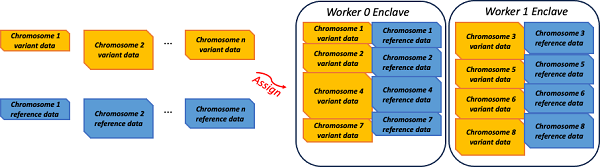
首先參考下圖,Jeddak Team基于賽題中最多使用2臺虛擬機的條件,將整個基因組推斷的工作負載拆分到了2個虛擬機中并行執行。而在每個工作節點(Worker)中,工作流被分為了兩個階段:預處理階段和PanGenie工作負載階段。
預處理階段
1. 在本階段,2個工作節點首先會對預先放置于其磁盤內的數據文件進行數據提取,該過程中節點會提取出數據中的關鍵信息,用作后續的參數選擇。
2. 在前期調研中Jeddak Team發現:一個關鍵的哈希表的大小會對整體的性能造成極大的影響,而適當地選擇較大的規模會比選擇小哈希表所造成的開銷少很多。為此Jeddak Team采用了自適應的哈希表規模選取策略,會根據實際的數據規模自適應地選擇參數。
3. 在實際情況下,一份樣本包含了多個染色體,而不同染色體對應的基因數據的分布并不均衡,所以簡單粗暴地按照編號來進行分配會導致工作節點負載的不平均,為此Jeddak Team采用了貪心算法以實現節點間的負載均衡。
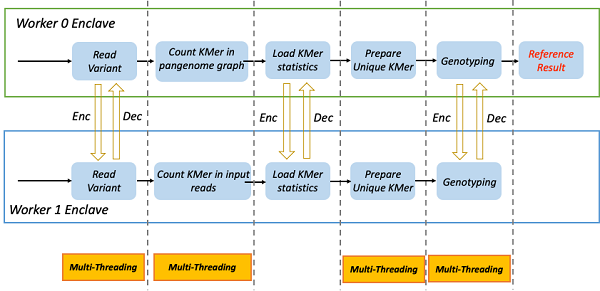
PanGenie工作負載階段
在這個階段工作節點會根據分配到的染色體編號來并行化數據處理,因為每個染色體對應的計算邏輯是獨立的。于是能夠最大發揮工作節點的計算能力。
由于任務是分配到2個節點上執行,該過程中需要對統計信息(Read Variant、Load KMer Statistics)、計算結果(Genotyping)進行同步,Jeddak Team對所有的通信數據進行加密以保證數據安全。
針對PanGenie的工作負載階段,Jeddak Team也采用了多個優化方案來一并提高整體的算法執行效率:
● PanGenie算法中使用了隱馬爾可夫模型(Hidden Markov Model,HMM)來進行基因型的推斷,Jeddak Team針對算法中HMM的發射概率以及轉移概率進行了優化。具體來說,Jeddak Team通過預處理部分概率值,降低每次實時計算的開銷,從而減少了整個HMM在計算過程中的復雜度。
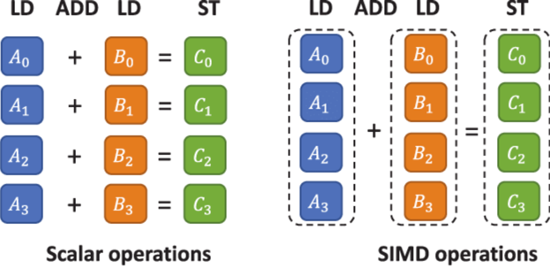
● 充分發揮AMD CPU提供的AVX指令集來提高對浮點型數據處理的效率。相較于分別計算多個浮點數,Jeddak Team通過單指令流多數據流(Single Instruction Multiple Data,SIMD)技術,實現了對四個浮點數的同時運算,從而成倍提高了計算效率。
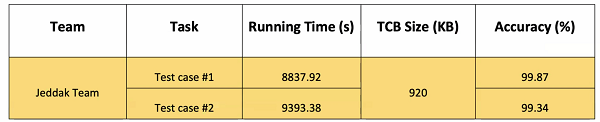
根據主辦方設置的兩個測試樣例,Jeddak Team的方案在僅使用2臺安全虛擬機、共計8個可用線程的嚴格限制下,最多耗費2.6小時就運行完成了測試,成為機密計算領域13個參賽隊伍中唯一完賽的團隊;同時Jeddak Team的方案保證了準確率在99%以上,且可執行代碼(TCB)也僅有920KB大小。
整個方案是Jeddak Team聯合香港城市大學、南方科技大學共同設計與實現。最終在本屆iDash大賽上取得了第一名的優異成績。
同態加密賽道揭秘
同態加密賽題設定的場景是:法醫鑒定時,檢查機構使用嫌犯基因、向數據機構的基因數據庫去查詢是否存在嫌疑人的親屬,從而快速定位嫌疑人身份。賽題要求檢查機構和數據機構的基因數據都需要使用同態加密技術保護,數據經過加密后會交由一個第三方計算機構進行密文預測,最后得到的密文結果可以被檢查機構解密作為判斷親屬關系的依據。
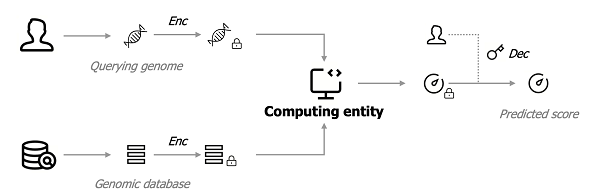
