擊這里在線咨詢客服")
明敏 豐色 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI
就說Sora有多火吧。
生成的視頻上線一個(gè)、瘋傳一個(gè)。

作者小哥新上傳的效果,點(diǎn)贊很快破萬。
失敗案例都讓人看得上癮。

將近10萬人點(diǎn)贊。
學(xué)術(shù)圈更炸開鍋了,各路大佬紛紛開麥。
紐約大學(xué)助理教授謝賽寧(ResNeXt的一作)直言,Sora將改寫整個(gè)視頻生成領(lǐng)域。

英偉達(dá)高級(jí)研究科學(xué)家Jim Fan高呼,這就是視頻生成的GPT-3時(shí)刻啊!
尤其在技術(shù)報(bào)告發(fā)布后,討論變得更加有趣。因?yàn)槠渲兄T多細(xì)節(jié)不是十分明確,所以大佬們也只能猜測。
包括“Sora是一個(gè)數(shù)據(jù)驅(qū)動(dòng)的物理引擎”、“Sora建立在DiT模型之上、參數(shù)可能僅30億”等等。
所以,Sora為啥能如此驚艷?它對(duì)視頻生成領(lǐng)域的意義是?這不,很快就有了一些可能的答案。
視頻生成的GPT-3時(shí)刻
總的來說,Sora是一個(gè)在不同時(shí)長、分辨率和寬高比的視頻及圖像上訓(xùn)練而成的擴(kuò)散模型,同時(shí)采用了Transformer架構(gòu),也就是一種“擴(kuò)散型Transformer”。
關(guān)于技術(shù)細(xì)節(jié),官方報(bào)告簡單提了以下6點(diǎn):
一是視覺數(shù)據(jù)的“創(chuàng)新轉(zhuǎn)化”。
與大語言模型中的token不同,Sora采用的是“Patches(補(bǔ)片)”來統(tǒng)一不同的視覺數(shù)據(jù)表現(xiàn)形式。
如下圖所示,在具體操作中,模型先將視頻壓縮到低維潛空間中,然后將它們表示分解為時(shí)空補(bǔ)片,從而將視頻轉(zhuǎn)換為補(bǔ)片。(啊這,說了又仿佛什么都沒說)
二是訓(xùn)練了一個(gè)視頻壓縮網(wǎng)絡(luò)。
它可以降低視覺數(shù)據(jù)維度,輸入視頻,輸出時(shí)空上壓縮的潛表示。
Sora就在這上面完成訓(xùn)練。相應(yīng)地,OpenAI也訓(xùn)練了一個(gè)專門的解碼器。
三是時(shí)空補(bǔ)片技術(shù)(Spacetime latent patches)。
給定一個(gè)壓縮的輸入視頻,模型提取一系列時(shí)空補(bǔ)片,充當(dāng)Transformer的token。正是這個(gè)基于補(bǔ)片的表示讓Sora能夠?qū)Σ煌直媛省⒊掷m(xù)時(shí)間和長寬比的視頻和圖像進(jìn)行訓(xùn)練。
在推理時(shí),模型則通過在適當(dāng)大小的網(wǎng)格中排列隨機(jī)初始化的補(bǔ)片來控制生成視頻的大小。
四是擴(kuò)展Transformer也適用于視頻生成的發(fā)現(xiàn)。
OpenAI在這項(xiàng)研究中發(fā)現(xiàn),擴(kuò)散型Transformer同樣能在視頻模型領(lǐng)域中完成高效擴(kuò)展。
下圖展示出隨著訓(xùn)練資源的增加,樣本質(zhì)量明顯提升(固定種子和輸入條件)。

五是視頻多樣化上的一些揭秘。
和其他模型相比,Sora能夠hold住各種尺寸的視頻,包括不同分辨率、時(shí)長、寬高比等等。

也在構(gòu)圖和布局上優(yōu)化了更多,如下圖所示,很多業(yè)內(nèi)同類型模型都會(huì)盲目裁剪輸出視頻為正方形,造成主題元素只能部分展示,但Sora可以捕捉完整的場景:

