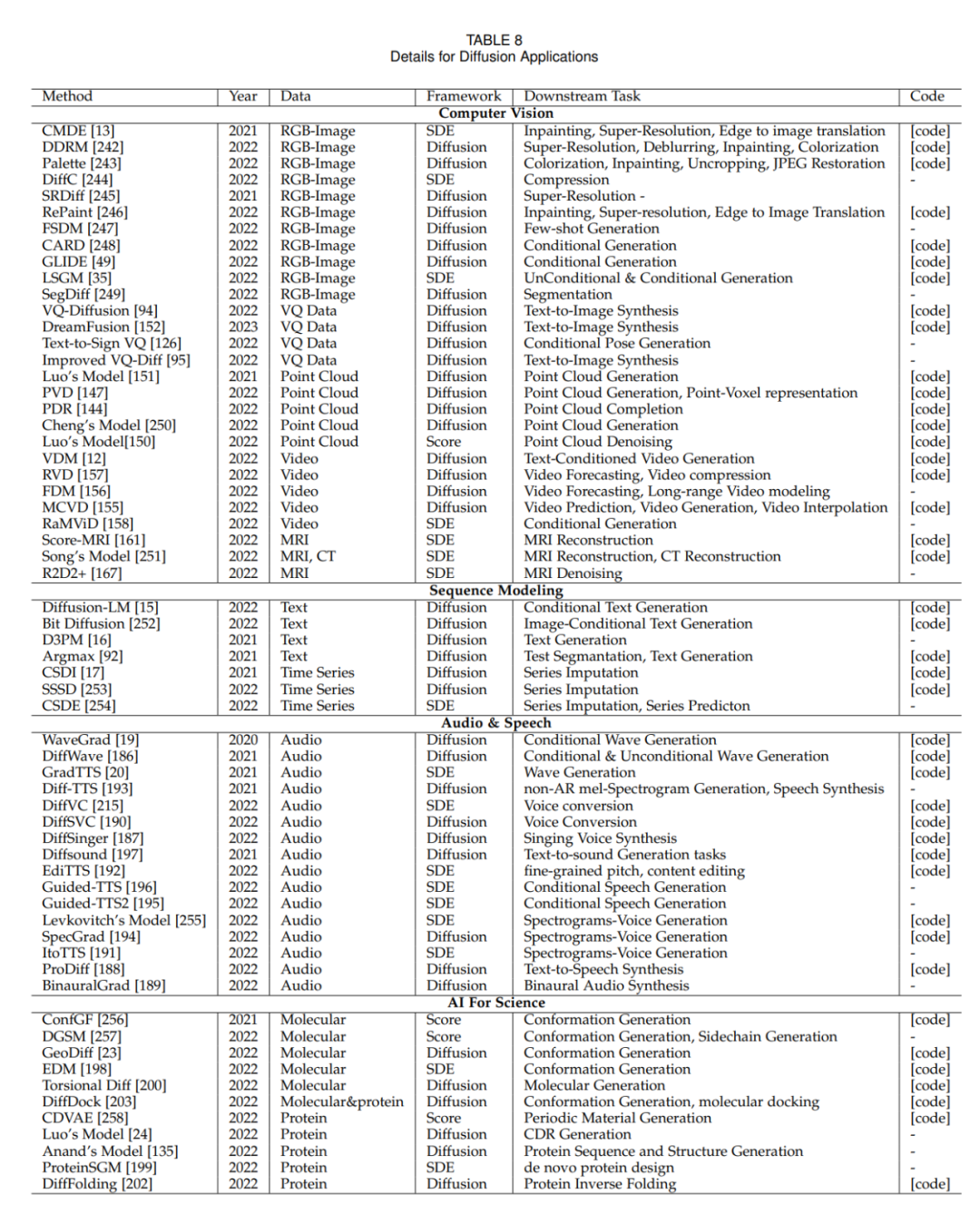
為了使機器具有人類的想象力,深度生成模型取得了重大進展。這些模型能創造逼真的樣本,尤其是擴散模型,在多個領域表現出色。擴散模型解決了其他模型的限制,如 VAEs 的后驗分布對齊問題、GANs 的不穩定性、EBMs 的計算量大和 NFs 的網絡約束問題。因此,擴散模型在計算機視覺、自然語言處理等方面備受關注。
擴散模型由兩個過程組成:前向過程和反向過程。前向過程把數據轉化為簡單的先驗分布,而反向過程則逆轉這一變化,用訓練好的神經網絡模擬微分方程來生成數據。與其他模型相比,擴散模型提供了更穩定的訓練目標和更好的生成效果。
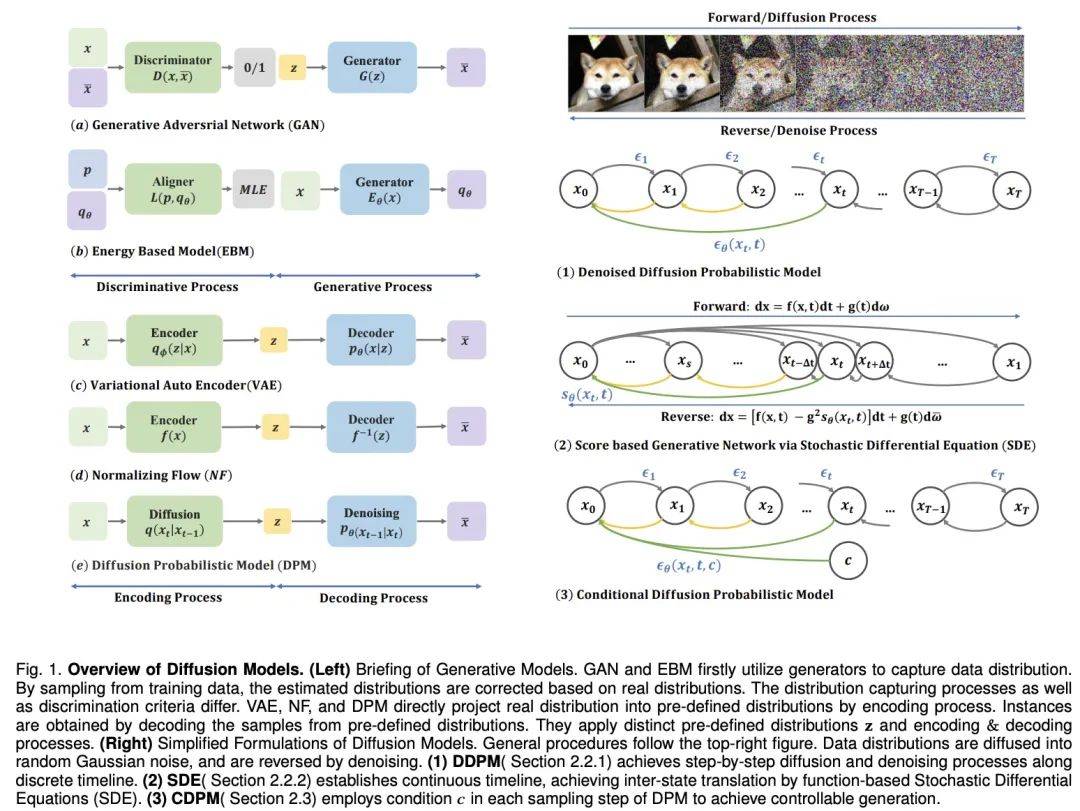
不過,擴散模型的采樣過程伴隨反復推理求值。這一過程面臨著不穩定性、高維計算需求和復雜的似然性優化等挑戰。研究者為此提出了多種方案,如改進 ODE/SDE 解算器和采取模型蒸餾策略來加速采樣,以及新的前向過程來提高穩定性和降低維度。
近期,港中文聯合西湖大學、MIT、之江實驗室,在 IEEE TKDE 上發表的題為《A Survey on Generative Diffusion Models》的綜述論文從四個方面討論了擴散模型的最新進展:采樣加速、過程設計、似然優化和分布橋接。該綜述還深入探討了擴散模型在不同應用領域的成功,如圖像合成、視頻生成、3D 建模、醫學分析和文本生成等。通過這些應用案例,展示了擴散模型在真實世界中的實用性和潛力。

- 論文地址:https://arxiv.org/pdf/2209.02646.pdf
- 項目地址:https://Github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
算法改進
采樣加速
- 知識蒸餾
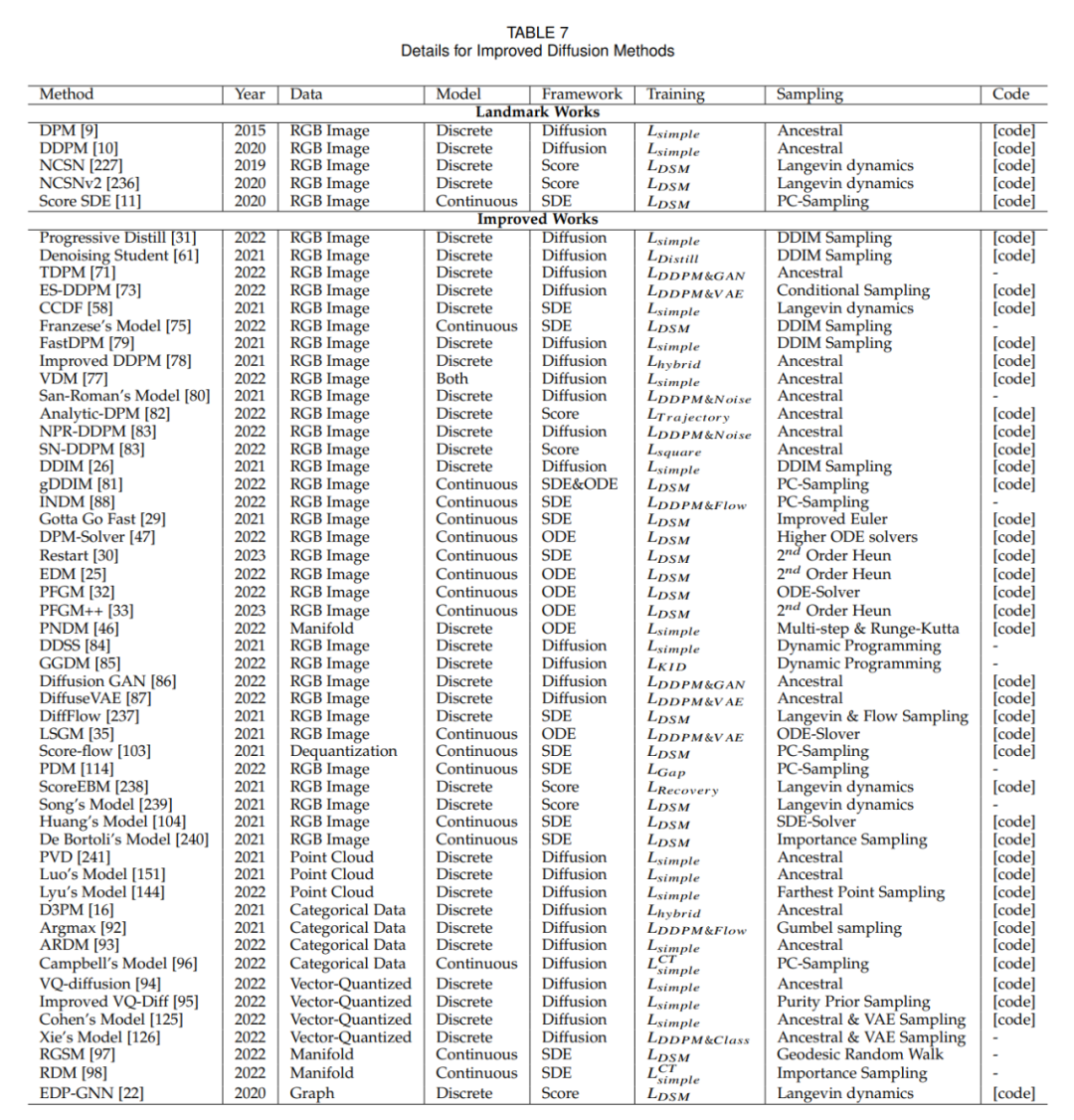
