
7月14日消息,當貝AI正式推出“雙模型回答”功能,通過同時調用兩個獨立訓練的AI模型對用戶提問進行解答,并呈現對比結果,幫助用戶快速篩選更優答案。這一更新標志著當貝AI在智能交互效率與準確性上邁出關鍵一步,同時保留了其原有的核心功能優勢,形成“高效對比+全能服務”的雙重體驗。
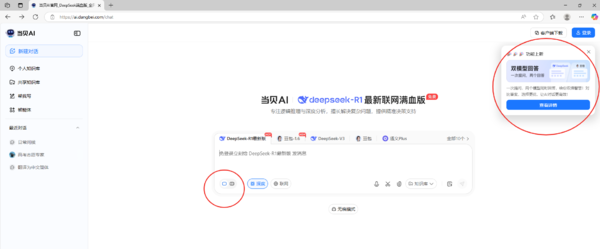
雙模型回答:一次提問,雙重保障
當貝AI的雙模型回答功能基于“并行計算+對比優化”架構設計。當用戶輸入問題后,系統會同步啟動兩個經過不同數據訓練的AI模型:
模型A:側重邏輯分析與結構化輸出,擅長處理技術類、步驟類問題(如設備故障排查、功能設置指南);
模型B:聚焦語義理解與自然語言生成,更適合生活類、創意類問題(如影音推薦、文案創作)。
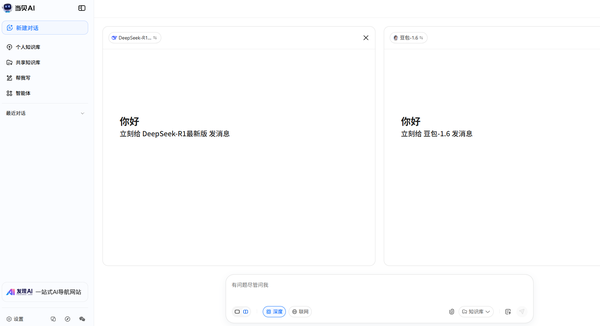
兩個模型獨立運行,最終答案以分欄形式并列展示,用戶可直觀對比內容細節、邏輯嚴謹性及表述風格。這一設計有效解決了單一模型可能存在的知識盲區或表述偏差問題,尤其適用于復雜問題或高精度需求場景。
當貝AI全場景覆蓋,打造智能生態中樞
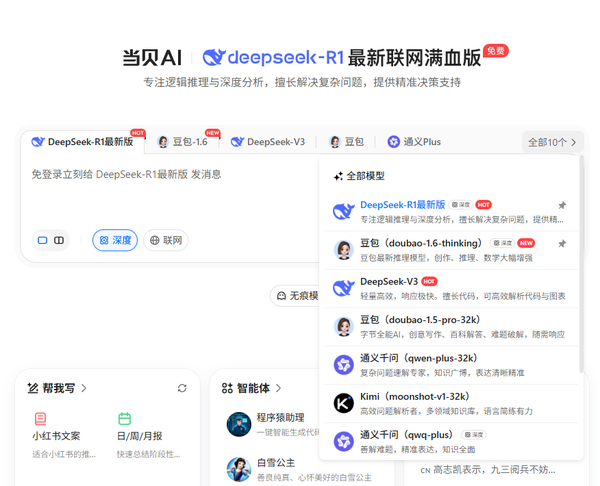
當貝AI之所以能在眾多智能服務平臺中脫穎而出,一大亮點在于其深度整合了多個頂尖大模型,像DeepSeek - R1 671B滿血版、DeepSeek - V3、豆包、通義千問、Kimi等。用戶能夠依據不同的任務需求,自由且靈活地切換模型。就拿DeepSeek - R1 671B滿血版來說,它具備高達6710億的參數規模,在代碼生成、法律咨詢等復雜場景中表現極為出色。這種“多模型聚合”的模式十分巧妙,它成功避免了單一模型存在能力短板的問題,讓用戶可以“按需調用”最優工具,進而顯著提升任務執行效率,真正達成了智能服務的高效與精準。
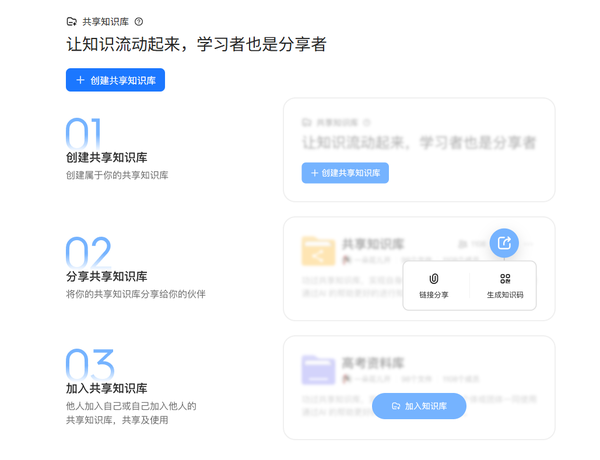
除了強大的模型聚合能力,當貝AI在知識管理方面也有著卓越表現。其知識庫容量突破一億字,支持用戶上傳PDF、Word、Excel、圖片等多格式文件。系統會運用自研的NLP技術自動解析文件內容,并生成結構化知識圖譜。對于個人用戶而言,可將PDF、Word等各類文檔上傳至個人知識庫,借助自然語言處理構建專屬的結構化知識體系;而在團隊協作場景中,如企業項目管理、教育機構資源共享等,共享知識庫則發揮著重要作用,它通過權限分級來保障數據安全,實現跨部門的知識沉淀與共享。
在數據使用與安全保障上,當貝AI同樣考慮周全。它支持PC端、網頁端、移動端(蘋果、安卓)多設備同步,用戶能夠隨時隨地使用,不受設備和地點的限制,輕松實現數據的實時共享與同步。同時,采用“本地優先”策略,敏感數據處理均在端側完成,僅在需要聯網時通過加密通道與云端交互,并且用戶可以自主選擇數據共享范圍,有效降低了數據泄露的風險。此外,還提供無痕模式,對話記錄僅存儲于用戶設備,關閉窗口后便會自動清除,全方位確保用戶的隱私安全。
當貝AI的應用場景十分廣泛,在寫代碼、做PPT、查股票、制定旅游攻略、詢問生活常識等方面都表現出色,尤其適合創作者、職場人士和學生群體。創作者可以利用它快速獲取創作靈感和素材,職場人士能借助它提升工作效率,學生則可通過它輔助學習。
總之,當貝AI憑借其豐富的功能特點和卓越的性能表現,為用戶提供了全方位、個性化的智能服務。無論是個人日常使用,還是團隊協作辦公,當貝AI都能成為用戶的得力助手,助力用戶在不同場景下高效完成任務。