報(bào)告指出,這都要?dú)w功于OpenAI直接在視頻數(shù)據(jù)的原始尺寸上進(jìn)行了訓(xùn)練。
最后,是語言理解方面上的功夫。
在此,OpenAI采用了DALL·E 3中引入的一種重新標(biāo)注技術(shù),將其應(yīng)用于視頻。
除了使用描述性強(qiáng)的視頻說明進(jìn)行訓(xùn)練,OpenAI也用GPT來將用戶簡短的提示轉(zhuǎn)換為更長的詳細(xì)說明,然后發(fā)送給Sora。
這一系列使得Sora的文字理解能力也相當(dāng)給力。
關(guān)于技術(shù)的介紹報(bào)告只提了這么多,剩下的大篇幅都是圍繞Sora的一系列效果展示,包括文轉(zhuǎn)視頻、視頻轉(zhuǎn)視頻,以及圖片生成。

可以看到,諸如其中的“patch”到底是怎么設(shè)計(jì)的等核心問題,文中并沒有詳細(xì)講解。
有網(wǎng)友吐槽,OpenAI果然還是這么地“Close”(狗頭)。
正是如此,各路大佬和網(wǎng)友們的猜測也是五花八門。
謝賽寧分析:
1、Sora應(yīng)該是建立在DiT這個(gè)擴(kuò)散Transformer之上的。
簡而言之,DiT是一個(gè)帶有Transformer主干的擴(kuò)散模型,它= [VAE 編碼器 + ViT + DDPM + VAE 解碼器]。
謝賽寧猜測,在這上面,Sora應(yīng)該沒有整太多花哨的額外東西。
2、關(guān)于視頻壓縮網(wǎng)絡(luò),Sora可能采用的就是VAE架構(gòu),區(qū)別就是經(jīng)過原始視頻數(shù)據(jù)訓(xùn)練。
而由于VAE是一個(gè)Con.NET,所以DiT從技術(shù)上來說是一個(gè)混合模型。

3、Sora可能有大約30億個(gè)參數(shù)。

謝賽寧認(rèn)為這個(gè)推測不算不合理,因Sora可能還真并不需要人們想象中的那么多GPU來訓(xùn)練,如果真是如此,Sora的后期迭代也將會(huì)非常快。
英偉達(dá)AI科學(xué)家Jim Fan則認(rèn)為:
Sora應(yīng)該是一個(gè)數(shù)據(jù)驅(qū)動(dòng)的物理引擎。
Sora是對(duì)現(xiàn)實(shí)或幻想世界的模擬,它通過一些去噪、梯度下降去學(xué)習(xí)復(fù)雜渲染、“直覺”物理、長鏡頭推理和語義基礎(chǔ)等。
比如這個(gè)效果中,提示詞是兩艘海盜船在一杯咖啡里航行廝殺的逼真特寫視頻。
Jim Fan分析,Sora首先要提供兩個(gè)3D資產(chǎn):不同裝飾的海盜船;必須在潛在空間中解決text-to-3D的隱式問題;并且要兩艘船避開彼此的路線,兼顧咖啡液體的流體力學(xué)、保持真實(shí)感、帶來仿佛光追般的效果。

有一些觀點(diǎn)認(rèn)為,Sora只是在2D層面上控制像素。Jim Fan明確反對(duì)這種說法。他覺得這就像說GPT-4不懂編碼,只是對(duì)字符串進(jìn)行采樣。
不過他也表示,Sora還無法取代游戲引擎開發(fā)者,因?yàn)樗鼘?duì)于物理的理解還遠(yuǎn)遠(yuǎn)不夠,仍然存在非常嚴(yán)重的“幻覺”。

所以他提出Sora是視頻生成的GPT-3時(shí)刻。
回到2020年,GPT-3不是一個(gè)很完美的模型,但是它有力證明了上下文學(xué)習(xí)的重要性。所以不要糾結(jié)于GPT-3的缺陷,多想想后面的GPT-4。