在擴散模型領域,提高采樣速度的關鍵技術之一是知識蒸餾。這個過程涉及從一個大型、復雜的模型中提取出知識,并將其轉移到一個更小、更高效的模型中。例如,通過使用知識蒸餾,我們可以簡化模型的采樣軌跡,使得在每個步驟中都以更高的效率逼近目標分布。Salimans 等人采用了一種基于常微分方程(ODE)的方法來優化這些軌跡,而其他研究者則發展了直接從噪聲樣本估計干凈數據的技術,從而在時間點 T 上加速了這一過程。
- 訓練方式
改進訓練方式也是提升采樣效率的一種方法。一些研究專注于學習新的擴散方案,其中數據不再是簡單地加入高斯噪聲,而是通過更復雜的方法映射到潛在空間。這些方法中,有些關注于優化逆向解碼過程,比如調整編碼的深度,而其他則探索了新的噪聲規模設計,使噪聲的加入不再是靜態的,而是變成了一個可以在訓練過程中學習的參數。
- 免訓練采樣
除了訓練新的模型以提高效率,還有一些技術致力于加速已經預訓練好的擴散模型的采樣過程。ODE 加速是其中的一種技術,它利用 ODE 來描述擴散過程,從而使得采樣可以更快地進行。例如,DDIM 是一種利用 ODE 進行采樣的方法,后續的研究則引入了更高效的 ODE 求解器,如 PNDM 和 EDM,以進一步提升采樣速度。
- 結合其他生成模型
此外,還有研究者提出了解析方法來加速采樣,這些方法試圖找到一個無需迭代就能從噪聲數據中直接恢復干凈數據的解析解。這些方法包括 Analytic-DPM 及其改進版本 Analytic-DPM++,它們提供了一種快速且精確的采樣策略。
擴散過程設計
- 潛在空間
潛在空間擴散模型如 LSGM 和 INDM 結合了 VAE 或歸一化流模型,通過共用的加權去噪分數匹配損失來優化編解碼器和擴散模型,使得 ELBO 或對數似然的優化旨在構建易于學習和生成樣本的潛在空間。例如,Stable Diffusion 首先使用 VAE 學習潛在空間,然后訓練擴散模型以接受文本輸入。DVDP 則在圖像擾動過程中動態調整像素空間的正交組件。
- 創新的前向過程
