
介紹
緩存是一種強大的技術,廣泛應用于計算機系統的各個方面,從硬件緩存到操作系統、網絡瀏覽器,尤其是后端開發。對于Meta這樣的公司來說,緩存尤為重要,因為它有助于減少延遲、擴展繁重的工作負載并節約成本。由于他們的用例非常依賴緩存,這帶來另一系列問題,即緩存失效。
多年來,Meta已經將他們的緩存一致性指標從99.9999%(6個9)提高到99.99999999%(10個9),這意味著在其緩存集群中,每十億次緩存寫入中,不一致的寫入次數將少于1次。
本文將重點討論以下內容:
- 什么是緩存失效和緩存一致性?
- 為什么Meta對緩存一致性如此重視,甚至6個9的準確率都無法滿足需求?
- Meta的監控系統如何幫助他們改善緩存失效和緩存一致性,并修復錯誤的?
一、緩存失效和緩存一致性
顧名思義,緩存并不保存數據的原始來源,因此當原始來源的數據發生變化時,應該有一個主動使陳舊緩存條目失效的過程。如果在失效過程中處理不當,可能會在緩存中無限期地留下與原始來源不一致的值。
那么,我們如何使緩存失效呢?
我們可以設置TTL(生存時間)來維持緩存的新鮮度,由此就沒有其他系統會導致緩存失效了。但是,在本文的主題是Meta的緩存一致性,我們將假設使緩存失效的操作是由緩存本身以外的其它系統執行的。
首先,讓我們看看緩存不一致是如何產生的:
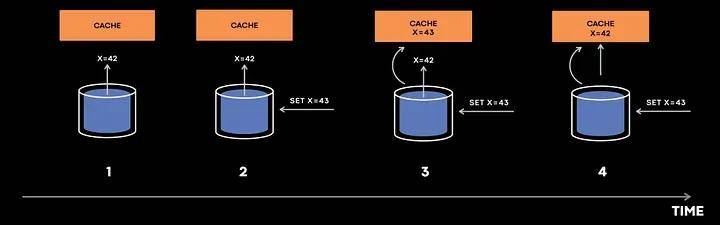
請假設1、2、3、4是依次遞增的時間戳。
- 緩存首先嘗試從數據庫中填充值。
- 但在x=42的值到達緩存之前,某個操作更新了數據庫,將x的值改為43。
- 數據庫發送了x=43的緩存失效事件,并在x=42到達緩存之前到達了緩存,于是緩存的值被設置為43。
- 現在,事件x=42到達緩存,緩存的值被設置為42,于是引入了不一致性。
為了解決這個問題,我們可以使用版本字段來執行沖突解決,這樣舊版本就永遠不會覆蓋當前版本。該解決方案適用于互聯網上幾乎 99% 的公司,但由于系統的復雜性,這個解決方案可能還是無法應對Meta的運營規模。
二、為什么Meta如此重視緩存一致性?
從Meta的角度來看,緩存不一致幾乎與數據庫數據丟失一樣糟糕,而從用戶的角度來看,緩存不一致可能導致糟糕的體驗。
當你在Instagram上給用戶發送私信(DM)時,后臺會有一個用戶到主存儲器(用戶信息就存儲在主存儲器)的映射,用戶的信息就存儲在主存儲器中。
