擊這里在線咨詢客服")
一、彈性伸縮技術(shù)實(shí)踐
1.全網(wǎng)容器化后一線研發(fā)的使用問題
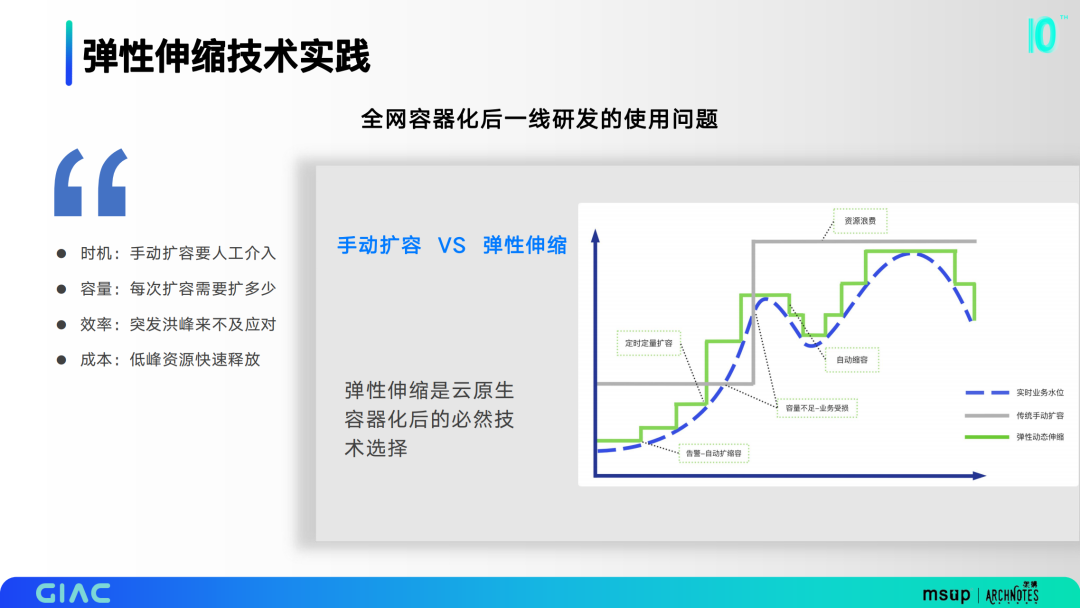
全網(wǎng)容器化后一線研發(fā)會面臨一系列使用問題,包括時機(jī)、容量、效率和成本問題,彈性伸縮是云原生容器化后的必然技術(shù)選擇。
2.使用原生彈性HPA遇到的問題
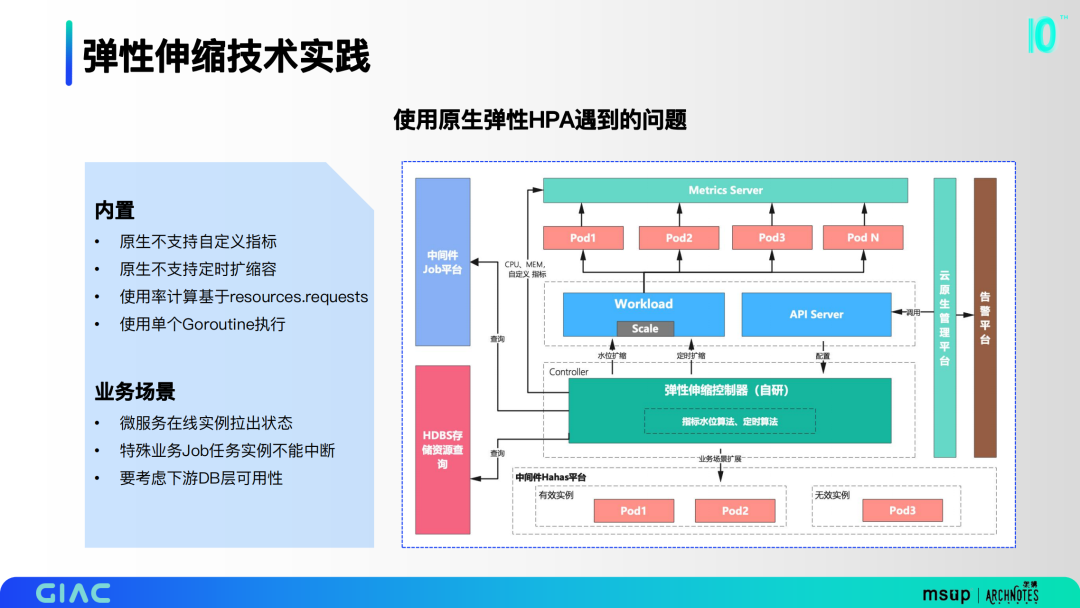
當(dāng)時第一時間考慮用原生HPA組件,但在實(shí)際調(diào)研和小規(guī)模使用的時候發(fā)現(xiàn)了很多問題。一方面是內(nèi)置的問題,如原生不支持自定義指標(biāo)和定時擴(kuò)縮容,使用率計(jì)算基于resources.requests,使用單個Goroutine執(zhí)行。更大的痛點(diǎn)在業(yè)務(wù)場景上,微服務(wù)在線實(shí)例拉出狀態(tài),特殊業(yè)務(wù)Job任務(wù)實(shí)例不能中斷,要考慮下游DB層可用性。
3.基于業(yè)務(wù)實(shí)例實(shí)際水位、有效負(fù)載的彈性能力
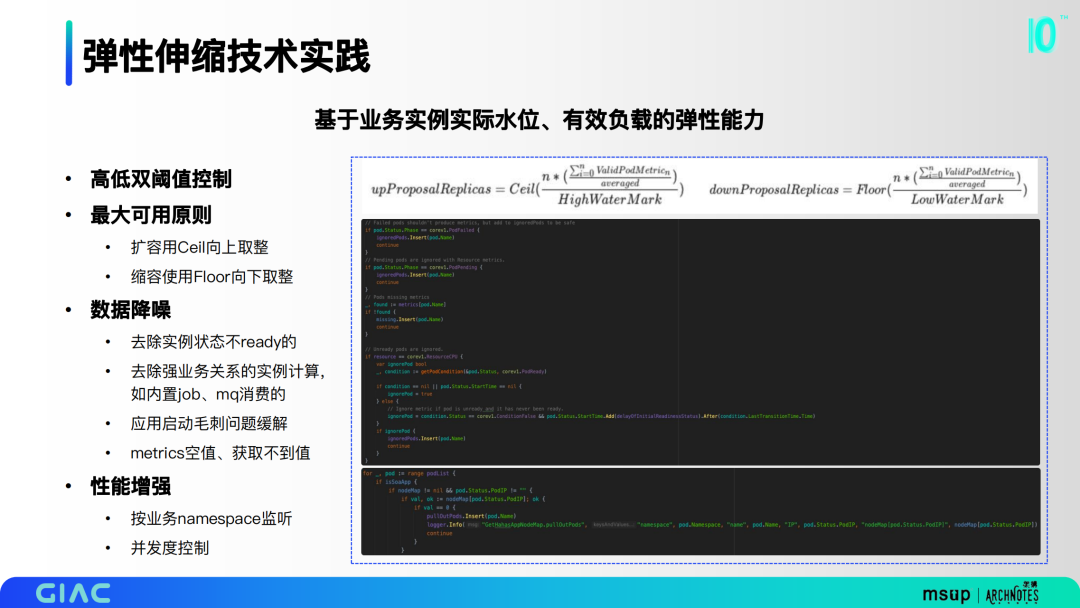
