
文 | 元宇宙新聲,作者 | 賈桂鵬
距離大模型橫空出世已經(jīng)過去一年有余,在AI大模型的浪潮下,各大科技企業(yè)爭先恐后地推出了自家的大模型產(chǎn)品。
與此同時,各行業(yè)企業(yè)也對大模型保持著高度關注,一些其他行業(yè)的企業(yè)也紛紛跨界布局大模型相關產(chǎn)品。
面對著全球都在追逐的大模型浪潮,這也使其對算力需求無處不在,但算力供給相對有限,“缺口”或許將影響人工智能的發(fā)展。未來,算力問題也成為各行業(yè)實現(xiàn)人工智能普惠的最大難點。那么,這一困局如何破解呢?
大模型在流行
《北京市人工智能行業(yè)大模型創(chuàng)新應用白皮書(2023年)》中顯示,截至2023年10月,我國10億參數(shù)規(guī)模以上的大模型廠商及高校院所共計254家,分布于20余個省市/地區(qū)。
商業(yè)咨詢機構(gòu)愛分析的報告稱,2023年中國大模型市場規(guī)模約為50億元,預計到2024年這一數(shù)字將達到120億元。
顯然,2024年,大模型將繼續(xù)其火熱的現(xiàn)象,在2023年形成的百模大戰(zhàn)競爭將會進一步白熱化,進一步滲透到各行各業(yè)的數(shù)字化進程中。
我們看到,大模型真正的價值在于行業(yè)側(cè)的應用落地,就目前業(yè)內(nèi)對大模型的認知來看,絕大多數(shù)人對大模型相關產(chǎn)品的發(fā)展觀點類似于互聯(lián)網(wǎng),消費級只是開始,產(chǎn)業(yè)級價值更大。
但如同互聯(lián)網(wǎng)一樣,消費互聯(lián)網(wǎng)發(fā)展迅速,甚至已經(jīng)接近“天花板”;產(chǎn)業(yè)互聯(lián)網(wǎng)也僅是近年來在政策引導,數(shù)字技術驅(qū)動下,逐步發(fā)展提速。
為什么大模型技術是產(chǎn)業(yè)界的一次革命呢?
一直以來,AI在產(chǎn)業(yè)化的進程當中,發(fā)展得非常慢。那么在大模型的技術出來后,我們認為它來到了一個轉(zhuǎn)折點。
需要了解的是,大模型不僅是一個聊天機器人,也不是像抖音、快手這樣讓人消磨時間的娛樂軟件。它是一個提高生產(chǎn)力的工具,不僅僅是公司間競爭的利器,更重要的是,它像發(fā)電廠一樣,把以前很難直接使用的大數(shù)據(jù)從“石油”狀態(tài)加工成了“電”。而“電”是通用的,就能賦能百行千業(yè),就能夠在實體經(jīng)濟轉(zhuǎn)型數(shù)字化、智能化的過程中發(fā)揮重要的作用。
據(jù)有關機構(gòu)預測,未來三年,在生產(chǎn)經(jīng)營環(huán)節(jié)應用AI大模型的企業(yè)占比將提高到80%以上。
為了進一步釋放AI的效果,我們需要推動產(chǎn)學研用的深度融合,強化高價值的數(shù)據(jù)、高性能的算力、高質(zhì)量的算法和協(xié)同創(chuàng)新,加快關鍵技術突破和產(chǎn)業(yè)應用,讓AI不僅會寫文章做PPT,更能夠?qū)嶋H應用于各個領域。
然而,隨著大模型的不斷發(fā)展,我們也面臨著一些挑戰(zhàn)。
比如,目前的大模型是萬事通,但不是行業(yè)通。如果你真的用過大模型,在震驚完它什么都會之后,你會發(fā)現(xiàn)一旦問它一些行業(yè)的問題,它就會說很多概念性的正確廢話。也就是說,大模型對行業(yè)理解的深度還遠遠不足。
大模型無法保證生成的內(nèi)容完全可信,或者說大模型能產(chǎn)生知識模糊、制造知識幻覺。比如它會輸出“賈寶玉打虎”“林黛玉三打白骨精”等不符合事實的信息。
我們認為,相比于AI大模型自身發(fā)展的問題,算力不足的問題更顯突出。由于大模型的規(guī)模龐大,需要巨大的計算資源來進行訓練和推理。
但現(xiàn)有的計算基礎設施還無法滿足這一需求,這導致了訓練時間過長、推理速度緩慢等問題。這不僅限制了大模型的應用范圍,也制約了我們的創(chuàng)新步伐。
AI時代,算力需求增加
