
據(jù) BusinessWire 報道,JEDEC 已發(fā)布 GDDR7 內(nèi)存標準規(guī)范。下一代內(nèi)存將用于顯卡,AMD、美光、Nvidia、三星和SK海力士都參與了此事。我們預計 GDDR7 將成為高端 RDNA 4 和 Blackwell GPU 的首選內(nèi)存,據(jù)傳它們將于明年推出,并在我們的最佳顯卡排行榜上爭奪一席之地。
自第一款顯卡開始支持 GDDR6 內(nèi)存以來,已經(jīng)過去了近六年的時間。這就是 Nvidia 于 2018 年 9 月推出的 RTX 20 系列圖靈架構。首款采用 GDDR6 的RTX 2080和RTX 2080 Ti GPU 的內(nèi)存時鐘頻率為 14 Gbps (14 GT/s),每臺設備可提供 56 GB/s 的速度。后來的解決方案(例如 AMD 的RX 7900 XTX)的時鐘速度高達 20 Gbps,速度為 80 GB/s。
Nvidia 幫助創(chuàng)建了更快的 GDDR6X 替代方案,在RTX 3080中的速度為 19 Gbps,最終在最新的RTX 4080 Super中高達 23 Gbps 。按照官方說法,美光 GDDR6X 芯片的速率高達 24 Gbps,每臺設備的速率可達 96 GB/s。
GDDR7 將大幅增加帶寬。JEDEC 的規(guī)格最終將達到每臺設備 192 GB/s。計算得出,內(nèi)存速度為 48 Gbps,是最快 GDDR6X 的兩倍。然而,它達到該速度的方式與之前的內(nèi)存解決方案不同。
GDDR7 將使用三個級別的信令(-1、0、+1)每兩個周期傳輸三位數(shù)據(jù)。這是 GDDR6 中使用的 NRZ(不歸零)信號的變化,GDDR6 在兩個周期內(nèi)傳輸兩位。僅這一變化就使數(shù)據(jù)傳輸效率提高了 50%,這意味著基礎時鐘不必是 GDDR6 的兩倍。
其他變化包括使用獨立于核心的線性反饋移位寄存器訓練模式來提高準確性并減少訓練時間。GDDR7 的獨立通道數(shù)量將增加一倍(GDDR6 為 4 個,而 GDDR6 為 2 個),并且將使用 PAM3 信令。
這些都不是新信息,三星去年 7 月透露了許多關鍵的 GDDR7 細節(jié)。然而,JEDEC 標準的發(fā)布標志著一個重要的里程碑,并表明 GDDR7 解決方案的公開可用性和使用迫在眉睫(相對而言)。
Nvidia 的下一代 Blackwell 架構預計在推出時將使用 GDDR7。我們可能會在 2024 年末推出 Blackwell 的數(shù)據(jù)中心版本,但它將使用 HBM3E 內(nèi)存而不是 GDDR7。消費級產(chǎn)品很可能會在 2025 年初上市,并且像往常一樣,這些部件將會有專業(yè)版和數(shù)據(jù)中心版。AMD 也在開發(fā) RDNA 4,我們預計它也將使用 GDDR7——不過,如果兩家公司的低端部件出于成本原因仍然選擇堅持使用 GDDR6,也不要感到驚訝。
無論哪種情況,AMD 或 Nvidia 在最高速度下使用 GDDR7 都可能使用當今最寬的 384 位接口提供高達 2,304 GB/s 的帶寬。我們真的會看到這樣的帶寬嗎?也許不是,例如 Nvidia 的 RTX 40 系列 GPU(配備 GDDR6X)都使用略低于最大時鐘的時鐘。盡管如此,我們?nèi)匀豢梢暂p松地看到即將推出的架構的帶寬翻倍。