我們基于業(yè)務(wù)實(shí)例實(shí)際水位、有效負(fù)載構(gòu)建彈性能力。
- 高低雙閾值控制,像一些有浮動的業(yè)務(wù),可以盡量把底層的穩(wěn)定性去做有效的約束;
- 最大可用原則,擴(kuò)容用Ceil向上取整,縮容使用Floor向下取整;
- 數(shù)據(jù)降噪,去除實(shí)例狀態(tài)不ready的,去除強(qiáng)業(yè)務(wù)關(guān)系的實(shí)例計(jì)算,應(yīng)用啟動毛刺問題緩解,metrics空值、獲取不到值;
- 性能增強(qiáng),按業(yè)務(wù)namespace監(jiān)聽,實(shí)現(xiàn)并發(fā)度控制。
4.水位閾值彈性和定時彈性的融合實(shí)現(xiàn)

這里同時做了水位閾值彈性和定時彈性的融合,保證單個的應(yīng)用能夠同時使用閾值和定時彈性。基本原則是擴(kuò)容時大者取大,縮容時不能低于定時副本數(shù)。
5.業(yè)務(wù)使用彈性后的生產(chǎn)效果
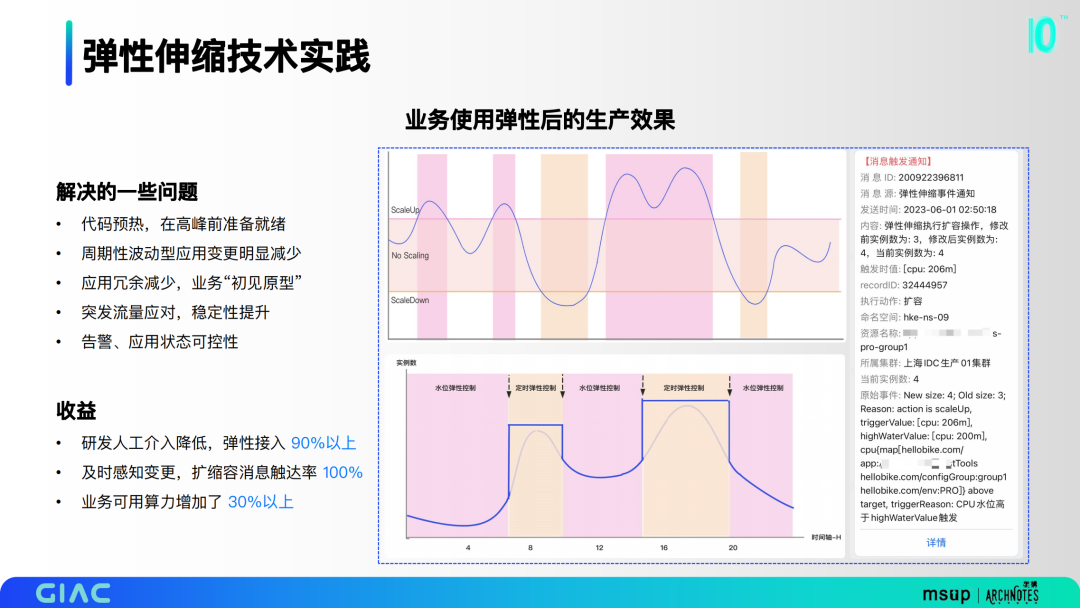
業(yè)務(wù)使用彈性后產(chǎn)生了一定的效果,如圖是高低閾值和定時的區(qū)間。這里解決了一些問題:
- 代碼預(yù)熱,在高峰前準(zhǔn)備就緒;
- 周期性波動型應(yīng)用變更明顯減少;