比賽要求判別400條查詢樣本在一個擁有2000條基因數據的數據庫中是否存在親屬。其中正負查詢樣本的數量相同。在整個計算流程中,檢查機構與數據機構的基因數據不能被泄露,計算機構必須在密文狀態下處理基因數據,并且檢查機構與數據機構在數據加密前不能進行相關預處理,即提高了系統能效要求。為此,Jeddak Team基于全同態技術提出了兩種安全高效的密文關系預測方案。
在第一個方案中,Jeddak Team分析了基因數據的特點:發現當一條待查詢的基因數據在數據庫中存在親屬時,它更有可能與數據庫樣本維度的中心點有較大的距離。進一步講,如果將基因數據與數據庫中心、待查詢數據集中心的距離相減,這種距離差異可以更清晰地劃分有、無親屬關系的查詢樣本。
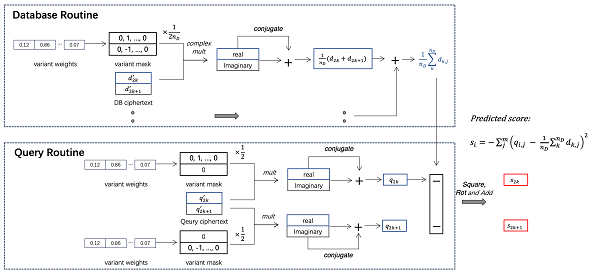
基于以上數據集特點,Jeddak Team設計了使用同態加密方案來計算樣本距離數據庫、查詢數據集中心的距離差異。Jeddak Team將距離差異的計算方法優化成若干加減法和一次內積運算組成的算法。在加密數據時,Jeddak Team采用CKKS加密算法并通過系數編碼的方式將多個基因數據加密到一條密文多項式的系數上。基于這種編碼方式,可以通過一次多項式乘法計算出兩組密文數據向量的內積,從而得到一條樣本對應的預測得分。查詢機構可以解密、并根據得分大小判斷出查詢樣本是否在數據庫內存在親屬的可能性。
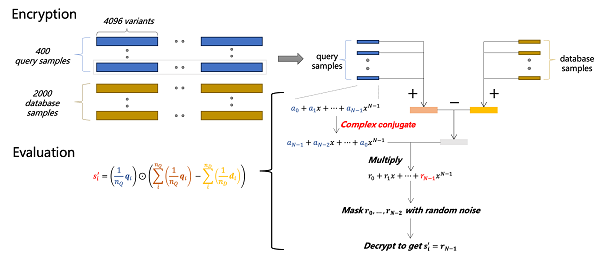
第二個方案則是從直觀認識出發:如果兩條基因數據存在親屬關系,那它們應當有更小的距離。基于此,Jeddak Team首先通過條件概率的方法,計算得到每個等位基因對判斷樣本親屬關系的權重。實操中選取1000個權重值最大的基因作為判別親屬關系的依據。該方案使用了被選取的基因來計算每個查詢樣本與數據庫中心點的距離,從而作為每個樣本的預測結果。
Jeddak Team依然采用CKKS算法實現了第二個方案,并利用復數的特點將每兩個相鄰的查詢數據加密分別加密到同一條密文的實部和虛部。在密文計算的過程中,Jeddak Team首先將被選取基因的明文掩碼作用在每一條加密數據上,然后將計算后的數據庫中心點和每條查詢數據均提取到密文的實部上。最終,查詢樣本與數據庫中心點的距離可以通過密文乘法和移位操作完成。
上述兩個方案是Jeddak Team與南京大學共同設計與實現,最終在iDASH 2023競賽中以0.977的得分獲得了第二名的成績。
Jeddak可信隱私計算平臺
iDASH競賽通常設定的是醫學場景,因為醫療數據極其敏感,故要求使用隱私計算技術在密態數據基礎上執行運算,從而既實現業務目標、又保障數據的安全隱私。此次Jeddak Team所使用的核心技術均源于自研的Jeddak可信隱私計算平臺,涵蓋機密計算、聯邦學習、多方安全計算、同態加密、差分隱私、區塊鏈等多種形態的產品技術。據悉,Jeddak可信隱私計算平臺近兩年在字節內外實施了70余個隱私計算相關項目,典型如ToB側火山引擎和公司內部的抖音用數管控等。
隱私計算在數據要素價值釋放過程中發揮著越來越重要的作用,但因處于早期發展階段,無論相關技術、產品和市場都亟待深入探索。字節跳動安全研究團隊基于Jeddak的大量應用實踐,總結出隱私計算基礎建設的三個關鍵問題:技術突破、產品創新、領域洞察,以下簡要介紹Jeddak Team的相關工作。