為了提高生成模型的效率和強度,研究人員探索了新的前向過程設計。泊松場生成模型將數據視為電荷,沿電場線將簡單分布引向數據分布,與傳統擴散模型相比,它提供了更強大的反向采樣。PFGM++ 進一步將這一概念納入高維度變量。Dockhorn 等人的臨界阻尼朗之萬擴散模型利用哈密頓動力學中的速度變量簡化了條件速度分布的分數函數學習。
- 非歐幾里得空間
在離散空間數據(如文本、分類數據)的擴散模型中,D3PM 定義了離散空間的前向過程。基于這種方法,已有研究擴展到語言文本生成、圖分割和無損壓縮等。在多模態挑戰中,矢量量化數據轉換為代碼,顯示出卓越的結果。在黎曼流形中的流形數據,如機器人技術和蛋白質建模,要求擴散采樣納入黎曼流形。圖神經網絡和擴散理論的結合,如 EDP-GNN 和 GraphGDP,處理圖數據來捕捉排列不變性。
似然優化
盡管擴散模型優化了 ELBO,但似然優化仍是一個挑戰,特別是對于連續時間擴散模型。ScoreFlow 和變分擴散模型(VDM)等方法建立了 MLE 訓練與 DSM 目標的聯系,Girsanov 定理在此中起到了關鍵作用。改進的去噪擴散概率模型(DDPM)提出了一種結合變分下界和 DSM 的混合學習目標,以及一種簡單的重新參數化技術。
分布連接
擴散模型在將高斯分布轉換為復雜分布時表現出色,但在連接任意分布時存在挑戰。α- 混合方法通過迭代混合和解混來創建確定性橋梁。矯正流加入額外步驟來矯正橋梁路徑。另一種方法是通過 ODE 實現兩個分布之間的連接,而薛定諤橋或高斯分布作為中間連接點的方法也在研究之中。
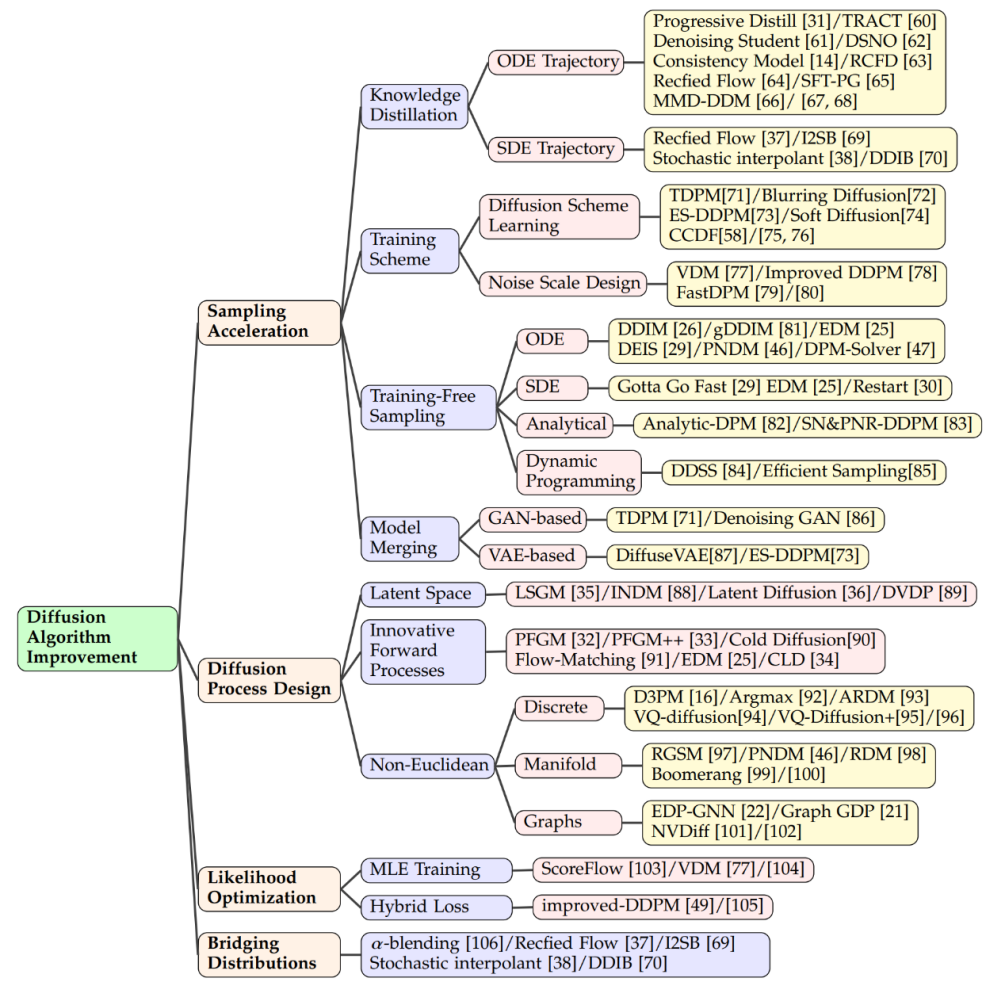
應用領域
圖片生成
擴散模型在圖像生成中非常成功,不僅能生成普通圖像,還能完成復雜任務,比如把文本轉換成圖像。模型如 Imagen、Stable Diffusion 和 DALL-E 2 在這方面展示了高超技術。它們使用擴散模型結構,結合跨注意力層的技術,把文本信息整合進生成圖像。除了生成新圖像,這些模型還能編輯圖像而不需再訓練。