這些什么時候才能真正到達?我們不排除在 2024 年末推出的可能性。Nvidia 的 RTX 30 系列于 2020 年秋季推出,RTX 40 系列于 2022 年秋季推出。AMD 的 RX 6000 系列同樣于 2020 年底推出,RX 7000 系列于 2022 年底推出。如果保持同樣的兩年節(jié)奏,我們可以在年底前看到 GDDR7 顯卡。但不要抱太大希望,因為我們?nèi)匀徽J為 2025 年初的可能性更大。
JEDEC 發(fā)布 GDDR7 圖形內(nèi)存標準
微電子行業(yè)標準制定的全球領導者JEDEC固態(tài)技術協(xié)會很高興地宣布發(fā)布JESD239圖形雙倍數(shù)據(jù)速率(GDDR7) SGRAM。JESD239 GDDR7 提供的帶寬是 GDDR6 的兩倍,每臺設備的帶寬高達 192 GB/s,可滿足圖形、游戲、計算、網(wǎng)絡和 AI 應用中對更多內(nèi)存帶寬不斷增長的需求。
JESD239 GDDR7 是首款使用脈沖幅度調(diào)制 (PAM) 接口進行高頻操作的 JEDEC 標準 DRAM。其 PAM3 接口提高了高頻操作的信噪比 (SNR),同時提高了能效。通過使用 3 個級別(+1、0、-1)在 2 個周期內(nèi)傳輸 3 位,而不是傳統(tǒng)的 NRZ(不歸零)接口在 2 個周期內(nèi)傳輸 2 位,PAM3 提供了更高的數(shù)據(jù)傳輸速率。循環(huán),從而提高性能。
其他高級功能包括:
具有眼圖掩蔽和錯誤計數(shù)器的核心獨立 LFSR(線性反饋移位寄存器)訓練模式可提高訓練準確性,同時減少訓練時間;
獨立通道數(shù)量翻倍,從 GDDR6 中的 2 個增加到 GDDR7 中的 4 個;
支持 16 Gbit 至 32 Gbit 密度,包括支持 2 通道模式以使系統(tǒng)容量加倍;
通過整合最新的數(shù)據(jù)完整性功能,包括帶實時報告的片上 ECC (ODECC)、數(shù)據(jù)中毒、錯誤檢查和清理以及帶命令阻塞的命令地址奇偶校驗 (CAPARBLK),滿足 RAS(可靠性、可用性、可維護性)的市場需求;
JEDEC 董事會主席 Mian Quddus 表示:“JESD239 GDDR7 標志著高速內(nèi)存設計的重大進步。“隨著向 PAM3 信號的轉(zhuǎn)變,內(nèi)存行業(yè)有了一條新的途徑來擴展 GDDR 設備的性能并推動圖形和各種高性能應用的不斷發(fā)展。”
“GDDR7 是首款不僅專注于帶寬,而且通過整合最新的數(shù)據(jù)完整性功能來滿足 RAS 市場需求的 GDDR,這些功能使 GDDR 設備能夠更好地服務云游戲和計算等現(xiàn)有市場,并擴展到 AI、 JEDEC GDDR 小組委員會主席 Michael Litt 說道。
AMD 計算 和圖形首席技術官兼企業(yè)研究員 Joe Macri 表示:“今天推出的突破性 GDDR7 內(nèi)存標準代表著釋放下一代消費、游戲、商業(yè)和企業(yè)設備潛力的關鍵一步。” “通過利用 GDDR7 的變革力量,我們可以共同開啟變革計算和圖形可能性的新時代,為創(chuàng)新和發(fā)現(xiàn)塑造的未來鋪平道路。”
