擊這里在線咨詢客服")
12 月 7 日消息,OpenAI 啟動了為期 12 天的“shipmas”新品發(fā)布周期,將推出一系列新功能、新產(chǎn)品以及相關(guān)演示。本次活動第二日,OpenAI 推出了強(qiáng)化微調(diào)(Reinforcement Fine-Tuning),幫助開發(fā)者和機(jī)器學(xué)習(xí)工程師打造針對特定復(fù)雜領(lǐng)域任務(wù)的專家模型。
該項(xiàng)目通過全新的模型定制技術(shù),讓開發(fā)者可以使用高質(zhì)量任務(wù)集對模型進(jìn)行微調(diào),并利用參考答案評估模型的響應(yīng),從而提升模型在特定領(lǐng)域任務(wù)中的推理能力和準(zhǔn)確性。
強(qiáng)化微調(diào)簡介
IT之家附上官方介紹:開發(fā)人員能夠使用數(shù)十到數(shù)千個高質(zhì)量任務(wù),定制 OpenAI 的模型,并使用提供的參考答案對模型的響應(yīng)進(jìn)行評分。官方表示這項(xiàng)技術(shù)強(qiáng)化了模型推理類似問題的方式,并提高了其在該領(lǐng)域特定任務(wù)上的準(zhǔn)確性。

與標(biāo)準(zhǔn)微調(diào)不同,RFT 利用強(qiáng)化學(xué)習(xí)算法,可以將模型性能從高中水平提升到專家博士水平。
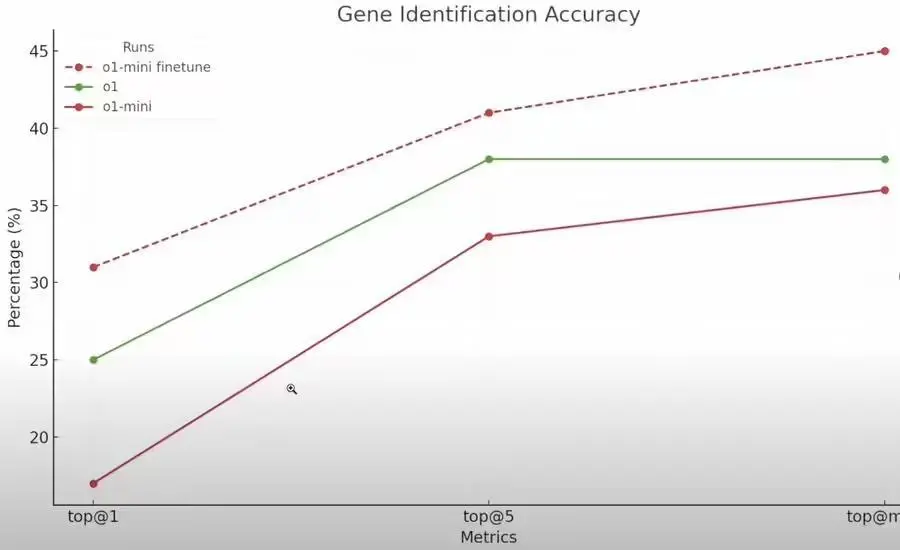
RFT 與監(jiān)督式微調(diào)不同,它不是讓模型模仿輸入,而是教模型以全新的方式進(jìn)行推理,通過對模型答案進(jìn)行評分并強(qiáng)化正確的推理路線,RFT 只需少量示例即可顯著提高模型性能。
RFT 支持用戶利用自己的黃金數(shù)據(jù)集創(chuàng)建獨(dú)特的模型,并將其應(yīng)用于法律、金融、工程、保險(xiǎn)等需要專業(yè)知識的領(lǐng)域。
強(qiáng)化微調(diào)面向群體
OpenAI 勵研究機(jī)構(gòu)、高校和企業(yè)申請,特別是那些目前由專家領(lǐng)導(dǎo)執(zhí)行一系列狹窄復(fù)雜任務(wù),并且將受益于人工智能協(xié)助的機(jī)構(gòu)。
OpenAI 表示強(qiáng)化微調(diào)在結(jié)果具有客觀“正確”答案,且大多數(shù)專家會同意的任務(wù)中表現(xiàn)出色,因此認(rèn)為在法律、保險(xiǎn)、醫(yī)療、金融、工程等領(lǐng)域會有更好的表現(xiàn)。
參與者可提前訪問 Alpha 版強(qiáng)化微調(diào) API,并在特定領(lǐng)域任務(wù)中進(jìn)行測試,此外 OpenAI 鼓勵參與者分享數(shù)據(jù)集,共同改進(jìn) OpenAI 模型。
OpenAI 預(yù)計(jì) 2025 年初公開發(fā)布強(qiáng)化微調(diào)功能。
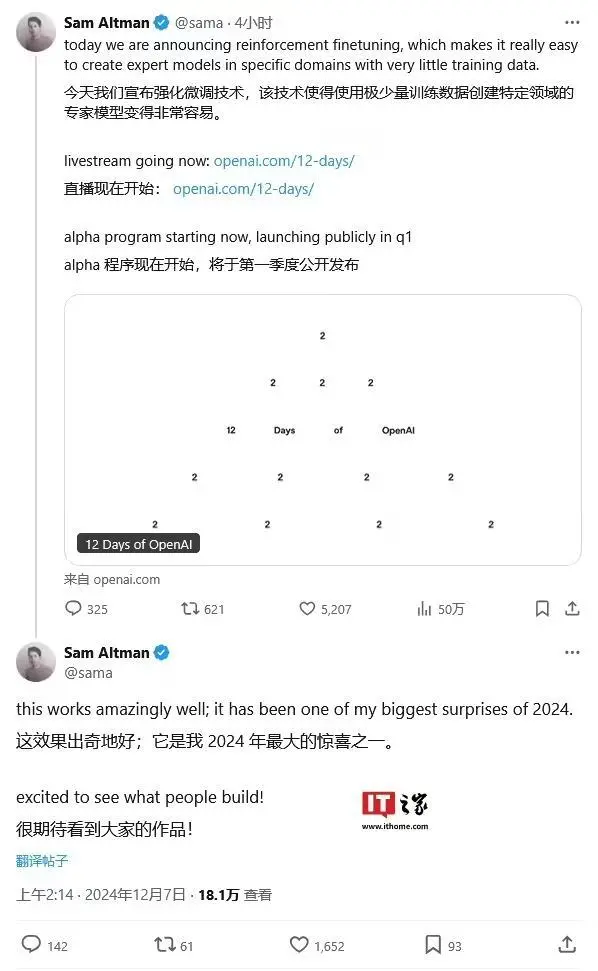
OpenAI 首席執(zhí)行官山姆?阿爾特曼(Sam Altman)表示:“強(qiáng)化微調(diào),效果出奇地好;它是我 2024 年最大的驚喜之一。”
【來源:IT之家】





