擊這里在線咨詢客服")
Meta 承諾其下一代定制人工智能芯片將更加強(qiáng)大,能夠更快地訓(xùn)練其排名模型。
Meta 訓(xùn)練和推理加速器 (MTIA) 旨在與 Meta 的排名和推薦模型完美配合。這些芯片可以幫助提高訓(xùn)練效率,并使推理(即實(shí)際的推理任務(wù))變得更容易。
該公司在一篇博客文章中表示,MTIA 是其長(zhǎng)期計(jì)劃的重要組成部分,該計(jì)劃旨在圍繞如何在其服務(wù)中使用人工智能來構(gòu)建基礎(chǔ)設(shè)施。它希望設(shè)計(jì)的芯片能夠與其當(dāng)前的技術(shù)基礎(chǔ)設(shè)施和 GPU 的未來進(jìn)步相配合。
Meta 在其帖子中表示:“實(shí)現(xiàn)我們對(duì)定制芯片的雄心意味著不僅要投資于計(jì)算芯片,還要投資于內(nèi)存帶寬、網(wǎng)絡(luò)和容量以及其他下一代硬件系統(tǒng)。”
Meta于 2023 年 5 月發(fā)布了 MTIA v1,專注于向數(shù)據(jù)中心提供這些芯片。下一代 MTIA 芯片也可能瞄準(zhǔn)數(shù)據(jù)中心。MTIA v1 預(yù)計(jì)要到 2025 年才會(huì)發(fā)布,但 Meta 表示這兩款 MTIA 芯片現(xiàn)已投入生產(chǎn)。
目前,MTIA 主要訓(xùn)練排名和推薦算法,但 Meta 表示,最終目標(biāo)是擴(kuò)展芯片的功能,開始訓(xùn)練生成式人工智能,如 Llama 語言模型。
Meta 表示,新的 MTIA 芯片“從根本上專注于提供計(jì)算、內(nèi)存帶寬和內(nèi)存容量的適當(dāng)平衡。”該芯片將擁有 256MB 片上內(nèi)存,頻率為 1.3GHz,而 v1 的片上內(nèi)存為 128MB 和 800GHz。Meta 的早期測(cè)試結(jié)果顯示,在公司評(píng)估的四種型號(hào)中,新芯片的性能比第一代版本好三倍。
Meta 致力于 MTIA v2 已有一段時(shí)間了。該項(xiàng)目?jī)?nèi)部稱為 Artemis,此前有報(bào)道稱僅專注于推理。
隨著人工智能的使用,對(duì)計(jì)算能力的需求不斷增加,其他人工智能公司一直在考慮制造自己的芯片。谷歌于 2017 年發(fā)布了新的 TPU 芯片,而微軟則發(fā)布了 Maia 100 芯片。亞馬遜還有其 Trainium 2 芯片,其訓(xùn)練基礎(chǔ)模型的速度比之前的版本快四倍。
購(gòu)買強(qiáng)大芯片的競(jìng)爭(zhēng)凸顯了需要定制芯片來運(yùn)行人工智能模型。對(duì)芯片的需求增長(zhǎng)如此之快,以至于目前在人工智能芯片市場(chǎng)占據(jù)主導(dǎo)地位的英偉達(dá)的估值達(dá)到了 2 萬億美元。
Meta下一代訓(xùn)練和推理加速器