除此之外,還有膽大的網(wǎng)友甚至懷疑Sora用上了虛幻引擎5來創(chuàng)建部分訓(xùn)練數(shù)據(jù)。

他甚至挨個(gè)舉例分析了好幾個(gè)視頻中的效果以此佐證猜想:
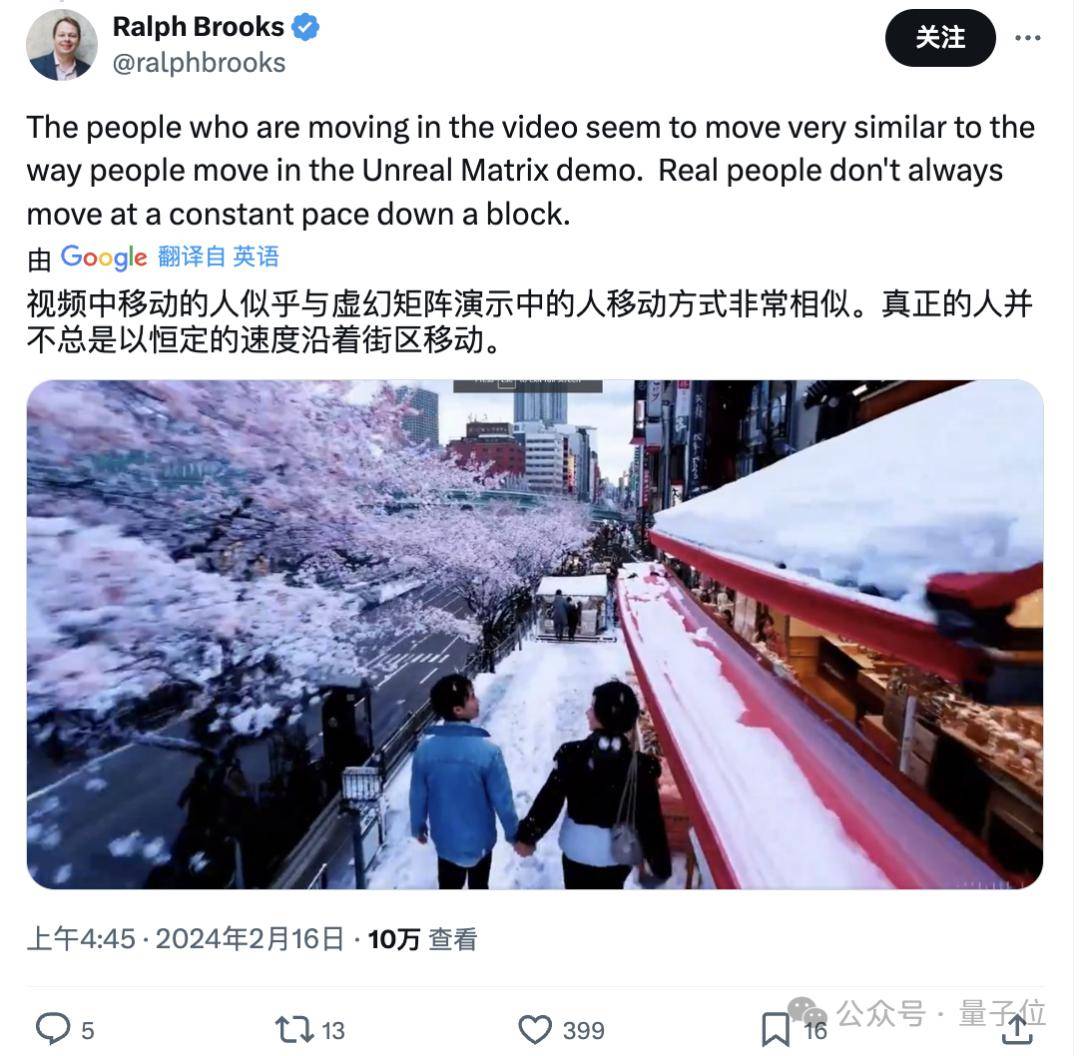
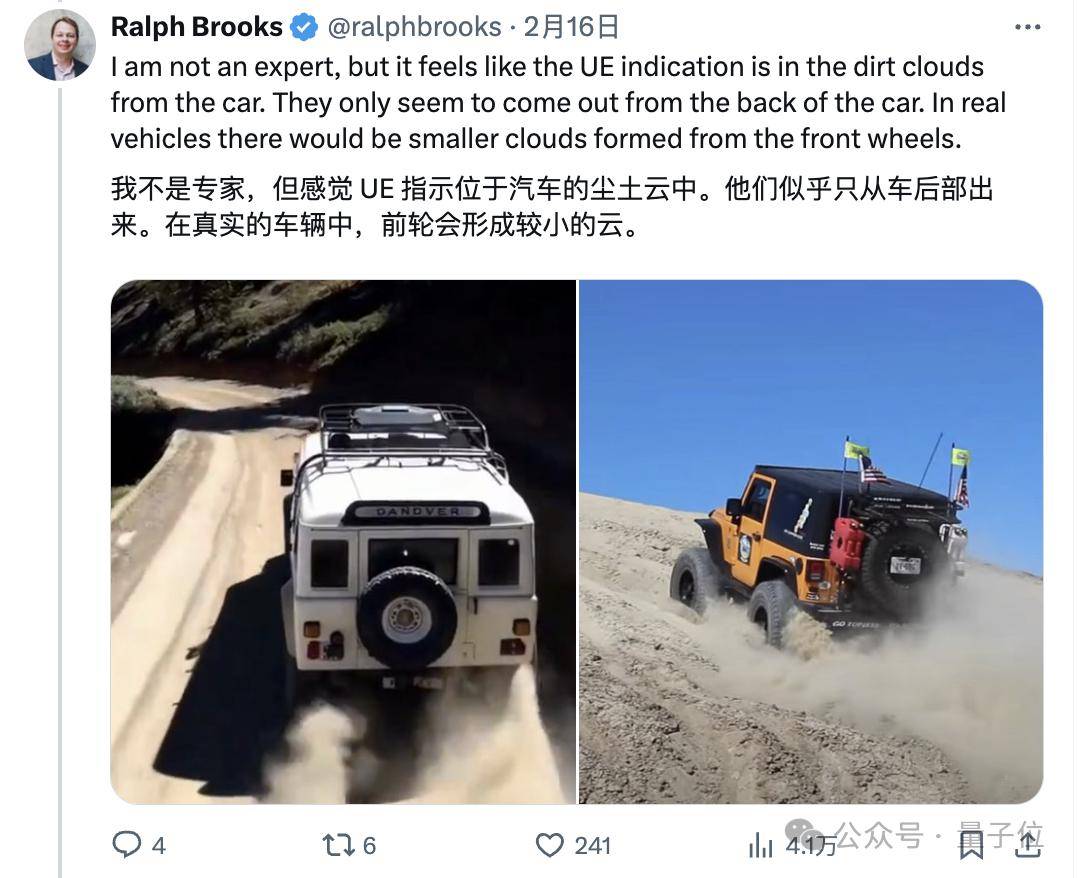
不過反駁他的人也不少,理由包括“人走路的鏡頭明顯還是奇怪,不可能是引擎的效果”、“YouTube上有數(shù)十億小時(shí)的各種視頻,ue5的用處不大吧”……
如此種種,暫且不論。
最后,有網(wǎng)友表示,盡管不對(duì)OpenAI放出更多細(xì)節(jié)抱有期待,但還是很想知道Sora在視頻編碼、解碼,時(shí)間插值的額外模塊等方面是不是有創(chuàng)新。
OpenAI估值達(dá)800億美元
在Sora引發(fā)全球關(guān)注的同時(shí),OpenAI的估值也再次拉高,成為全球第三高估值的科技初創(chuàng)公司。
隨著最新一要約收購?fù)瓿桑琌penAI的估值正式達(dá)到800億美元,僅次于字節(jié)跳動(dòng)和SpaceX。
這筆交易由風(fēng)投公司Thrive Capital牽頭,外部投資者可以從一些員工手中購買股份,去年年初時(shí)OpenAI就完成過類似交易,使其當(dāng)時(shí)的估值達(dá)到290億美元。
而在Sora發(fā)布后,GPT-4 Turbo也大幅降低速率限制,提高TPM(每分鐘最大token數(shù)量),較上一次實(shí)現(xiàn)2倍提升。
總裁Brockman還親自帶貨宣傳。