編輯是通過調整跨注意力層(鍵、值、注意力矩陣)實現的。比如,通過調整特征圖改變圖像元素或引入新文本嵌入加入新概念。有研究確保模型生成時能關注文本的所有關鍵詞,以確保圖像準確反映描述。擴散模型還能處理基于圖像的條件輸入,比如源圖像、深度圖或人體骨架等,通過編碼并整合這些特征來引導圖像生成。一些研究把源圖像編碼特征加入模型開始層,實現圖像到圖像編輯,也適用于深度圖、邊緣檢測或骨架作為條件的場景。
3D 生成
在 3D 生成方面,通過擴散模型的方法主要有兩種。第一種是直接在 3D 數據上訓練模型,這些模型已被有效應用在多種 3D 表示形式,如 NeRF、點云或體素等。例如,研究者們已經展示了如何直接生成 3D 對象的點云。為了提高采樣的效率,一些研究引入了混合點 - 體素表示,或者將圖像合成作為點云生成的額外條件。另一方面,有研究使用擴散模型來處理 3D 對象的 NeRF 表示,并通過訓練視角條件擴散模型來合成新穎視圖,優化 NeRF 表示。第二種方法強調使用 2D 擴散模型的先驗知識來生成 3D 內容。比如,Dreamfusion 項目使用得分蒸餾采樣目標,從預訓練的文本到圖像模型中提取出 NeRF,并通過梯度下降優化過程來實現低損失的渲染圖像。這一過程也被進一步擴展,以加快生成速度。
視頻生成
視頻擴散模型是對 2D 圖像擴散模型的擴展,它們通過添加時間維度來生成視頻序列。這種方法的基本思想是在現有的 2D 結構中添加時間層,以此來模擬視頻幀之間的連續性和依賴關系。相關的工作展示了如何利用視頻擴散模型來生成動態內容,例如 Make-A-Video、AnimatedDiff 等模型。更具體地,RaMViD 模型使用 3D 卷積神經網絡擴展圖像擴散模型到視頻,并開發了一系列視頻特定的條件技術。
醫學分析