- 應(yīng)用冗余減少,業(yè)務(wù)“初見原型”;
- 突發(fā)流量應(yīng)對,穩(wěn)定性提升;
- 告警、應(yīng)用狀態(tài)可控性。
最終彈性接入90%以上,擴(kuò)縮容消息觸達(dá)率100%,業(yè)務(wù)可用算力增加了 30%以上。
6.混合云模式下的 ClusterAutoScale

集群可用資源變多,不等于整體開支降低,因此我們考慮去做混合云模式下的ClusterAutoScale。這里有一些關(guān)注點(diǎn),包括鏡像即服務(wù)、CloudProvider 適配、節(jié)點(diǎn)初始化和節(jié)點(diǎn)回收。

右圖是基本流程,有兩個觸發(fā)策略,一是基于不可調(diào)度事件,二是基于資源池水位閾值。這里我們也解決了一些問題,包括 CloudProvider 對接私有云資源API,Pod網(wǎng)段分配域路由宣告,私有云可用容量評估及資源打散,以及資源灰度回收邏輯。
7.注意事項(xiàng)

在實(shí)際業(yè)務(wù)時生產(chǎn)使用的時候,有很多關(guān)注點(diǎn),包括業(yè)務(wù)池的容量、應(yīng)用維度的實(shí)例波動率標(biāo)準(zhǔn)、存活探測和就緒探測的接口區(qū)別、指標(biāo)閾值和彈性規(guī)則的合理性巡檢、不做過多filter、不強(qiáng)依賴其他系統(tǒng)平臺。