我們看到,GPT-3實際上是生成語言生成模型,他參數(shù)量大概1750億,而隨著GPT-4和未來GPT-5的推出這個發(fā)展趨勢還會延續(xù)。
比如,對標GPT-3和GPT-4模型,GPT-3模型訓練使用了128臺英偉達A100服務器(訓練34天),對應640P算力,GPT-4模型訓練使用了3125臺英偉達A100服務器(訓練90—100天),對應15625P算力。從GPT-3至GPT-4模型參數(shù)規(guī)模增加約10倍,但用于訓練的GPU數(shù)量增加了近24倍(且不考慮模型訓練時間的增長)。
從全球算力的表現(xiàn)狀態(tài)分析來看,從22到23年經(jīng)歷了疫情,數(shù)字經(jīng)濟其實在這幾年增長還比較快。
尤其數(shù)字化優(yōu)先成為企業(yè)重要的戰(zhàn)略發(fā)展途徑。所以算力已經(jīng)成為整個行業(yè)里面科技的更新和迭代的一個重要支撐。
未來算力發(fā)展的趨勢
眾所周知,人工智能實現(xiàn)方法之一為機器學習,而深度學習是用來實現(xiàn)機器學習的技術,通常可分為“訓練”和“推理”兩個階段。
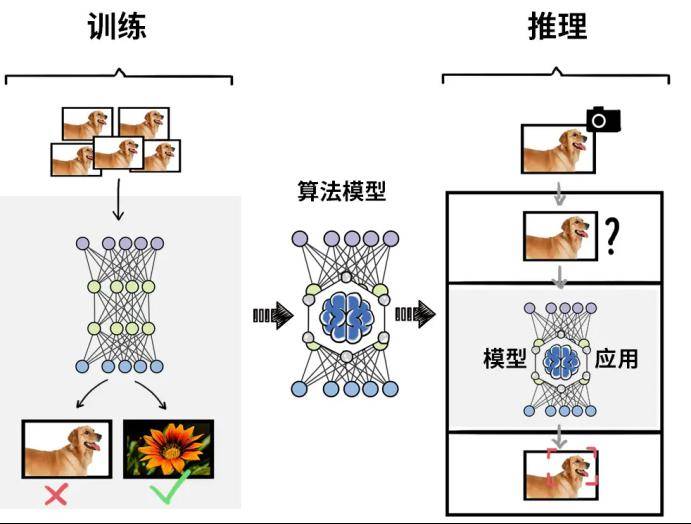
訓練階段:需要基于大量的數(shù)據(jù)來調(diào)整和優(yōu)化人工智能模型的參數(shù),使模型的準確度達到預期,核心在于算力。
推理階段:訓練結(jié)束后,建立的人工智能模型可用于推理或預測待處理輸入數(shù)據(jù)對應的輸出,這個過程為推理階段,對單個任務的計算能力不及訓練,但總計算量也相當可觀。
雖然,目前算力的需求在不斷增加,也導致了出現(xiàn)“算力危機”,但我們看到突破這些危機的一些技術趨勢。
第一個趨勢,在算力層面,我們看到通用算力正在轉(zhuǎn)向?qū)S盟懔Γ部梢苑Q為智能算力。專用算力包括以GPU為核心的并行訓練加速,例如,英偉達DPU,谷歌的GPU,還有新型的算力形態(tài),如NPU等,用于加速 AI 載體。

第二個趨勢是從單點到分布式的發(fā)展。在十多年前,我們可能只需要使用CPU進行AI模型訓練,然后逐漸轉(zhuǎn)向GPU加CPU的方式。當時由于CPU和GPU的編程方式不同,需要重新編譯兩次才能在CPU和GPU上運行,因此在那個時候,AI模型通常在單臺機器上單卡上運行。隨著模型參數(shù)的增加和模型類型的多樣化,從單機單卡逐漸演變成了單機多卡,然后隨著GPU的崛起,從單機多卡又發(fā)展為分布式訓練。這也使得模型訓練的速度更快。
第三個趨勢是能耗和可持續(xù)性。隨著訓練集群的出現(xiàn),能耗上升成為一個問題,數(shù)據(jù)中心需要進行改建和升級以滿足能耗要求,這也引發(fā)了合規(guī)和可持續(xù)性的關注。高能耗需要政府批準,因此降低能耗、實現(xiàn)綠色和節(jié)能成為趨勢。
第四個趨勢是軟硬結(jié)合。從純硬件走向軟硬件結(jié)合,尤其是英偉達等公司的帶領,軟件生態(tài)系統(tǒng)變得至關重要。軟件工程師和人工智能算法工程師的參與推動了這一趨勢。

就我國而言,未來,隨著新的算力芯片到來的,還有國內(nèi)各地出臺的一系列利好政策,也積極引導大模型研發(fā)企業(yè)應用國產(chǎn)芯片,加快提升算力供給的國產(chǎn)化率,提升算力資源統(tǒng)籌供給能力,攜手企業(yè)共同推動算力市場發(fā)展。
寫在最后
可以說,算力是數(shù)字經(jīng)濟時代最底層的驅(qū)動器,無人駕駛、智慧城市、智能交通、智慧金融、仿生科技、生命醫(yī)學、氣候預測以及農(nóng)業(yè)精細化等,都離不開超大算力的支持。在未來的大國競爭中,算力之強弱將直接深度影響到新技術的研發(fā)效率和研發(fā)成果。
未來,大模型時代的全面到來,注定充滿挑戰(zhàn),而挑戰(zhàn)往往孕育著機遇。以計算為代表的顛覆技術成為大模型時代的重要底座。最終,誰將主導這場算力的變革,讓業(yè)界看到大模型市場的新機會,在廣闊的市場中率先突圍呢?我們拭目以待。