想象一下這里有三個用戶:Bob、Mary和Alice。這兩個用戶都給Alice發送了消息。Bob在美國,Alice在歐洲,而Mary在日本。因此,系統會查詢離用戶最近的區域,并將消息發送到Alice的數據存儲區。在這種情況下,當TAO(The Associations and Objects,Meta的社交圖譜存儲系統)副本查詢Bob和Mary所在的區域時,它們都有不一致的數據,并將消息發送到了沒有任何Alice消息的區域。
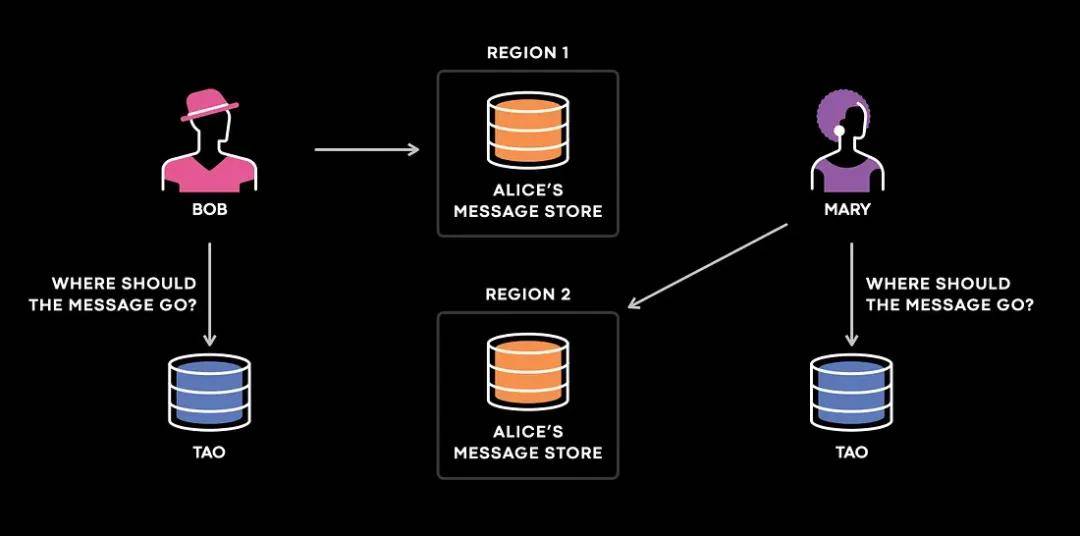
在上述情況下,將會出現消息丟失和糟糕的用戶體驗,因此這是Meta需要解決的首要問題之一。
三、監控
要解決緩存失效和緩存一致性問題,首先要進行測量。如果我們能夠準確測量緩存一致性,并在緩存中出現不一致條目時發出警報,就能發現問題。然而Meta確保其測量結果不包含任何誤報,只是因為值班工程師會忽略警報,由此指標就失去可信度和可用性。
在深入探討Meta實施的解決方案之前,最簡單的解決方案將是記錄并跟蹤緩存的每次狀態變化。在工作負載較小的情況下,這個方案是可行的,但Meta的系統每天的緩存填充量超過10萬億次。記錄和跟蹤所有緩存狀態,會將已經很重的緩存工作負載變成更加沉重,我們甚至不想考慮如何調試它。
四、Polaris
宏觀來看,Polaris作為客戶端與有狀態服務進行交互,并假定其對服務內部結構一無所知。Polaris基于“緩存最終應與數據庫一致”的原則工作。Polaris接收失效事件后會查詢所有副本,以驗證是否發生其他違規情況。
例如:如果Polaris接收到x=4版本4的失效事件,它以客戶端身份檢查所有緩存副本,以驗證是否發生其他違規情況。如果一個副本返回x=3@版本3,Polaris會將其標記為不一致,并重新獲取樣本,以便稍后與同一目標緩存主機進行檢查。Polaris會在特定的時間尺度(例如,一分鐘、五分鐘或十分鐘)內報告不一致性。
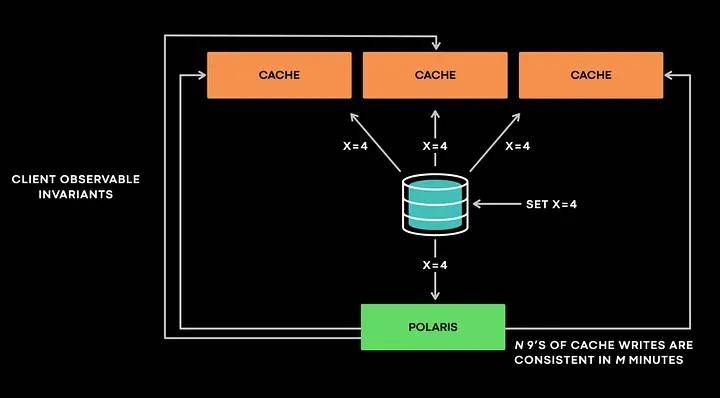
這種多時間尺度的設計不僅允許Polaris內部擁有多個隊列,以有效實現回退和重試,對于防止誤報也至關重要。
讓我們通過另一個例子來理解這一點:
假設Polaris接收到一個版本為4的失效事件x=4。但當Polaris檢查緩存時,卻找不到x的條目,它應該將此標記為不一致。在這種情況下,有兩種可能性。
- 在版本3時,x是不可見的,但版本4的寫入是該鍵上的最新寫入,這確實是一個緩存不一致。
- 可能是版本5的寫入刪除了鍵x,也許Polaris只是看到了比失效事件中更新的數據。
現在,我們如何確定這兩種情況中哪一種是正確的?