二、中間件容器化及混部填谷
1.業(yè)務(wù)獨(dú)立池水位與混部預(yù)期
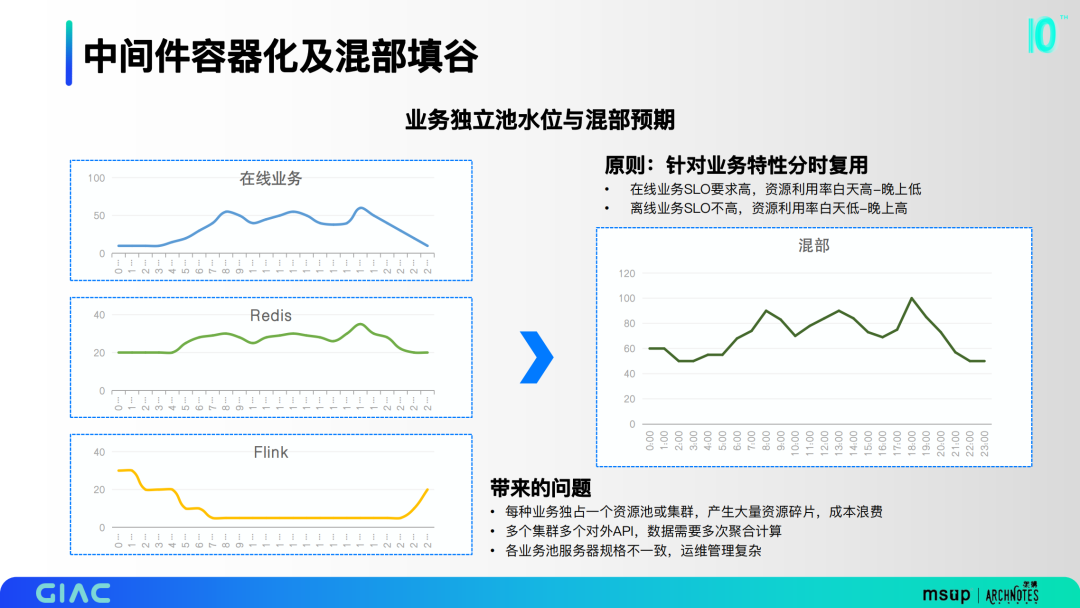
針對業(yè)務(wù)特性,將redis和flink資源池進(jìn)行融合,達(dá)到分時復(fù)用的效果。之前的形態(tài)會帶來很多問題:
- 每種業(yè)務(wù)獨(dú)占一個資源池或集群,產(chǎn)生大量資源碎片,造成成本浪費(fèi);
- 多個集群多個對外API,數(shù)據(jù)需要多次聚合計(jì)算;
- 各業(yè)務(wù)池服務(wù)器規(guī)格不一致,運(yùn)維管理復(fù)雜。
2.混部的總體思路
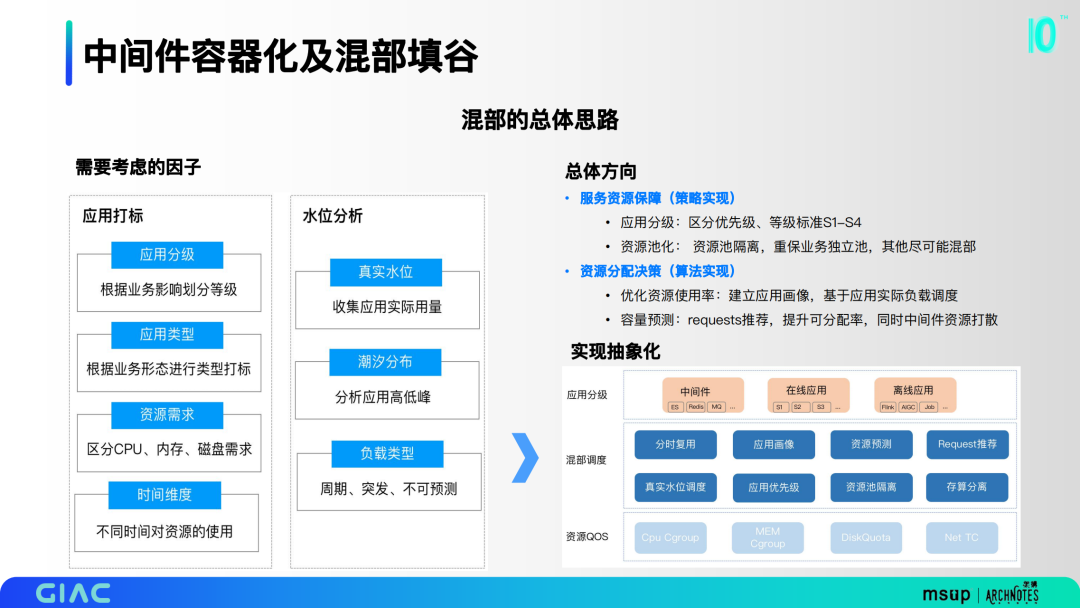
混部里面這里做了一些思考,考慮了應(yīng)用分級、資源需求、潮汐分布等等。將這些因子抽象歸納,分為應(yīng)用分級、混部調(diào)度、資源QOS三層。我們也確定了幾個總體方向,包括服務(wù)資源保障的策略實(shí)現(xiàn)和資源分配決策的算法實(shí)現(xiàn)。