但與此同時(shí),OpenAI申請(qǐng)注冊(cè)“GPT”商標(biāo)失敗了。
理由是“GPT”太通用。
One More Thing
值得一提的是,有眼尖的網(wǎng)友發(fā)現(xiàn),昨天Stability AI也發(fā)布了SVD 1.1。
但似乎在Sora發(fā)布不久后火速刪博。
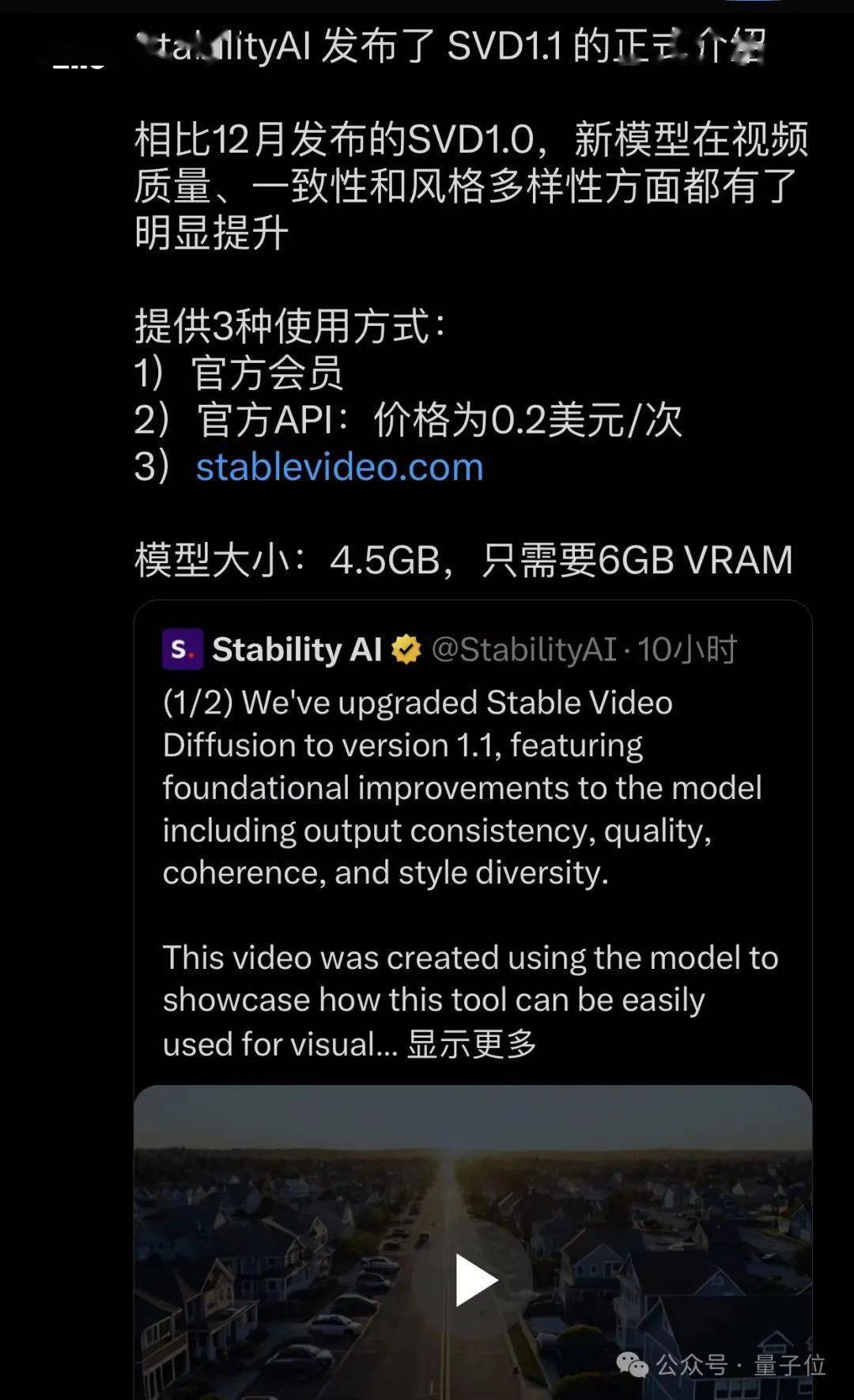
有人銳評(píng),這不是翻版汪峰么?不應(yīng)該刪,應(yīng)該返蹭個(gè)熱度。
這還玩?zhèn)€p啊。

還有人感慨,Sora一來,立馬就明白張楠為啥要聚焦剪映了。

以及賣課大軍也聞風(fēng)而動(dòng),把商機(jī)拿捏死死的。

參考鏈接:
[1]https://openai.com/research/video-generation-models-as-world-simulators
[2]https://Twitter.com/DrJimFan/status/1758210245799920123
[3]https://x.com/sainingxie/status/1758433676105310543?s=20
[4]https://twitter.com/charliebholtz/status/1758200919181967679
[5]https://www.reuters.com/technology/openai-valued-80-billion-after-deal-nyt-reports-2024-02-16/
— 完—