“美光在通過 JEDEC 定義圖形 DRAM 標準方面有著悠久的歷史,并且在與我們的合作伙伴和客戶一起推動 GDDR7 標準化活動方面發(fā)揮了關鍵作用,”美光計算和網(wǎng)絡部門的首席架構師兼杰出技術人員 Frank Ross 說道。業(yè)務單位。“利用多級信令的 GDDR 產(chǎn)品的開發(fā)有助于確定滿足未來不斷增長的系統(tǒng)帶寬需求的途徑。通過添加領先的 RAS 功能,GDDR7 標準可滿足遠遠超出傳統(tǒng)圖形市場的工作負載要求。”
NVIDIA GPU 產(chǎn)品管理副總裁 Kaustubh Sanghani 表示:“ NVIDIA很高興我們與 JEDEC 的合作幫助 PAM 信號成為 GDDR7 的基礎技術,幫助客戶充分發(fā)揮 GPU 的性能。”
三星 執(zhí)行副總裁兼內(nèi)存產(chǎn)品規(guī)劃主管 YongCheol Bae 表示:“人工智能、高性能計算和高端游戲需要高性能內(nèi)存來以前所未有的速度處理數(shù)據(jù)。” “GDDR7 32Gbps 將實現(xiàn) 1.6 倍的性能提升,同時具有最高的可靠性和成本效益。”
“隨著每一代圖形內(nèi)存的出現(xiàn),業(yè)界始終致力于實現(xiàn)同時確保最高速度和提高能效的宏偉目標。SK海力士很榮幸能夠作為JEDEC成員參與GDDR7標準工作,并很高興能夠為客戶提供最高速度和出色功效的內(nèi)存。再次實現(xiàn)標準工作將成為業(yè)界擴展內(nèi)存生態(tài)系統(tǒng)的新機遇。”SK海力士產(chǎn)品規(guī)劃副總裁Sang Kwon Lee表示。
GDDR7 更多技術細節(jié)曝光:
36Gbps與PAM 3編碼
當三星前年10月嘲笑GDDR7 內(nèi)存的持續(xù)開發(fā)時, Cadence 沒有透露即將推出的規(guī)范的任何其他技術細節(jié)。但他們最近透露了有關該技術的一些額外細節(jié)。事實證明,GDDR7 內(nèi)存將使用 PAM3 和 NRZ 信號,并將支持許多其他功能,目標是達到每個引腳高達 36 Gbps 的數(shù)據(jù)速率。
簡短的 GDDR 歷史課
在較高的層面上,近年來 GDDR 內(nèi)存的發(fā)展相當簡單:更新的內(nèi)存迭代提高了信號速率,增加了突發(fā)大小(burst size)以跟上這些信號速率,并提高了通道利用率。但是這些都沒有顯著增加存儲單元的內(nèi)部時鐘。例如,GDDR5X 和后來的 GDDR6 將其突發(fā)大小增加到 16 字節(jié),然后切換到雙通道 32 字節(jié)訪問粒度。雖然每一代技術都面臨著挑戰(zhàn),但最終行業(yè)參與者已經(jīng)能夠通過每個版本的 GDDR 提高內(nèi)存總線的頻率,以保持性能的提升。
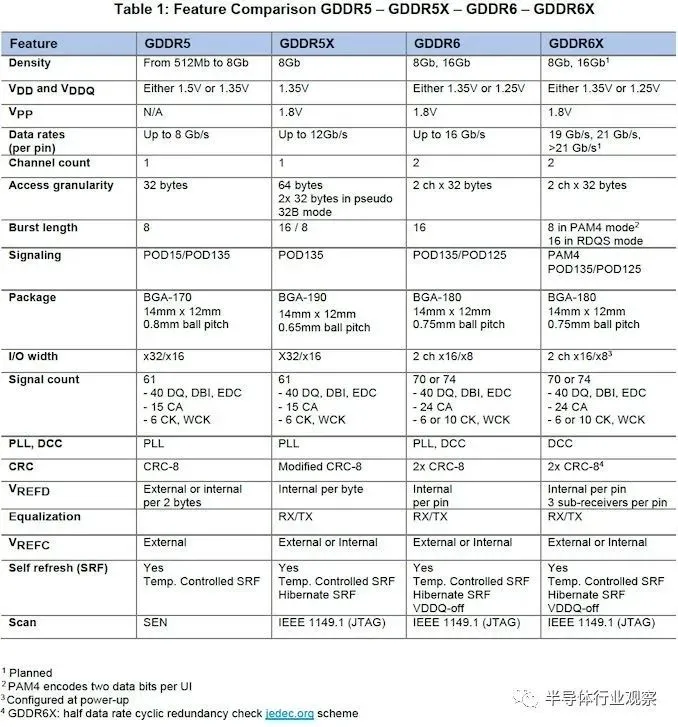
但即使是“簡單”的頻率增加也越來越變得不那么簡單了。這促使該行業(yè)尋找除了加快時鐘之外的解決方案。