在服務(wù)資源保障上,主要是對應(yīng)用分級打標(biāo)。我們把所有的業(yè)務(wù)做了S1-S4的分級,并落到了CMDB里,最終落到K8S的優(yōu)先級標(biāo)簽里面。第二部分是資源池化,優(yōu)先去考慮以底層的業(yè)務(wù)為重保,把一些優(yōu)先級較低的應(yīng)用分別打散到各個資源池。
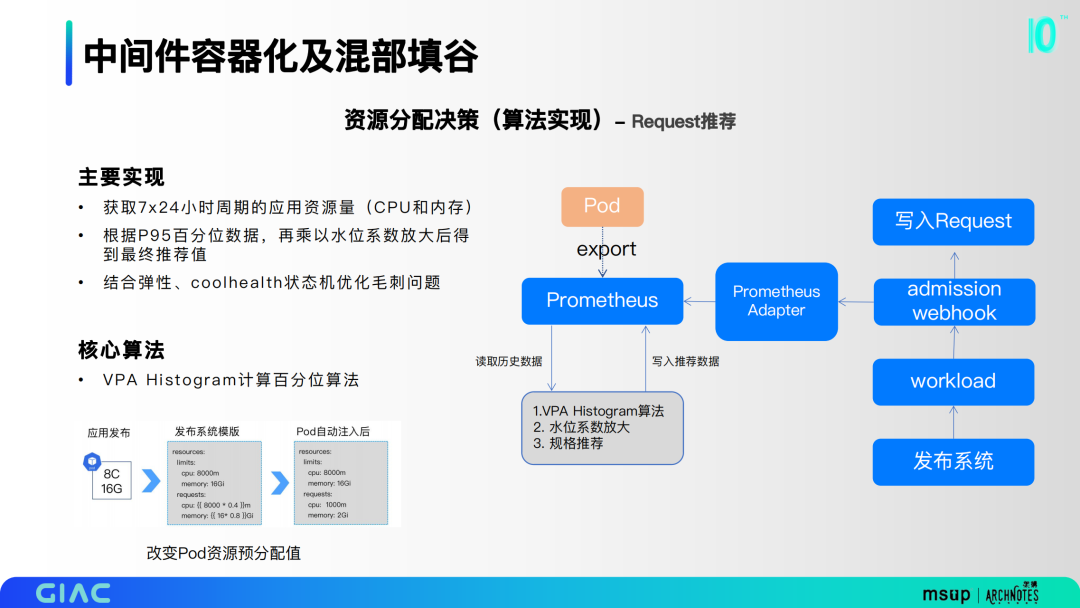
在資源分配決策上, 第一部分是Request推薦。主要基于VPA Histogram計(jì)算百分位算法,通過獲取7x24小時周期的應(yīng)用資源量,根據(jù)P95百分位數(shù)據(jù),再乘以水位系數(shù)放大后得到最終推薦值,并結(jié)合彈性、coolhealth狀態(tài)機(jī)優(yōu)化毛刺問題。
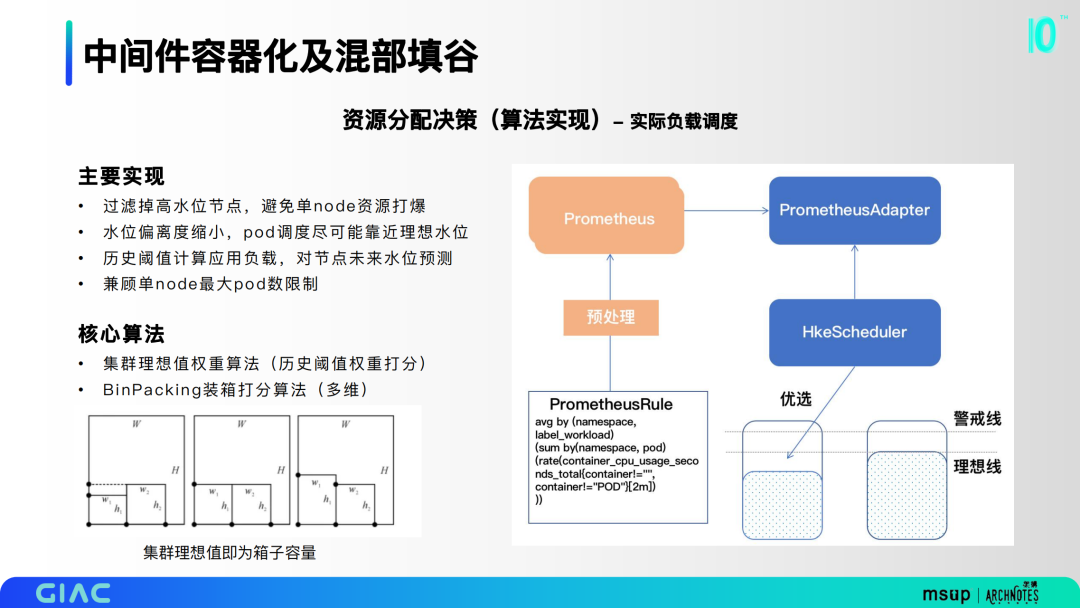
第二部分是實(shí)際負(fù)載調(diào)度,主要基于集群理想值權(quán)重算法和BinPacking裝箱打分算法。過濾掉高水位節(jié)點(diǎn),避免單node資源打爆;水位偏離度縮小,pod調(diào)度盡可能靠近理想水位;歷史閾值計(jì)算應(yīng)用負(fù)載,對節(jié)點(diǎn)未來水位預(yù)測;兼顧單node最大pod數(shù)限制。