Meta 的下一代大規(guī)模基礎(chǔ)設(shè)施正在以人工智能為基礎(chǔ)進(jìn)行構(gòu)建,包括支持新的生成式人工智能 (GenAI) 產(chǎn)品和服務(wù)、推薦系統(tǒng)以及先進(jìn)的人工智能研究。隨著支持人工智能模型的計(jì)算需求隨著模型的復(fù)雜性而增加,Meta預(yù)計(jì)這項(xiàng)投資將在未來幾年增長(zhǎng)。
去年,Meta推出了元訓(xùn)練和推理加速器 (MTIA:Meta Training and Inference Accelerator) v1,這是Meta在內(nèi)部設(shè)計(jì)時(shí)考慮到 Meta 的人工智能工作負(fù)載的第一代人工智能推理加速器,特別是Meta的深度學(xué)習(xí)推薦模型,它正在改善各種體驗(yàn)我們的產(chǎn)品。
在Meta看來,MTIA 是一項(xiàng)長(zhǎng)期事業(yè),旨在為 Meta 獨(dú)特的工作負(fù)載提供最高效的架構(gòu)。隨著人工智能工作負(fù)載對(duì)我們的產(chǎn)品和服務(wù)變得越來越重要,這種效率將提高M(jìn)eta為全球用戶提供最佳體驗(yàn)的能力。MTIA v1 是提高公司基礎(chǔ)設(shè)施的計(jì)算效率并更好地支持公司的軟件開發(fā)人員構(gòu)建 AI 模型以促進(jìn)新的、更好的用戶體驗(yàn)的重要一步。
現(xiàn)在,Meta正在分享有關(guān)下一代 MTIA 的詳細(xì)信息。

Meta表示,該推理加速器是公司更廣泛的全棧開發(fā)計(jì)劃的一部分,用于定制、特定領(lǐng)域的芯片,可解決獨(dú)特的工作負(fù)載和系統(tǒng)問題。這個(gè)新版本的 MTIA 使Meta之前的解決方案的計(jì)算和內(nèi)存帶寬增加了一倍以上,同時(shí)保持了與工作負(fù)載的緊密聯(lián)系。它旨在高效地服務(wù)于為用戶提供高質(zhì)量推薦的排名和推薦模型。
據(jù)Meta介紹,該芯片的架構(gòu)從根本上側(cè)重于為服務(wù)排名和推薦模型(serving ranking and recommendation models)提供計(jì)算、內(nèi)存帶寬和內(nèi)存容量的適當(dāng)平衡。在推理中,即使批量大小(batch sizes)相對(duì)較低,Meta也認(rèn)為需要能夠提供相對(duì)較高的利用率。通過專注于提供相對(duì)于典型 GPU 而言超大的 SRAM 容量,Meta認(rèn)為可以在批量大小有限的情況下提供高利用率,并能在遇到大量潛在并發(fā)工作時(shí)提供足夠的計(jì)算。