● 技術突破:核心是解決隱私計算的能效問題。例如此次iDASH競賽,不但要求分析建模精準安全、而且對計算能效也提出很高要求。尤其是后者,被認為是隱私計算大規模應用和產業化的主要瓶頸。為此Jeddak Team從相關理論創新到工程優化的多個層面做了大量努力,包括自主研發更高效的安全協議、硬件加速、以及特有的隱私計算網絡等,已全面接入內外部業務。基于有限資源使用、端到端全鏈路執行效果如:百億級數據的PSI隱私求交50分鐘完成;億級千維數據的XGB聯邦學習訓練約4小時完成、十億級推理40分鐘內完成;面向百億級數據的PIR匿蹤查詢約4小時完成;億級數據的MPC多方安全計算聚合查詢約1小時完成。這些真實業務場景下的能效突破,不但體現了Jeddak的技術先進性、也奠定其成為工業級產品的基礎。
● 產品創新:現階段隱私計算產品的表現形式相對單一,主要面向解決數據流通共享中的一些特定隱私保護問題,缺乏廣泛賦能的平臺級和殺手級應用。原因除了上述能效問題外,也缺乏集中呈現的豐富場景、以驅動更多嘗試探索。Jeddak Team充分結合公司內外部大量實際需求不斷實踐,逐步形成了隱私計算產品的三類應用范式:(1)與數據基礎設施融合。即隱私計算能力下沉、完整接管上游業務的用數過程。例如,針對抖音業務中臺的用數申請以滿足多源數據共享的聯合建模需求,Jeddak不但為此實現了數據的安全隱私保護及其所有權和使用權分離,同時也示范了隱私計算與大規模基礎設施的深度融合實踐。(2)與數據產品融合。目的是把隱私計算功能集成進數據套件以方便用戶觸達,例如以插件的形式結合。于是當使用套件服務來處理敏感數據時,便可直接開啟保序加密、同態加密等功能,完成相關密文計算,類似把ChatGPT能力與Office套件的各種應用關聯打通。另一類創新是,Jeddak數據安全沙箱與一方敏感數據組合并集成進便攜式服務器,形成數信一體機產品,從而滿足用戶數據不出域條件下、在TEE內實現了多源數據的安全匯聚計算。(3)與數據應用開發工具融合。目標是輔助用戶便捷拓展領域應用,例如Jeddak聯邦學習已嵌入公司AI推薦平臺、并配套研發了支持調用的SDK工具。使得平臺上游業務可同時獲取到聯邦學習能力、輕易構建出自己的AI隱私計算應用,從而打通利用更多敏感數據源、大幅提升建模質量,其作用類似于大模型的領域開發工具鏈LangChain。從實踐效果看,這三種應用范式基本覆蓋和滿足了公司內外業務的相關需求,摸索出隱私計算廣泛賦能的實施方法和路徑。
● 領域洞察:除了技術突破和產品創新外,還需深入結合業務的屬性特征才能發揮隱私計算的最大效用。原因在于,利用這些特定約束可助力實現成本控制與目標達成的最佳平衡。例如,基于可信計算的Jeddak數據安全沙箱大量服務了公司職能線(e.g.人力/財務/研效等),其業務場景特征是:數據流轉共享常見、處理邏輯靈活多變、且有準實時計算要求。對此Jeddak充分結合利用了TEE技術特長和業務特點,體現出較高實施效用。另一類典型案例如,一些金融行業的應用對安全隱私提出極高要求,為此Jeddak Team基于多方安全計算MPC技術、設計實現了全密態機器學習系統以滿足數學可證安全性,并且在營銷預測建模場景中實際落地。因此,對業務領域的深入洞察不但能幫助提升應用效果、甚至可挖掘和推動更多的技術服務創新。
對于隱私計算的應用發展還有兩類問題特別值得關注。一是對私域數據的保護和價值重視:很多實體往往并不清晰自身數據的潛在效用,平時可能疏于積累和防護,而最近GPT4 Turbo展現的基于私域數據的微調、能夠為用戶創建出高質量領域大模型,凸顯其重要性。二是從頂層設計的高度來推動隱私計算的大規模應用、賦能數字經濟:除了產業政策促進外,AI大模型的普及很可能是重要的需求牽引。為此Jeddak Team正積極探索相關技術,包括基于軟件實現的大模型聯邦精調、以及構建由GPU所組成的可信計算環境。
Jeddak Team相關負責人表示:“本次iDASH競賽檢驗了自身能力水平,同時也學習到很多先進經驗,期待未來與業界伙伴密切交流合作,共同推進隱私計算的技術進步與蓬勃發展。”(作者:范宇棟)