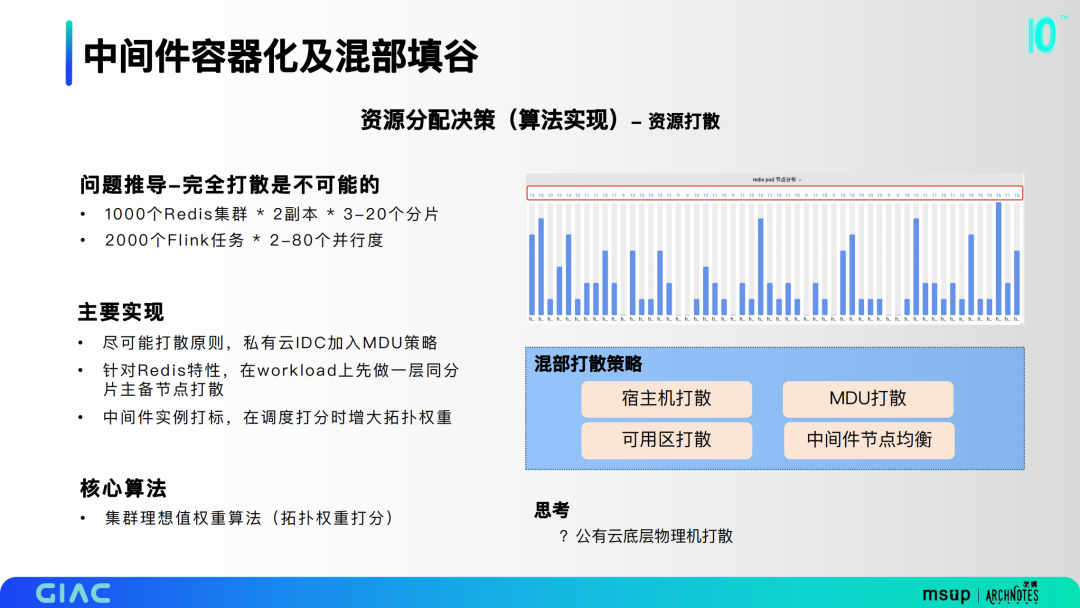
第三部分是資源打散,通過問題推導(dǎo),完全打散是不可能的,我們希望盡可能打散,在私有云IDC加入MDU策略。常用的策略有宿主機(jī)打散、可用區(qū)打散和MDU打散。
3.成效和問題
最終資源使用率有明顯提高,成本賬單同比持續(xù)降低。這里也帶來了一個無法回避的問題:物理機(jī)宕機(jī)。爆炸半徑增大,穩(wěn)定性怎么保障,是我們基礎(chǔ)設(shè)施的同學(xué)都需要去思考的問題。二是對根因下鉆和故障定位帶來挑戰(zhàn),如何觀測和評估影響。
三、K8S觀測與穩(wěn)定性
1.基于Prometheus的容器監(jiān)控平臺
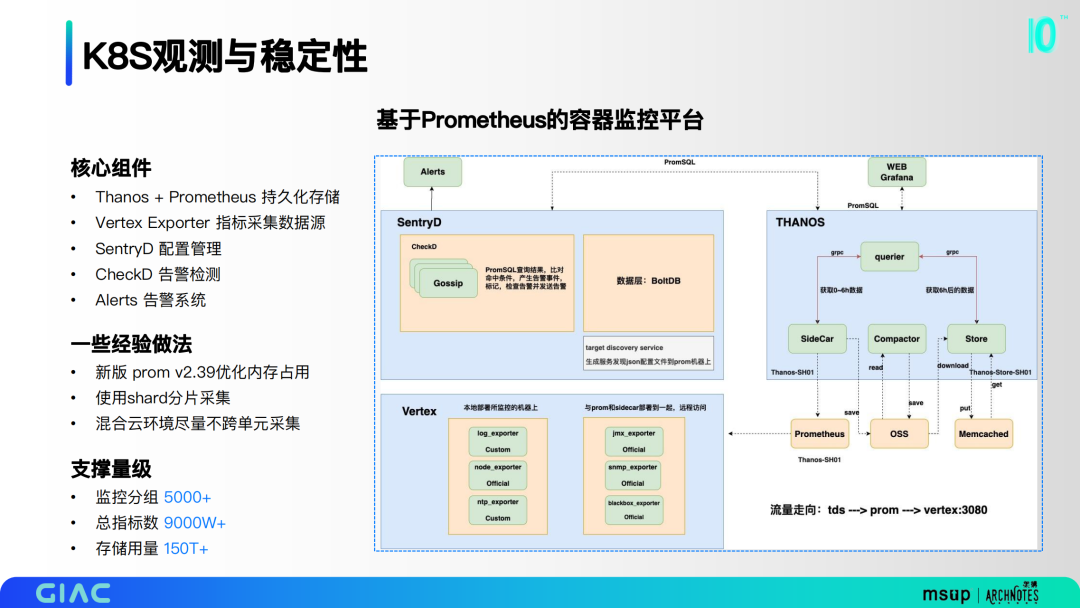
基于Prometheus構(gòu)建了監(jiān)控體系,核心組件包括Thanos + Prometheus 持久化存儲、Vertex Exporter 指標(biāo)采集數(shù)據(jù)源、SentryD 配置管理、CheckD 告警檢測和Alerts 告警系統(tǒng)。
2.監(jiān)控高級模式

我們自研了vertex采集工具,實(shí)現(xiàn)了快速生成metrics指標(biāo)的能力,支持用戶自定義指標(biāo)名稱,方便按業(yè)務(wù)、按分組區(qū)分。和exporter算力共享,每個實(shí)例 limit 2C/4G就可滿足一個物理機(jī)的采集任務(wù)。