借助 GDDR6X,美光和 NVIDIA 將傳統(tǒng)的不歸零 (NRZ/PAM2) 編碼替換為四級脈沖幅度調(diào)制 (PAM4) 編碼。PAM4 使用四個信號電平將有效數(shù)據(jù)傳輸速率提高到每個周期兩個數(shù)據(jù)位,從而實現(xiàn)更高的數(shù)據(jù)傳輸速率。實際上,由于 GDDR6X 在 PAM4 模式下運行時具有 8 字節(jié) (BL8) 的突發(fā)長度(burst length),因此在相同數(shù)據(jù)速率(或者更確切地說,信號速率)下它并不比 GDDR6 快,而是設計為能夠達到比 GDDR6 可以輕松實現(xiàn)的更高的數(shù)據(jù)速率。
四級脈沖幅度調(diào)制在信號丟失方面優(yōu)于 NRZ。對于給定的數(shù)據(jù)速率,由于 PAM4 需要 NRZ 信號傳輸波特率的一半,因此產(chǎn)生的信號損失顯著減少。隨著更高頻率的信號在通過導線/走線時衰減得更快——而且按照數(shù)字邏輯標準,內(nèi)存走線的距離相對較長——能夠在本質(zhì)上是較低頻率的總線上運行,最終使一些工程和走線更容易實現(xiàn)更高的數(shù)據(jù)速率。
權衡(trade-off )是 PAM4 信號通常對隨機和感應噪聲更敏感;為了換取較低頻率的信號,您必須能夠正確識別兩倍的狀態(tài)。實際上,這會導致給定頻率下的誤碼率更高。為了降低BER,需要在Rx端進行均衡,在Tx端進行預補償,這會增加功耗。雖然它未用于 GDDR6X 內(nèi)存,但在更高頻率(例如 PCIe 6.0)下,前向糾錯 (FEC) 也是一項實際要求。
當然,GDDR6X 內(nèi)存子系統(tǒng)需要全新的內(nèi)存控制器,以及用于處理器和內(nèi)存芯片的全新物理接口 (PHY)。這些復雜的實現(xiàn)在很大程度上是四級編碼直到最近才幾乎完全用于高端數(shù)據(jù)中心網(wǎng)絡的主要原因,在這些網(wǎng)絡中有支持使用這種尖端技術的利潤。
GDDR7:PAM3 編碼高達 36 Gbps/pin
考慮到上述在使用 PAM4 信號或 NRZ 信號時的權衡,事實證明支持 GDDR7 內(nèi)存標準的 JEDEC 成員反而采取了一些折衷的立場。GDDR7 內(nèi)存設置為使用 PAM3 編碼進行高速傳輸,而不是使用 PAM4。
顧名思義,PAM3 介于 NRZ/PAM2 和 PAM4 之間,使用三級脈沖幅度調(diào)制(-1、0、+1)信號,允許它每個周期傳輸 1.5 位(或者更確切地說是 3 位以上)兩個周期)。PAM3 提供比 NRZ 更高的每周期數(shù)據(jù)傳輸速率——減少了遷移到更高內(nèi)存總線頻率的需要以及由此帶來的信號丟失挑戰(zhàn)——同時需要比 PAM4 更寬松的信噪比。總的來說,GDDR7 承諾比 GDDR6 具有更高的性能,同時比 GDDR6X 具有更低的功耗和實施成本。
對于那些記分的人來說,這實際上是我們看到的第二個使用 PAM3 的主要消費技術。出于類似的技術原因,USB4 v2(又名 80Gbps USB)也在使用 PAM3。那么 PAM3 到底是什么?