擴散模型幫助解決了醫學分析中獲取高質量數據集的挑戰,尤其在醫學成像方面表現出色。這些模型憑借其強大的圖像捕捉能力,在提升圖像的分辨率、進行分類和噪聲處理方面取得了成功。例如,Score-MRI 和 Diff-MIC 使用先進的技術加速 MRI 圖像的重建和實現更精確的分類。MCG 在 CT 圖像超分辨率中采用流形校正,提高了重建速度和準確性。在生成稀有圖像方面,通過特定技術,模型能在不同類型的圖像間進行轉換。例如,FNDM 和 DiffuseMorph 分別用于腦部異常檢測和 MR 圖像配準。一些新方法通過少量高質量樣本合成訓練數據集,如一個使用 31,740 個樣本的模型合成了一個包含 100,000 個實例的數據集,取得了非常低的 FID 得分。
文本生成
文本生成技術是連接人類和 AI 的重要橋梁,能制造流暢自然的語言。自回歸語言模型雖然生成連貫性強的文本但速度慢,而擴散模型能夠快速生成文本但連貫性相對較弱。兩種主流的方法是離散生成和潛在生成。離散生成依賴于先進技術和預訓練模型;例如,D3PM 和 Argmax 視詞匯為分類向量,而 DiffusionBERT 將擴散模型與語言模型結合提升文本生成。潛在生成則在令牌的潛在空間中生成文本,例如,LM-Diffusion 和 GENIE 等模型在各種任務中表現出色,顯示了擴散模型在文本生成中的潛力。擴散模型預計將在自然語言處理中提升性能,與大型語言模型結合,并支持跨模態生成。
時間序列生成
時間序列數據的建模是在金融、氣候科學、醫療等領域中進行預測和分析的關鍵技術。擴散模型由于其能夠生成高質量的數據樣本,已經被用于時間序列數據的生成。在這個領域,擴散模型通常被設計為考慮時間序列數據的時序依賴性和周期性。例如,CSDI(Conditional Sequence Diffusion Interpolation)是一種模型,它利用了雙向卷積神經網絡結構來生成或插補時間序列數據點。它在醫療數據生成和環境數據生成方面表現出色。其他模型如 DiffSTG 和 TimeGrad 通過結合時空卷積網絡,能夠更好地捕捉時間序列的動態特性,并生成更加真實的時間序列樣本。這些模型通過自我條件指導的方式,逐漸從高斯噪聲中恢復出有意義的時間序列數據。