3.event 事件流持久化

實(shí)現(xiàn)了事件收集器,K8S全資源類型listwatch收集,同時把所有的event全量打印,針對特別的一些探針做了Response信息返回的打印。
4.logs 日志平臺

把系統(tǒng)日志和業(yè)務(wù)日志等通過一些消費(fèi)和采集的收集器,推送到kafka,最終聚合成一個平臺。
5.trace鏈路
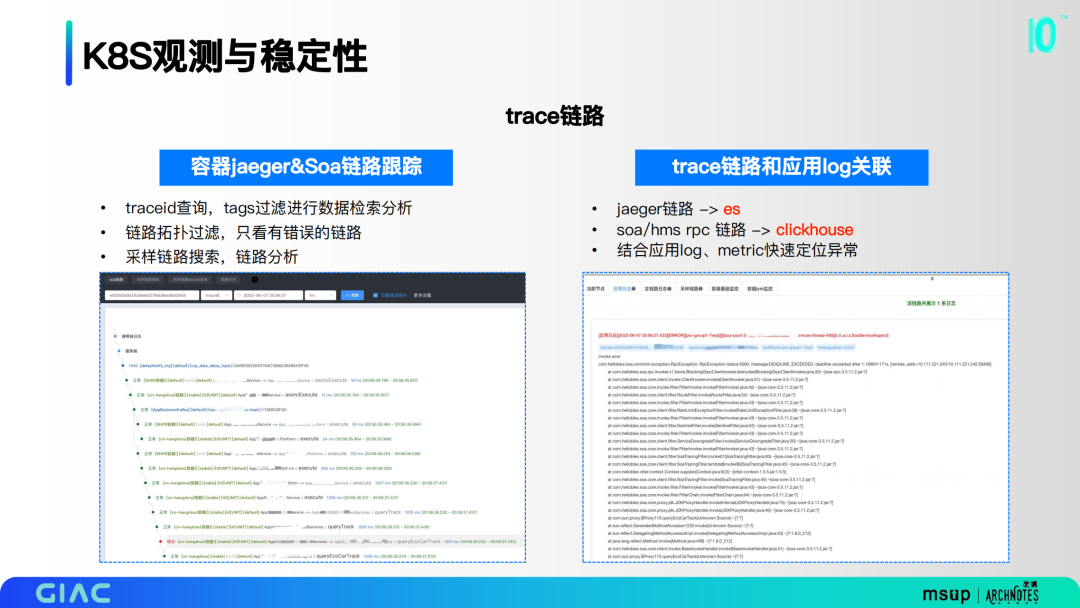
我們通過traceid查詢,tags過濾進(jìn)行數(shù)據(jù)檢索分析;鏈路拓?fù)溥^濾,只看有錯誤的鏈路;采樣鏈路搜索,鏈路分析。
6.K8S穩(wěn)定性關(guān)注的指標(biāo)

這里把K8S穩(wěn)定性關(guān)注的指標(biāo)分為五類,原生組件可用性、集群容量水位、集群資源負(fù)載、業(yè)務(wù)異常實(shí)例和云平臺可用性。
7.穩(wěn)定性大盤
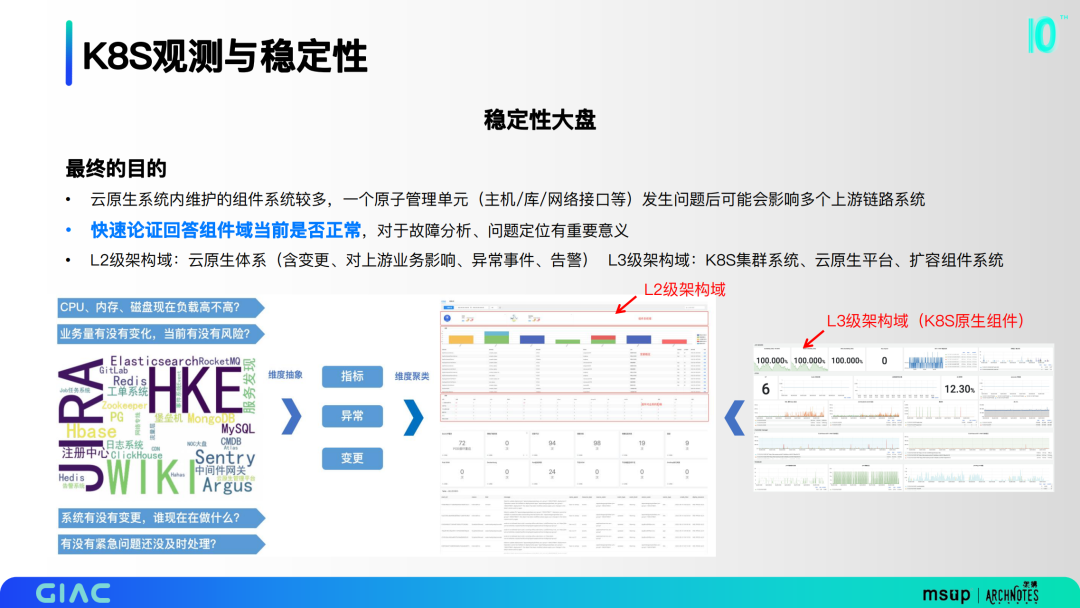