該加速器由 8x8 處理元件 (PE:processing elements) 網(wǎng)格組成。這些 PE 顯著提高了密集計(jì)算性能(比 MTIA v1 提高了 3.5 倍)和稀疏計(jì)算性能(提高了 7 倍)。這部分歸功于與稀疏計(jì)算流水線相關(guān)的架構(gòu)的改進(jìn)。它還來自Meta為 PE 網(wǎng)格供電的方式:Meta將本地 PE 存儲(chǔ)的大小增加了兩倍,將片上 SRAM 增加了一倍,將其帶寬增加了 3.5 倍,并將 LPDDR5 的容量增加了一倍。
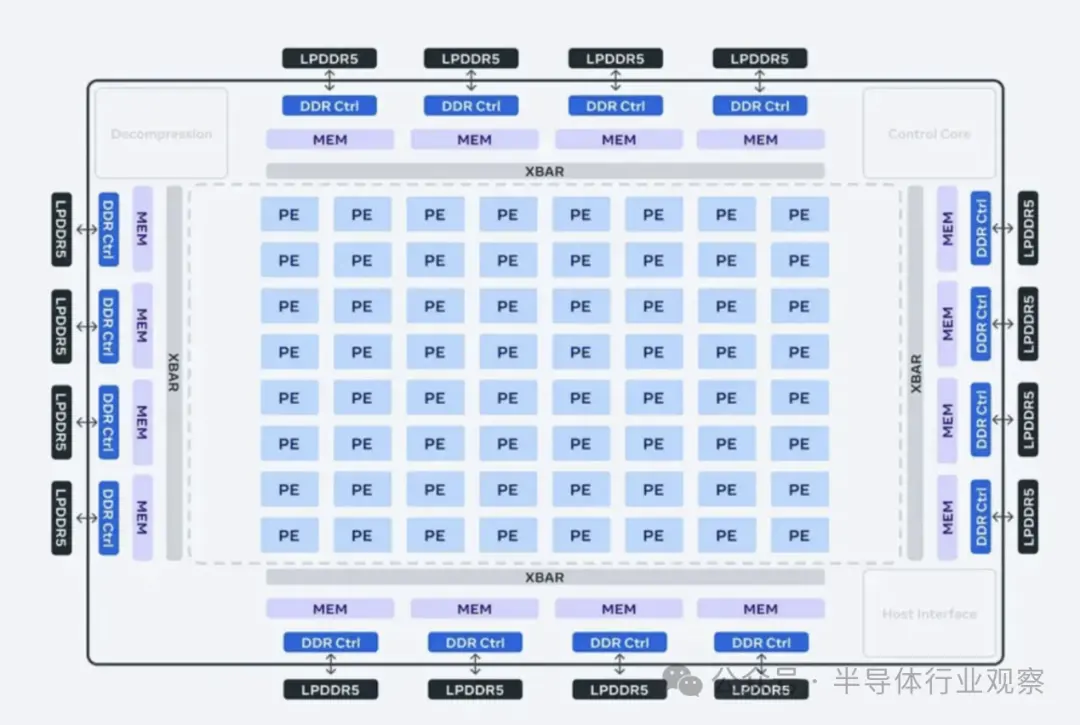

Meta新的 MTIA 設(shè)計(jì)還采用改進(jìn)的片上網(wǎng)絡(luò) (NoC) 架構(gòu),使帶寬加倍,并允許以低延遲在不同 PE 之間進(jìn)行協(xié)調(diào)。PE 中的這些功能和其他新功能構(gòu)成了關(guān)鍵技術(shù),這對(duì)于Meta將 MTIA 擴(kuò)展到更廣泛、更具挑戰(zhàn)性的工作負(fù)載的長(zhǎng)期路線圖至關(guān)重要。


Meta強(qiáng)調(diào),有效地服務(wù)公司的工作負(fù)載不僅僅是一個(gè)硅挑戰(zhàn)。共同設(shè)計(jì)硬件系統(tǒng)和軟件堆棧以及芯片對(duì)于整體推理解決方案的成功更是至關(guān)重要。

為了支持下一代芯片,Meta開發(fā)了一個(gè)大型機(jī)架式系統(tǒng),最多可容納 72 個(gè)加速器。它由三個(gè)機(jī)箱組成,每個(gè)機(jī)箱包含 12 個(gè)板,每個(gè)板包含兩個(gè)加速器。Meta專門設(shè)計(jì)了該系統(tǒng),以便可以將芯片的時(shí)鐘頻率設(shè)置為 1.35GHz(從 800 MHz 提高)并以 90 瓦的功率運(yùn)行,而第一代設(shè)計(jì)的功耗為 25 瓦。Meta表示,這個(gè)設(shè)計(jì)能確保公司可以提供更密集的功能以及更高的計(jì)算、內(nèi)存帶寬和內(nèi)存容量。這種密度也能使Meta能夠更輕松地適應(yīng)各種模型復(fù)雜性和尺寸。

除此之外,Meta還將加速器之間以及主機(jī)與加速器之間的結(jié)構(gòu)升級(jí)到 PCIe Gen5,以提高系統(tǒng)的帶寬和可擴(kuò)展性。如果選擇擴(kuò)展到機(jī)架之外,還可以選擇添加 RDMA NIC。
Meta重申,從投資 MTIA 之初起,軟件就一直是公司重點(diǎn)關(guān)注的領(lǐng)域之一。作為 PyTorch 的最初開發(fā)者,Meta重視可編程性和開發(fā)人員效率。按照Meta所說, MTIA 堆棧旨在與 PyTorch 2.0 以及 TorchDynamo 和 TorchInductor 等功能完全集成。前端圖形級(jí)捕獲、分析、轉(zhuǎn)換和提取機(jī)制(例如 TorchDynamo、torch.export 等)與 MTIA 無關(guān),并且正在被重用 MTIA 的較低級(jí)別編譯器從前端獲取輸出并生成高效且設(shè)備特定代碼。這個(gè)較低級(jí)別的編譯器本身由幾個(gè)組件組成,負(fù)責(zé)為模型和內(nèi)核生成可執(zhí)行代碼。