為了驗證這兩種情況Polaris需要通過查詢數據庫進行檢查。繞過緩存的查詢可能是計算密集型的,并且也可能使數據庫面臨風險,因為保護數據庫和擴展讀取密集型工作負載是緩存的兩個最常見的用例。因此,我們不能向系統發送太多查詢。
Polaris的解決方案是,延遲執行此類檢查并調用數據庫,直到不一致的樣本超過設定的閾值(例如1分鐘或5分鐘),從而解決了這個問題。Polaris的產品指標表述為“在M分鐘內,N個九的緩存寫入是一致的。”因此,目前Polaris提供了一個指標:表示在五分鐘的時間尺度內,99.99999999%的緩存是一致的。
現在,讓我們通過一個編碼示例,了解Polaris如何幫助Meta解決由緩存不一致性引起的bug:
假設有一個緩存,它維護著密鑰到元數據的映射和密鑰到版本的映射。
cache_data = {}
cache_version = {}
meta_data_table = {"1": 42}
version_table = {"1": 4}
1.當讀取請求到來時,首先在緩存中檢查該值。如果緩存中不存在該值,則從數據庫中返回該值。
def read_value(key):
value = read_value_from_cache(key)
if value is not None:
return value
else:
return meta_data_table[key]
def read_value_from_cache(key):
if key in cache_data:
return cache_data[key]
else:
fill_cache_thread = threading.Thread(target=fill_cache(key))
fill_cache_thread.start()
return None
2.緩存返回 None 結果,然后開始從數據庫填充緩存。我在這里使用了線程來使進程異步。
def fill_cache(key):
fill_cache_metadata(key)
fill_cache_version(key)
def fill_cache_metadata(key):
meta_data = meta_data_table[key]
print("Filling cache meta data for", meta_data)
cache_data[key] = meta_data
def fill_cache_version(key):
time.sleep(2)
version = version_table[key]
print("Filling cache version data for", version)
cache_version[key] = version
def write_value(key, value):
version = 1
if key in version_table:
version = version_table[key]
version = version + 1
write_in_databse_transactionally(key, value, version)
time.sleep(3)
invalidate_cache(key, value, version)
def write_in_databse_transactionally(key, data, version):
meta_data_table[key] = data
version_table[key] = version
3.同時,當版本數據填入緩存時,數據庫可能會有新的寫入請求,更新元數據值和版本值。此時這看似是一個bug,但實際不是,因為緩存失效應使緩存恢復到與數據庫一致的狀態(注意,我在緩存中添加了 time.sleep,并在數據庫中添加了寫入函數,以復現該問題)。
def invalidate_cache(key, metadata, version):
try:
cache_data = cache_data[key][value] ## To produce error
except:
drop_cache(key, version)
def drop_cache(key, version):
cache_version_value = cache_version[key]
if version > cache_version_value:
cache_data.pop(key)
cache_version.pop(key)
read_thread = threading.Thread(target=read_value, args=("1"))
write_thread = threading.Thread(target=write_value, args=("1",43))
print_thread = threading.Thread(target=print_values)
4.后來,在緩存失效過程中,由于某些原因導致失效失敗,在這種情況下,異常處理程序有條件放棄緩存。
丟棄緩存函數的邏輯是,如果最新值大于 cache_version_value,那么就刪除該鍵,但在我們實際情況中并非如此。因此,這將導致在緩存中無限期地保留陳舊的元數據。
請注意,這只是對bug發生過程的簡化表述,實際中的bug會更加錯綜復雜,涉及數據庫復制和跨區域通信。只有當上述所有步驟都按特定順序發生時,才會觸發bug。這種不一致性很少被觸發,一般都隱藏在交錯操作和臨時錯誤后面的錯誤處理代碼中。
既然您已經接到 Polaris 調用緩存不一致的請求,那么最重要的就是檢查日志,看看問題出在哪里。正如我們之前所討論的,記錄每一個緩存數據變化幾乎是不可能的,但如果我們只記錄有可能導致變化的變化呢?
五、一致性跟蹤
如果正在值班的你接到了Polaris報告的緩存不一致性的通知,最重要的是檢查日志并確定問題出在哪里。正如我們之前討論的,記錄每個緩存數據更改幾乎是不可能的,但如果我們只記錄那些有可能導致不一致性的更改呢?
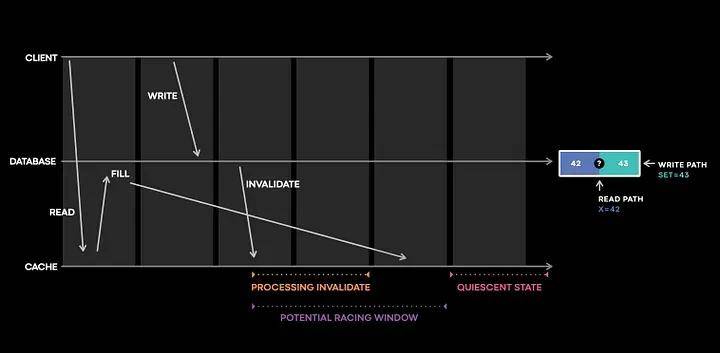
我們查看上面實現的代碼,如果緩存沒有收到失效事件或者失效操作沒有生效,那么問題就可能發生。從值班人員的角度來看,我們需要檢查以下內容:
- 緩存服務器是否接收到了失效請求?
- 服務器是否正確處理了失效請求?
- 之后相關條目是否變得不一致了?
Meta已經構建了一個有狀態追蹤庫,該庫在這個紫色小窗口中記錄和跟蹤緩存變更,所有有趣且復雜的交互都在這里觸發bug,從而導致緩存不一致。
結論
對于任何分布式系統來說,可靠的監控和日志系統都是必不可少的,以確保我們能夠抓住bug,并在捕獲bug時迅速找到根本原因,從而減少問題發生。以Meta為例,Polaris識別異常后立即發出警報。借助一致性跟蹤提供的信息,值班工程師在不到30分鐘內就定位到了bug。
>>>>參考資料
- engineering.fb.com/2022/06/08/core-infra/cache-made-consistent/
作者丨Mayank Sharma 編譯丨onehunnit
來源丨medium.com/@mayank.sharma2796/how-meta-improved-their-cache-consistency-to-99-99999999-58d79674a806
*本文為dbaplus社群編譯整理,如需轉載請取得授權并標明出處!歡迎廣大技術人員投稿,投稿郵箱:[email protected]