音頻生成
音頻生成涉及到從語音合成到音樂生成等多個應用場景。由于音頻數據通常包含復雜的時間結構和豐富的頻譜信息,擴散模型在此領域同樣表現出潛能。例如,WaveGrad 和 DiffSinger 是兩種擴散模型,它們利用條件生成過程來產生高質量的音頻波形。WaveGrad 使用 Mel 頻譜作為條件輸入,而 DiffSinger 則在這個基礎上添加了額外的音樂信息,如音高和節奏,從而提供更精細的風格控制。文本到語音(TTS)的應用中,Guided-TTS 和 Diff-TTS 將文本編碼器和聲學分類器的概念結合起來,生成既符合文本內容又遵循特定聲音風格的語音。Guide-TTS2 進一步展現了如何在沒有明確分類器的情況下生成語音,通過模型自身學習到的特征引導聲音生成。
分子設計
在藥物設計、材料科學和化學生物學等領域,分子設計是發現和合成新化合物的重要環節。擴散模型在這里作為一種強大的工具,能夠高效探索化學空間,生成具有特定性質的分子。在無條件的分子生成中,擴散模型不依賴于任何先驗知識,自發地生成分子結構。而在跨模態生成中,模型可能會結合特定的功能條件,例如藥效或目標蛋白的結合傾向,來生成具有所需性質的分子。基于序列的方法可能會考慮蛋白質序列來引導分子的生成,而基于結構的方法則可能使用蛋白質的三維結構信息。這樣的結構信息可以在分子對接或者抗體設計中被用作先驗知識,從而提高生成分子的質量。
圖生成
使用擴散模型生成圖,旨在更好地理解和模擬現實世界的網絡結構和傳播過程。這種方法幫助研究人員挖掘復雜系統中的模式和相互作用,預測可能的結果。應用包括社交網絡、生物網絡分析以及圖數據集的創建。傳統方法依賴于生成鄰接矩陣或節點特征,但這些方法可擴展性差,實用性有限。因此,現代圖生成技術更傾向于根據特定條件生成圖。例如,PCFI 模型使用圖的一部分特征和最短路徑預測來引導生成過程;EDGE 和 DiffFormer 分別用節點度和能量約束來優化生成;D4Explainer 則通過結合分布和反事實損失來探索圖的不同可能性。這些方法提高了圖生成的精確度和實用性。