云原生系統(tǒng)內(nèi)維護(hù)的組件系統(tǒng)較多,一個原子管理單元發(fā)生問題后可能會影響多個上游鏈路系統(tǒng)。快速論證回答組件域當(dāng)前是否正常,對于故障分析、問題定位有重要意義。
四、未來的展望規(guī)劃
未來規(guī)劃主要分為四部分,一是在離線的深度混部與調(diào)優(yōu),下一階段還要持續(xù)推進(jìn)哈啰內(nèi)部云化中間件的混部進(jìn)程,聚焦大算力應(yīng)用的資源編排和成本優(yōu)化。
二是數(shù)據(jù)存儲容器化,數(shù)據(jù)庫、NoSQL的容器化工作,基于容器Cgroup隔離、以及類K8S資源編排模型的落地。目前哈啰內(nèi)部已有部分業(yè)務(wù)開始生產(chǎn)化,還在持續(xù)建設(shè)中。
三是Serverless業(yè)務(wù)場景模式探索,中后臺的算法模型、數(shù)據(jù)任務(wù)job場景有一定的實(shí)踐,業(yè)務(wù)大前端BFF層、無代碼工程建設(shè)上在持續(xù)探索。
四是基于AIOPS&可觀測性的智能故障預(yù)測,基于時序預(yù)測模型能力,探索metrics異常指標(biāo)提前發(fā)現(xiàn),收斂告警系統(tǒng)誤報、漏報問題,提升故障發(fā)現(xiàn)、故障定位能力。
作者丨羅濤
來源丨公眾號:哈啰技術(shù)(ID:gh_426073316492)