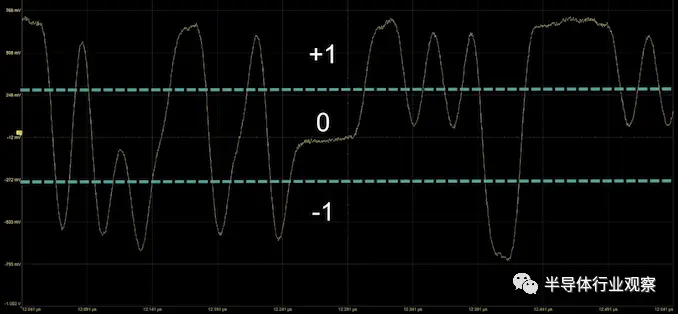
PAM3 是一種數(shù)據(jù)線可以承載 -1、0 或 +1 的技術。該系統(tǒng)所做的實際上是將兩個 PAM3 傳輸組合成一個 3 位數(shù)據(jù)信號,例如 000 是一個 -1 后跟一個 -1。這變得很復雜,所以這里有一個表格:
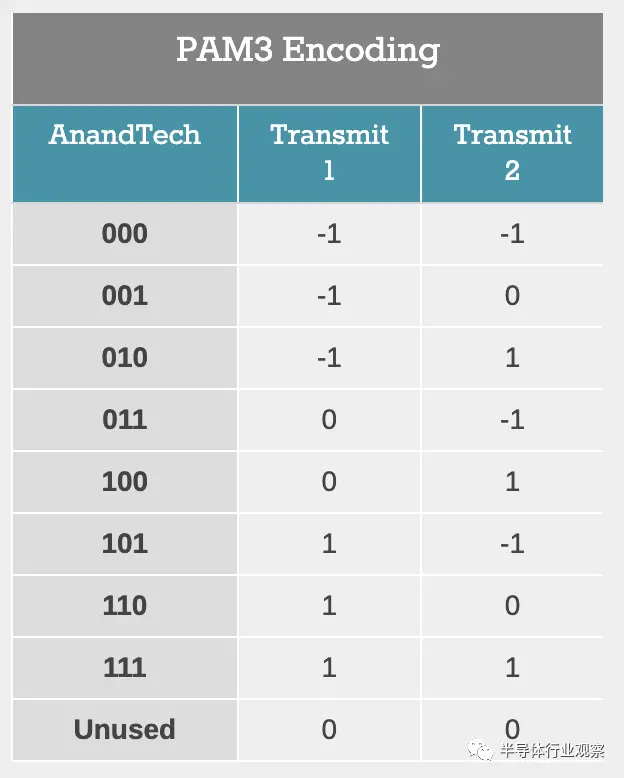
當我們將 NRZ 與 PAM3 和 PAM4 進行比較時,我們可以看到 PAM3 的數(shù)據(jù)傳輸速率處于 NRZ 和 PAM4 的中間。在這種情況下使用 PAM3 的原因是為了在沒有 PAM4 需要啟用的額外限制的情況下實現(xiàn)更高的帶寬。
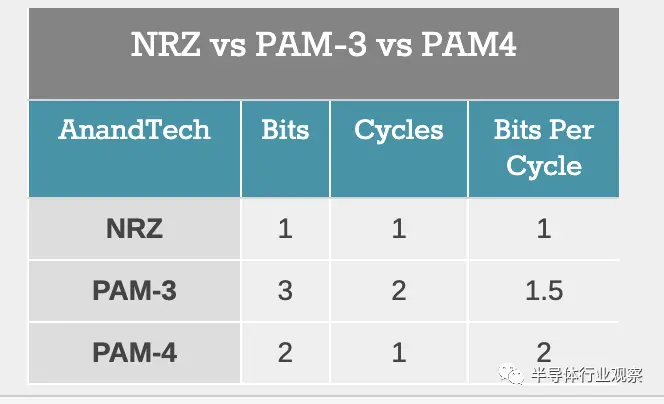
話雖如此,三星承諾的具有 36 Gbps 數(shù)據(jù)傳輸速率的 256 位內(nèi)存子系統(tǒng)將使用多少功率還有待觀察。GDDR7 規(guī)范本身尚未獲得批準,硬件本身仍在構建中(這正是 Cadence 等工具發(fā)揮作用的地方)。但請記住,AI、HPC 和圖形的帶寬需求量很大,帶寬將永遠受到歡迎。
優(yōu)化效率和功耗
除了提高吞吐量外,GDDR7 有望采用多種方式來優(yōu)化內(nèi)存效率和功耗。特別是,GDDR7 將支持四種不同的讀取時鐘 (RCK) 模式,以便僅在需要時啟用它:
始終運行:始終運行并在睡眠模式下停止;
禁用:停止運行;
Start with RCK Start command:主機可以在讀出數(shù)據(jù)之前通過發(fā)出RCK Start命令來啟動RCK,并在需要時使用RCK Stop命令停止。
Start with Read:當 DRAM 收到任何涉及讀出數(shù)據(jù)的命令時,RCK 自動開始運行。它可以使用 RCK Stop 命令停止。