結論與展望
數據限制下的挑戰
除了推理速度低外,擴散模型在從低質量數據中辨識模式和規律時也常常遇到困難,導致它們無法泛化到新的場景或數據集。此外,處理大規模數據集時也會出現計算上的挑戰,如延長的訓練時間、過度的內存使用,或者無法收斂到期望的狀態,從而限制了模型的規模和復雜性。更重要的是,有偏差或不均勻的數據采樣會限制模型生成適應不同領域或人群的輸出的能力。
可控的基于分布的生成
提高模型理解和生成特定分布內樣本的能力對于在有限數據情況下實現更好的泛化至關重要。通過專注于識別數據中的模式和相關性,模型可以生成與訓練數據高度匹配并滿足特定要求的樣本。這需要有效的數據采樣、利用技術以及優化模型參數和結構。最終,這種增強的理解能力允許更加控制和精確的生成,從而改善泛化性能。
利用大型語言模型的高級多模態生成
擴散模型的未來發展方向涉及通過整合大型語言模型(LLMs)來推進多模態生成。這種整合使模型能夠生成包含文本、圖像和其他模態組合的輸出。通過納入 LLMs,模型對不同模態間相互作用的理解得到增強,生成的輸出更加多樣化和真實。此外,LLMs 顯著提高了基于提示的生成效率,通過有效利用文本與其他模態之間的聯系。另外,LLMs 作為催化劑,提高了擴散模型的生成能力,擴大了它可以生成模態的領域范圍。
與機器學習領域的整合
將擴散模型與傳統的機器學習理論結合,為提高各種任務的性能提供了新的機會。半監督學習在解決擴散模型的固有挑戰,例如泛化問題,以及在數據有限的情況下實現有效的條件生成方面特別有價值。通過利用未標記數據,它加強了擴散模型的泛化能力,并在特定條件下生成樣本時實現了理想的性能。
此外,強化學習通過使用精調算法,在模型的采樣過程中提供針對性的指導,起著至關重要的作用。這種指導確保了專注的探索并促進了受控生成。另外,通過整合額外的反饋,豐富了強化學習,從而改善了模型的可控條件生成能力。
算法改進方法(附錄)
領域應用方法(附錄)