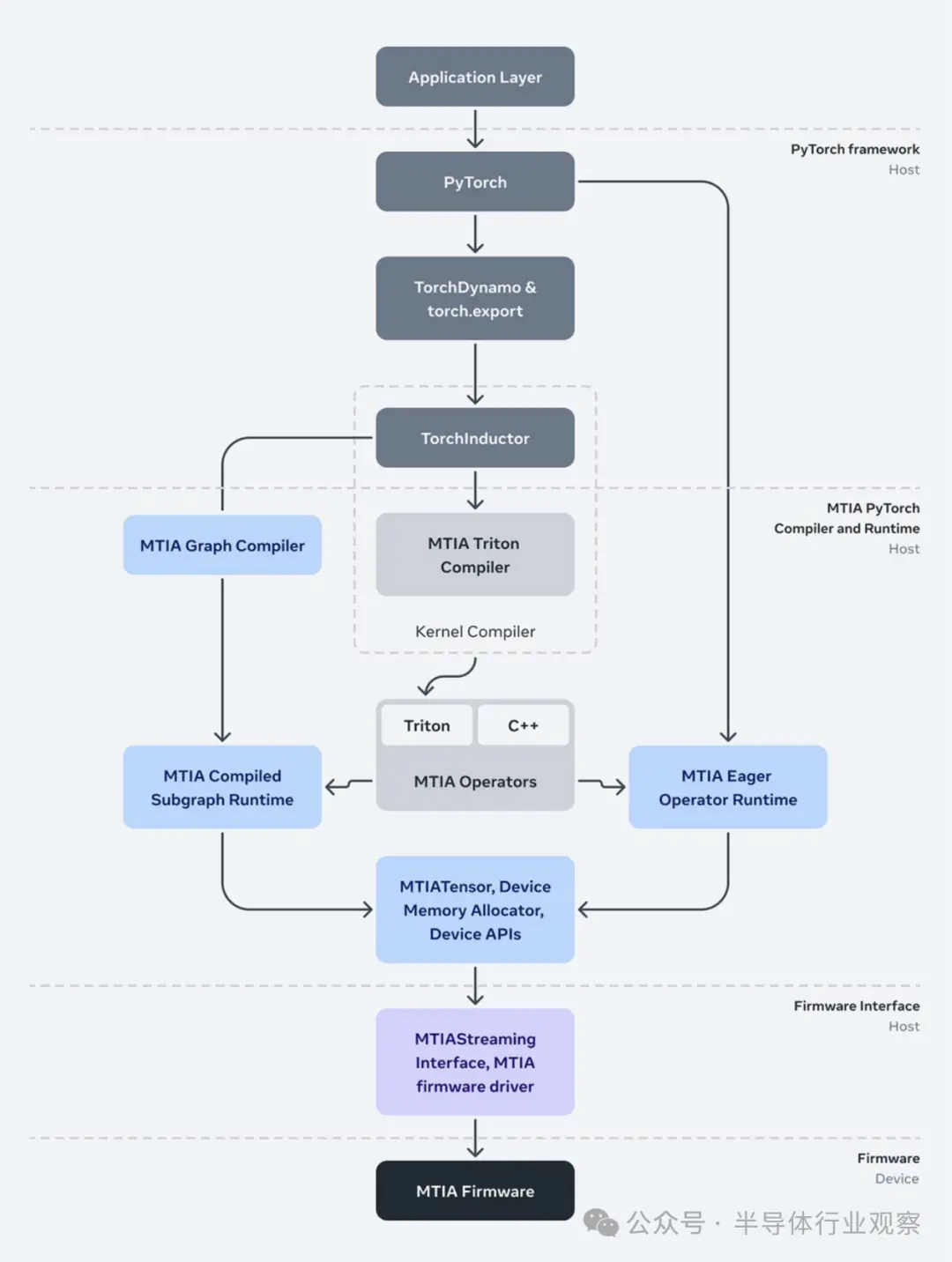
下面是負(fù)責(zé)與驅(qū)動(dòng)程序/固件連接的運(yùn)行時(shí)堆棧。MTIA Streaming 接口抽象提供了推理和(未來)訓(xùn)練軟件管理設(shè)備內(nèi)存以及在設(shè)備上運(yùn)行運(yùn)算符和執(zhí)行編譯圖所需的基本和必要操作。最后,運(yùn)行時(shí)與位于用戶空間的驅(qū)動(dòng)程序進(jìn)行交互——Meta解析說,做出這一決定是為了使公司能夠在生產(chǎn)堆棧中更快地迭代驅(qū)動(dòng)程序和固件。
在許多方面,這種新芯片系統(tǒng)運(yùn)行的軟件堆棧與 MTIA v1 類似,這使得團(tuán)隊(duì)的部署速度更快,因?yàn)镸eta已經(jīng)完成了在該架構(gòu)上運(yùn)行應(yīng)用程序所需的大部分必要的集成和開發(fā)工作。
新的 MTIA 旨在與為 MTIA v1 開發(fā)的代碼兼容。由于Meta已經(jīng)將完整的軟件堆棧集成到芯片中,因此開發(fā)者在幾天內(nèi)就可以使用這款新芯片啟動(dòng)并運(yùn)行我們的流量。這使Meta能夠快速落地下一代 MTIA 芯片,在不到 9 個(gè)月的時(shí)間內(nèi)從第一個(gè)芯片到在 16 個(gè)地區(qū)運(yùn)行的生產(chǎn)模型。
此外,Meta還通過創(chuàng)建 Triton-MTIA 編譯器后端來為 MTIA 硬件生成高性能代碼,進(jìn)一步優(yōu)化了軟件堆棧。Triton是一種開源語言和編譯器,用于編寫高效的機(jī)器學(xué)習(xí)計(jì)算內(nèi)核。它提高了開發(fā)人員編寫 GPU 代碼的效率,Meta發(fā)現(xiàn), Triton 語言與硬件無關(guān),足以適用于 MTIA 等非 GPU 硬件架構(gòu)。
Triton-MTIA 后端執(zhí)行優(yōu)化以最大限度地提高硬件利用率并支持高性能內(nèi)核。它還公開了利用 Triton 和 MTIA 自動(dòng)調(diào)整基礎(chǔ)設(shè)施來探索內(nèi)核配置和優(yōu)化空間的關(guān)鍵方法。
按照Meta所說,他們實(shí)現(xiàn)了對(duì) Triton 語言功能的支持并集成到 PyTorch 2 中,為 PyTorch 操作員提供了廣泛的覆蓋范圍。例如,借助 orchInductor,開發(fā)人員可以在提前 (AOT) 和即時(shí) (JIT) 工作流程中利用 Triton-MTIA。