此外,GDDR7 內(nèi)存子系統(tǒng)將能夠并行發(fā)出兩個獨立的命令。例如,Bank X 可以通過在 CA[2:0] 上發(fā)出 Refresh per bank 命令來刷新,而 Bank Y 可以通過同時在 CA[4:3] 上發(fā)出讀取命令來讀取。此外,GDDR7 將支持線性反饋移位寄存器 (LFSR) 數(shù)據(jù)訓練模式,以確定適當?shù)碾妷弘娖胶蜁r序,以確保一致的數(shù)據(jù)傳輸。在這種模式下,主機將跟蹤每個單獨的眼睛(連接),這將允許它應用適當?shù)碾妷阂愿玫貎?yōu)化功耗。
最后,GDDR7 將能夠根據(jù)帶寬需求在 PAM3 編碼和 NRZ 編碼之間切換。在高帶寬場景中,將使用 PAM3,而在低帶寬場景中,內(nèi)存和內(nèi)存控制器可以切換到更節(jié)能的 NRZ。
雖然 GDDR7 承諾在不大幅增加功耗的情況下顯著提高性能,但技術觀眾最大的問題可能是 新型內(nèi)存何時可用。由于沒有來自 JEDEC 的硬性承諾,因此沒有預計 GDDR7 發(fā)布的具體時間表。但考慮到所涉及的工作和 Cadence 驗證系統(tǒng)的發(fā)布,預計 GDDR7 將與 AMD 和 NVIDIA 的下一代 GPU 一起進入現(xiàn)場并不是沒有道理的。請記住,這兩家公司傾向于以大約兩年的節(jié)奏推出新的 GPU 架構,這意味著我們將在 2024 年晚些時候開始看到 GDDR7 出現(xiàn)在設備上。
當然,鑒于如今有如此多的 AI 和 HPC 公司致力于帶寬需求高的產(chǎn)品,其中一兩家可能會更快發(fā)布依賴 GDDR7 顯存的解決方案。但 GDDR7 的大規(guī)模采用幾乎肯定會與 AMD 和 NVIDIA 的下一代圖形卡的量產(chǎn)同時發(fā)生。
【來源:半導體行業(yè)觀察】