根據(jù)Meta的觀察,Triton-MTIA 顯著提高了開發(fā)人員的效率,這使Meta能夠擴(kuò)大計(jì)算內(nèi)核的創(chuàng)作范圍并顯著擴(kuò)展對(duì) PyTorch 運(yùn)算符的支持。
Meta總結(jié)說,迄今為止的結(jié)果表明,這款 MTIA 芯片可以處理作為 Meta 產(chǎn)品組件的低復(fù)雜性 (LC) 和高復(fù)雜性 (HC) 排名和推薦模型。在這些模型中,模型大小和每個(gè)輸入樣本的計(jì)算量可能存在約 10 倍到 100 倍的差異。因?yàn)镸eta控制整個(gè)堆棧,所以與商用 GPU 相比,Meta可以實(shí)現(xiàn)更高的效率。實(shí)現(xiàn)這些收益需要持續(xù)的努力,隨著Meta在系統(tǒng)中構(gòu)建和部署 MTIA 芯片,他們承諾將繼續(xù)提高每瓦性能。
Meta分享說,早期結(jié)果表明,在公司評(píng)估的四個(gè)關(guān)鍵模型中,這種下一代芯片的性能比第一代芯片提高了 3 倍。在平臺(tái)層面,與第一代 MTIA 系統(tǒng)相比,憑借 2 倍的設(shè)備數(shù)量和強(qiáng)大的 2 路 CPU,Meta能夠?qū)崿F(xiàn) 6 倍的模型服務(wù)吞吐量和 1.5 倍的每瓦性能提升。為了實(shí)現(xiàn)這一目標(biāo),Meta在優(yōu)化內(nèi)核、編譯器、運(yùn)行時(shí)和主機(jī)服務(wù)堆棧方面取得了重大進(jìn)展。隨著開發(fā)者生態(tài)系統(tǒng)的成熟,優(yōu)化模型的時(shí)間正在縮短,但未來提高效率的空間更大。
MTIA 已部署在數(shù)據(jù)中心,目前正在為生產(chǎn)中的模型提供服務(wù)。Meta已經(jīng)看到了該計(jì)劃的積極成果,因?yàn)樗刮覀兡軌驗(yàn)楦芗娜斯ぶ悄芄ぷ髫?fù)載投入和投資更多的計(jì)算能力。事實(shí)證明,它在針對(duì)元特定工作負(fù)載提供性能和效率的最佳組合方面與商用 GPU 具有高度互補(bǔ)性。

Meta最后說,MTIA 將成為公司長(zhǎng)期路線圖的重要組成部分,旨在為 Meta 獨(dú)特的人工智能工作負(fù)載構(gòu)建和擴(kuò)展最強(qiáng)大、最高效的基礎(chǔ)設(shè)施。
Meta也正在設(shè)計(jì)定制芯片,以便與公司現(xiàn)有的基礎(chǔ)設(shè)施以及未來可能利用的新的、更先進(jìn)的硬件(包括下一代 GPU)配合工作。實(shí)現(xiàn)我們對(duì)定制芯片的雄心意味著不僅要投資于計(jì)算芯片,還要投資于內(nèi)存帶寬、網(wǎng)絡(luò)和容量以及其他下一代硬件系統(tǒng)。
“我們目前正在進(jìn)行多個(gè)計(jì)劃,旨在擴(kuò)大 MTIA 的范圍,包括對(duì) GenAI 工作負(fù)載的支持。”Meta說。
【來源:半導(dǎo)體行業(yè)觀察】





